構造化データ
はじめに
私たちは、セマンティックウェブの進化における重要な時期を迎えています。AIは広く利用可能になり、多くの日常的なアプリケーションに統合されています。この章は3年目を迎え、過去1年間のトレンドを分析し、時間とともに急速に進展する状況を検証する貴重な機会を提供します。これまでの版を振り返ることで、構造化データの現状と今後の方向性について包括的な視点を提供できます。
拡大する構造化データの展望
過去18ヶ月間で、構造化データの状況は大きく変化しました。2023年、Googleは検索エンジン結果ページ(SERP)から FAQ と HowTo のリッチリザルトを廃止しました(参照)。2024年11月には、検索結果からサイトリンク検索ボックスも削除される予定です(参照)。しかし、それと並行して、GoogleとBingの両方で構造化データの使用に関する新しい革新と拡大の波が起きています。
2023-2024年の主要な進展:
-
新しい構造化データタイプ: Googleは、車両リスト、コース情報、バケーション賃貸、製品の3Dモデルなど、いくつかの新しいタイプを導入しました。また、eコマース分野では、Googleは特にMerchant CenterとSchema.orgを通じて、ロイヤリティプログラムを構造化データの提供に統合しました。
-
既存タイプの強化: 組織データ、製品バリアントの改善、割引リッチリザルトの導入。
-
構造化データカルーセル:
ItemListと他のタイプを組み合わせた構造化データカルーセルのベータ版がリリースされ、GoogleのSERPで新しいコンテンツ表示の可能性が開かれました(参照)。 -
GS1統合: GS1 Digital LinkなどのGS1標準のサポートが強化され、物理的およびデジタル製品情報のギャップを埋めることを目指しています。この技術により、メーカーと小売業者はQRコードを通じて物理製品とデジタルIDを接続できます。スキャンすると、これらのコードは包括的な製品情報へのアクセスを提供し、透明性と顧客エンゲージメントを向上させます。また、
gs1:CertificationDetailsプロパティは、Googleによってschema:Certificationとして正式に採用され、業界固有の拡張機能がSchema.org標準に影響を与え、統合できることを示しています。 -
検索アプリケーションを超えたセマンティックデータ: 構造化データは、従来の検索エンジンを超えて、ソーシャルウェブアプリケーションで重要な役割を果たすようになっています。たとえば:
- ID検証: Mastodonなどのプラットフォームは、双方向のID検証に
rel=meリンクを使用しています(参照)。 - 連合ソーシャルネットワーク:
rel=meの使用により、Mastodonユーザーはサードパーティのウェブサイト(例:Ghost)でアカウントを検証でき、クロスプラットフォームのIDを強化しています(Ghostでのrel=meに関する議論)。 - 新しいジャーナリズム機能: Mastodonは最近、ジャーナリストと出版社のためのコンテンツ検証をサポートするために
fediverse:creator属性を導入しました(参照)。
- ID検証: Mastodonなどのプラットフォームは、双方向のID検証に
従来の実装を超えて
構造化データのエコシステムが成熟するにつれて、実装戦略の多様化が進んでいます。検索エンジンが構造化データの主要な消費者である一方で、その応用は大幅に拡大しています:
-
マークアップとしてのSchema.org: ウェブページに直接構造化データを埋め込む従来の方法は、現代のSEOプラクティスの基盤であり続けています。
-
データ標準としてのSchema.org: HTMLでの使用を超えて、Schema.orgはAPIやフィードを通じて共有されるデータの標準化にますます活用されています。たとえば、GoogleのData Commonsイニシアチブは、拡張されたSchema.org語彙を使用して、世界中の数百の組織からのデータセットを統合しています。この標準化は、データセットの発見や関係性のマッピングなどのタスクをサポートし、AI駆動環境でのデータセットの出所、サブセット、派生の理解に重要です(参照)。
-
ソーシャルウェブアプリケーションでのセマンティックデータ:
-
デジタル製品パスポート(DPP):
構造化データは、EUのデジタル製品パスポートなどの新興の規制要件において重要な役割を果たしています。これは、eコマースにおける透明性と持続可能性を向上させるために設計されています。これらのパスポートは、GS1 Digital Linksを活用して、QRコードを通じて包括的な製品情報を提供します。
- AI駆動のディスカバリーのための構造化データ:
AI駆動の検索エンジン、チャットボット、会話型アシスタントがその範囲を拡大し続ける中、構造化データは、これらのプラットフォーム全体でコンテンツの発見可能性と文脈理解を向上させる上で重要な役割を果たしています。主な例としては:
- AI検索エンジン: Bing ChatやGoogle AI Overviewなどのプラットフォームは、構造化データを活用して言語モデルを訓練するだけでなく、文脈的に豊かで正確な応答を提供しています。構造化データを活用することで、これらのシステムはデータセット間の複雑な関係を解釈し、検索の関連性を向上させ、ユーザーが相互接続されたデータセットをシームレスにナビゲートできるようにしています(参照)。
これらの機能は、構造化データが発見可能性の向上だけでなく、AIシステムがデータ間の関係を解釈し、それに基づいて行動する能力を向上させる上で、進化する役割を示しています。これにより、より豊かで有用なユーザー体験が生まれます。
この多様化は、構造化データがデータの相互運用性、社会的信頼、規制遵守、AI駆動のコンテンツ発見を促進する上で、ますます重要な役割を果たしていることを示しています。システムがデータ間の複雑な関係を理解し、それに基づいて行動できるようにすることで、構造化データはより豊かで、よりインテリジェントなデジタル体験の基盤を築いています。
AIと機械学習時代における構造化データ
生成AIと高度な機械学習の登場により、構造化データの重要性がさらに強調されています:
-
事実の検証: 構造化データは、AIシステムにとって解析可能なソースを提供し、情報を効率的に抽出、解釈、検証することを可能にします。これにより:
- 偽情報の対策: AIは、構造化データを信頼できる他のソースと相互参照することで、事実を検証できます。
- コンテンツの理解の向上: 明確なエンティティの定義と関係を提供することで、構造化データは複雑なトピックの解釈を支援します。
- ユーザー体験の向上: 構造化データにより、チャットボットや音声アシスタントなどのAIシステムは、ユーザーのクエリに対して正確で文脈的に豊富な応答を提供できます。
- 検索理解の強化: 構造化データにより、検索エンジンやAI駆動システムがコンテンツをより洗練された方法で解釈できます。
- 機械学習のトレーニングデータ: 構造化データは、高品質の機械学習モデルのトレーニング材料です。
この章が提供するもの
この章では、2023-2024年の構造化データのトレンドについてデータ主導の分析を行い、主要な発展とベストプラクティスを紹介します:
-
ランドスケープの進化:
- Google AI OverviewやBing ChatなどのAI駆動検索の増加に伴う構造化データの主要な変化。
- GoogleとBingの構造化データポリシーの変化と、SEOへの影響。
-
普及と成長:
- JSON-LD、Microdata、RDFaなどの一般的な形式のトレンド。
Product、Organization、Articleなどのスキーマタイプの採用率。
-
実装とベストプラクティス:
- JSON-LDの使用など、構造化データのベストプラクティス。
- 一般的な間違いとその回避方法。
-
リッチリザルトとSERP機能:
FAQやHowToなどの廃止された機能の影響。- カルーセルや製品知識パネルの導入。
-
AI駆動検索:
- AI駆動検索や音声アシスタントにおける構造化データの役割。
- AI駆動コンテンツ発見のトレンド。
-
eコマースの革新:
- デジタル製品パスポートやGS1デジタルリンクの成長。
- eコマースや新しいリッチリザルトタイプにおける構造化データの役割。
-
知識グラフとグラフRAG:
- 知識グラフとグラフRAGがAI出力の強化においてどのように重要になっているか。
-
データの品質と整合性:
- 高品質の構造化データを維持するためのベストプラクティス。
-
新しいスキーマとユースケース:
- SEOやeコマースにおけるスキーマタイプの革新とその適用。
-
将来の展望:
- 構造化データがAI、セマンティックSEO、コンテンツ発見においてどのように進化していくか。
この章では、SEO、AI、eコマースにおける構造化データの影響について包括的な視点を提供し、開発者やマーケターに実行可能な洞察を提供します。
主要概念
構造化データが複雑さを増している中、分析を進める前に重要な概念を探求し、説明することが重要です。このセクションでは、分野の基本的な考え方と最近の発展を概説します。
リンクデータとセマンティックウェブ
リンクデータは、構造化データの基礎をなすものです。ウェブページに構造化データを追加し、参照されたエンティティにURIリンクを提供することで、情報の相互に結びついたウェブを作り出します。これにより、リソース記述フレームワーク(RDF)を介してウェブページをデータベースとして扱えるセマンティックウェブを支援します。
セマンティックトリプル(主語-述語-目的語)の概念は、エンティティ間の関係を表現する上で基本的です。SPARQLは、グラフデータやRDFトリプルをクエリするための特定の言語で、GraphQLは、さまざまなバックエンド(データベースやマイクロサービスを含む)から構造化データを取得するための柔軟なAPIクエリ言語です。これらのツールは相互に補完し、SPARQLはセマンティックウェブアプリケーションにおけるRDFデータセットのクエリに優れ、GraphQLはウェブやモバイルアプリケーションにおける構造化データへのアクセスを簡素化します。
オープンデータと5つ星モデル
ティム・バーナーズ=リーのオープンデータモデルの5つ星は、依然として重要です。それは、ウェブで利用可能、構造化、非専有、URI識別、相互リンクされたデータの重要性を強調しています。構造化データは、このモデルのより高いレベル達成で重要な役割を果たし、よりオープンで相互接続されたウェブエコシステムに貢献します。
AI検索、音声アシスタント、デジタルアシスタント
AI、LLM、高度な自然言語処理の統合により、検索とデジタルアシスタンスの状況は劇的に進化しています。この収束により、従来の検索エンジン、音声起動システム、AI駆動のデジタルアシスタントの境界線が曖昧になっています。
セマンティック検索エンジンとAI駆動検索
セマンティック検索は、従来のキーワードマッチングを超えて、高度なAI駆動のエクスペリエンスを含むようになりました。これらのシステムは構造化データを活用して、より正確で文脈に即した、対話的な検索結果を提供します。主な進展は以下の通りです:
- Google AI Overview:複雑なトピックに関する包括的な(時に誤解を招く)AI生成サマリーを提供する機能。
- Microsoft Bing Chat:Bing検索結果に直接チャットベースのAIインタラクションを統合。
- Meta AI:Facebook、Messenger、Instagram、WhatsAppなどのプラットフォーム全体に統合されたMetaのAIアシスタント。
- SearchGPT(およびChatGPT):検索結果を対話型レスポンスに統合するOpenAIのAI検索エンジン。
- Perplexity.ai:詳細なソース付きの回答を提供するAI駆動の検索エンジン。
- You.com:AIによる要約検索結果とより対話的な検索のためのチャットインターフェースを提供。
これらのプラットフォームは、ユーザーの意図と文脈を理解する能力が向上し、検索の精度とユーザー体験を大幅に改善しています。従来のウェブインデックスと、リアルタイムの情報検索、自然言語生成を組み合わせることが多いです。
構造化データの役割
構造化データは、これらのAI駆動システムで以下のような重要な役割を果たしています:
- エンティティ認識の強化:クエリで言及されたエンティティを正確に識別し、曖昧さを解消するのに役立ちます。
- 文脈の提供:エンティティとその関係に関する追加情報を提供し、応答の精度を向上させます。
- 知識グラフ統合の促進:これらのシステムが膨大な相互接続された情報データベースにアクセスできるようにします。
- リッチレスポンスの実現:視覚要素やインタラクティブな機能を含む、詳細で多面的な回答の生成をサポートします。
- 音声クエリ解釈の改善:テキストベースの検索よりも曖昧になりやすい音声クエリの意図を理解するのを支援します。
生成AIとAI検索エンジンにおける構造化データの影響を評価するのは依然として困難ですが、地理参照クエリなどの場合、Perplexity.aiやYou.comのユーザー体験でエンティティの初期的な出現を観察できます。

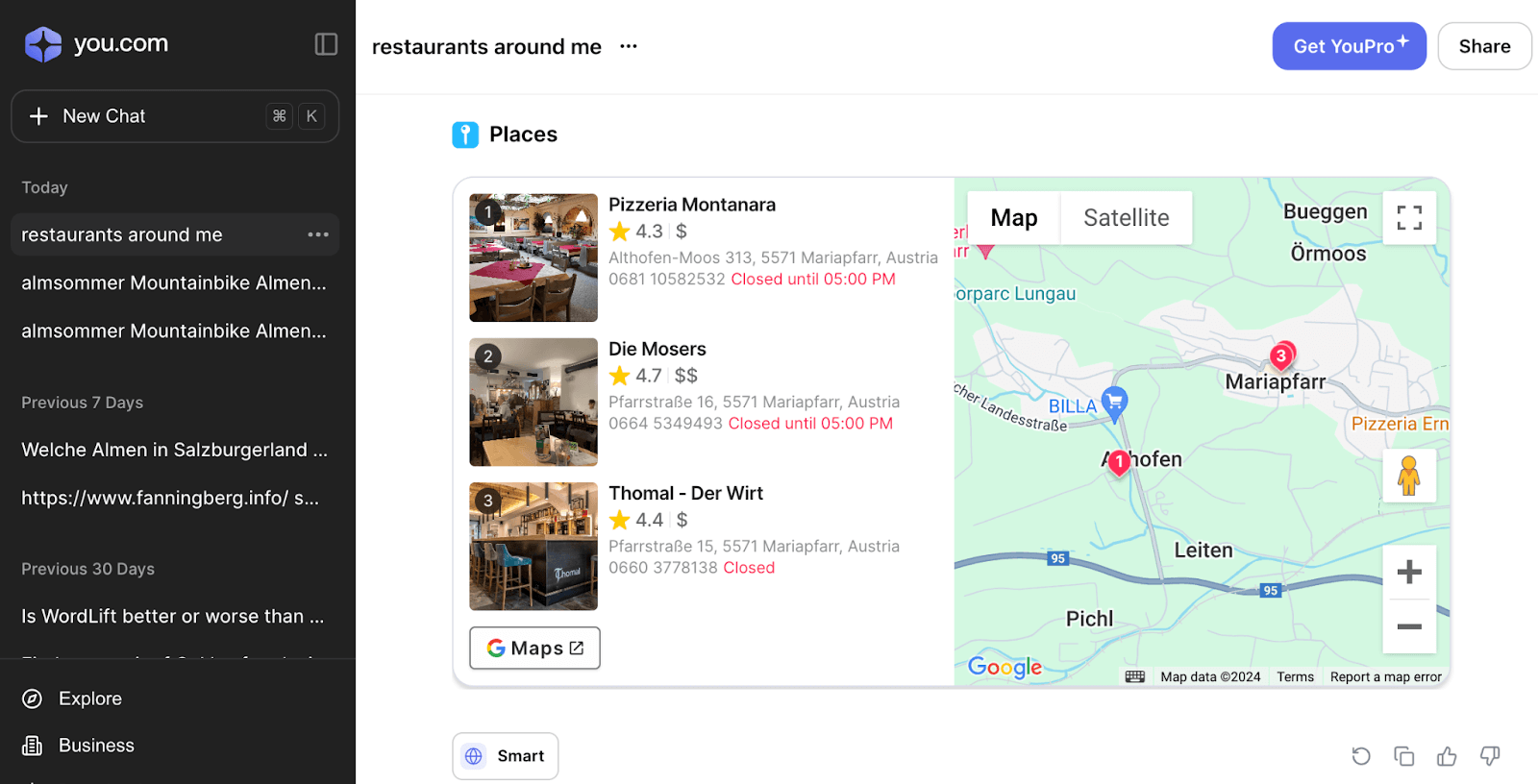
これは、Bing CopilotやGoogleのGeminiと対話する際により一貫性が見られます。
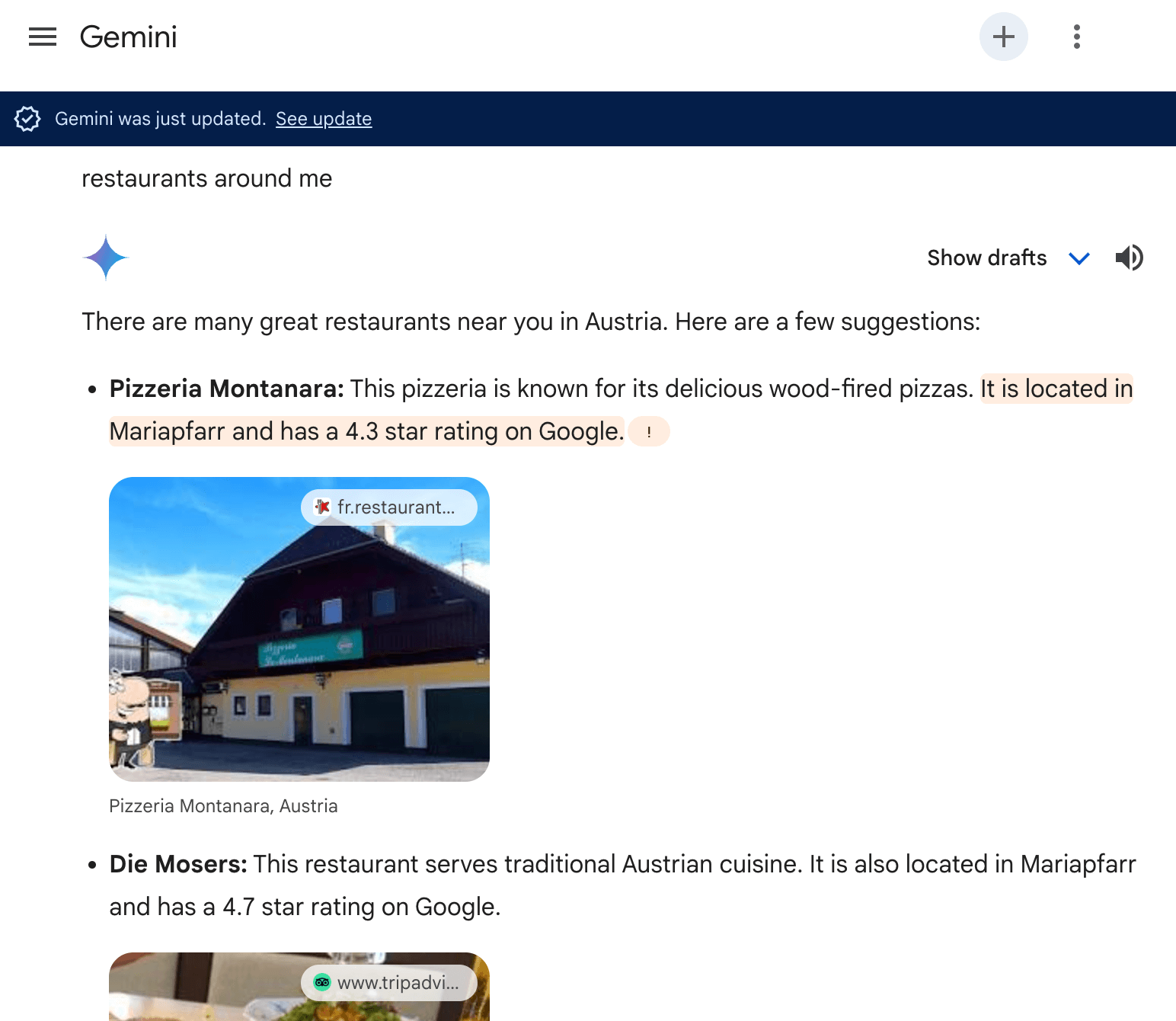
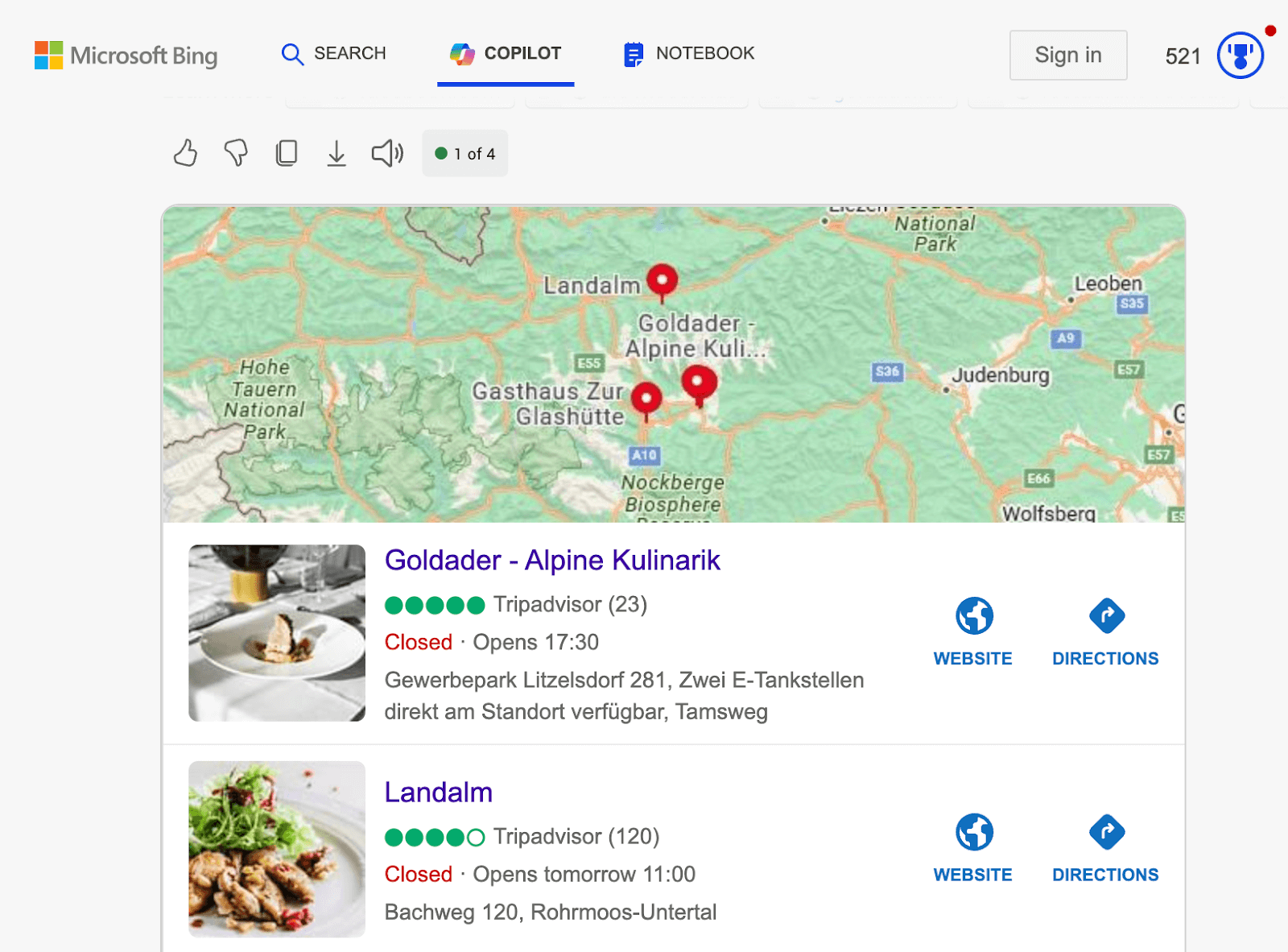
実証的に、上記で見られるように、AI駆動の検索システムは、さまざまな確立された知識ベースと権威あるプラットフォームからデータを取得しています:
- 地図サービス:Google MapsとBing Mapsは、位置情報の重要なデータソースとして機能しています。
- 権威あるウェブサイト:TripAdvisorなどの構造化データマークアップが豊富なプラットフォームは、AI検索システムの知識ベースに大きく貢献しています。
- 業界固有のデータベース:業界固有のデータベースとプラットフォームは、さまざまな分野でAI駆動検索のための専門情報を提供しています。
AI駆動検索への移行とその影響
従来の検索からAI駆動検索へのこの移行は、より広範で洗練された最適化アプローチを要求します:
-
マルチプラットフォーム可視性: SEO戦略は、以下のような多様なAIサーフェスとプラットフォーム全体での可視性を考慮する必要があります:
- 従来の検索エンジン(Google、Bing)
- AIチャットボット(ChatGPT、GoogleのGemini、Perplexity、AnthropicのClaude)
- 統合アシスタント(Microsoft Copilot、Apple-ChatGPT統合の可能性)
- エコシステム固有のツール(Google Workspace、Microsoft 365)
- ブラウザとデバイスレベルの統合
-
従来の最適化を超えて: この状況での成功は、GoogleのAI Overviewなどの特定の機能の最適化を超えています。すべての新興検索インターフェースでコンテンツを発見可能で理解しやすくするための包括的なアプローチが必要です。
-
構造化データの戦略的活用: 可視性の向上の鍵は、スキーママークアップを使用して構造化データを公開するだけでなく、ビジネスやコンテンツにとって重要なエンティティに関する構造化情報へのアクセスを促進することにあります。これには以下が含まれます:
- 明確な構造化情報が利用可能で、さまざまなAIシステムが容易に解釈できることを確保する。
- ボット用のウェブページを説明するメタデータが、人間の読者に提示されるコンテンツと一致していることを確保する。
- 製品やサービスに関する正確な情報を、関連するプラットフォームやマーケットプレイス(例:Google Merchant、Amazon)に直接提供する。
リッチリザルトとナレッジパネル
構造化データによって実現されるリッチリザルトとナレッジパネルは、検索エンジン結果ページ(SERP)の重要な機能です。これらの拡張表示は、ユーザーに即座に関連性の高い情報を提供し、クリック率とユーザーエンゲージメントを大幅に向上させます。リッチリザルトがより多様で洗練されるにつれて、コンテンツの可視性に対する新たな機会が生まれています。Googleからの最近の例として、ローカルビジネス(レストラン、ホテル、バケーション賃貸などのサブタイプを含む)、製品、イベントに関連するリスト記事ページ向けの構造化データカルーセルの導入があります。
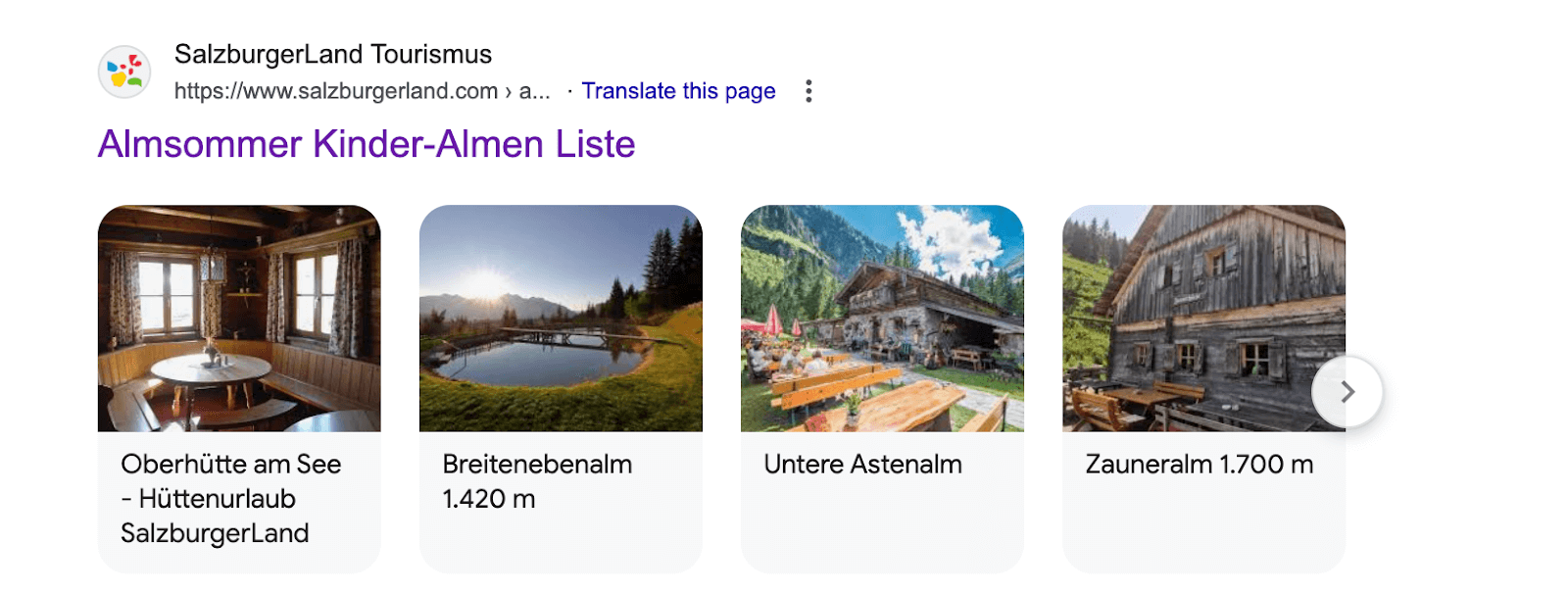
このカルーセル形式は、リスト記事ページの構造化データの表示を強化し、ローカルビジネスや製品などの複数のオプションにSERP上で直接アクセスできるようにします。
構造化データに直接影響されないもう1つの注目すべき例は、新しいGoogle Merchantナレッジパネルです。これは製品ナレッジグラフパネルの機能を拡張します。構造化データは、エンティティの曖昧性解消に貢献するシグナルとして機能し、検索エンジンがビジネスとその属性を正確に識別するのを支援し、これらのパネルの表示につながる可能性があります。この機能は、大小を問わず、ビジネスがGoogleの検索結果ページに直接販売者の重要な情報を表示することで、ユーザーとの信頼関係を構築するのに役立ちます。
ナレッジグラフとGraph RAG
ナレッジグラフは、構造化データアプリケーションにおいてますます中心的な役割を果たすようになり、正確で明示的なトリプル表現を通じて事実情報をカプセル化しています(参照)。これらは、エンティティ間の複雑な関係を表現し、クエリを実行するための強力な方法を提供すると同時に、透明な記号的推論機能を提供します。Graph RAG(Retrieval-Augmented Generation)の出現は、ナレッジグラフと大規模言語モデルを組み合わせて、検証可能な構造化情報でAI生成の応答を強化し、LLMに内在する事実の不整合や不透明性の課題に対処する重要な進展を表しています。
ラベル付きプロパティグラフとRDFグラフの違い
ラベル付きプロパティグラフ(LPGs)とResource Description Framework(RDF)グラフは、データを整理し表現する2つの異なるアプローチです。Neo4jなどのデータベースで一般的に使用されるLPGsは、ノードと関係でデータを構造化し、それぞれがラベルとプロパティを持ちます。これにより、複雑なデータ関係を柔軟で直感的にモデル化できます。一方、セマンティックウェブの基盤となるRDFグラフは、トリプルベースの構造(主語-述語-目的語)を使用してデータを表現します。RDFは相互運用性と標準化を重視し、異なるシステムやドメイン間でデータをリンクするのに理想的です。LPGsが特定のアプリケーションで使いやすさとパフォーマンスを提供する一方、RDFはセマンティックデータの統合と推論のための堅牢なフレームワークを提供します。
ナレッジグラフの作成における構造化データの重要性は、いくら強調してもしすぎることはありません。構造化データは、エンティティとその関係を正確に定義することを可能にし、正確で信頼性の高いナレッジグラフの開発に不可欠です。構造化データを活用することで、組織はデータの発見可能性、相互運用性、AI生成の洞察の全体的な品質を向上させる包括的なナレッジグラフを構築できます。
Data Commons
Data Commonsは、Googleによるオープンソースかつオープンデータのイニシアチブで、国連や各国の国勢調査局など、さまざまなグローバルソースからの公開データセットを整理し、普遍的にアクセス可能にします。このプラットフォームは、2500億以上のデータポイントと2.5兆のトリプルを提供し、幅広い統計変数を網羅しています。Data Commonsでは、Schema.orgを使用して構造化データをエンコードし、多様なデータセットを標準化・正規化する統一されたナレッジグラフを作成し、共通のフレームワークを通じてより簡単なアクセスと探索を可能にします。この構造化されたアプローチは、膨大な量のデータを一貫性のある検索可能なシステムに統合するのに役立ちます。
デジタル製品パスポートとGS1デジタルリンク
eコマースとサプライチェーン分野では、デジタル製品パスポート(DPPs)とGS1 Digital Link標準が、製品情報の共有とアクセス方法に革命をもたらしています。これらの技術は、構造化データを活用して、物理的な製品の包括的で簡単にアクセス可能なデジタル表現を作成し、トレーサビリティ、サステナビリティへの取り組み、消費者情報へのアクセスを向上させています。
AI、機械学習、構造化データ
構造化データとAI/MLの相乗効果は深まっています。構造化データは、機械学習モデルのトレーニングにおいて、一貫性のある機械可読なラベルを提供する上で重要です。とくに以下の分野で重要です:
- 大規模言語モデル(LLMs):特定のドメインでの性能向上のための構造化データによるファインチューニング。
- 説明可能なAI:ナレッジグラフを使用してAIの意思決定プロセスを追跡・説明する。
- マルチモーダルAI:AIシステムで異なるデータタイプ(テキスト、画像、動画)をリンクする。
セマンティックSEOとデータ品質
SEOは、単純なキーワードマッチングを超えて、現在ではセマンティックSEOと呼ばれるものに進化しています。この現代的なアプローチは、構造化データと文脈理解を活用して、検索エンジンがより正確な結果を提供できるようにします。構造化メタデータを実装し、トピック間の関係性に焦点を当てることで、ウェブサイトはコンテンツにより深い意味を構築できます。これにより、GoogleやBingなどの検索エンジンは、単なるキーワードの頻度を数えるだけでなく、ユーザーの意図をよりよく理解できるようになります。
セマンティックSEOを実装することで、企業はトピックに基づいてコンテンツクラスターを作成でき、個々のキーワードだけでなく、音声検索アシスタントを含むさまざまな検索プラットフォームでコンテンツをより発見しやすく、文脈的に関連性の高いものにできます。この手法は、構造化データにより検索エンジンがコンテンツをより詳細なレベルで理解し、ユーザーの意図とのマッチングを容易にすることで、検索エンジンのランキングとユーザーエンゲージメントを大幅に向上させます。
データ品質もここで重要な役割を果たします。高品質な構造化データは、検索エンジンだけでなく、誤情報との戦いにおいても重要な一貫性と正確性を確保します。これは、構造化データが事実の検証やLLMのトレーニング強化などのAI駆動システムでますます使用されるようになるにつれて、ウェブ全体での信頼性を維持するのに役立ちます。
たとえば、EssilorLuxottica、L’Oréal、Wallmart、Shiseidoなどの組織は、ナレッジグラフなどのセマンティックテクノロジーを使用してコンテンツをリンクし、ユーザーにより詳細で文脈的に関連性の高い結果を提供しています。この実践は、AI駆動のコンテンツ発見を支援し、PerplexityやYou.comなどの生成検索を通じてコンテンツをより簡単に取得できるようにします。
セマンティックSEOに投資し、高品質な構造化データを維持することは、検索での可視性を向上させるだけでなく、AI駆動の発見のためのコンテンツの将来性を確保する基盤を築きます。
1年の振り返り
構造化データの実装状況は進化し続けています。この状況をよりよく理解するために、 構文/エンコーディング と 語彙 を区別することが重要です:
-
構文/エンコーディング: これらはウェブページに構造化データを埋め込む方法を定義します:
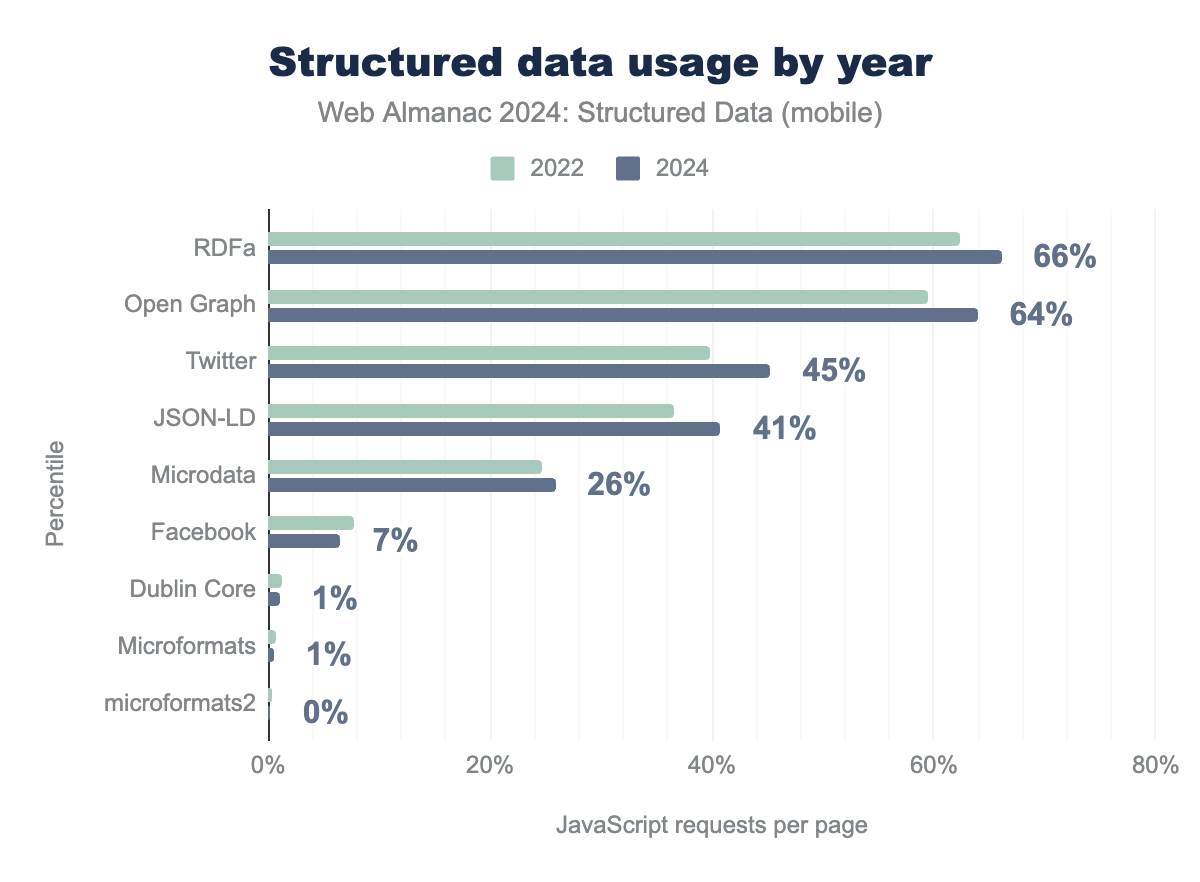
- RDFa: 強い存在感を維持し、66% のページで使用されています。
- JSON-LD: 人気が高まっており、41% のページで実装されています。
- Microdata: 安定した使用率で、26% のページで使用されています。
- HEAD データ: Twitter Cards のような非 RDFa メタタグを含みます。
-
ボキャブラリー: これらはデータの意味とセマンティクスを定義します:
- Open Graph Protocol (OGP): 広く使用されているボキャブラリーで、多くの場合 RDFa としてエンコードされています(64% のページ)。
- Twitter メタタグ: 急速に拡大し、45% のページで使用されています。
- Schema.org: 複数の構文で使用される柔軟なボキャブラリーです。
- Dublin Core: ニッチなユースケースで、通常 RDFa としてエンコードされます。
- Microformats: 主にクラスベースのメタデータとして実装されています。
構造化データの使用トレンド(2022-2024年)
データは構文と語彙の使用において注目すべきトレンドを示しています:
- RDFaとOpen Graph: 支配的で、それぞれ66%と64%のページで採用されています。
- JSON-LD: 上昇傾向を続け、2022年の34%から2024年には41%に増加しました。
- Twitterメタタグ(HEADデータ): 大幅な成長を見せ、現在45%に達しています。
- Microdata: 26%で安定しており、主にレガシーコンテキストで使用されています。
- Facebookメタタグ: 7%に減少し、Open Graphへの移行を反映しています。
- Dublin CoreとMicroformats: 最小限の使用で、それぞれ1%未満です。
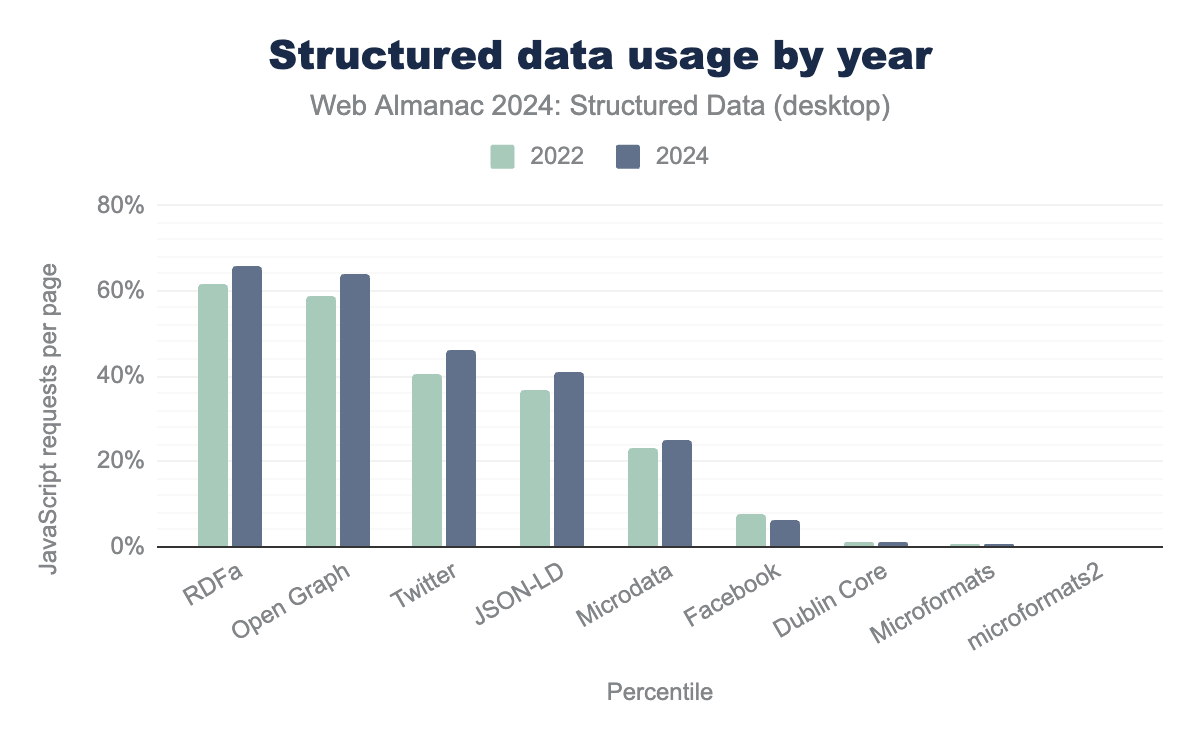
デスクトップとモバイルの実装におけるプラットフォームの差異は減少しており、デバイス間での標準化された構造化データ戦略への移行を示唆しています。この傾向は、検索エンジンとAIシステムがコンテンツの理解と表示を向上させるために構造化データへの依存度を高めていることと一致しています。
JSON-LD、Microdata、RDFaの使用状況の比較
3つの主要な構造化データ形式は、それぞれ異なる採用パターンを示しています:
- RDFa: もっとも高い採用率で、全ページの66%で使用されています。レガシーCMSプラットフォームで広く使用されており、主な実装例は以下の通りです:ナビゲーション要素(パンくずリスト)、基本的なページ構造、画像とドキュメントのメタデータ、リスト項目
- JSON-LD: 全ページの41%で使用されています(2022年の34%から増加)。3つの形式の中で最も急速に成長しており、Googleが推奨し、開発者の採用も広がっています。主に以下の用途で使用されています:組織データ、ローカルビジネス情報、製品リスト、記事やクリエイティブ作品
- Microdata: 全ページの26%で使用されています。安定した成長を見せていますが、速度は遅めです。主に以下の用途で使用されています:ウェブページ構造(8.34%のページ)、サイトナビゲーション(6.42%)、ヘッダーとフッター(5.97%と5.33%)、組織情報(4.87%)
各タイプについて、より詳細に分析してみましょう。
RDFa
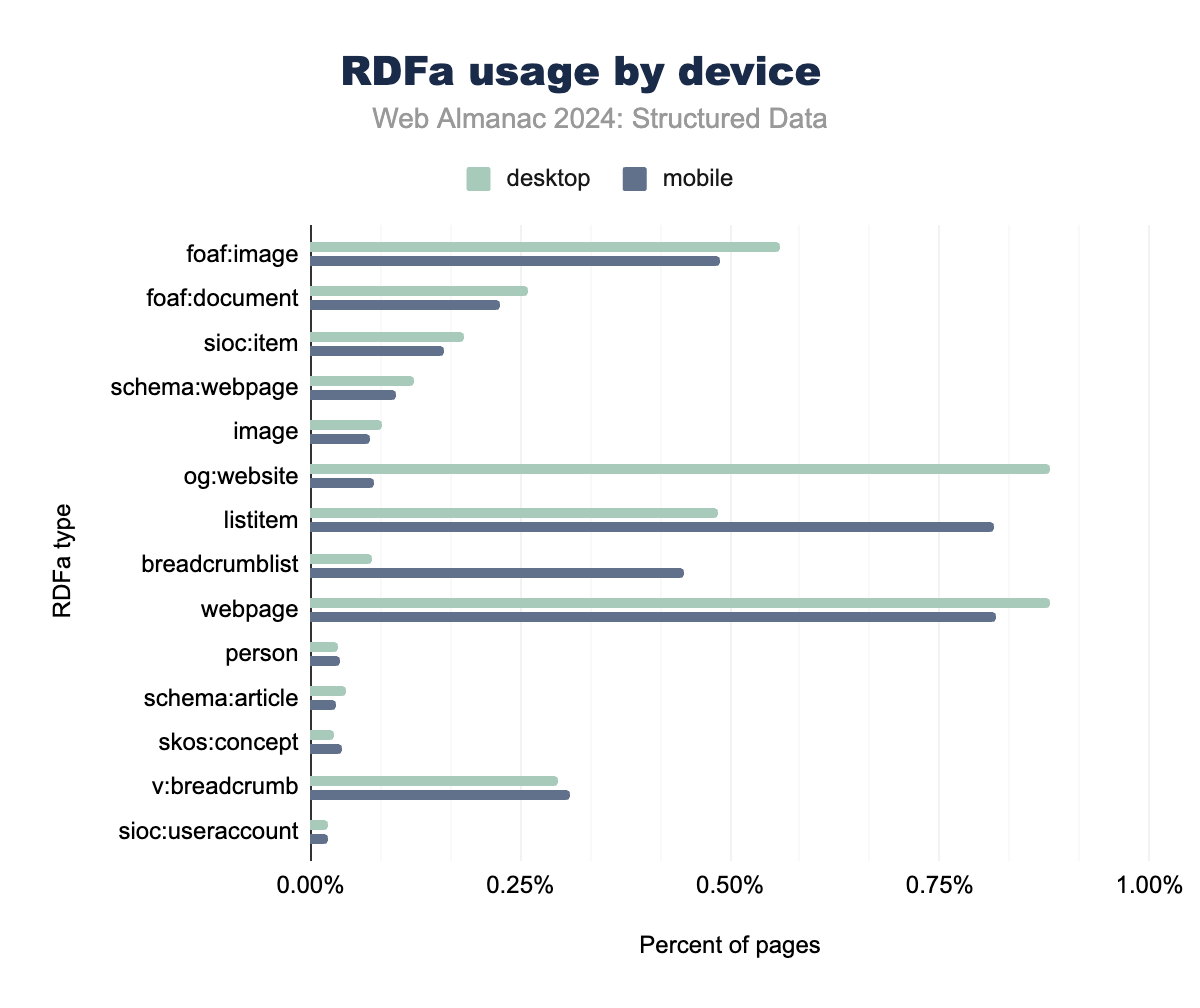
RDFaは、とくにレガシーCMSプラットフォーム内で、構造化データにおいて重要な役割を果たし続けています。しかし、listitemやbreadcrumblistなどのナビゲーション要素にRDFaを使用する傾向が顕著に増加しており、現在では多くのウェブページで一般的になっています。これは、とくにモバイルプラットフォームでのユーザー体験向上のために、構造化されたナビゲーションデータを強化することに業界全体が重点を置いていることを反映しています。
対照的に、foaf:imageやfoaf:documentなどの従来のRDFaタイプの使用は減少傾向にあります。これは、JSON-LDやOpen Graphなどの新しい形式が、画像やドキュメントのメタデータに対してより柔軟なソリューションを提供しているためです。RDFa内でのschema:webpageなどのSchema.orgタイプの採用は控えめながらも安定した成長を示しており、Schema.org語彙への移行がさらに進んでいることを示しています。
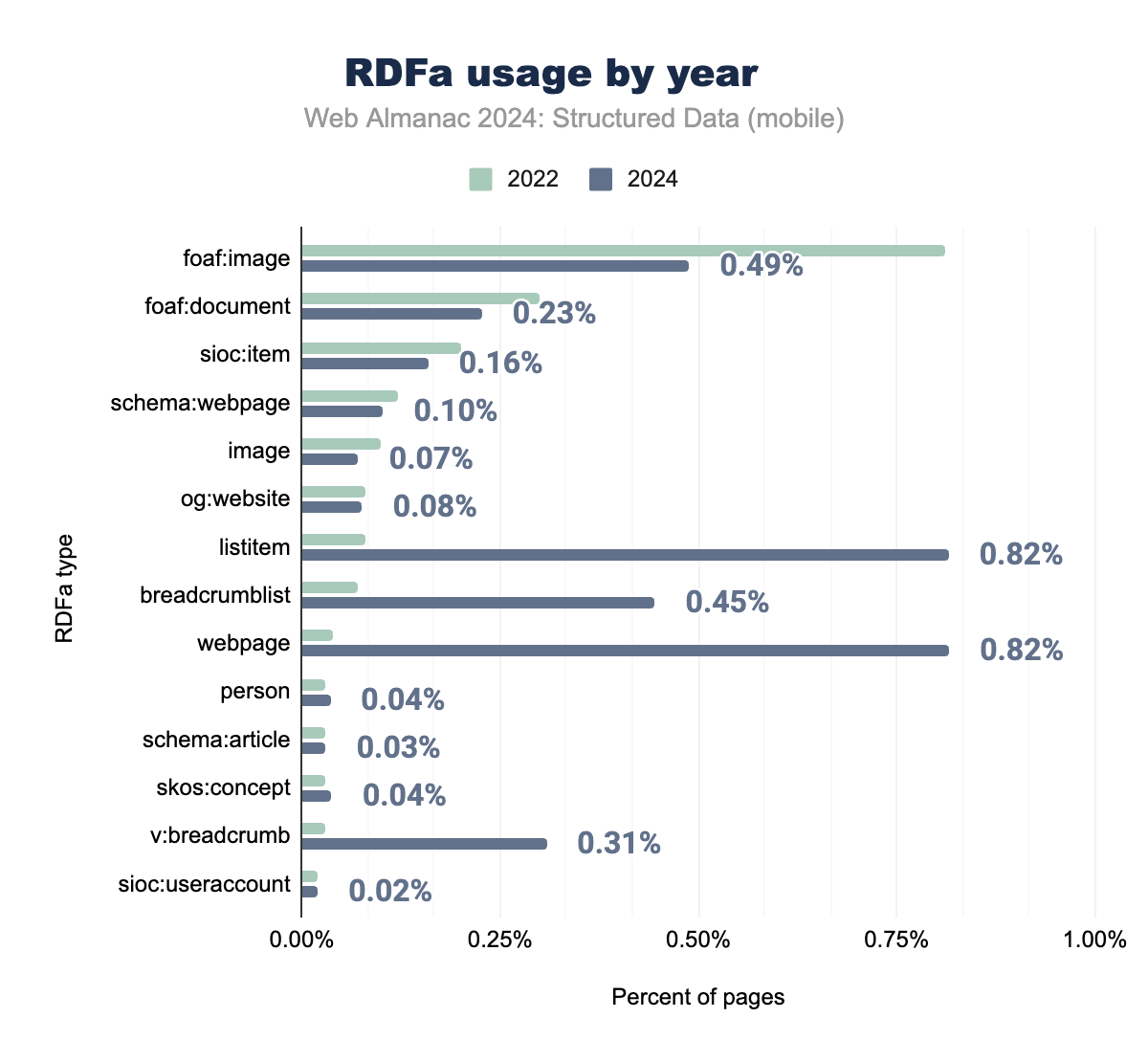
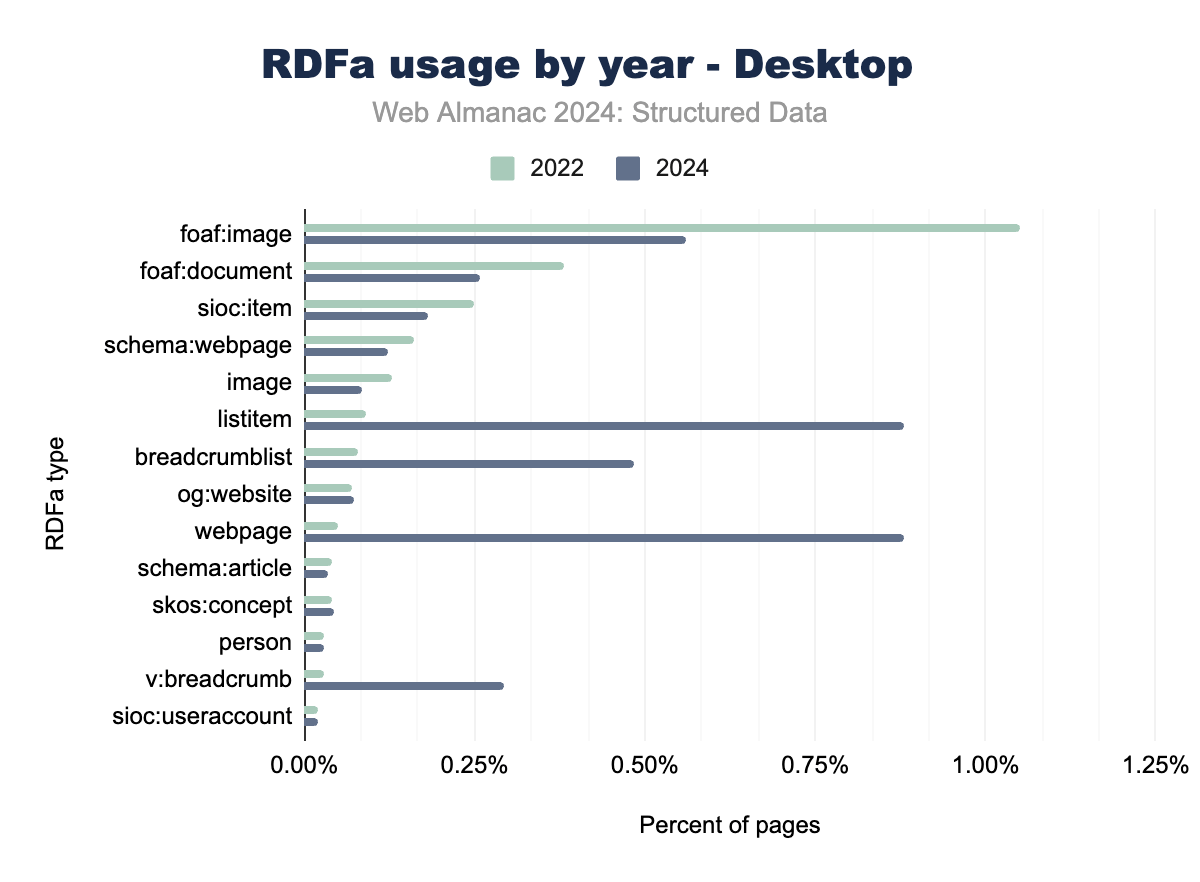
データは、RDFaが依然として有用なツールである一方で、とくに動的コンテンツアプリケーションにおいて、JSON-LDなどの現代的な構造化データ形式に徐々に取って代わられていることを示唆しています。
Dublin Core
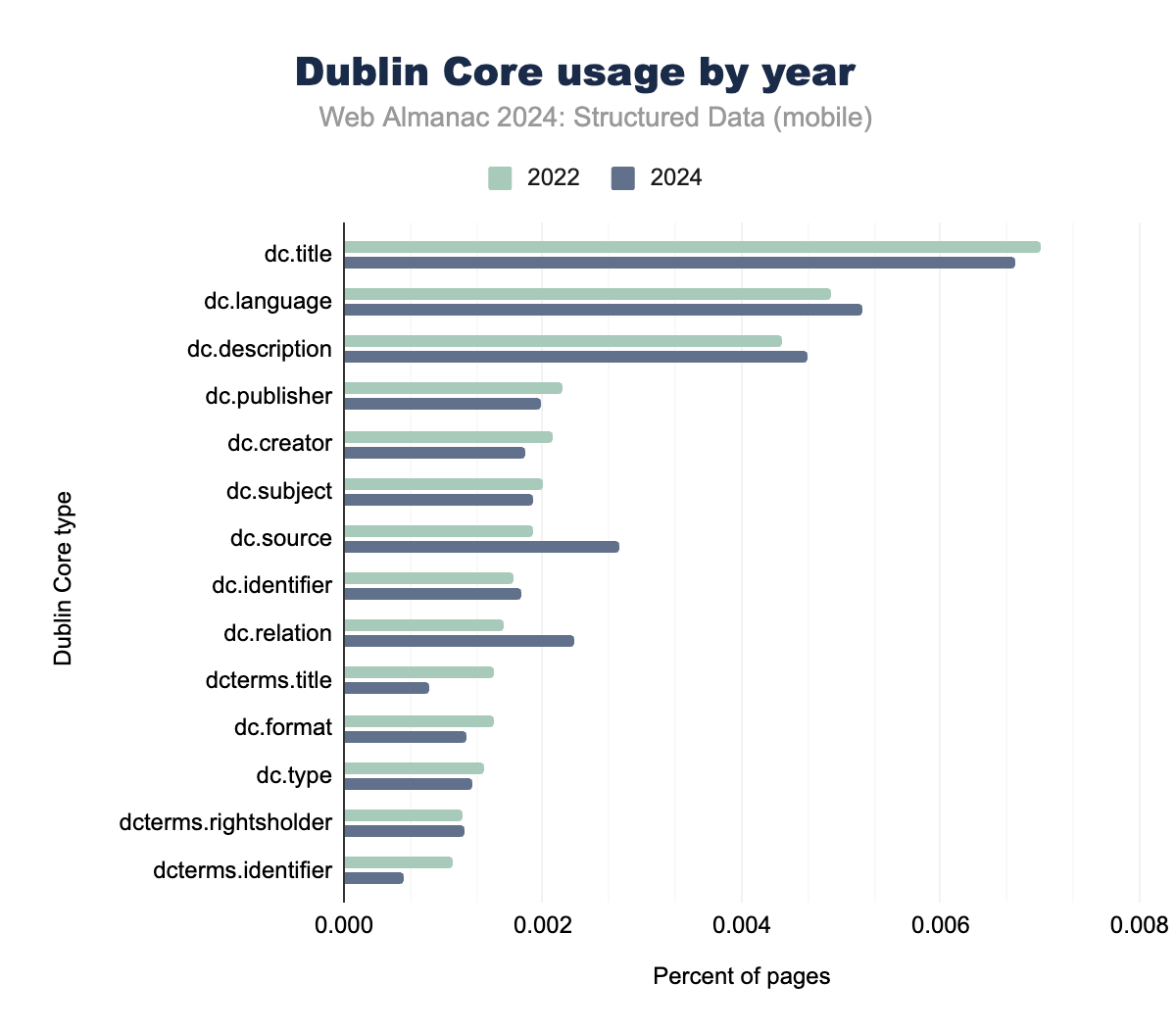

Dublin Coreは、とくにJSON-LDやOpen Graphなどの現代的な形式と比較すると、使用頻度は低いものの、安定したメタデータ形式として存在し続けています。
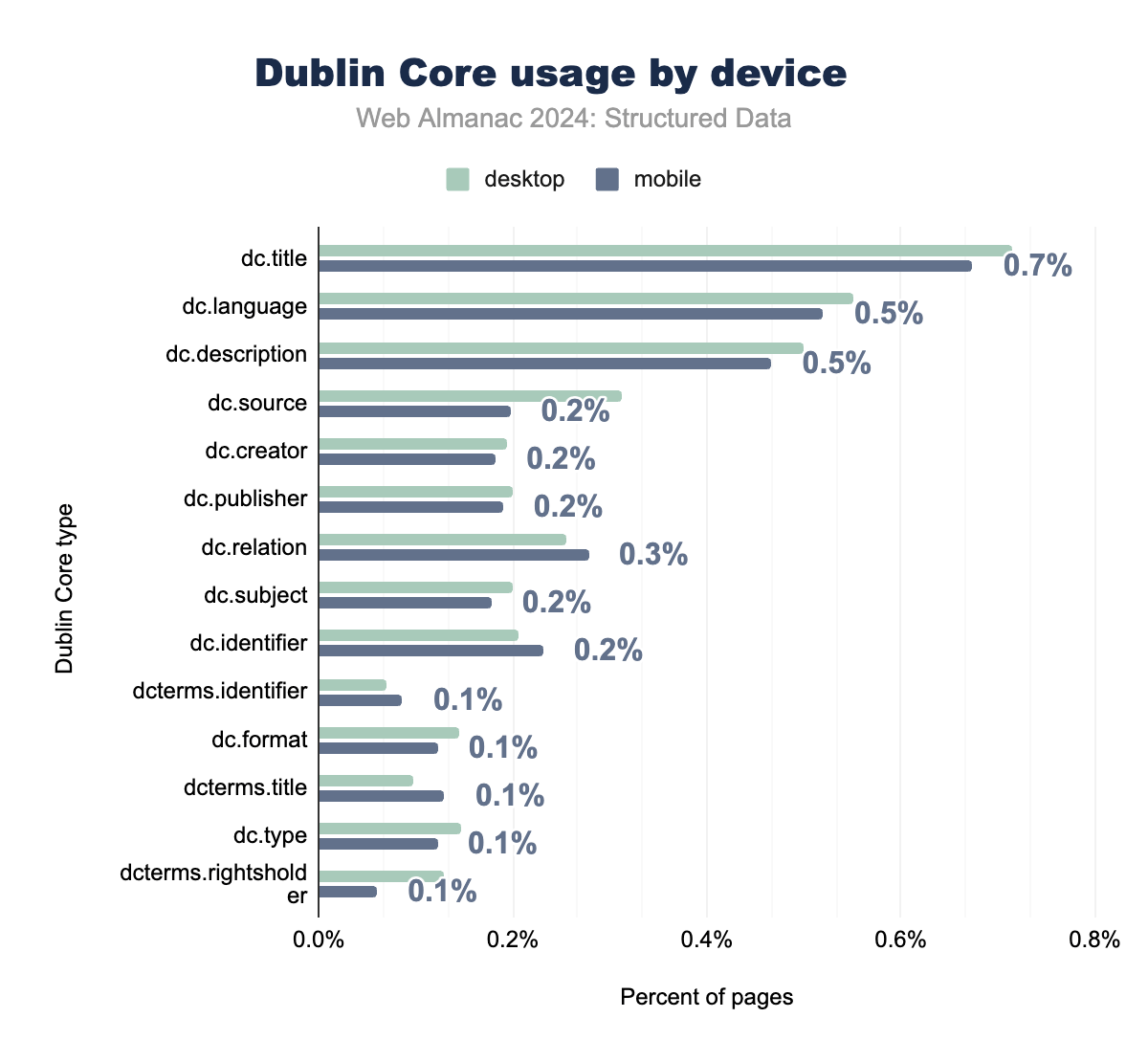
dc.titleやdc.languageなどの主要なフィールドは、年ごとの変化が最小限で、主に学術的およびレガシーなウェブプロジェクトで一貫した存在感を維持しています。
dc.sourceの使用の増加は、元のソースの引用に対する重視の高まりを反映しており、dc.identifierなどのフィールドは依然としてリソース識別に重要です。しかし、dcterms.identifierなどの専門的なフィールドの採用率は低下しており、Dublin Coreが今日のウェブ環境で中心的な役割を果たしていないことを示しています。
興味深いことに、Dublin Coreは多言語ドキュメント管理において、とくにdc.languageフィールドを通じて関連性を維持しています。このフィールドは、複数の言語でのコンテンツの管理と分類に不可欠であり、ドキュメントメタデータが国際化とローカライゼーションの取り組みをサポートする必要がある文脈で貴重なツールとなっています。
全体として、Dublin CoreはJSON-LDなどのより多機能な形式に徐々に取って代わられていますが、構造化されたドキュメントメタデータと多言語サポートが重要なニッチなニーズに対応し続けています。
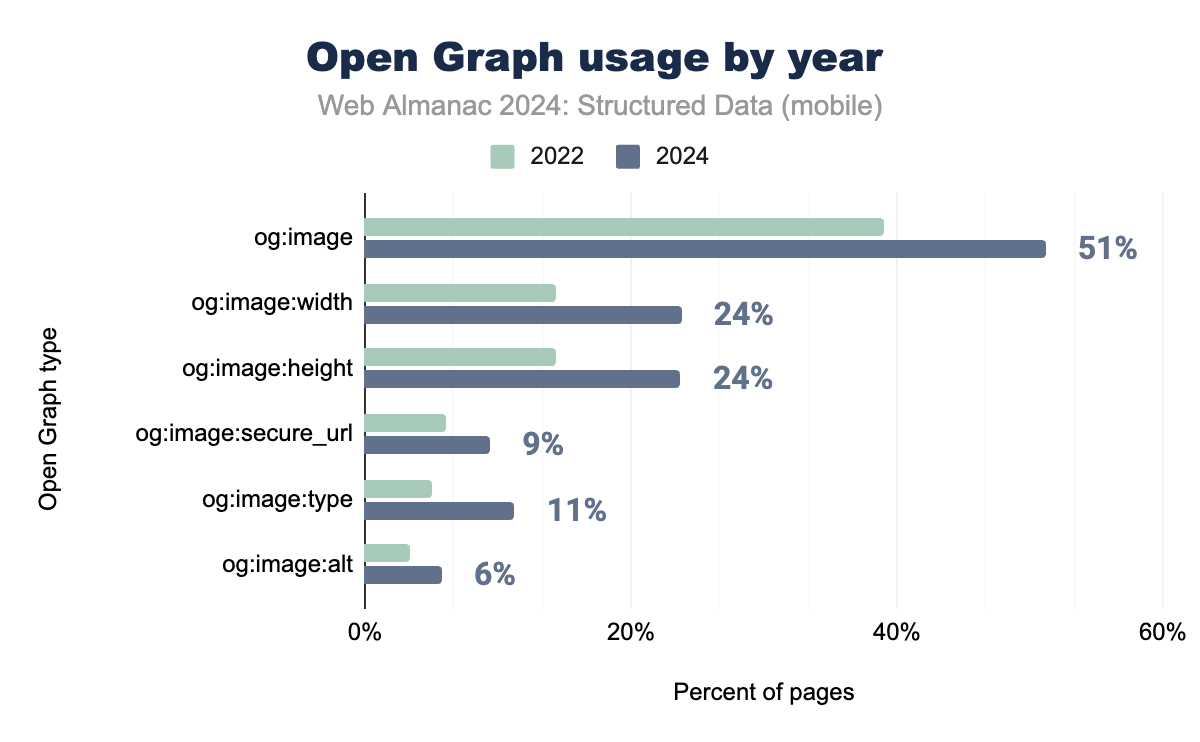
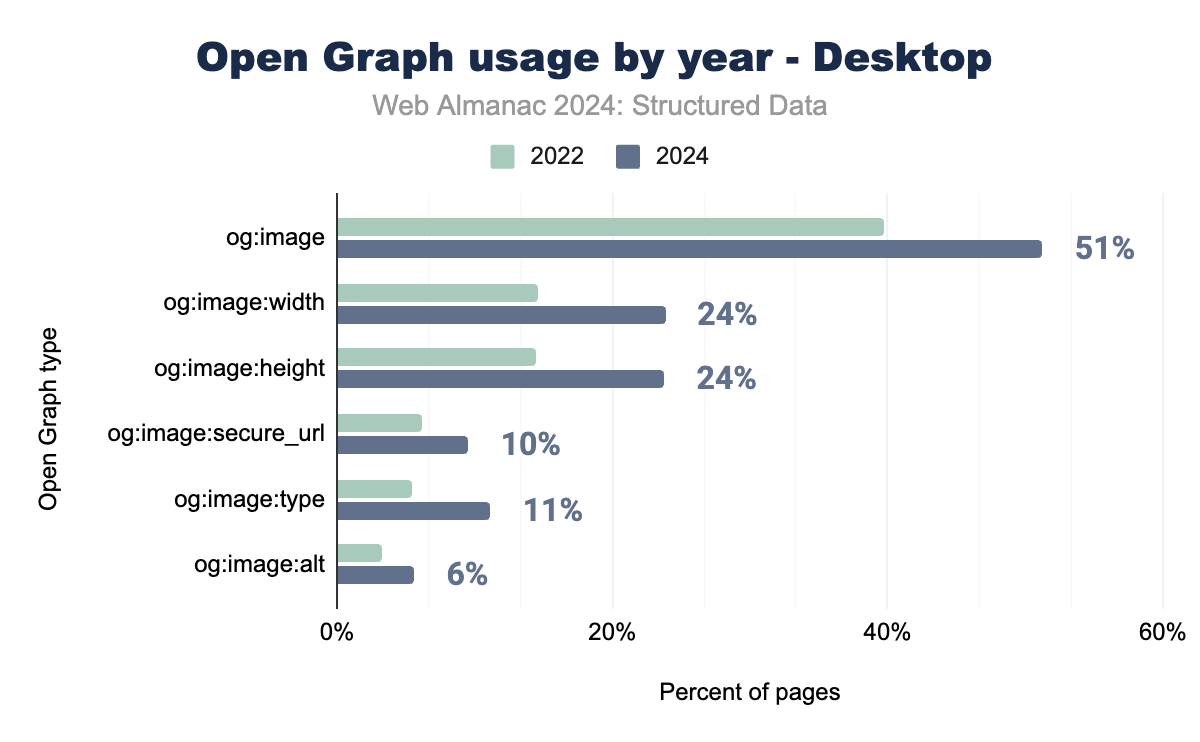
Open Graph
Open Graphは、とくにソーシャルメディア共有の文脈で、もっとも広く実装されている構造化データ形式の1つとして存在し続けています。og:imageタグは依然としてもっとも頻繁に使用されるプロパティであり、ビジュアルコンテンツの最適化に対する重視の高まりを反映しています。og:image:widthやog:image:heightなどの画像関連タグも、ウェブサイトがプラットフォーム間での共有コンテンツの表示を向上させようとする中で、着実な採用率の増加を見せています。
2024年の重要な進展として、Googleが検索ドキュメントを更新し、og:titleメタタグを検索結果でのタイトルリンク生成のソースとして含めるようになりました。この更新により、GoogleはHTMLの<title>タグなどの従来のソースとともにog:titleタグを考慮して、検索結果でのクリック可能なタイトルの表示方法を決定できるようになりました。その結果、og:titleタグは、ソーシャルメディアでの可視性だけでなく、SEOにおいても新たな重要性を獲得しました。
Open Graphのソーシャル共有と検索エンジン最適化におけるこの二重の役割は、ソーシャルプラットフォームでのユーザーエンゲージメントと検索結果での可視性の両方を向上させようとするウェブマスターにとって重要なツールとなっています。
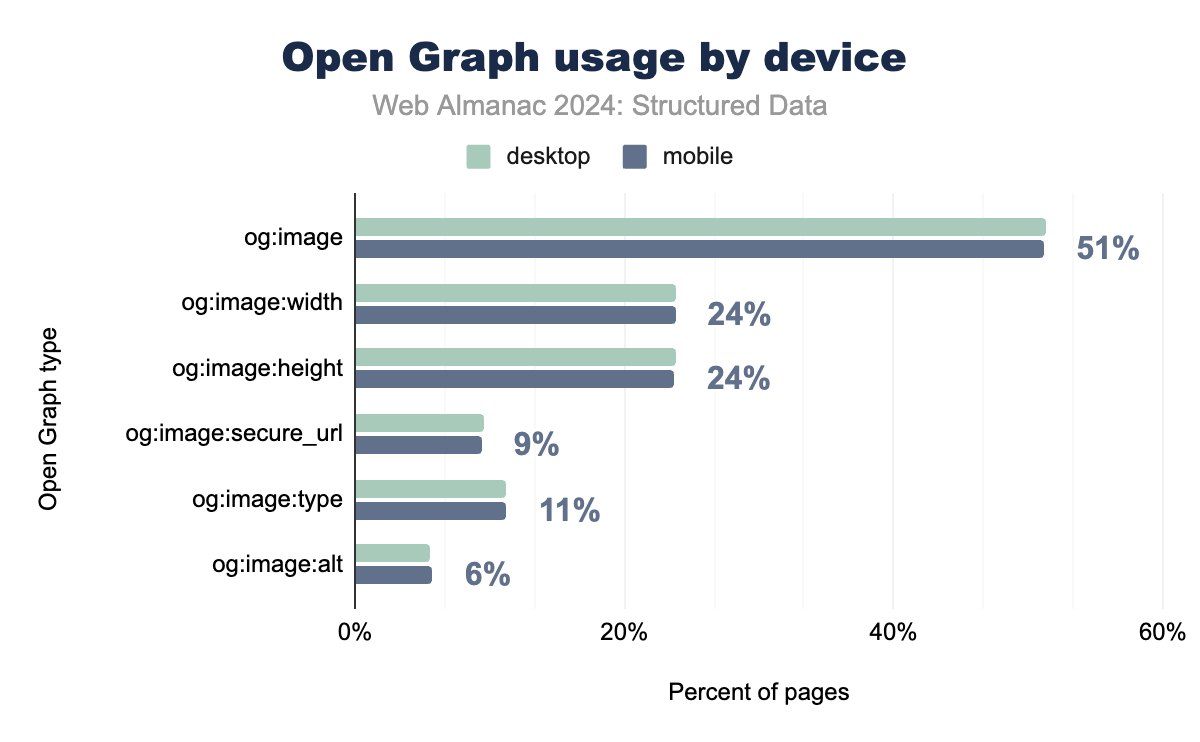
セキュリティとタイプ関連のプロパティも採用が進んでいます。画像URLが安全なHTTPS接続で提供されることを保証するog:image:secure_urlプロパティは、モバイルで9.41%、デスクトップで9.56%に増加しました。同様に、画像のMIMEタイプを指定するog:image:typeは、モバイルで11.26%、デスクトップで11.17%に成長しました。これらのプロパティは、デバイスやプラットフォーム間での一貫した安全なメディア配信を確保するのに役立っています。
プラットフォームが新しい所有者に移行し、Xとして再ブランディングされたにもかかわらず、Twitterのメタタグは構造化データの分野、とくにソーシャルメディア最適化の領域で重要な役割を果たし続けています。 twitter:card タグは、コンテンツがプラットフォームで共有された際の表示方法を定義する重要な役割を担っており、モバイルとデスクトップの両方のページで大幅な成長を示しています。
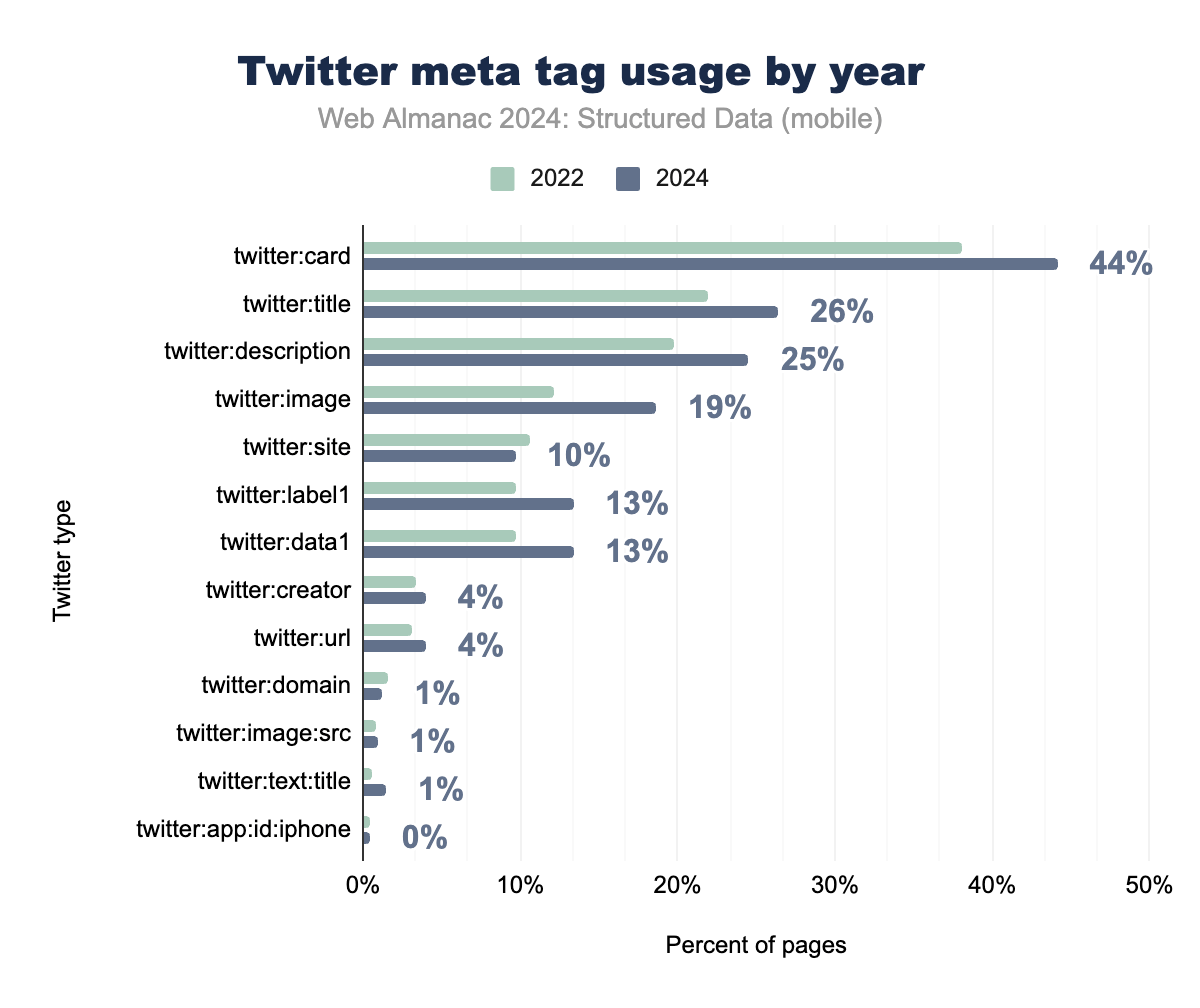
twitter:title や twitter:description などの基本的な説明タグも広く採用されており、モバイルページの約26%、デスクトップページの約24%に表示されています。これらのタグは、コンテンツのプレビュー、ソーシャルメディアで共有された際のウェブページの表示方法の向上、重要な情報の強調表示に不可欠です。
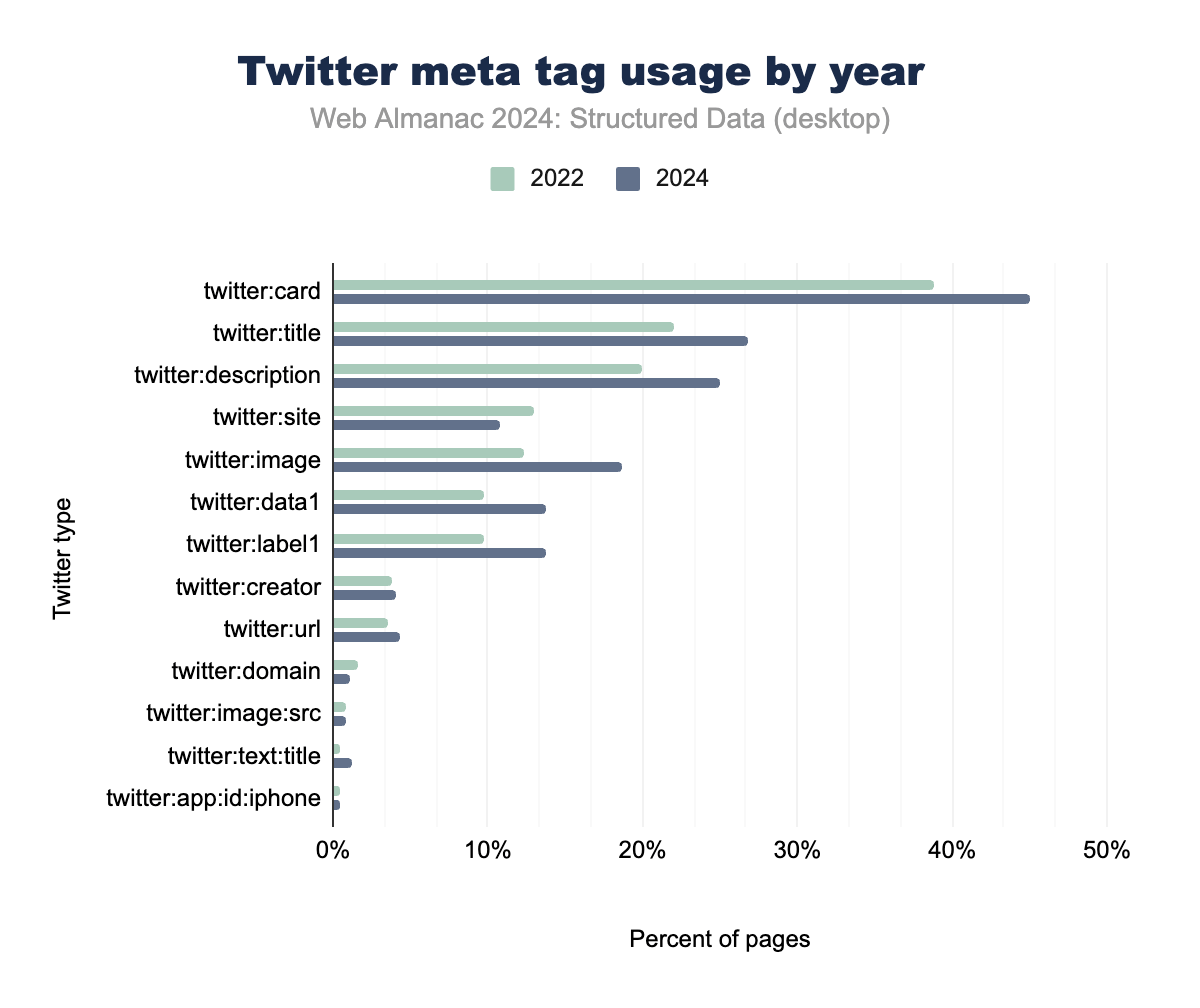

twitter:data1 や twitter:label1 などの拡張メタデータプロパティは、リッチカード機能をサポートしており、モバイルページの13.36%で使用されています。これは、商品リストやイベント詳細など、より詳細なコンテンツ表現のためにTwitter Cardsが増加していることを示しています。
Xは大きなブランディング変更を経ましたが、導入したメタデータアーキテクチャは、ウェブマスターやSEO専門家にとって依然として重要です。ソーシャルメディアで共有されるコンテンツが魅力的で情報豊富、かつインタラクションに最適化されることを保証しています。これは、ソーシャルメディアとメタデータのエコシステムにおけるプラットフォームの持続的な重要性を強調しています。
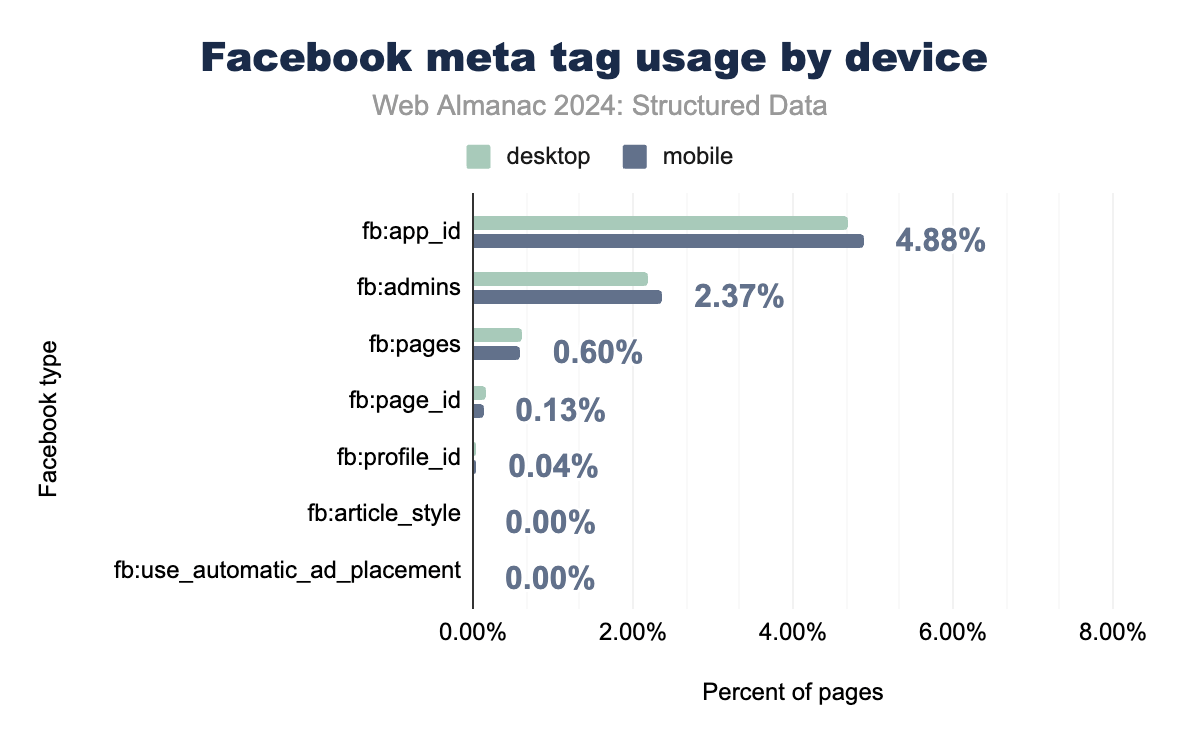
2022年から2024年にかけて、Facebook固有のメタタグの使用率は顕著に減少しています。これは、ソーシャル共有のメタデータ形式として Open Graph が業界全体で標準として採用されるようになったことを反映しています。Facebookプラットフォームとアプリを統合するためにかつて広く使用されていた fb:app_id タグは、現在ではモバイルページの4.9%にしか出現しなくなりました。同様に、fb:admins などの管理タグも2.4%まで減少し、コンテンツの可視性向上よりもバックエンド管理のために主に使用されています。
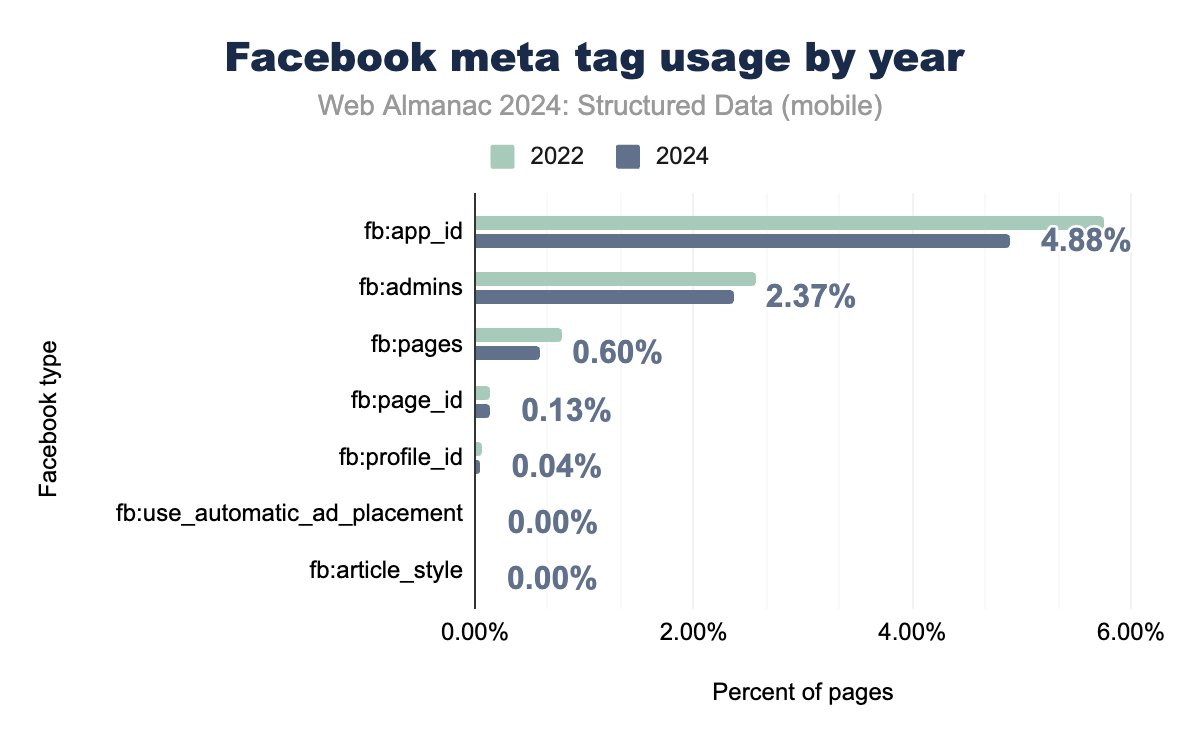
この減少は、開発者とウェブマスターがOpen Graphを採用するという戦略的な動きを強調しています。Open GraphはFacebookで生まれましたが、その後プラットフォームを超えたソーシャルメディア共有の標準となりました。Open Graphフォーマットは、より高い柔軟性と相互運用性を提供し、Facebookだけでなく他のソーシャルネットワークでもコンテンツ最適化の第一選択肢となっています。

Facebook固有のタグの採用率は低下しているものの、Facebook自体はソーシャルメディアの重要なプレイヤーであり、Open Graphがメタデータのニーズの大部分を処理しています。この傾向は、プラットフォームに依存しないタグがより広範な到達範囲と機能を提供する、ソーシャル共有標準の統合を反映しています。
MicroformatsとMicroformats2
Microformatsは、シンプルなセマンティックデータが必要とされるニッチなユースケースで、限定的な採用にとどまっています。住所関連データに使用される adr タグは、モバイルとデスクトップの両プラットフォームで約0.4%のページに表示され、もっとも広く採用されているMicroformatsタイプとなっています。geo や hReview などの他のタグは、JSON-LDやOpen Graphなどのより洗練されたフォーマットが普及するにつれて、使用率が最小限となっています。
Microformats2は、依然として比較的ニッチな存在ですが、前身よりも若干高い採用率を示しています。ブログや個人の身元データに使用される h-entry や h-card などのタグは、現在モバイルページの0.22%、デスクトップページの0.15%に表示されています。これらのタグは、とくに住所データやシンプルなコンテンツ構造に対して、特定のニーズに対応し続けています。


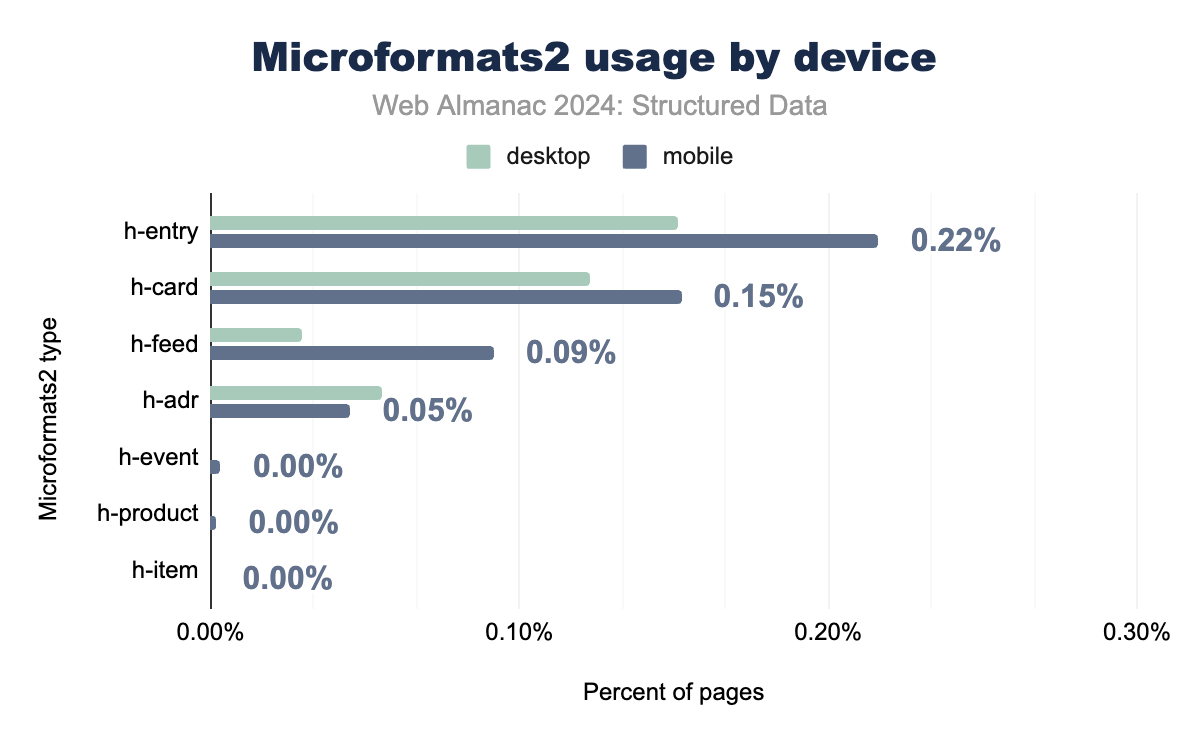

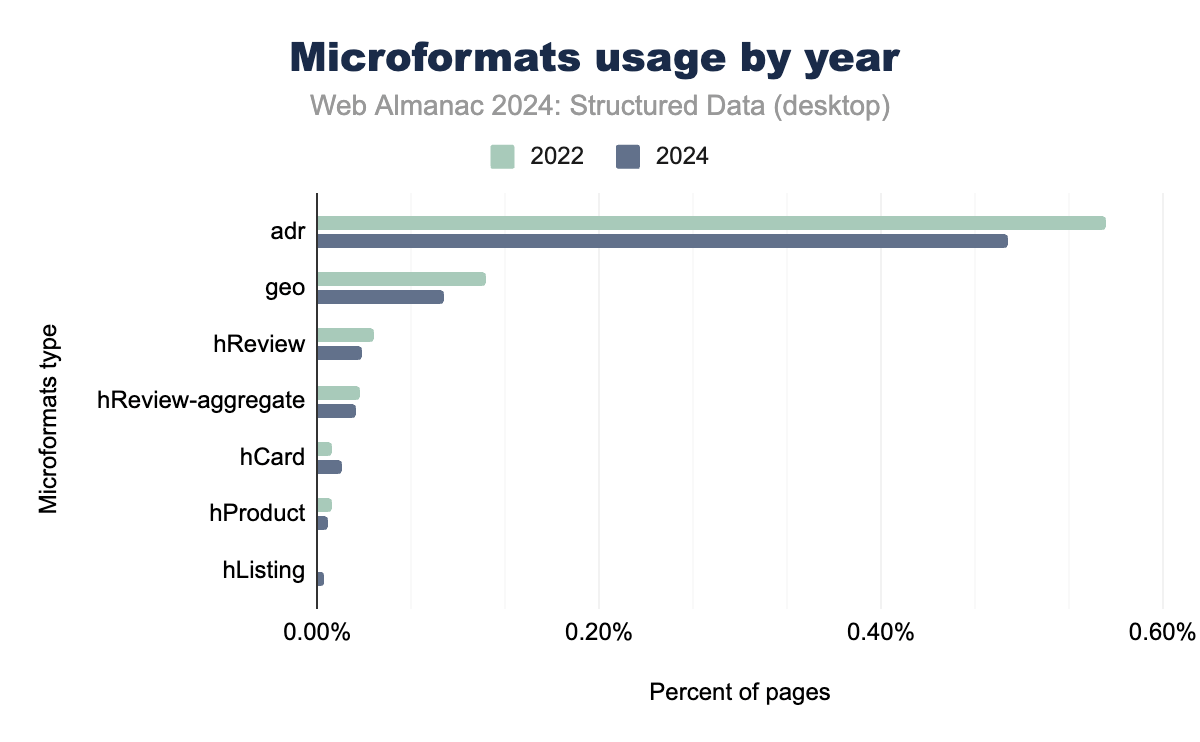
デバイス間の実装は比較的一貫性を保っていますが、モバイルとデスクトップの間で若干の差異が見られます。データは、2022年から2024年にかけて、とくに hReview や hReview-aggregate などのレビュー関連プロパティで、従来のMicroformatsの使用率が全体的に低下していることを示しています。この低下は、より広範な機能と現在のウェブ標準とのより良い統合を提供するJSON-LDやRDFaなどのより現代的な構造化データフォーマットへの業界の移行を反映しています。
この低下にもかかわらず、MicroformatsとMicroformats2は、軽量で人間が読みやすいセマンティックデータが必要とされる特定の文脈で有用であり続けています。しかし、全体的な存在感は、構造化データの分野を支配するJSON-LDなどのより多機能なフォーマットによって、依然として覆い隠されています。

Microdata
Microdataは、構造要素とナビゲーションデータに対して広く使用され続けており、とくにシンプルな静的ページ構造が必要とされるレガシープラットフォームやサイトで顕著です。もっとも頻繁に実装されるタイプには、モバイルページの8.34%に表示される schema.org/webpage と、モバイルページの6.42%で使用される schema.org/sitenavigationelement が含まれており、ウェブページ構造とサイトナビゲーションにおけるこのフォーマットの持続的な関連性を示しています。
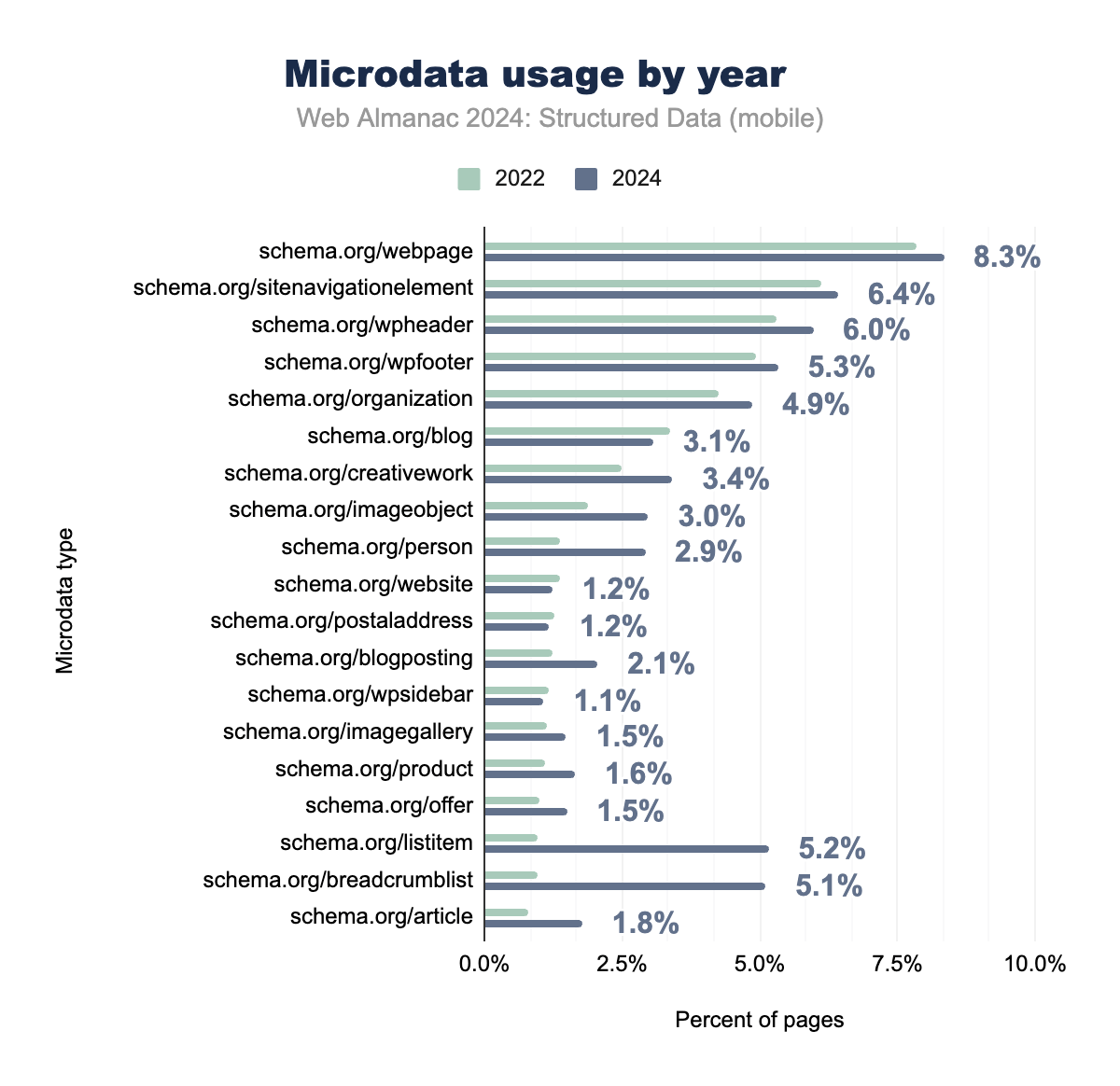
listitem や breadcrumblist などのナビゲーション関連タイプも着実な成長を見せており、とくにモバイルデバイスでの、より整理された構造化されたナビゲーションデータの必要性を反映しています。しかし、schema.org/article や schema.org/product などのコンテンツ固有のタイプは、開発者がより柔軟でスケーラブルな実装のためにJSON-LDに移行するにつれて、それぞれ1.77%と1.50%の採用率にとどまっています。
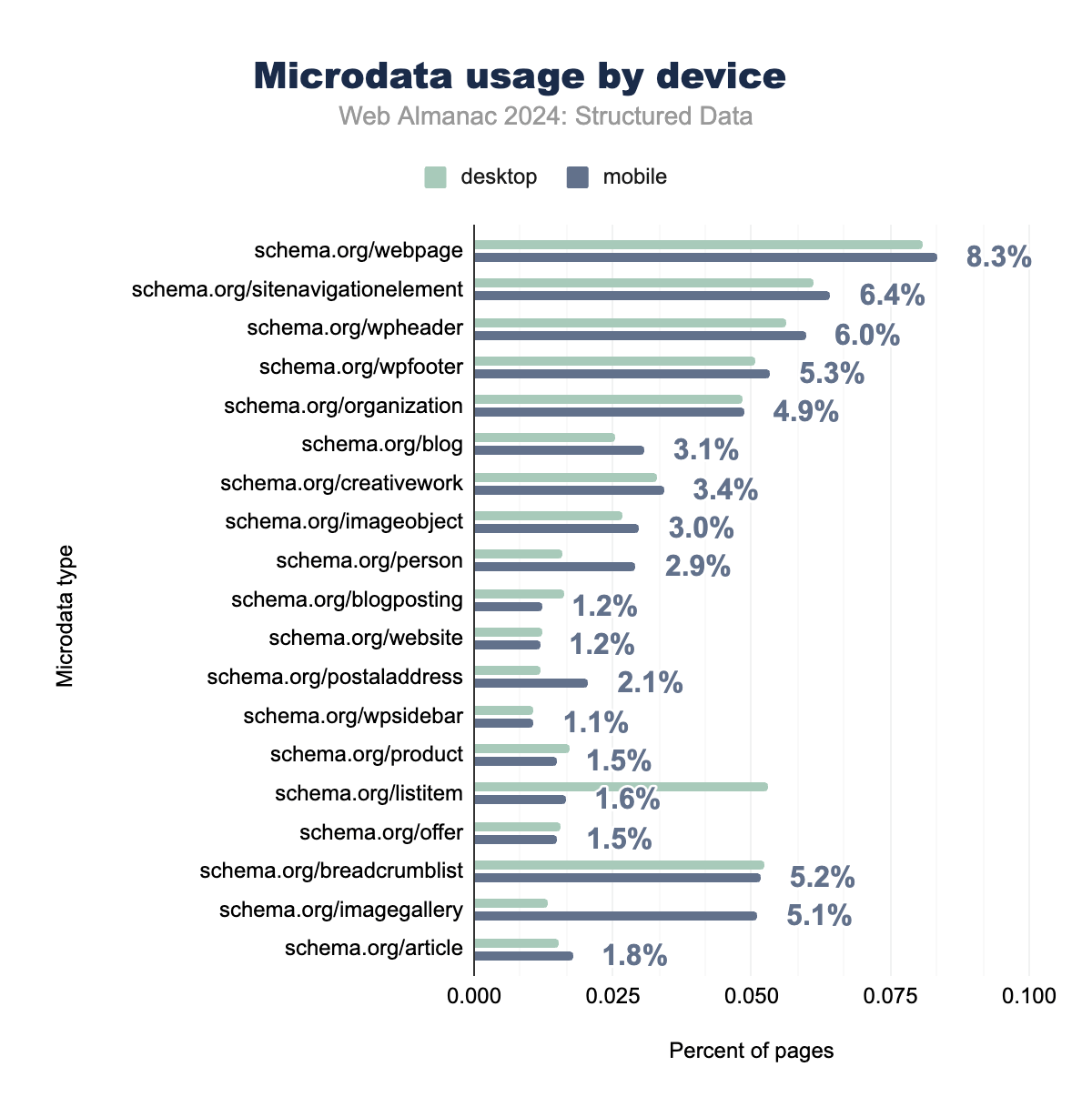
Microdataは基本的なウェブページ構造にとって重要なフォーマットであり続けていますが、動的コンテンツやeコマースアプリケーションでの使用は、大規模なウェブサイト全体でのコンテンツの充実と構造化データのスケーリングに対するより広範なサポートを提供するJSON-LDなどのより現代的なフォーマットに徐々に取って代わられています。
JSON-LD
JSON-LDタイプは、サイトの目的に応じてさまざまなデータタイプが使用され、ウェブサイト全体で広く実装され続けています。WebSiteスキーマが採用率をリードしており、モバイルページの12.73%に表示され、次いでOrganizationとLocalBusinessタイプがそれぞれ7.16%と3.97%となっています。これらのタイプは、エンティティの識別を確立し、検索エンジンに文脈情報を提供するために重要です。
実装パターンの多様性は、異なる業界やウェブサイトタイプが特定の構造化データをどのように優先しているかを反映しています。たとえば:
- eコマースサイトは、
Product、Offer、Reviewスキーマを頻繁に実装しています。 - ローカルビジネスは、ローカル検索の可視性を高めるために、
LocalBusiness、GeoCoordinates、OpeningHoursSpecificationを優先しています。 - コンテンツパブリッシャーは、書かれたコンテンツを効果的に構造化するために、
ArticleとBlogPostingスキーマをよく使用しています。
BreadcrumbListの実装は、ページの5.66%に表示され、構造化されたナビゲーションデータへの注目が高まっていることを示しています。WebPageスキーマは1.49%で安定した採用を見せており、Productスキーマはページの0.77%に表示されています。BlogPosting(1.40%)やArticle(0.18%)などのコンテンツ固有のタイプは、低いレベルではありますが、一貫した存在感を維持しています。
Restaurant(0.19%)、AutoDealer(1.09%)、Store(0.17%)などの専門的なビジネスタイプは、Googleのこれらのスキーマに対するサポートの増加に対応して、業界固有のマークアップの採用が増加していることを示しています。VideoObject、FAQPage、Eventなどのサポートコンテンツタイプは、それぞれ約0.34%のページに表示されており、専門的なコンテンツマークアップの着実ではあるが控えめな実装を示しています。
ItemListスキーマは2.44%の健全な採用率を示しており、構造化されたリストデータの使用が増加していることを示唆しています。JSON-LDタイプの全体的な分布は、基本的なエンティティタイプが支配的でありながら、専門的なスキーマが特定のビジネスとコンテンツのニーズに対応する成熟したエコシステムを反映しています。
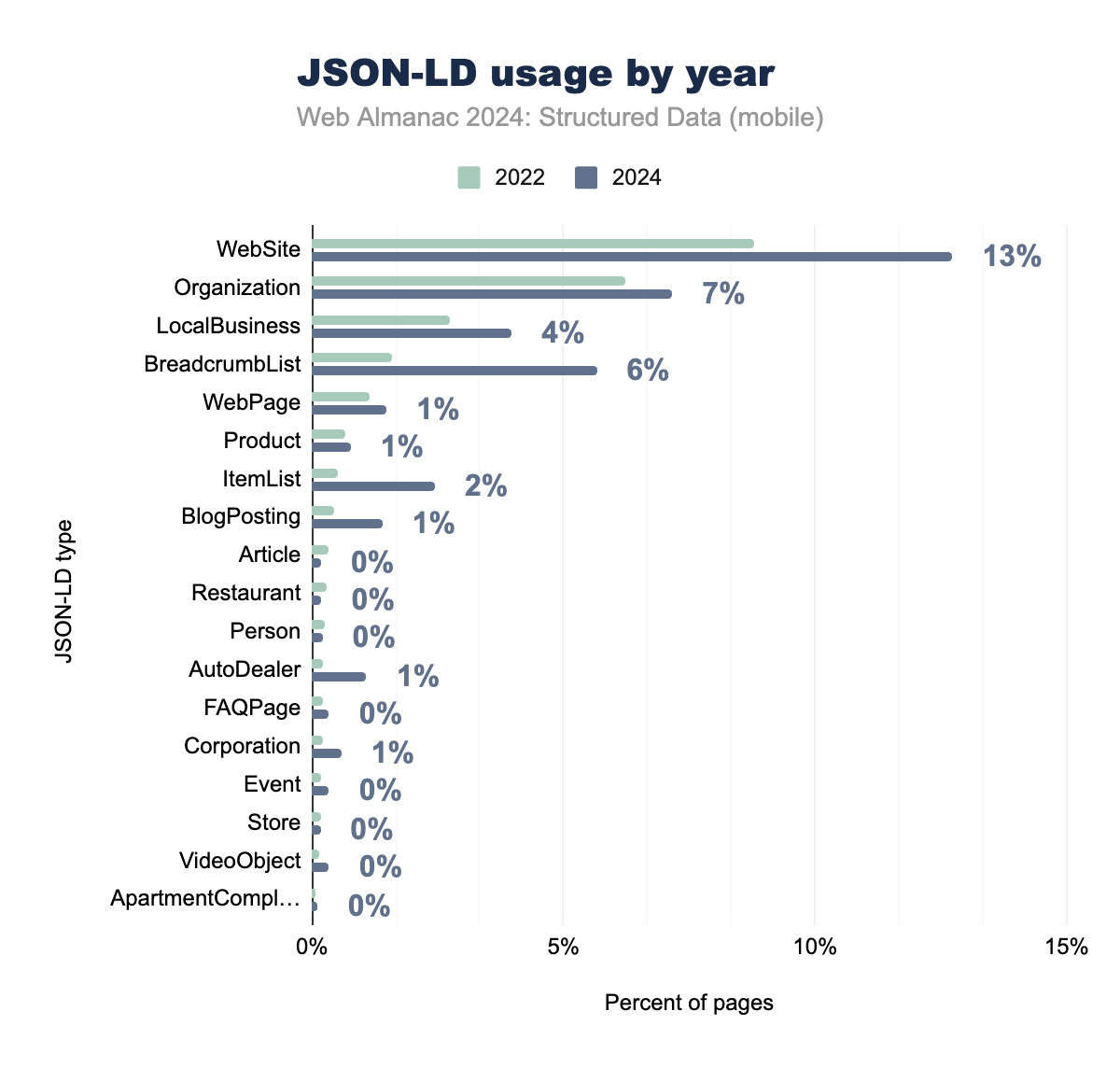
デバイス間での実装の一貫性は、開発者がターゲットプラットフォームに関係なく均一なマークアップを確保している、構造化データの展開に対する成熟したアプローチを示しています。モバイルとデスクトップの実装のこの整合性は、組織がレスポンシブデザインのベストプラクティスに従いながら、すべてのユーザーエクスペリエンスで一貫した構造化データを維持していることを示唆しています。
Googleが2023年8月にFAQとHowToのリッチリザルトを非推奨としたにもかかわらず(出典)、その採用率への影響は限定的です。HowToスキーマの採用は、その複雑さのために歴史的に低く、デスクトップとモバイルの両方で1%未満の実装率となっています。一方、FAQPageは採用を維持するだけでなく、デスクトップでは2022年の0.2%から2024年の0.6%へとわずかな増加さえ示しています。この傾向は、ウェブマスターがリッチリザルト以外の検索エンジンの可視性のためにFAQPageを実装することに価値を見出している可能性があることを示唆しています。
これらの観察は、Googleのサポートの変更にもかかわらず、特定の構造化データタイプの回復力を強調しています。また、構造化データの有用性が即時の検索結果の強化を超えて拡張されることが多いため、さまざまなプラットフォームでの構造化データの進化を監視することの重要性も指摘しています。

WebSite、Organization、LocalBusinessなどを含みます。JSON-LDの関係性
構造化データの実装におけるJSON-LDの関係性を評価する際、エンティティがグラフ内でどのように接続されているかについて、いくつかの重要なパターンが浮かび上がってきます。これらの関係性パターンは、構造化データがどのように包括的で相互接続されたエンティティの説明を作成し、検索エンジンがコンテンツの文脈と関係性をより良く理解するのに役立っているかを反映しています。最も成功している実装では、これらの接続を活用して、論理的なコンテンツ関係を維持しながら、豊かで詳細な情報を提供しています。
JSON-LDの関係性分析から最も重要なパターンを確認しましょう:
- ローカルビジネスのエコシステム。 最も洗練された構造化データの実装は、ローカルビジネスセクターで行われており、
LocalBusiness、OpeningHoursSpecification、PostalAddress、GeoCoordinatesの間で豊かな相互接続が見られます。これは、企業が基本的な位置情報を超えて、詳細な運営データを含む包括的なデジタルアイデンティティを作成していることを示唆しています。これは、Googleのローカル検索への注目度の高まりと、位置ベースのサービスの重要性の増加と一致しています。 - コンテンツ組織の成熟度。 出版社がより洗練されたコンテンツ構造を実装している明確なパターンがあります。
Article、BlogPosting、WebPageエンティティ間の関係は、一貫してImageObject、著者属性、出版詳細にリンクしています。これは単なる個々のコンテンツのマークアップではなく、コンテンツ、クリエイター、組織エンティティ間の明確な関係を確立する適切なコンテンツグラフの作成に関するものです。 - Eコマースの統合。 製品関連の関係性は興味深い進化を示しています。基本的な製品マークアップを超えて、
ReviewRating、AggregateOffer、PriceSpecificationエンティティへのより多くの接続が見られます。これは、Eコマースサイトが価格追跡や在庫状態などの高度な機能をサポートできる、より包括的な製品知識グラフを構築していることを示唆しています。
最も注目すべきは、これらのパターンが示すように、構造化データの実装が単純なSEOマークアップを超えて、AIを活用した検索体験と豊かなデータ統合をサポートできる真の知識グラフの作成に向かっていることです。

potentialAction、itemListElement、isPartOfなどの頻繁に使用されるプロパティが様々なスキーマに接続している様子を強調しています。
WebSite、SearchAction、Organizationなどの主要な接続を紹介しています。前のチャートでも見られるように、最も頻繁なJSON-LDプロパティの関係性は、ウェブサイト全体でいくつかの重要な実装パターンを明らかにしています。PotentialActionは主要なプロパティとして浮かび上がり、SearchActionとWebSiteへの強い接続を示しており、サイト検索機能の広範な実装を示しています(Googleがこの機能スニペットのサポートを削除しているため、これは減少すると予想されます)。画像関連のプロパティは別の主要なクラスターを形成し、ImageObjectがOrganizationとWebPageエンティティに頻繁に接続されており、視覚的コンテンツの帰属の重要性を示しています。publisherとlogoプロパティはOrganizationエンティティに頻繁にリンクし、明確なブランドアイデンティティを確立しています。
ナビゲーション構造はBreadcrumbListとitemListElementプロパティを通じて明確なパターンを示し、通常はWebPageエンティティに接続しています。コンテンツの関係性はmainEntityOfPage接続によって示され、ビジネス固有の情報は住所、openingHoursSpecification、地理的プロパティを通じて流れています。
特に注目すべきは、PostalAddress、ContactPoint、GeoCoordinatesが明確に定義されたクラスターを形成する、連絡先と位置情報の一貫した実装です。これは企業がローカルプレゼンスのマークアップを優先していることを示唆しています。様々なエンティティに接続されたレビュー関連のプロパティ(reviewRating、rating)の存在は、構造化データを通じた評判管理への強い焦点を示しています。
sameAs
sameAsプロパティは、エンティティの曖昧性解消と知識グラフの開発において重要な役割を果たし、単純なソーシャルメディアプロファイルのリンクを超えています。私たちのデータでは、主要なプラットフォームでの強力な実装が示されています(Facebookが4.53%、Instagramが3.67%)。しかし、真の戦略的価値は、sameAsが検索エンジンがエンティティの関係性を理解し、検証するのに役立つことにあります。
適切に実装されると、sameAsは強力なエンティティの曖昧性解消ツールとなり、特に組織や個人にとって、権威のあるソース(Wikidataが0.17%、Wikipediaが0.13%)にリンクすることで、ブランドが曖昧性のないエンティティ識別を確立できます。これにより、「エンティティの指紋」を作成し、検索エンジンが様々なオンライン存在を正しいエンティティに自信を持って関連付けるのに役立ちます。
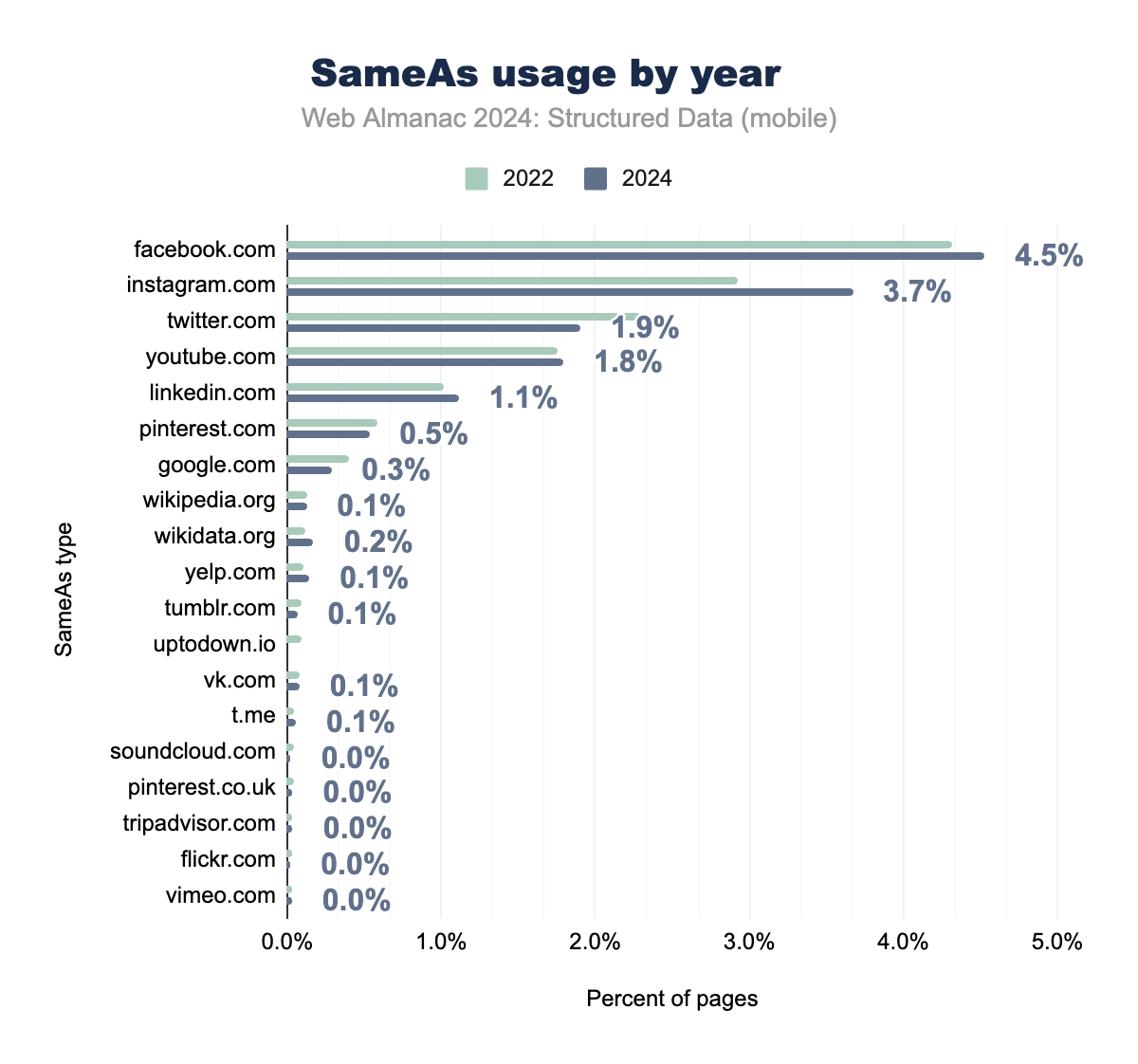
sameAsリンクの使用状況をタイプ別に比較する棒グラフ。Facebook.comが2024年に4.5%、Instagram.comが3.7%でリードしています。他のプラットフォームにはTwitter.com、YouTube.com、LinkedIn.comが含まれ、2年間の使用傾向を示しています。sameAs使用状況の前年比較
個人エンティティ(執行役員、作家、専門家)にとっても、sameAsは専門的なプロファイル(LinkedInが1.11%)を権威的で信頼できるエンティティマーカーとリンクすることで、権威と信頼性を確立するのに役立ちます。これは、E-E-A-T信号と知識パネルの生成に特に価値があります。

sameAsリンクの使用状況を比較した棒グラフ。Facebook.comがデスクトップで4.5%、モバイルで3.7%でトップに立ち、続いてInstagram.com、Twitter.comなどが続く。このデータは、プラットフォーム間での使用パターンの違いを強調している。sameAsの使用状況。
モバイルとデスクトップの実装の均一性は、構造化データの展開における重要な進展を示しています。これは、組織が異なるデバイスごとに別々の実装を維持するのではなく、一貫したテンプレートシステムや自動化ソリューションを使用して構造化データを管理することが増えていることを示唆しています。
JSON-LDコンテキスト
Schema.orgは、JSON-LDコンテキストの実装において2,000万を超えるインスタンスで依然として支配的な力を持ち、他のすべてのコンテキストを大きく上回っています。この支配力(20,960,693の実装数に対し、次に多いのはわずか11,973)は、構造化データマークアップの業界標準としての地位を反映しています。
二次的な実装の中では、contao.orgが11,973インスタンスでリードしており、主にそのCMSエコシステム内で使用されています。続いてgoogleapis.com(3,743)とbaidu.com(1,409)が続きます。教育機関はそれぞれ25-50の実装を示す一貫した採用パターンを示しており、Schema.org.cnやSchema.gov.sgなどの実装を通じて地域的なバリエーションが現れ、構造化データ標準のグローバルな採用を示しています。
Schema.orgと他のコンテキストとの間の大きな格差は、構造化データ標準化におけるその重要な役割を強調し、検索エンジンの要件との強い整合性を反映しています。
新たなトレンドと将来の展望
構造化データの状況は急速に進化しており、Googleによる車両、コース、3D製品モデルのための専門的なスキーマの導入と、GS1デジタルリンクを通じたデジタル製品パスポートのサポート強化が特徴です。JSON-LDの採用拡大(現在はページの41%)とsameAsプロパティを通じた洗練されたエンティティ関係は、包括的なナレッジグラフ開発に焦点を当てた成熟したエコシステムを示しています。
データは、特にeコマースとローカルビジネスの文脈で、より専門化された実装パターンへの明確なシフトを示しています。例えば、Product、Offer、Reviewなどの構造化データタイプはeコマースでより一般的になり、LocalBusinessとGeoCoordinatesはローカル検索の可視性向上のためにますます使用されています。
このシフトは部分的に、ウェブマスターにより特定のドメインに特化したスキーマに焦点を当てるよう促したGoogleのポリシー変更に起因しています。エンティティの曖昧さ解消もますます重要になっており、組織はsameAsやOrganizationなどの構造化データを活用して、プラットフォームやナレッジベース全体で明確なデジタルIDを確立しています。
未来に向けて: 構造化データの将来
現在のトレンドを分析しながら、私たちは今後の発展にも目を向けています:
-
AIと構造化データの共生関係
AIシステムと構造化データの相互依存関係の深まりは、根拠のある幻覚のないコンテンツ生成と対話型検索体験の向上にとって不可欠になっています。AIが正確で文脈が豊かな情報のために構造化データにますます依存するようになるにつれて、この共生関係はAI駆動ツールがウェブ全体のコンテンツとどのように相互作用するかを再定義しています。
-
Data Commonsとナレッジグラフの統合
公開データセットの構造化とリンクのためにSchema.orgを活用するGoogleのData Commonsなどのオープンデータイニシアチブの拡大は、ナレッジグラフベースのシステムの進化をさらに促進しています。これらのイニシアチブは、AI駆動のデータ充実と探索のための豊かで統一された基盤を提供し、プラットフォーム間でスケーラブルで信頼性の高いデータ統合の新たな可能性を生み出しています。
-
SEOntologyと専門的な語彙
並行して、SEOntologyや他の専門的な語彙の開発は、コンテンツの発見可能性と検索エンジン最適化を向上させるSEO固有の構造化データの必要性に対応しています。SEOの独自の要件に合わせた語彙を作成することで、構造化データとAIの連携をさらに強化し、よりターゲットを絞った効率的な検索体験を実現できます。
-
規制の影響
最後に、EUのデジタル製品パスポートなどの規制は、将来の構造化データ標準を再形成する態勢を整えています。これらのイニシアチブは、特にeコマースや製品トレーサビリティなどの領域で、構造化データの適用方法に影響を与え、より構造化され透明性の高いデータ実践を促すでしょう。
これらの側面を検討することで、2024年の構造化データの状況、その最近の進化、および将来の軌道について包括的な概要を提供することを目指しています。あなたが経験豊富なSEO専門家、ウェブ開発者、eコマース戦略家、あるいは単にウェブの進化に興味があるだけでも、この章は構造化データがデジタル世界をどのように再形成し、より接続性が高く、透明で、インテリジェントなオンライン体験への道を開いているかについての貴重な洞察を提供します。
結論
2024年の構造化データの分析は、SEOのルーツからAIとセマンティックメタデータにおけるより広範で戦略的な役割へのはっきりとしたシフトを示しています。60%以上のページでのRDFaとOpen Graphの優位性と、JSON-LDの成長(現在はページの41%、特にeコマースで)は、成熟しつつある技術を示しています。しかし、真の影響力は、構造化データがAIによる発見をどのように変革し、機械の理解を向上させているかにあります。
今年、検索エンジンが構造化データをどのように扱うかに大きな変化が見られました。GoogleはFAQ、HowTo、SiteLinkなどの特定のリッチリザルトを非推奨とする一方で、同時に車両、コース、3D製品モデル、ロイヤリティカード、認証などの新しいタイプを導入し、構造化データの範囲を拡大しています。さらに重要なことに、構造化データは今やAIシステムにとって不可欠となり、事実確認から検索能力の向上、大規模言語モデル(LLM)のトレーニングまで、さまざまなタスクをサポートしています。
デジタル製品パスポートの登場とGS1標準の採用増加は、商取引と規制遵守における構造化データの重要性の高まりを強調しています。AI駆動の検索が標準になるにつれて、企業は構造化データが単なる検索での可視性だけでなく、コンテンツが機械可読で将来にも対応できることを確保するために重要であることを認識しています。
構造化データ戦略を開発する企業にとって、前進の道は明確です:包括的に実装し、厳格に維持し、継続的に適応することです。新しいプロジェクトはJSON-LDに焦点を当てるべきですが、適切な場合はレガシーフォーマットも保持すべきです。システムは、新興技術や標準と共にスケールし進化するように構築する必要があります。
結論として、ウェブの未来は構造化され、セマンティックで、ますますインテリジェントになっています。今日、構造化データに投資する組織は、単に検索での可視性を向上させるだけでなく、AIディスカバリーでの成功の基盤を築いているのです。
