生成AI

はじめに
2022年11月30日、OpenAIはChatGPTを公開しました。このサービスは 生成的人工知能 (生成AI)を研究室から数百万人の日常生活へと一気に引き上げました。このリリースはアプリケーションとウェブがどうあるべきかというユーザーの期待を根本から変えました。さらに、付随する アプリケーションプログラミングインターフェース (API)はソフトウェア開発者に、アプリケーションを劇的にスマートにする強力なツールをもたらしました。
生成AIは、テキスト、ソースコード、画像、動画、音声、音楽など人間が理解できるコンテンツの処理と生成に特化した専門分野です。 大規模言語モデル (LLM)はこの分野の重要なコンポーネントです。膨大なテキストデータで学習されたLLMは自然言語を解釈・生成し、開発者が初めて人間言語を効果的に処理できるようにすることでソフトウェアアーキテクチャを拡張しています。最近では生成AI機能がWindows、Office、Photoshopなどの確立されたアプリケーションにも統合されています。
生成AIがますます普及する中、この章ではウェブにおける生成AIの新興トレンドを検討します。具体的には、「組み込みAI」と「Bring Your Own AI」アプローチによって実現するローカル生成AIの使用、llms.txtを介した生成AIコンテンツの発見可能性、そしてコンテンツ作成とソースコードへの生成AIの影響( AIフィンガープリント )に焦点を当てます。
データソース
この章では、HTTP Archiveのデータセットだけでなく、npmのダウンロード統計、およびChrome Platform Statusや他の研究者が提供するデータも使用しています。
特に断りのない限り、方法論で説明されている2025年7月のHTTP Archiveクロールを参照しています。APIの採用を検出するために、コード内の特定のAPI呼び出しの存在についてウェブサイトをスキャンしました。これはその存在を示すものであり、実行時の実際の使用状況を必ずしも示すものではありません。Chrome Platform Statusの使用データは常に、すべてのリリースチャンネルとプラットフォームにわたって、特定のAPIを少なくとも1回使用するGoogle Chromeのページロードの割合を指しています。
技術概要
このセクションでは、クラウドベースのAIモデルとローカルAIモデルの違いを説明し、これらのアプローチの長所と短所について議論した後、ローカル技術を詳しく検討します。
クラウド対ローカル
ほとんどの人は、OpenAI、Microsoft Foundry、AWS Bedrock、Google Cloud AI、またはDeepSeekプラットフォームなどのクラウドサービスを通じて生成AIを使用しています。これらのプロバイダーは膨大な計算リソースとストレージ容量にアクセスできるため、いくつかの重要な利点を提供しています:
- 高品質なレスポンス: モデルは非常に有能で強力です。
- 高速な推論時間: 強力なサーバーでレスポンスが素早く生成されます。
- 最小限のデータ転送: AIモデル全体ではなく、入出力データのみを転送する必要があります。
- ハードウェア非依存: クライアントのハードウェアや計算リソースに関わらず動作します。
しかし、クラウドベースのモデルには欠点もあります:
- 接続性: 安定したインターネット接続が必要です。
- 信頼性: ネットワーク遅延、サーバーの可用性、容量制限の影響を受けます。
- プライバシー: データをクラウドサービスに転送する必要があり、潜在的なプライバシーの懸念が生じます。ユーザーデータが将来のモデルの反復学習に使用されているかどうかは、しばしば不明確です。
- コスト: 通常、サブスクリプションやAPI使用料が必要であり、ウェブサイト作者は推論のコストを負担しなければならないことが多いです。
ローカルAI技術
クラウドベースシステムの限界は、Web AIと呼ばれるローカルAI技術を介して推論をクライアントに移行することで対処できます。モデルはユーザーのシステムにダウンロードされるため、その 重み (内部モデルパラメーター)を秘密にすることはできません。そのため、このアプローチは主にオープンウェイトモデルと組み合わせて使用されますが、オープンウェイトモデルは商用のクラウドベースのクローズドウェイトモデルと比べて一般的に性能が低いです。Epoch AIによると、オープンウェイトモデルは平均して約3か月、最先端の性能に遅れをとっています。
World Wide Web Consortium(W3C)のWeb Machine Learningコミュニティグループとワーキンググループは、AIを「ファーストクラスのウェブ市民」にするためにこの移行の標準化を積極的に進めています。この取り組みは2つの主要なアーキテクチャ方向に従っています:Bring Your Own AI と 組み込みAI です。
Bring Your Own AI
Bring Your Own AI(BYOAI)アプローチでは、開発者がモデルをユーザーに配信する責任を担います。ウェブアプリケーションは特定のモデルバイナリをダウンロードし、ローカルハードウェア上の低レベルAPIを使用して実行します。これにより、ユースケースに特化した高度に専門化されたモデルを実行できますが、大きな帯域幅も必要とします。
AIの推論をローカルで実行するために使用できる3つの処理ユニットがあります:
- 中央処理装置 (CPU):応答が速く、低遅延のAIワークロードに最適。
- グラフィックス処理装置 (GPU):高スループットで、AI加速デジタルコンテンツ作成に最適。
- ニューラル処理装置 (NPU)または テンソル処理装置 (TPU):低消費電力で、継続的なAIワークロードとバッテリー寿命のためのAIオフロードに最適。
ローカルAI推論を促進する3つの主要なAPIはWebAssembly(CPU)、WebGPU(GPU)、WebNN(CPU、GPU、NPU)です。
WebAssemblyとWebGPUの使用がAI活動を確認するわけではないことに注意することが重要です。これらは複雑な計算、3Dビジュアライゼーション、またはゲームなどのタスクに頻繁に使用される汎用APIです。
WebAssembly
WebAssemblyはウェブのバイトコードとして機能します。C++やRustなどのさまざまなプログラミング言語で書かれたコードをWebAssemblyにコンパイルできます。開発者がユーザーのCPUでブラウザのスクリプティングエンジンによって実行される最適化された高性能コードを書くことができます。
WebAssemblyは2017年以来すべての主要なブラウザエンジンに実装されており、広範なブラウザサポートを持っています。
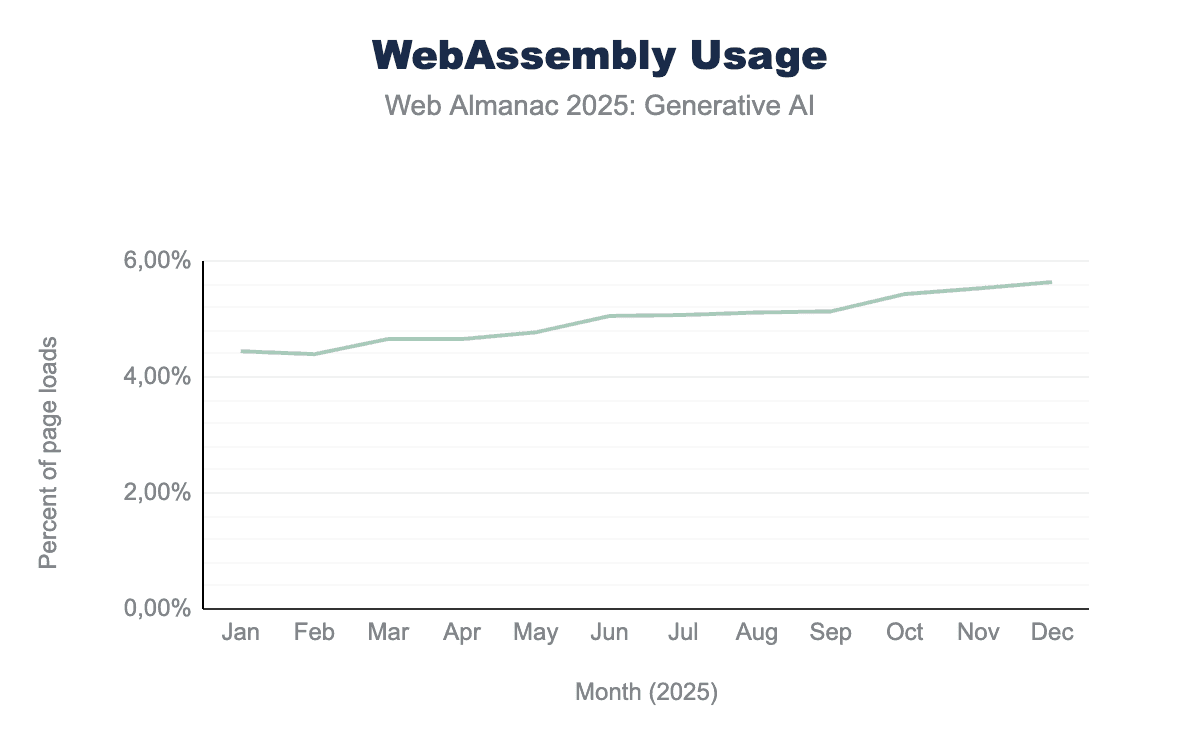
Chrome Platform Statusデータによると、WebAssemblyの使用率は2025年1月の4.44%のページロードから2025年12月の5.64%へと27%の線形成長を経験しました。2024年1月、WebAssemblyはページロードの3.37%でのみ有効でした。
WebGPU
WebGPUはWebGLの近代的な後継であり、現代のGPUの機能をウェブに公開するために設計されています。厳密にグラフィックス用であったWebGLとは異なり、WebGPUは コンピュートシェーダー のサポートを提供し、グラフィックスカード上での汎用コンピューティングを可能にします。これにより、開発者はAIモデルが必要とする大規模な並列計算をユーザーのグラフィックスカード上で直接実行できます。
WebGPUはブラウザでのAIワークロード実行の標準的な基盤となっています。2025年11月のFirefox 141のリリースにより、WebGPUはすべての主要なブラウザエンジンで利用可能になりました(Chromium、Gecko、WebKit)。
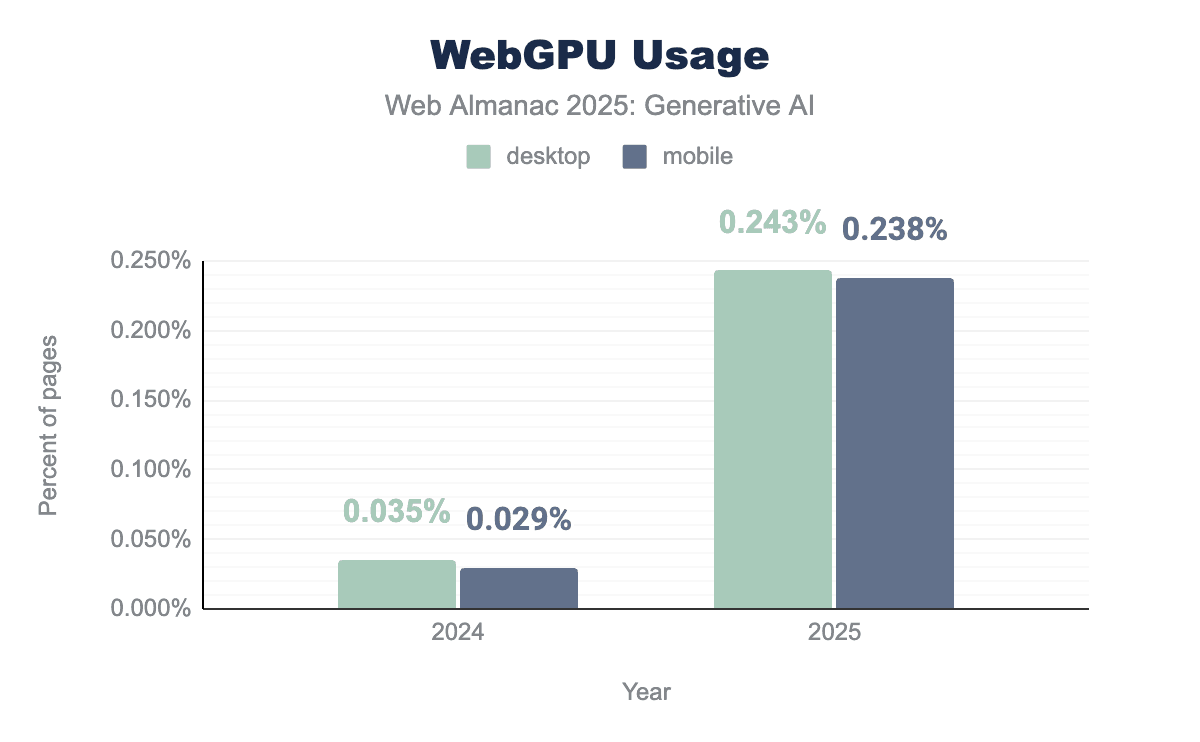
2025年7月のHTTP ArchiveデータクロールはAPIがすべてのデスクトップサイトの0.243%とモバイルサイトの0.238%で使用されていることを示しています。全体的にはまだ小さいながらも、2024年7月クロールと比較してデスクトップで591%(0.035%から増加)、モバイルで709%(0.029%から増加)という大幅な増加を示しています。Chrome Platform Statusデータは、2025年を通じて147%増加したページロードあたりのアクティベーションの指数的成長を示唆しています。
WebNN
Web Neural Network API(WebNN)は機械学習に特化した専用APIです。WebMLワーキンググループによって仕様策定され、このAPIはW3C勧告トラック—ウェブ標準となるための正式なプロセス—に位置づけられています。
WebNNはハードウェア非依存の抽象化レイヤーとして機能し、ブラウザがデバイス上で利用可能な最も効率的なハードウェアに処理をルーティングできるようにします。WebAssembly(CPUのみ)とWebGPU(GPUのみ)とは対照的に、WebNNはCPU、GPU、NPUで計算を実行できます。ネイティブに近い実行速度を達成できます。
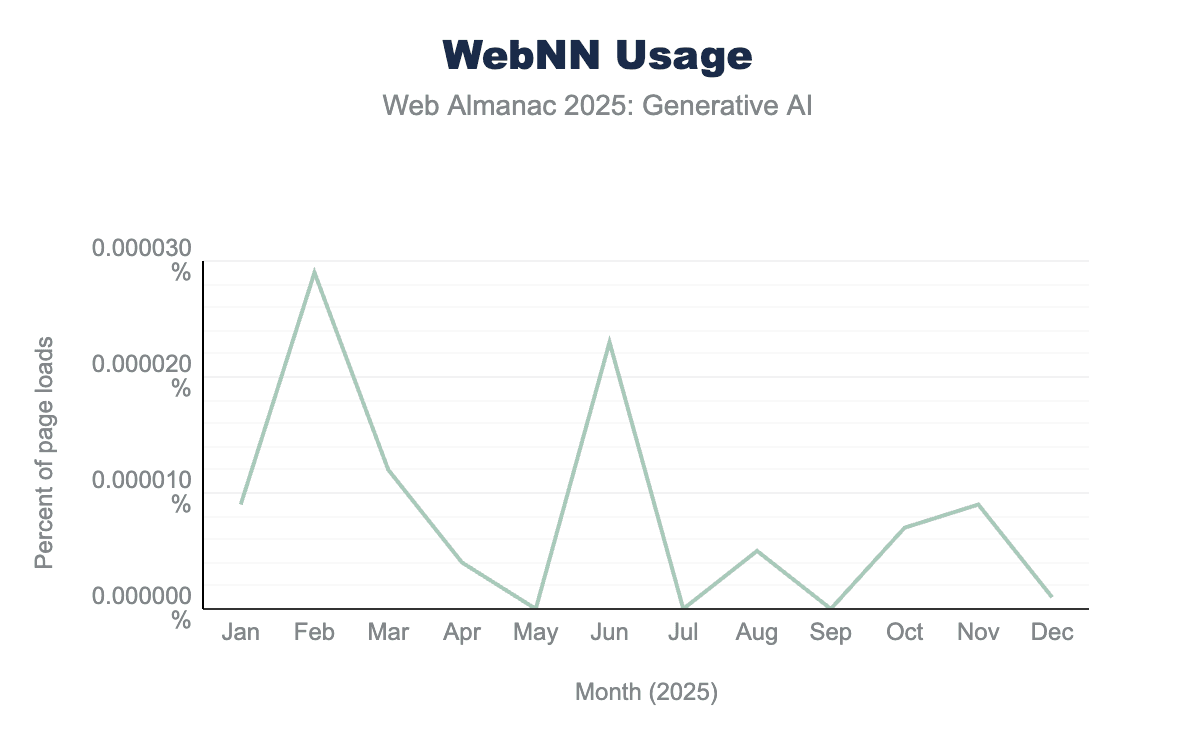
WebNNは現在活発に開発中であり、ChromeOS、Linux、macOS、Windows、AndroidのChromiumベースのブラウザでフラグの後ろに実装されています。2025年11月、FirefoxがAPIを正式にサポートする2番目のエンジンとして参加しました。WebNNがまだ実験的なAPIであることを考えると、Chrome Platform Statusデータによれば使用数は現在非常に低く、変動が大きく、2025年2月の最大アクティベーション率は0.000029%です。
ランタイム:ONNX RuntimeとTensorflow.js
ONNX Runtime(Microsoftが開発)とTensorflow.js(Googleが開発)は、ブラウザ上でAIモデルを直接実行するための主要なランタイムの2つです。これらのランタイムはWebAssembly、WebGPU、WebNNなどの低レベル技術の複雑さを抽象化します。
TensorFlow.jsはTensorFlowエコシステムと緊密に統合されており、学習と推論の両方をサポートしている一方、ONNX RuntimeはONNX標準を使用したクロスプラットフォーム推論に焦点を当て、複数のフレームワークからのモデルをクライアントサイドで実行できるようにしています。
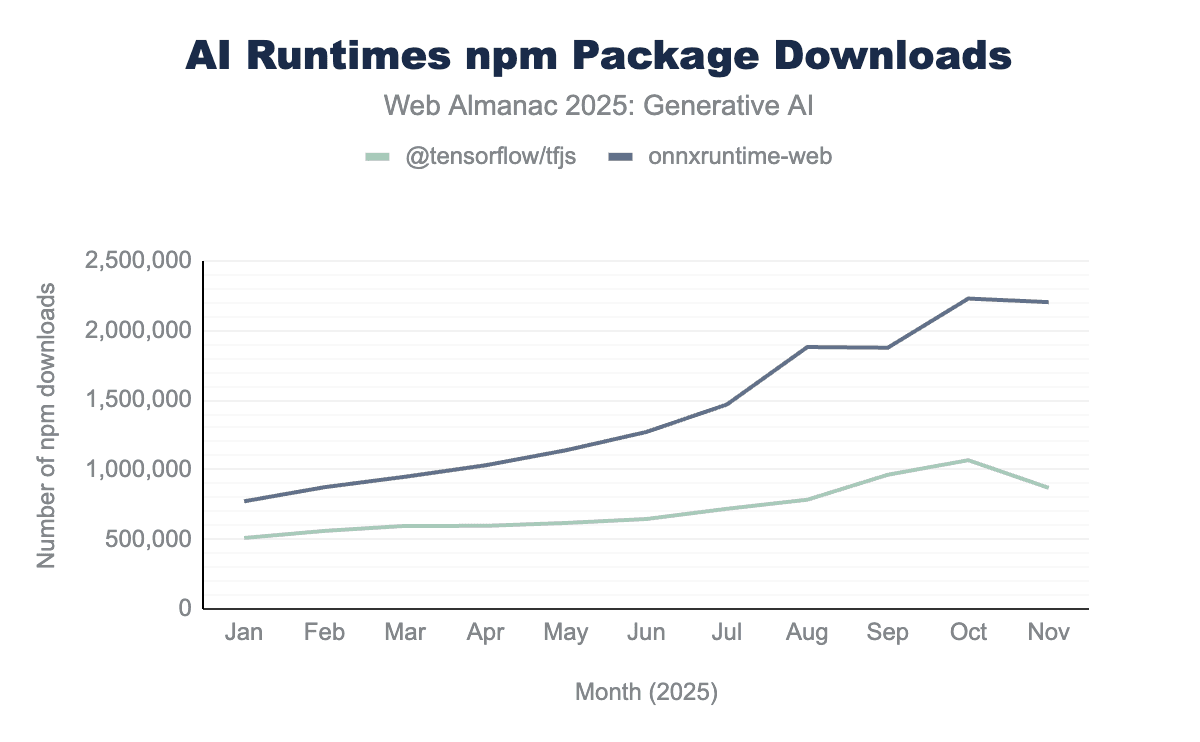
@tensorflow/tfjsとonnxruntime-webのnpmパッケージダウンロード数。
2025年1月から11月にかけて、ONNX Runtimeのnpmパッケージダウンロード数は185%増加し、TensorFlow.jsのダウンロード数は70%増加し、ブラウザベースのAIへの開発者の強い関心と高まりを示しています。
ライブラリ:WebLLMとTransformers.js
MLC AI研究チームが開発したWebLLMは、LLMに特化した高性能なブラウザ内推論エンジンです。Llama、Phi、Gemma、Mistralなどの様々なオープンウェイトLLMをブラウザ上で直接実行できます。現在、WebLLMは推論にWebGPUを使用しています。
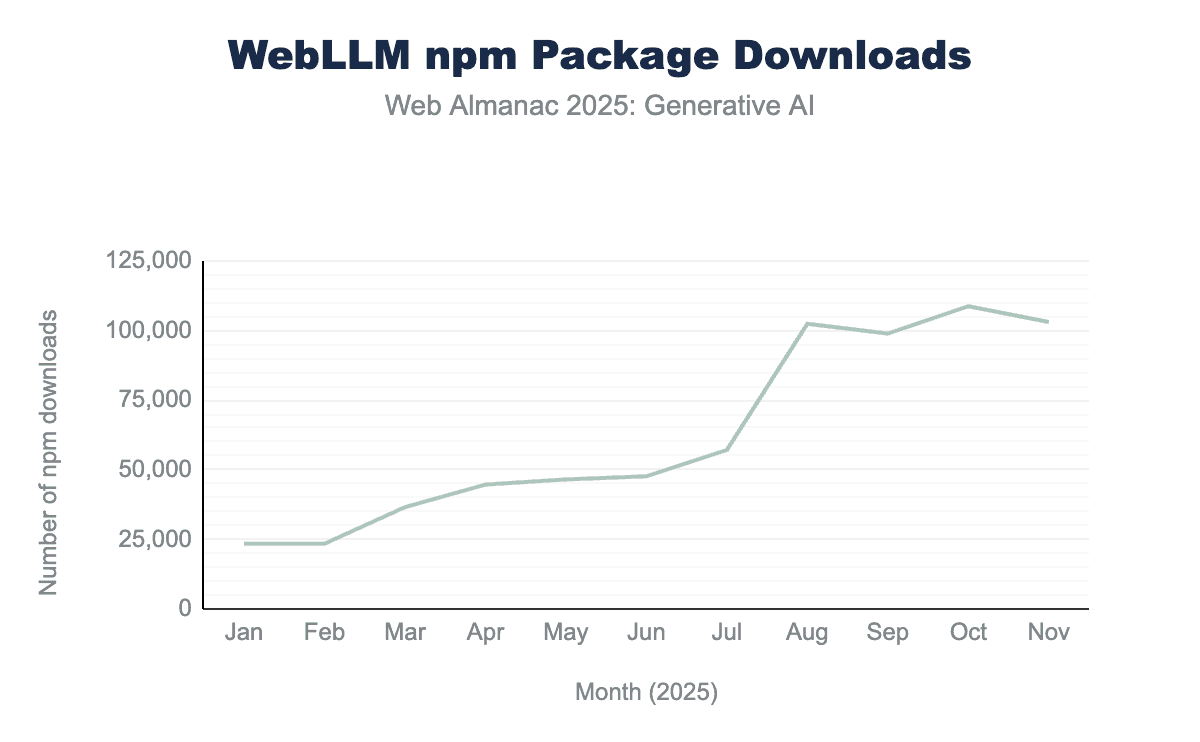
@mlc-ai/web-llmパッケージのnpmダウンロード数を示す折れ線グラフ。ダウンロード数は1月の23,425から11月の103,084へと340%増加し、7月の57,114から8月の102,440へとほぼ倍増する大きなスパイクが8月に発生しました。@mlc-ai/web-llmのnpmパッケージダウンロード数。
WebLLMはブラウザ内LLM推論の最も注目すべきソリューションの1つとして急速に台頭しました。2025年1月から11月にかけて、npmからのWebLLMパッケージのダウンロード数は340%増加しました。8月だけでダウンロード数がほぼ倍増しました。このサージを特定のイベントに帰因することはできませんでした。
Hugging Faceが開発したTransformers.jsは、人気のPython transformers APIを模倣した包括的なJavaScriptライブラリとして機能します。内部ではONNX Runtimeに依存して実行されます。LLMだけでなく、シンプルな高レベルパイプラインを通じてさまざまなタスクの事前学習済みモデルを実行できます。
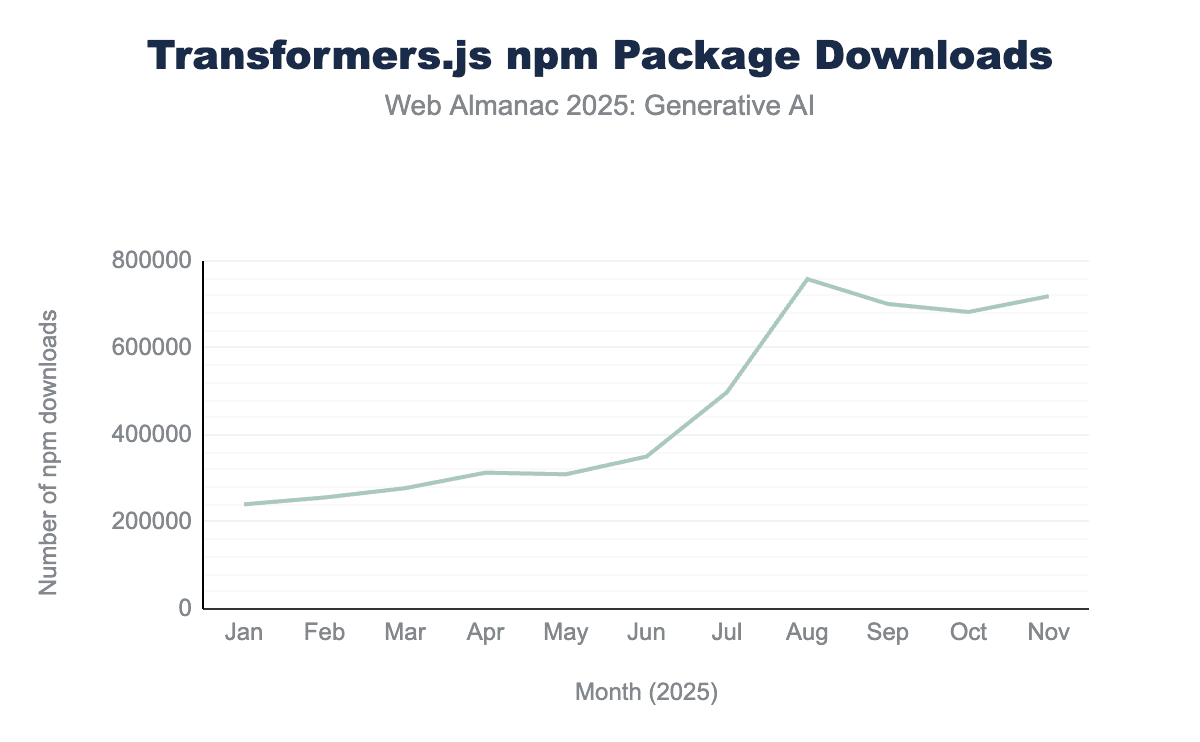
@huggingface/transformersパッケージのnpmダウンロード数を示す折れ線グラフ。ダウンロード数は1月の240,389から11月の719,103へとほぼ3倍になりました。トレンドは8月の大きなスパイクを示しており、年初来ピークの758,393に達しています。@huggingface/transformersのnpmパッケージダウンロード数。
2025年1月から11月にかけて、npmパッケージのダウンロード数はほぼ3倍になり、2025年8月にも顕著なサージが見られました。
組み込みAI
組み込みAIはGoogleとMicrosoftが推進するイニシアティブで、ウェブ開発者に高レベルのAI APIを提供することを目指しています。BYOAIとは異なり、このアプローチはブラウザ自身が提供するモデルを活用します。開発者は特定のモデルを指定できませんが、この方法によりすべてのウェブサイトが同じモデルを共有でき、一度だけダウンロードすれば良いことを意味します。
このイニシアティブは複数のAPIで構成されています:
- Prompt API: 開発者にローカルLLMへの低レベルアクセスを提供します。
-
タスク固有のAPI:
- Writing Assistance APIs: テキストの要約、執筆、リライトを行います。
- Proofreader API: テキスト内の誤りを発見・修正します。
- Language Detector と Translator APIs: テキストコンテンツの言語を検出し、別の言語に翻訳します。
すべてのAPIはWebMLコミュニティグループ内で仕様策定されており、まだインキュベーション中でW3C勧告トラックには載っていません。一部のAPIはすでに一般提供されていますが、他はブラウザフラグの有効化が必要だったり、Origin Trial中で有効化に登録済みトークンが必要です—安定していて本番機能の出荷に広く利用可能なWebGPUとは異なります。
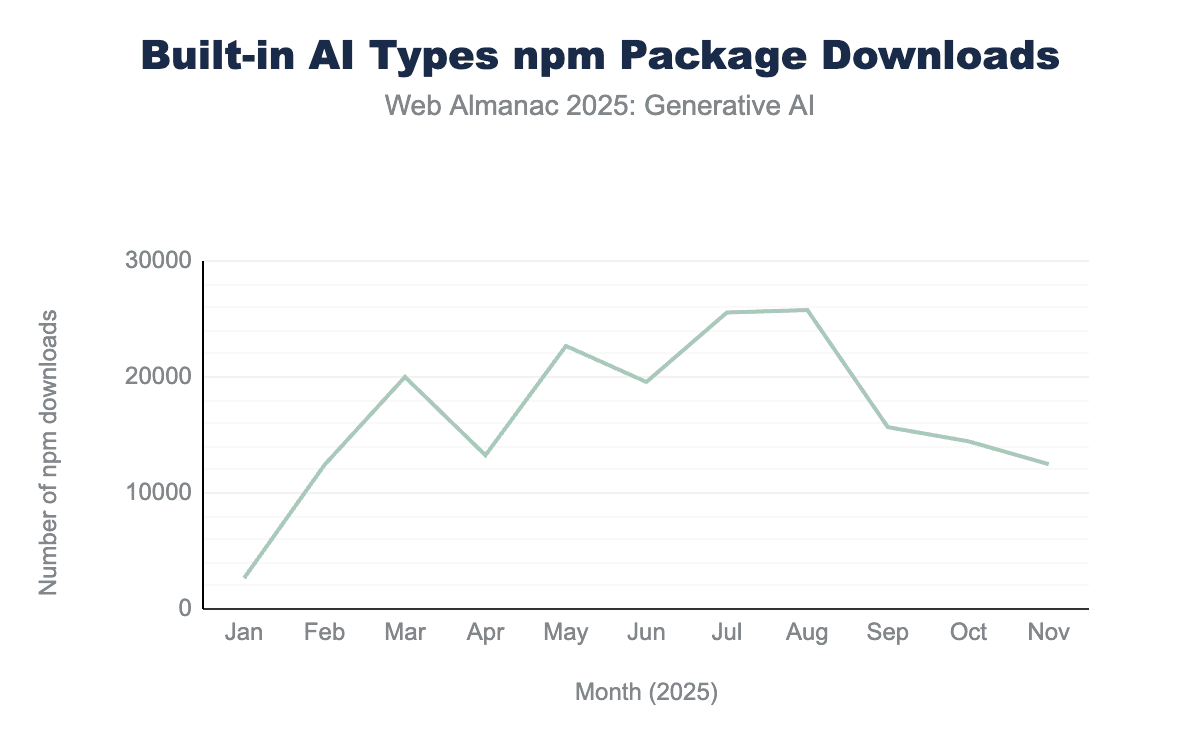
@types/dom-chromium-aiパッケージのnpmダウンロード数を示す折れ線グラフ。ダウンロード数は1月の2,653から始まり、8月の25,770でピークに達し、11月の12,478へと緩やかに減少しました。@types/dom-chromium-aiのnpmパッケージダウンロード数。
組み込みAI向けのTypeScriptタイピングを含む@types/dom-chromium-aiパッケージのダウンロード数は、APIの実験的なステータスを反映しているかもしれません:ダウンロード数は2025年8月に25,770でピークに達し、その後緩やかに減少しました。このトレンドは開発者が実験的なAPIの採用に慎重であることを示唆しているかもしれません。ただし、タイピングパッケージのダウンロード統計はAPIの実際の使用状況を反映していない場合があります。
Prompt API
Prompt APIは、ChromeでGemini Nano(Gemini Nano)やEdgeでPhi-4-mini(Phi-4-mini)など、ユーザーのブラウザが提供するLLMにアクセスするための標準化されたインターフェースを導入します。これらの一度だけダウンロードするモデルを活用することで、APIはモデルの重みダウンロードを必要とするライブラリに関連する帯域幅の障壁とコールドスタートの遅延を解消します。
しかし、2025年12月時点では技術は移行段階にあります:Chrome 138のブラウザ拡張機能では完全に出荷されていますが、ウェブページのアクセスはまだOrigin Trialに制限されています。このAPIは現在モバイルデバイスでは利用できません。
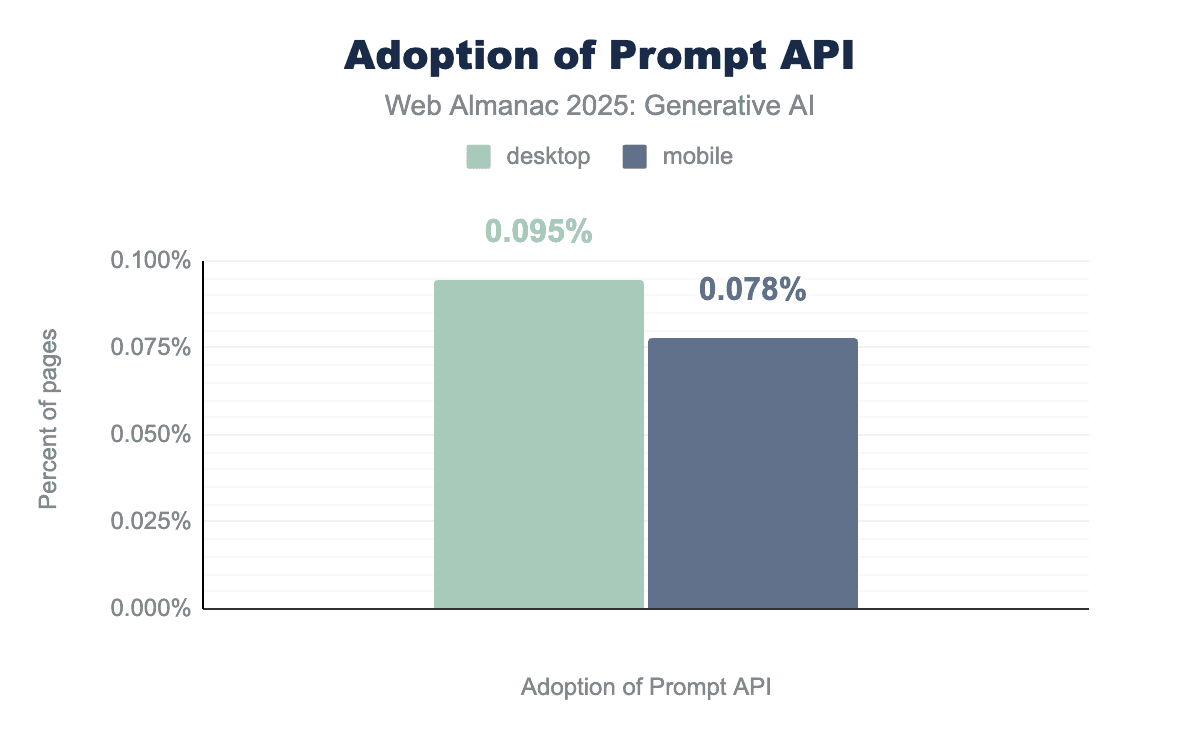
そのため、採用はまだ初期段階にあります。2025年7月(利用可能な最初の計測)のHTTP Archiveデータでは、すべてのデスクトップサイトのわずか0.095%とモバイルサイトの0.078%でAPIが検出され、標準的なユーティリティではなく実験としての現在のステータスを反映しています。
分析したサンプルサイトの多くは、外部スクリプトのGoogle Publisher Tagsを通じてPrompt APIを使用していました。このプロジェクトは、著者がウェブサイトに動的な広告を組み込むことを可能にします。Google Publisher TagsスクリプトはPrompt APIを使用してページのコンテンツをInteractive Advertising Bureau(IAB)コンテンツ分類3.1カテゴリのリストに分類し、Summarizer API(次のセクションを参照)を使用してページのコンテンツの要約を生成し、両方をサーバーに送信します。ただし、分析中にコードブランチはアクティブではないように見えました。
Writing Assistance APIsとProofreader API
次に、タスク固有のAPIを検討します。Writing Assistance APIsはプロンプトエンジニアリングの複雑さを抽象化します。同じ基盤となる埋め込みLLMを使用しますが、異なる言語的目標を達成するために特殊なシステムプロンプトを適用します:
- Writer API: プロンプトに基づいて新しいコンテンツを作成します
- Rewriter API: プロンプトに基づいて入力を言い換えます
- Summarizer API: テキストの要約を生成します
さらに、Proofreader APIは開発者がテキストを校正し、文法エラーやスペルミスを修正することを可能にします。
Summarizer APIはChrome 138で出荷されました。2025年12月時点では、Writer、Rewriter、Proofreader APIはOrigin Trial中です。すべてのAPIは現在モバイルデバイスでは利用できません。
2025年7月のHTTP Archiveクロールでは、Writer.create()への呼び出しのみが検出されました(デスクトップサイトの0.127%とモバイルサイトの0.137%)。これは当初Writer APIの使用を示唆していましたが、手動チェックにより、サンプリングされたサイトの多くが実際には同じAPIシグネチャを共有するProtobuf.jsのWriterを使用していることが判明しました。そのため、このメトリクスのチャートは省略することにしました。
Translator APIとLanguage Detector API
組み込みAI APIの最後のカテゴリはTranslator APIとLanguage Detector APIで構成されています。Writing Assistance APIsとは異なり、これらのAPIはLLMに依存せず、代わりに特殊なタスク固有のニューラルネットワークを活用しており、生成AIの厳密な定義の外に置かれます。
APIはChrome 138で出荷されましたが、現在モバイルデバイスでは利用できません。

これらは組み込みAI APIの中で最も広い採用を達成しています。2025年7月のHTTP ArchiveクロールはTranslator APIをすべてのデスクトップサイトの0.277%とモバイルサイトの0.262%で検出し、Language Detector APIはわずか0.001%少ないサイトで使用されていました。
チェックしたサンプルサイトの多くは、Shopifyストアのアドオンとして機能するレビューツールJudge.meを利用していました。Judge.meはLanguage DetectorとTranslator APIの両方を使用しており、これが使用の密な結合の理由かもしれません:Language Detector APIはほぼ同じ絶対数のサイトに存在し、Translator APIにわずか約100サイト遅れていました。
ブラウザ固有のランタイム:Firefox AI Runtime
Chromiumサイドによる組み込みAI APIsの代替として、FirefoxはFirefox AI Runtimeを試験的に導入しています。これはTransformers.jsとONNX Runtimeをベースにしたネイティブで動作するローカル推論ランタイムです。ただし、このランタイムはまだ一般のウェブからはアクセスできません。拡張機能や、Firefoxの組み込み翻訳機能などの特権的な用途にのみ使用できます。
発見可能性
このセクションでは、ウェブにおける生成AIの採用増加に伴うウェブの発見可能性のダイナミクスを見ていきます。AIプラットフォームやサービスがコンテンツを発見する方法に影響を与える2つの重要なアプローチ、robots.txtとllms.txtファイルに主に焦点を当てます。
robots.txt
ドメインのルートに配置されたrobots.txtファイル(例:http://example.com/robots.txt)は、ウェブサイトオーナーが自動化ボットに対するクロールディレクティブを宣言できるようにします。歴史的にウェブクロールは主に検索エンジンやアーカイブによって行われていました。しかし、生成AIの時代には、ウェブサイトはAIエージェントによっても、またはLLMの学習のためにインターネット規模のデータを収集するモデルプロバイダーによってもクロールされる可能性があります。その結果、ウェブサイトはこれらのクローラーへのアクセスを管理するためにますますrobots.txtファイルに依存しています。
OpenAIがモデルのトレーニングに使用するユーザーエージェントGPTBotをターゲットにしたディレクティブの例を以下に示します:
User-Agent: GPTBot
Disallow: /robots.txtへの準拠は任意であり、アクセス制御を厳密に強制するものではないことに注意することが重要です。
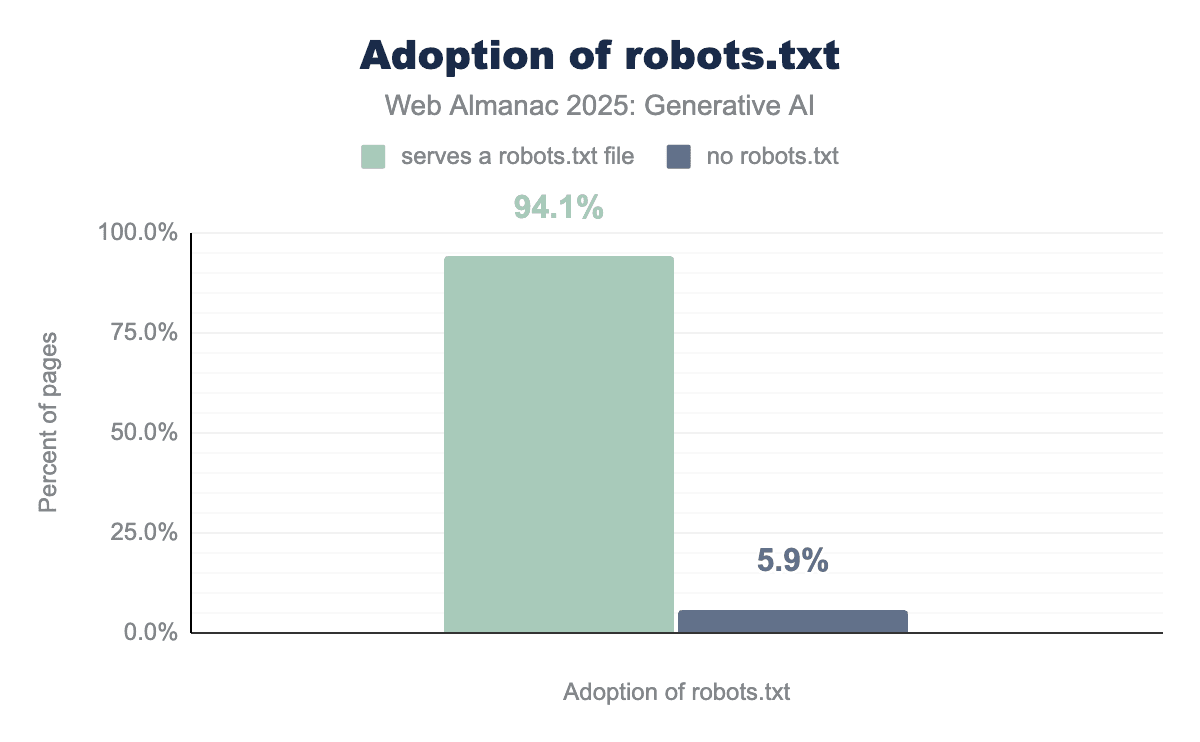
robots.txtがある場合とない場合のサイトを比較した棒グラフ。サイトの94.1%という大部分がファイルを提供しています。robots.txtの採用状況。
robots.txtの使用は依然として非常に普及しています:分析した約1,290万サイトのうち約94.1%が少なくとも1つのディレクティブを含むrobots.txtファイルを持っています。
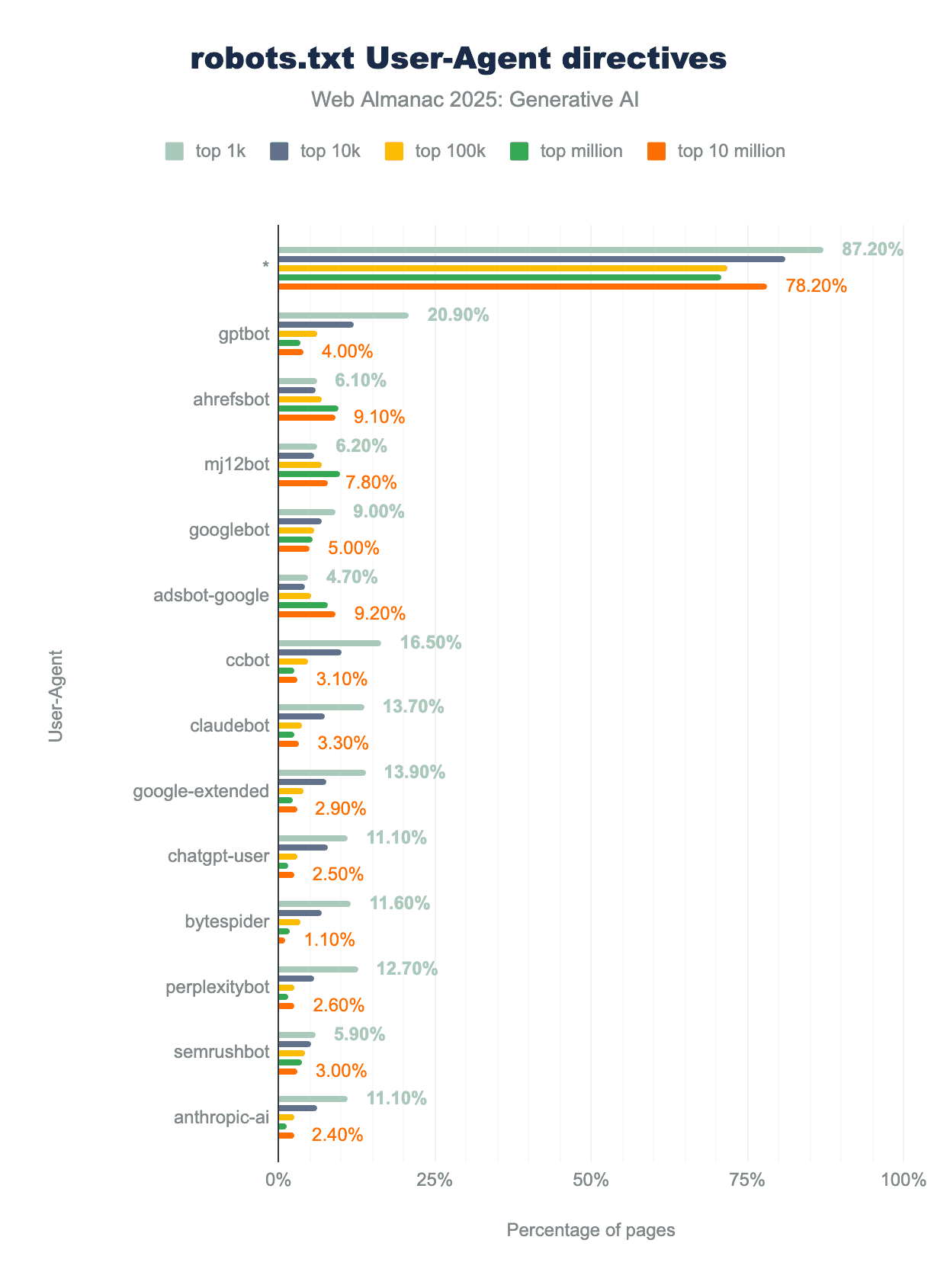
robots.txtのUser-Agentディレクティブをランク付けした棒グラフ。ワイルドカード*が最も一般的なディレクティブで、次にgptbotディレクティブが続きます。次のAIボットclaudebotは8位にいます。トップ1kサイトはより人気の低いサイトよりも頻繁にボットに言及する傾向があります。例えば、gptbotはトップ1kサイトの20.9%、トップ10kサイトの12.1%、トップ100kサイトの6.1%、トップ100万サイトの3.6%、トップ1000万サイトの4%のrobots.txtファイルで言及されています。robots.txtディレクティブ。
上図はすべてのウェブサイトで観察されたトップディレクティブを、ランク別にグループ化して示しています。ワイルドカードディレクティブ*が最も一般的に使用され、robots.txtファイルの97.4%に存在します。これにより、サイト作者がすべてのボットに対するグローバルなルールを設定できます。2番目に多く使用されるユーザーエージェントはgptbot(分析ではユーザーエージェント名を小文字化したことに注意)で、2024年の2.6%から2025年の約4.5%へと採用が増加しました。
他に頻繁にターゲットにされるAIボットには、Anthropic(claudebot、anthropic-ai、claude-web)、Google(google-extended)、OpenAI(chatgpt-user)、Perplexity(perplexitybot)のものが含まれます。
AIボットをターゲットにしたディレクティブは人気サイトで著しく多く見られ、そのほぼすべてがアクセスを拒否しています。これは人気サイトがオーガニックトラフィックに悪影響を与えることなくAIクローラーを制限できるためと考えられます。全体として、robots.txtファイル内でのAI固有ディレクティブの採用の明確な増加が観察されました。
llms.txt
llms.txtファイルは、推論時にLLMがウェブサイトを効果的に活用できるように設計された新興のプロポーザルです。robots.txtと同様に、ウェブサイトのドメインのルートにホストされます(例:https://example.com/llms.txt)。主な違いはその機能にあります:robots.txtはトレーニングや推論中にクロールを許可・禁止するものをボットに指示しますが、llms.txtはウェブサイトのコンテンツの構造化されたLLMフレンドリーな概要を提供します。これにより、LLMはユーザーのクエリに答える際にリアルタイムでウェブサイトを効率的にナビゲートできます。
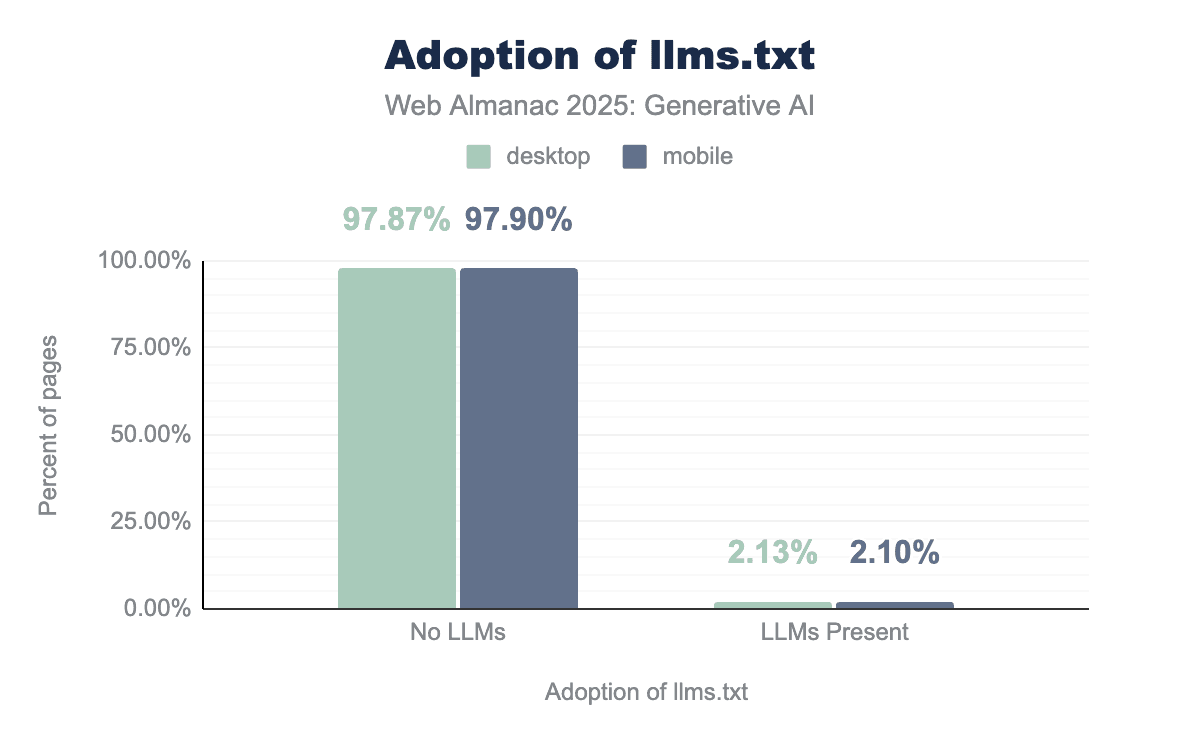
llms.txtがあるサイトとないサイトのデスクトップとモバイルを比較した棒グラフ。ファイルはデスクトップの2.13%とモバイルサイトの2.1%にのみ存在し、大多数のデスクトップの97.87%とモバイルサイトの97.9%には存在しません。llms.txtの採用状況。
llms.txtは比較的新しいため、ウェブ上での使用は非常に限られていました。デスクトップページでは、有効なllms.txtエントリを示すのはわずか2.13%で、97.87%はこのファイルの証拠を示していません。モバイルページも同様のパターンを示し、2.1%のページが有効なエントリを含み、97.9%が含んでいません。
したがって、大多数のサイトはまだllms.txtを通じて明示的なAIアクセス設定を示していません。存在する場合、そのファイルはアーリーアダプターがAI駆動の発見可能性を試験的に実装しているか、エージェントのユースケースを促進しているか、または 生成エンジン最適化 (GEO)を探求していることを示します。検索エンジン最適化(SEO)とは対照的に、GEOはコンテンツをLLMやPerplexityやGoogle AI ModeなどのAI対応検索ツールが容易に取り込めるようにすることに焦点を当てています。詳細についてはSEO章を参照してください。
AIフィンガープリント
OpenAI ChatGPT、Google Gemini、Microsoft Copilotなどのサービスはすでに広く使用されています。AIの支援を受けてコンテンツが書かれることが増えています。このセクションでは、生成AIがウェブコンテンツとソースコードに与える影響を分析します。
AIカラー
モデルは特定の単語を過剰に使用する傾向があり、それがAIフィンガープリントとして機能します。フロリダ州立大学の研究者たちは2020年から2024年にかけてPubMedに発表された研究論文を比較しました。彼らの分析は、「delves」という単語の使用が驚異の6,697%増加したことを明らかにしました。動詞「delve」の他の活用形も大幅に増加しました。このような指標を個々のケースをAI生成として分類するために使用すべきではありませんが、採用のトレンドを理解するためには依然として有用です。この章のこの部分では、LLMがウェブサイトを生成するために使用する一般的なパターンを掘り下げます(delve)😉。
AI生成ウェブデザインの最も認識しやすい指標は、「AIパープル問題」とも呼ばれる紫色とグラデーションの広範な使用です。
広く採用されているCSSフレームワークTailwindの作成者Adam Wathanは、最近のインタビューで、このトレンドは主要なAIトレーニングクロールのタイミングから生じている可能性が高いと述べました。2020年代初頭、Tailwindチームは当時のデザイントレンドを反映するためにドキュメントや例に深い紫色を多く使用していました。その結果、そのデータでトレーニングされたLLMは、現在の黒いデザインへの好みなど、より現代的なトレンドに置き換えられた美学を「固定」してしまったようです。
「AIパープル」の美学を定量化するために、ChatGPTのリリース後の年からデータセット内のすべてのルートページのCSS(ウェブサイトのスタイリングを担当)を分析しました。よく知られたindigo-500カラー(#6366f1)の存在、CSSグラデーションの使用、およびAI生成ウェブサイトに関連する他のカラーを追跡しました。
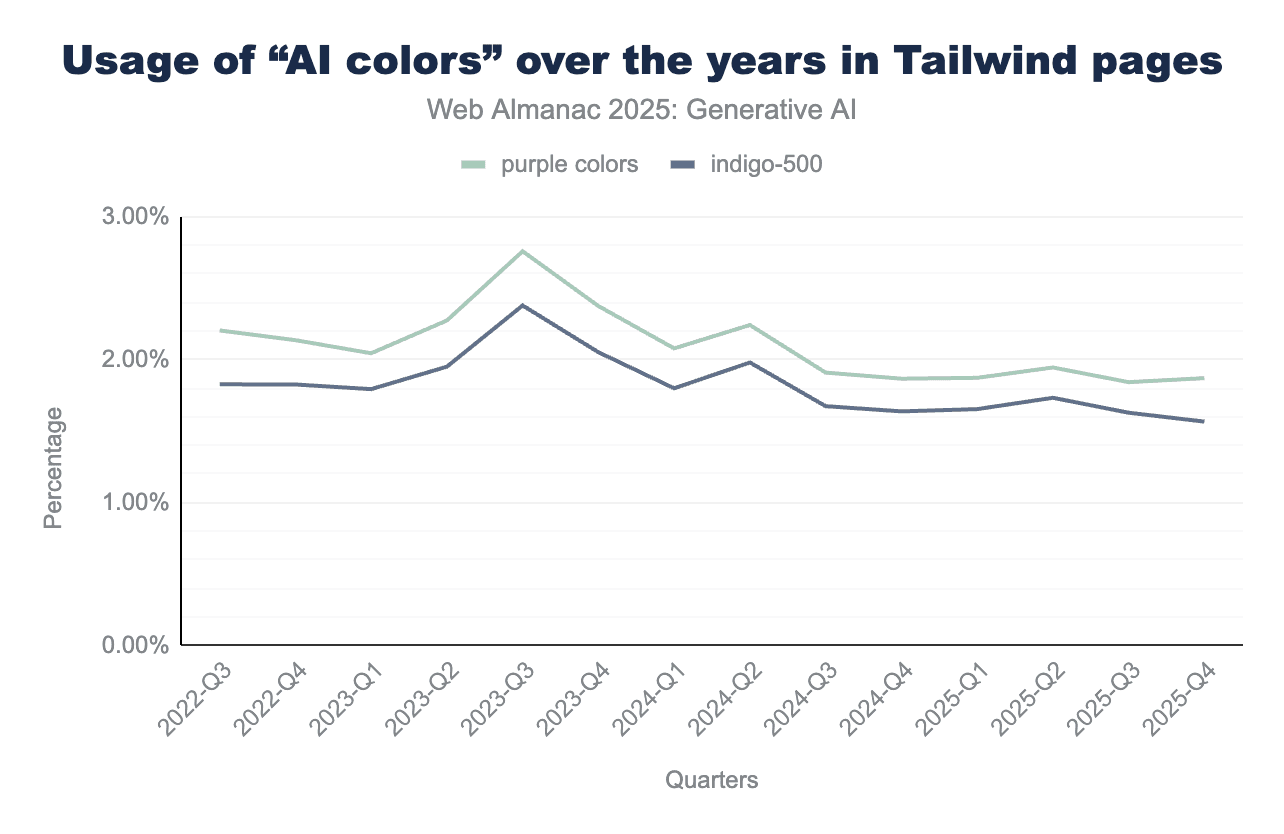
TailwindはClaude、Gemini、OpenAIモデルなどのLLMが好むフレームワークであるため、これらの指標を使用しているTailwindベースのウェブサイトの割合を特に調べました。TailwindウェブページはHTTP ArchiveのWappalyzerフォークを使用して識別されました。驚くことに、indigo-500または他の2つの一般的に言及されるAIカラー(#8b5cf6バイオレットと#a855f7パープル)を使用するウェブサイトに顕著なサージは見られませんでした。
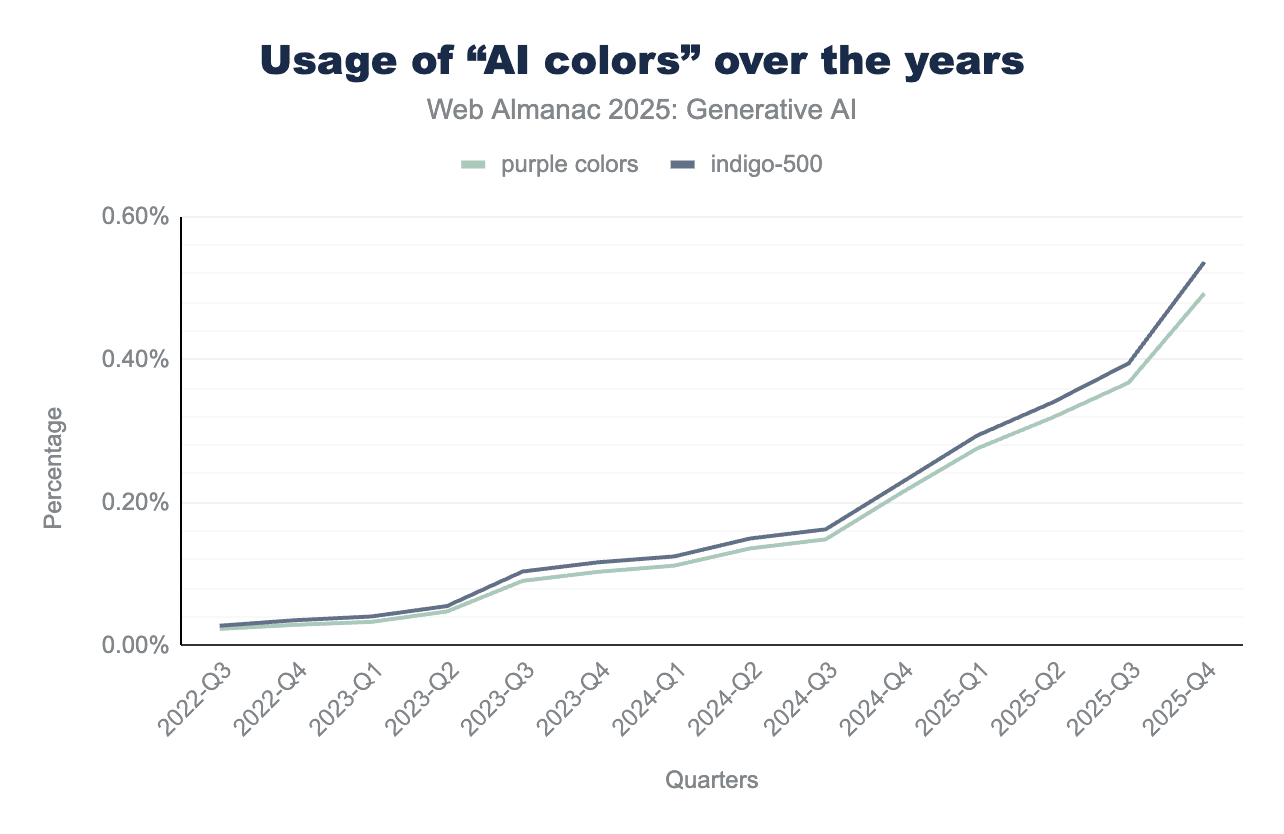
しかし、Tailwindフレームワークの全体的な爆発的成長により、ウェブ全体の割合として測定した場合、これらの特定のカラーは大幅な増加を示しました。
分析はCSSの変数のみに依存しており、ソースコード全体を解析すると現実的な限界を超えるためです。その結果、私たちの数値は控えめな推定値を表しています。ハードコードされた16進数値(例:#6366f1)や古いプリプロセッサを使用しているサイトはクエリで見えませんでした。さらに、カラーの明度を1%調整するだけでも検出を回避できます。
「AIスロップ」や紫がかったデザインに関するオンラインでの頻繁な議論にもかかわらず、HTTP Archiveデータセットの分析は、このトレンドがAIが紫を「選択した」結果というよりも、Tailwindの人気の全般的な上昇を反映しているかもしれないことを示唆しています。
グラデーション、シャドウ、特定のフォントのサージもテストしましたが、統計的に有意な増加は見られませんでした。
バイブコーディングプラットフォーム
新たに作成されるウェブサイトの数が多い理由の1つは、ウェブサイト構築を容易にするプラットフォームの出現です。前の10年間のコンテンツ管理システム(CMS)ツールの普及後、ユーザーはそれらの制約を超えて、v0、Replit、またはLovableなどのツールを使用して会話型AIを通じてウェブサイトを生成できるようになりました。これらのプラットフォームでは、独自のドメインまたはプラットフォーム提供のサブドメイン(例:mywebsite.tool.com)を使用してページを公開できます。
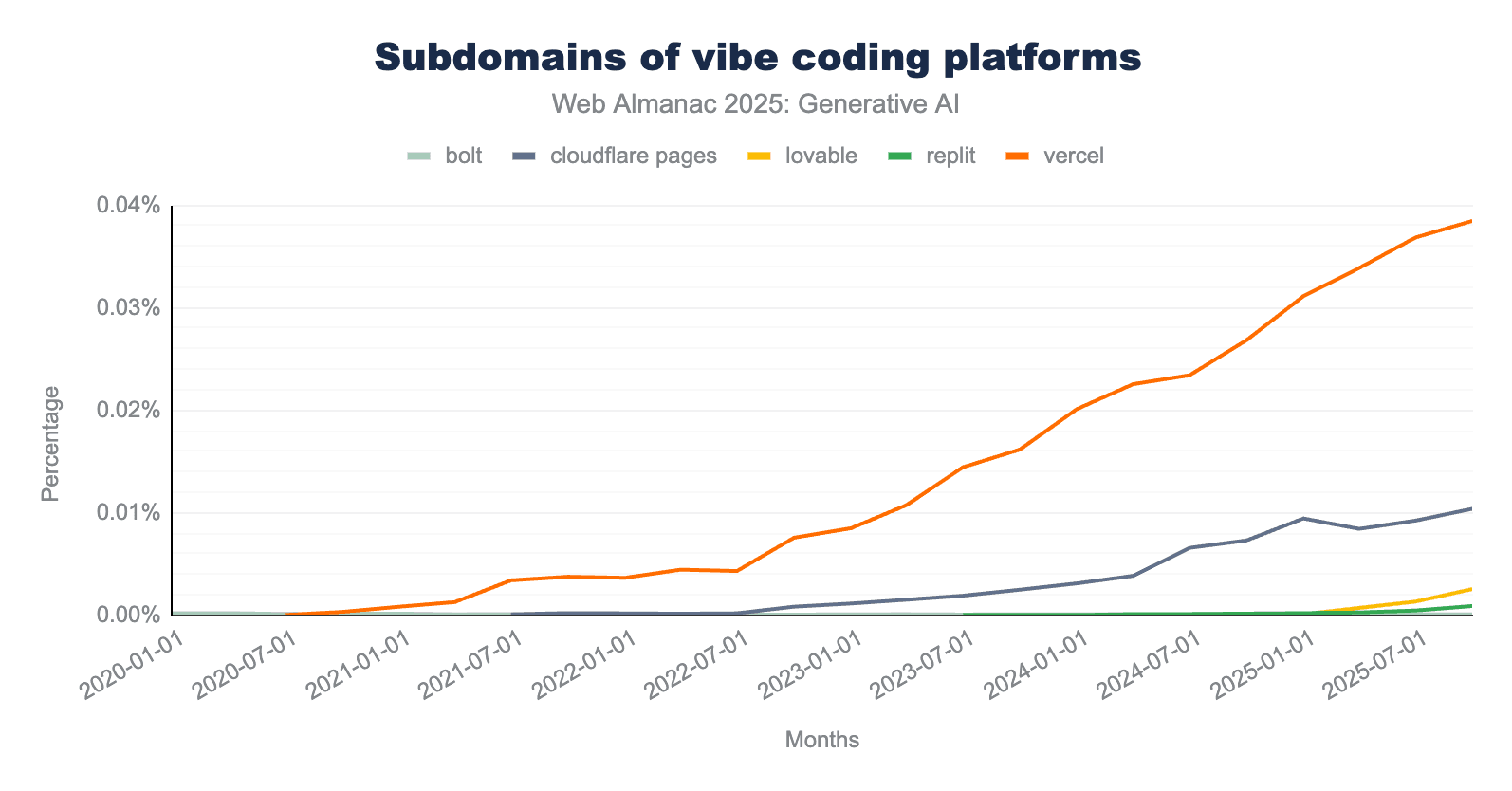
上図はHTTP Archiveデータセット内でのバイブコーディングプラットフォームのサブドメインの相対的な成長を示しています。Vercel(*.vercel.app)が依然として支配的なプロバイダーですが、2023年後半のバイブコーディングツールv0(*.v0.dev)のリリースよりずっと前からサブドメインホスティングを提供していました。データはv0のローンチ後の即時サージを示していませんでした。Lovable(*.lovable.appと*.lovable.dev)は2025年初頭の10サブドメインから2025年10月には315に成長しました。これはデータセットで利用可能なページのみを含むことに注意してください。Lovableによると、Lovableでは毎日100,000もの新しいプロジェクトが構築されています。
.aiドメイン
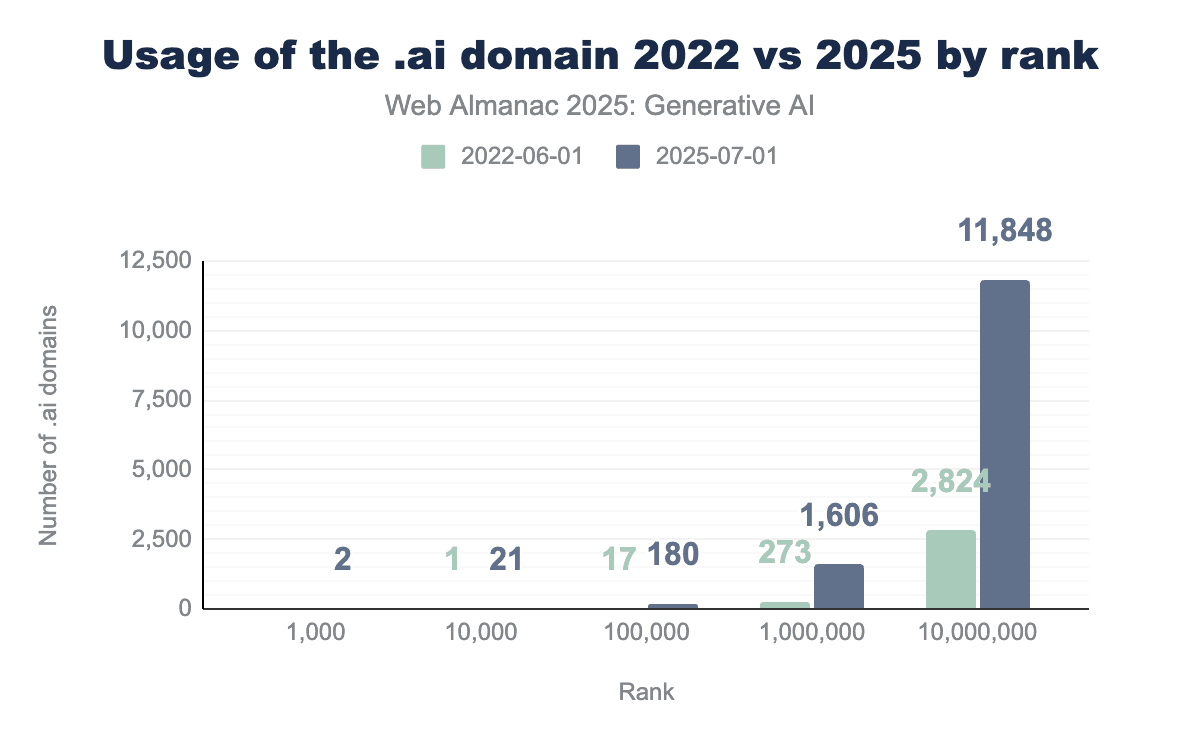
AIも.aiドメインもChatGPT以前から存在していましたが、ChatGPT登場後に生まれた新たな可能性がAIネイティブビジネスの波をもたらしました。その多くはアンギラの国コードである.aiトップレベルドメインを採用しました。このトレンドは、上図に示す2022年のChatGPT以前の状況と2025年の使用状況の比較が示すように、すべてのランクにわたって.aiドメイン登録の大幅な増加をもたらしました。
Chromeデータセットでトップ1,000の最も訪問されたウェブサイトに入った.aiドメインは、https://character.aiとアダルトサイトの2つのみでした。
結論
2025年、生成AIはクラウド専用技術から基本的なブラウザコンポーネントへと移行しました。BYOAIはWebAssemblyやWebGPUなどの基盤APIの成長、またWebLLMやTransformers.jsなどのライブラリに後押しされて即時採用を支配しました。同時に、組み込みAIはブラウザ内に直接標準化されたAIレイヤーの基盤を築き始めました。より制限的なrobots.txtファイルと歓迎的なllms.txtの構造の間に緊張関係が生まれています。バイブコーディングと.aiドメインの台頭は、AIがアプリの機能だけでなく、アプリの構築方法も再形成していることを証明しています。
2025年を超えて見ると、次の進化の飛躍はすでに見えています:エージェントAIです。インタラクティブなチャットボットの時代から、継続的なユーザー介入なしに意思決定、マルチステップワークフローの実行、複雑なタスクの解決ができる自律エージェントへと移行しています。このシフトは、Perplexity Comet、ChatGPT Atlas、またはOpera Neonなどの新しいクラスの「エージェントブラウザ」の台頭をもたらしています。
これらのエージェントをウェブの広大なリソースに接続するために、WebMCP(Web Model Context Protocol)などの新しいプロトコルが登場しています。HTTPがリソースの送信を標準化するように、WebMCPはエージェントがウェブインターフェースを認識し操作する方法を標準化することを目指しており、AIネイティブウェブが読み取り可能なだけでなく、アクション可能であることを保証します。


