Caching
Introduction
Caching is a technique that enables the reuse of previously downloaded content. It provides a significant performance benefit by avoiding costly network requests and it also helps scale an application by reducing the traffic to a website’s origin infrastructure. There’s an old saying, “the fastest request is the one that you don’t have to make,” and caching is one of the key ways to avoid having to make requests.
There are three guiding principles to caching web content: cache as much as you can, for as long as you can, as close as you can to end users.
Cache as much as you can. When considering how much can be cached, it is important to understand whether a response is static or dynamic. Requests that are served as a static response are typically cacheable, as they have a one-to-many relationship between the resource and the users requesting it. Dynamically generated content can be more nuanced and require careful consideration.
Cache for as long as you can. The length of time you would cache a resource is highly dependent on the sensitivity of the content being cached. A versioned JavaScript resource could be cached for a very long time, while a non-versioned resource may need a shorter cache duration to ensure users get a fresh version.
Cache as close to end users as you can. Caching content close to the end user reduces download times by removing latency. For example, if a resource is cached on an end user’s browser, then the request never goes out to the network and the download time is as fast as the machine’s I/O. For first time visitors, or visitors that don’t have entries in their cache, a CDN would typically be the next place a cached resource is returned from. In most cases, it will be faster to fetch a resource from a local cache or a CDN compared to an origin server.
Web architectures typically involve multiple tiers of caching. For example, an HTTP request may have the opportunity to be cached in:
- An end user’s browser
- A service worker cache in the user’s browser
- A shared gateway
- CDNs, which offer the ability to cache at the edge, close to end users
- A caching proxy in front of the application, to reduce the backend workload
- The application and database layers
This chapter will explore how resources are cached within web browsers.
Overview of HTTP caching
For an HTTP client to cache a resource, it needs to understand two pieces of information:
- “How long am I allowed to cache this for?”
- “How do I validate that the content is still fresh?”
When a web browser sends a response to a client, it typically includes headers that indicate whether the resource is cacheable, how long to cache it for, and how old the resource is. RFC 7234 covers this in more detail in section 4.2 (Freshness) and 4.3 (Validation).
The HTTP response headers typically used for conveying freshness lifetime are:
Cache-Controlallows you to configure a cache lifetime duration (i.e. how long this is valid for).Expiresprovides an expiration date or time (i.e. when exactly this expires).
Cache-Control takes priority if both are present. These are discussed in more detail below.
The HTTP response headers for validating the responses stored within the cache, i.e. giving conditional requests something to compare to on the server side, are:
Last-Modifiedindicates when the object was last changed.- Entity Tag (
ETag) provides a unique identifier for the content.
ETag takes priority if both are present. These are discussed in more detail below.
The example below contains an excerpt of a request/response header from HTTP Archive’s main.js file. These headers indicate that the resource can be cached for 43,200 seconds (12 hours), and it was last modified more than two months ago (difference between the Last-Modified and Date headers).
> GET /static/js/main.js HTTP/1.1
> Host: httparchive.org
> User-agent: curl/7.54.0
> Accept: */*
< HTTP/1.1 200
< Date: Sun, 13 Oct 2019 19:36:57 GMT
< Content-Type: application/javascript; charset=utf-8
< Content-Length: 3052
< Vary: Accept-Encoding
< Server: gunicorn/19.7.1
< Last-Modified: Sun, 25 Aug 2019 16:00:30 GMT
< Cache-Control: public, max-age=43200
< Expires: Mon, 14 Oct 2019 07:36:57 GMT
< ETag: "1566748830.0-3052-3932359948"The tool RedBot.org allows you to input a URL and see a detailed explanation of how the response would be cached based on these headers. For example, a test for the URL above would output the following:
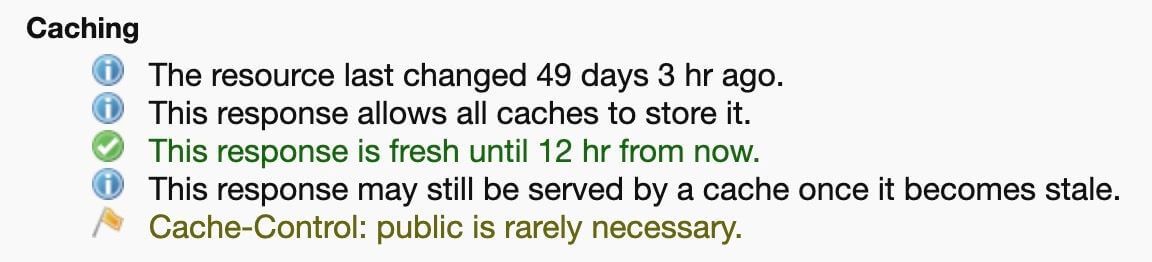
Cache-Control information from RedBot.
If no caching headers are present in a response, then the client is permitted to heuristically cache the response. Most clients implement a variation of the RFC’s suggested heuristic, which is 10% of the time since Last-Modified. However, some may cache the response indefinitely. So, it is important to set specific caching rules to ensure that you are in control of the cacheability.
72% of responses are served with a Cache-Control header, and 56% of responses are served with an Expires header. However, 27% of responses did not use either header, and therefore are subject to heuristic caching. This is consistent across both desktop and mobile sites.
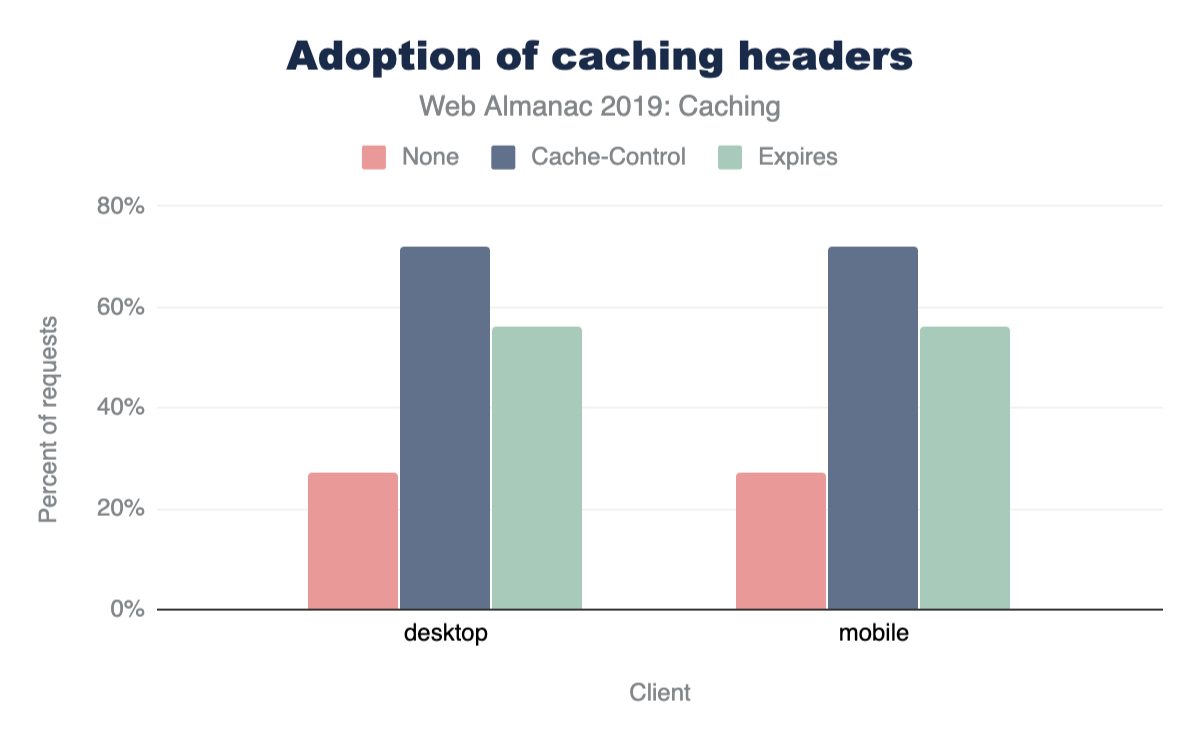
Cache-Control and Expires headers.
What type of content are we caching?
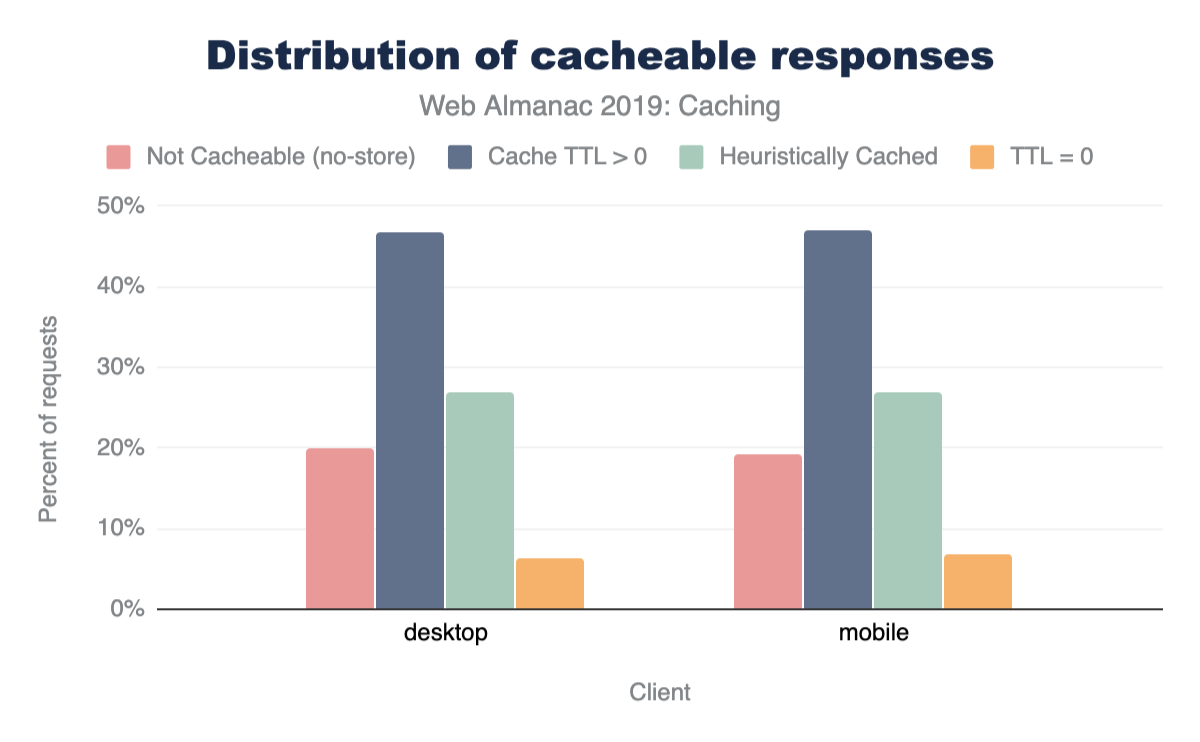
A cacheable resource is stored by the client for a period of time and available for reuse on a subsequent request. Across all HTTP requests, 80% of responses are considered cacheable, meaning that a cache is permitted to store them. Out of these,
- 6% of requests have a time to live (TTL) of 0 seconds, which immediately invalidates a cached entry.
- 27% are cached heuristically because of a missing
Cache-Controlheader. - 47% are cached for more than 0 seconds.
The remaining responses are not permitted to be stored in browser caches.
The table below details the cache TTL values for desktop requests by type. Most content types are being cached however CSS resources appear to be consistently cached at high TTLs.
| Desktop Cache TTL Percentiles (Hours) | |||||
|---|---|---|---|---|---|
| 10 | 25 | 50 | 75 | 90 | |
| Audio | 12 | 24 | 720 | 8,760 | 8,760 |
| CSS | 720 | 8,760 | 8,760 | 8,760 | 8,760 |
| Font | < 1 | 3 | 336 | 8,760 | 87,600 |
| HTML | < 1 | 168 | 720 | 8,760 | 8,766 |
| Image | < 1 | 1 | 28 | 48 | 8,760 |
| Other | < 1 | 2 | 336 | 8,760 | 8,760 |
| Script | < 1 | < 1 | 1 | 6 | 720 |
| Text | 21 | 336 | 7,902 | 8,357 | 8,740 |
| Video | < 1 | 4 | 24 | 24 | 336 |
| XML | < 1 | < 1 | < 1 | < 1 | < 1 |
While most of the median TTLs are high, the lower percentiles highlight some of the missed caching opportunities. For example, the median TTL for images is 28 hours, however the 25th percentile is just one-two hours and the 10th percentile indicates that 10% of cacheable image content is cached for less than one hour.
By exploring the cacheability by content type in more detail in Figure 16.5 below, we can see that approximately half of all HTML responses are considered non-cacheable. Additionally, 16% of images and scripts are non-cacheable.
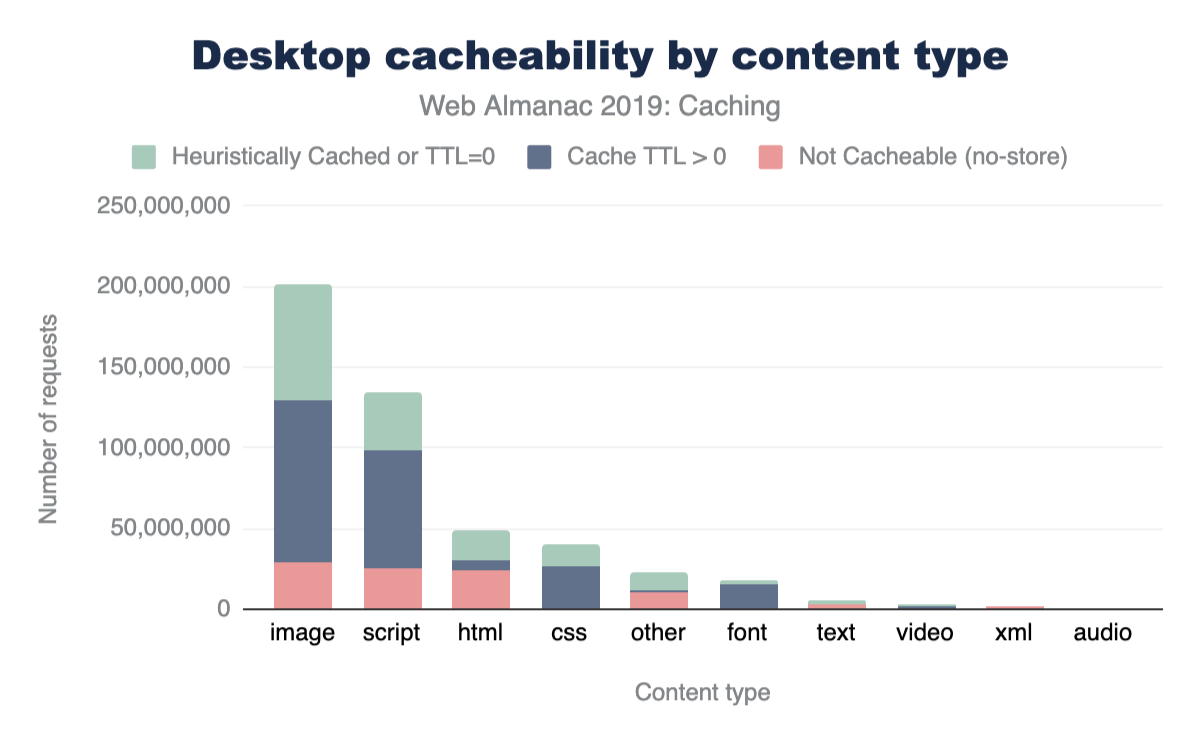
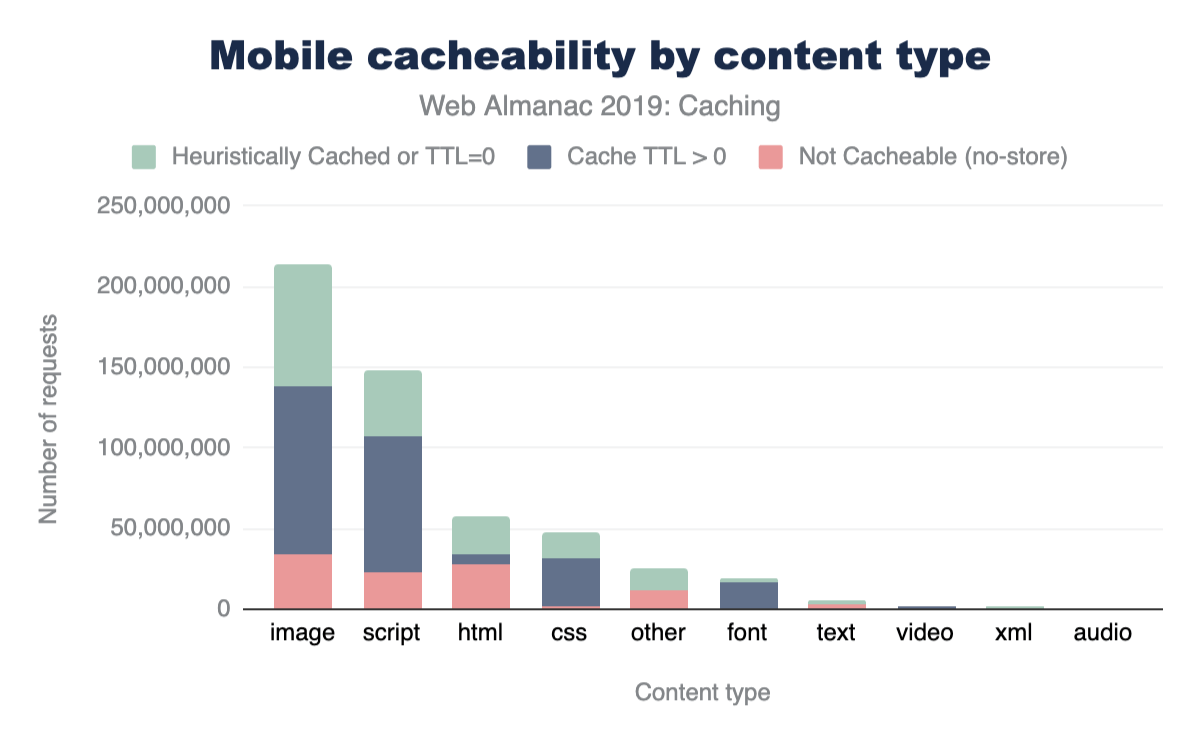
The same data for mobile is shown below. As can be seen, the cacheability of content types is consistent between desktop and mobile.
Cache-Control vs Expires
In HTTP/1.0, the Expires header was used to indicate the date/time after which the response is considered stale. Its value is a date timestamp, such as:
Expires: Thu, 01 Dec 1994 16:00:00 GMT
HTTP/1.1 introduced the Cache-Control header, and most modern clients support both headers. This header provides much more extensibility via caching directives. For example:
no-storecan be used to indicate that a resource should not be cached.max-agecan be used to indicate a freshness lifetime.must-revalidatetells the client a cached entry must be validated with a conditional request prior to its use.privateindicates a response should only be cached by a browser, and not by an intermediary that would serve multiple clients.
53% of HTTP responses include a Cache-Control header with the max-age directive, and 54% include the Expires header. However, only 41% of these responses use both headers, which means that 13% of responses are caching solely based on the older Expires header.
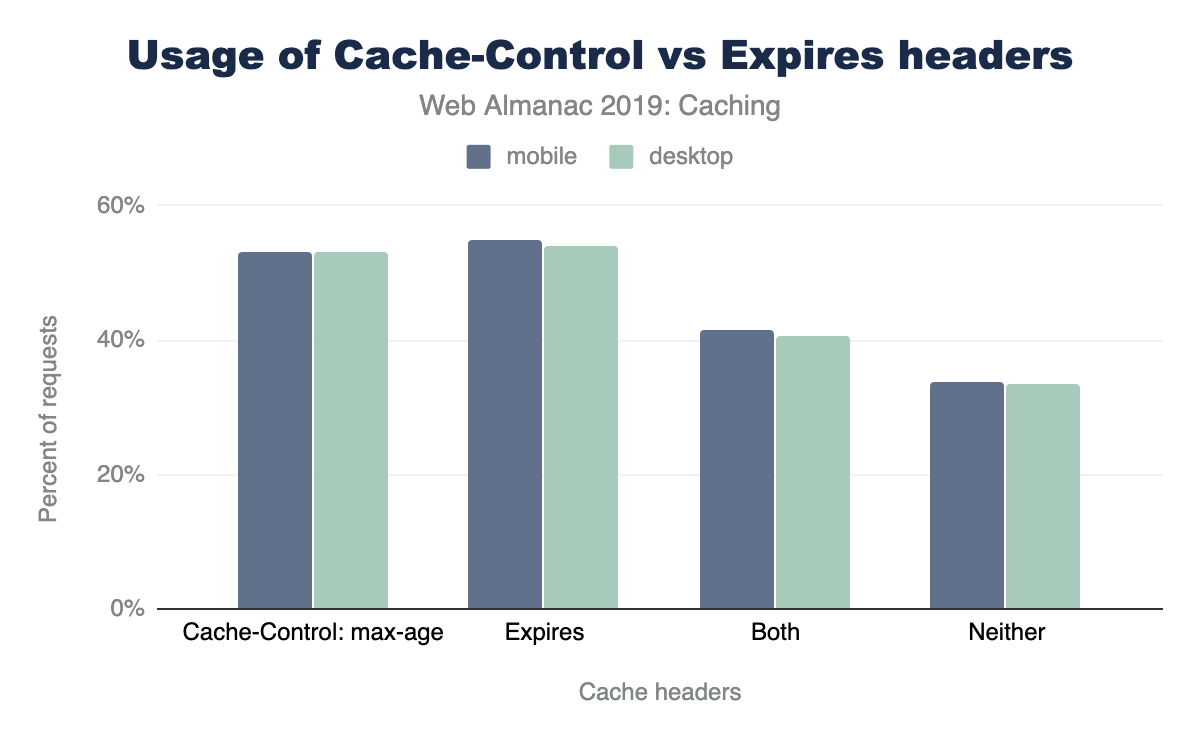
Cache-Control: max-age, 54%-55% use Expires, 41%-42% use both, and 34% use neither. The figures are given for both desktop and mobile but the figures are near identical with mobile having a percentage point higher in use of expires.Cache-Control versus Expires headers.
Cache-Control directives
The HTTP/1.1 specification includes multiple directives that can be used in the Cache-Control response header and are detailed below. Note that multiple can be used in a single response.
| Directive | Description |
|---|---|
| max-age | Indicates the number of seconds that a resource can be cached for. |
| public | Any cache may store the response. |
| no-cache | A cached entry must be revalidated prior to its use. |
| must-revalidate | A stale cached entry must be revalidated prior to its use. |
| no-store | Indicates that a response is not cacheable. |
| private | The response is intended for a specific user and should not be stored by shared caches. |
| no-transform | No transformations or conversions should be made to this resource. |
| proxy-revalidate | Same as must-revalidate but applies to shared caches. |
| s-maxage | Same as max age but applies to shared caches only. |
| immutable | Indicates that the cached entry will never change, and that revalidation is not necessary. |
| stale-while-revalidate | Indicates that the client is willing to accept a stale response while asynchronously checking in the background for a fresh one. |
| stale-if-error | Indicates that the client is willing to accept a stale response if the check for a fresh one fails. |
Cache-Control directives.
For example, cache-control: public, max-age=43200 indicates that a cached entry should be stored for 43,200 seconds and it can be stored by all caches.
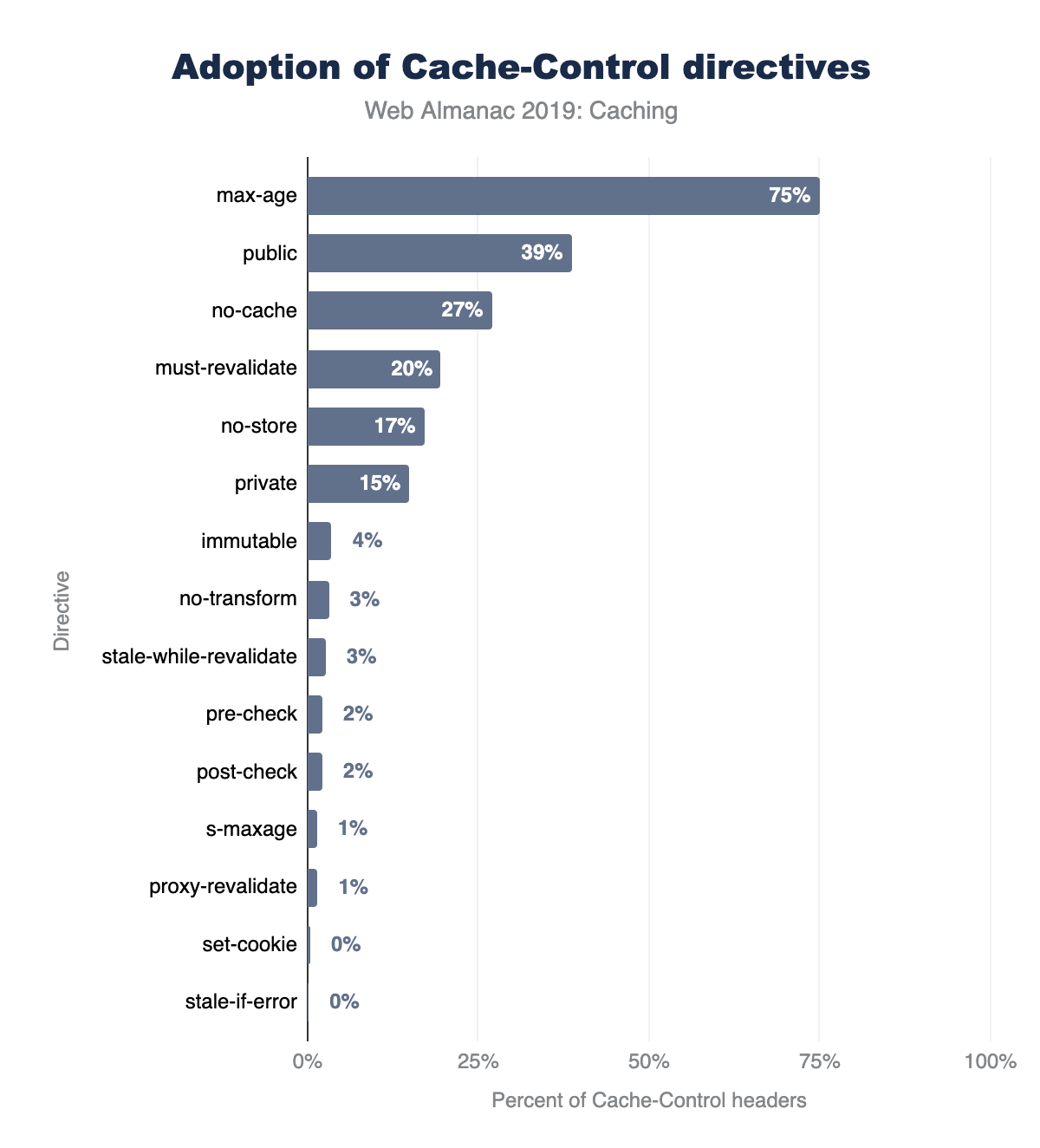
Cache-Control directives on mobile.
Figure 16.9 above illustrates the top 15 Cache-Control directives in use on mobile websites. The results for desktop and mobile are very similar. There are a few interesting observations about the popularity of these cache directives:
max-ageis used by almost 75% ofCache-Controlheaders, andno-storeis used by 18%.publicis rarely necessary since cached entries are assumedpublicunlessprivateis specified. Approximately 38% of responses includepublic.- The
immutabledirective is relatively new, introduced in 2017 and is supported on Firefox and Safari. Its usage has grown to 3.4%, and it is widely used in Facebook and Google third-party responses.
Another interesting set of directives to show up in this list are pre-check and post-check, which are used in 2.2% of Cache-Control response headers (approximately 7.8 million responses). This pair of headers was introduced in Internet Explorer 5 to provide a background validation and was rarely implemented correctly by websites. 99.2% of responses using these headers had used the combination of pre-check=0 and post-check=0. When both of these directives are set to 0, then both directives are ignored. So, it seems these directives were never used correctly!
In the long tail, there are more than 1,500 erroneous directives in use across 0.28% of responses. These are ignored by clients, and include misspellings such as “nocache”, “s-max-age”, “smax-age”, and “maxage”. There are also numerous non-existent directives such as “max-stale”, “proxy-public”, “surrogate-control”, etc.
Cache-Control: no-store, no-cache and max-age=0
When a response is not cacheable, the Cache-Control no-store directive should be used. If this directive is not used, then the response is cacheable.
There are a few common errors that are made when attempting to configure a response to be non-cacheable:
- Setting
Cache-Control: no-cachemay sound like the resource will not be cacheable. However, theno-cachedirective requires the cached entry to be revalidated prior to use and is not the same as being non-cacheable. - Setting
Cache-Control: max-age=0sets the TTL to 0 seconds, but that is not the same as being non-cacheable. Whenmax-ageis set to 0, the resource is stored in the browser cache and immediately invalidated. This results in the browser having to perform a conditional request to validate the resource’s freshness.
Functionally, no-cache and max-age=0 are similar, since they both require revalidation of a cached resource. The no-cache directive can also be used alongside a max-age directive that is greater than 0.
Over 3 million responses include the combination of no-store, no-cache, and max-age=0. Of these directives no-store takes precedence and the other directives are merely redundant
18% of responses include no-store and 16.6% of responses include both no-store and no-cache. Since no-store takes precedence, the resource is ultimately non-cacheable.
The max-age=0 directive is present on 1.1% of responses (more than four million responses) where no-store is not present. These resources will be cached in the browser but will require revalidation as they are immediately expired.
How do cache TTLs compare to resource age?
So far we’ve talked about how web servers tell a client what is cacheable, and how long it has been cached for. When designing cache rules, it is also important to understand how old the content you are serving is.
When you are selecting a cache TTL, ask yourself: “how often are you updating these assets?” and “what is their content sensitivity?”. For example, if a hero image is going to be modified infrequently, then cache it with a very long TTL. If you expect a JavaScript resource to change frequently, then version it and cache it with a long TTL or cache it with a shorter TTL.
The graph below illustrates the relative age of resources by content type, and you can read a more detailed analysis here. HTML tends to be the content type with the shortest age, and a very large % of traditionally cacheable resources (scripts, CSS, and fonts) are older than one year!
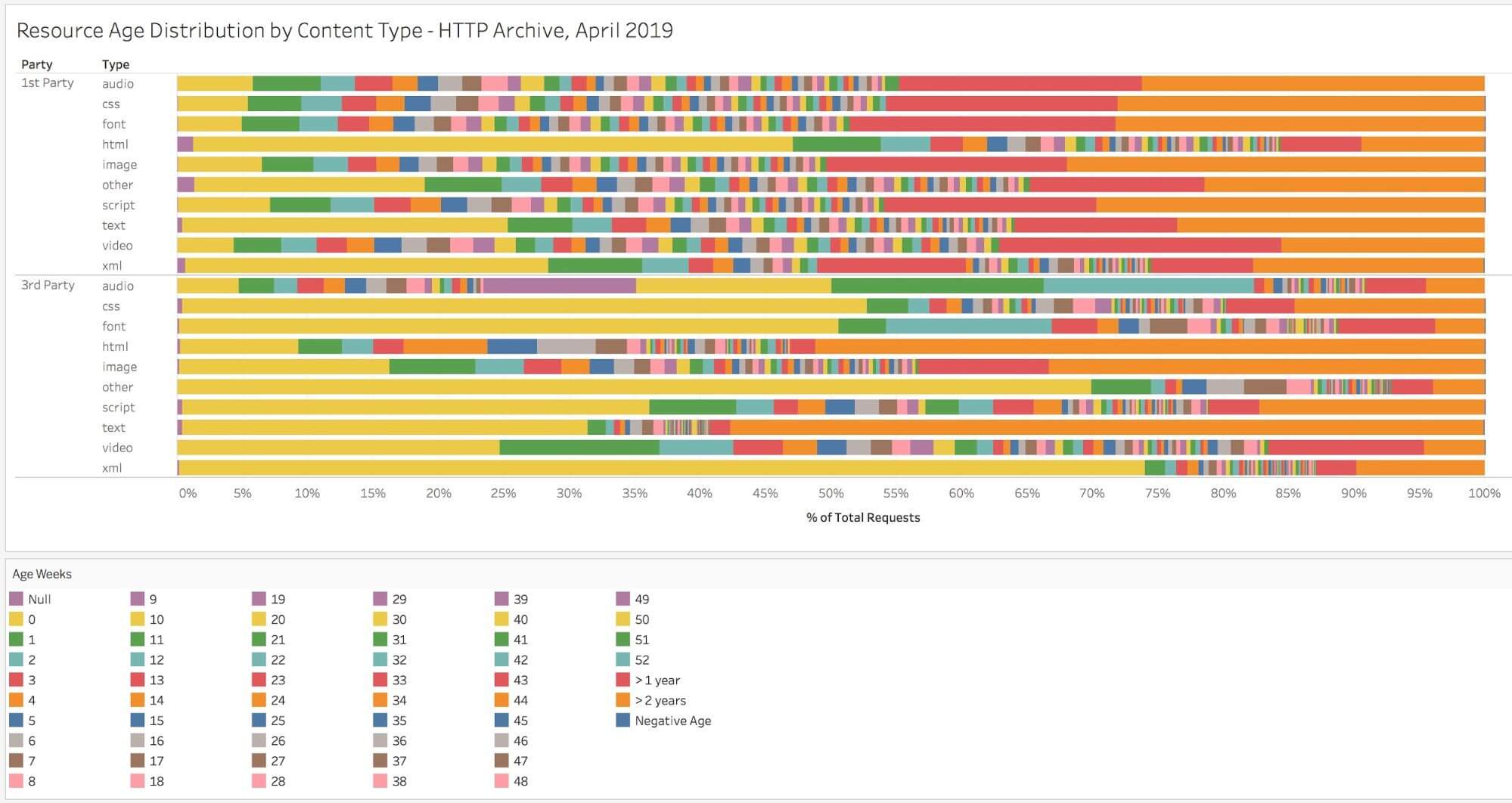
By comparing a resources cacheability to its age, we can determine if the TTL is appropriate or too low. For example, the resource served by the response below was last modified on 25 Aug 2019, which means that it was 49 days old at the time of delivery. The Cache-Control header says that we can cache it for 43,200 seconds, which is 12 hours. It is definitely old enough to merit investigating whether a longer TTL would be appropriate.
< HTTP/1.1 200
< Date: Sun, 13 Oct 2019 19:36:57 GMT
< Content-Type: application/javascript; charset=utf-8
< Content-Length: 3052
< Vary: Accept-Encoding
< Server: gunicorn/19.7.1
< Last-Modified: Sun, 25 Aug 2019 16:00:30 GMT
< Cache-Control: public, max-age=43200
< Expires: Mon, 14 Oct 2019 07:36:57 GMT
< ETag: "1566748830.0-3052-3932359948"Overall, 59% of resources served on the web have a cache TTL that is too short compared to its content age. Furthermore, the median delta between the TTL and age is 25 days.
When we break this out by first vs third-party, we can also see that 70% of first-party resources can benefit from a longer TTL. This clearly highlights a need to spend extra attention focusing on what is cacheable, and then ensuring caching is configured correctly.
| Client | 1st Party | 3rd Party | Overall |
|---|---|---|---|
| Desktop | 70.7% | 47.9% | 59.2% |
| Mobile | 71.4% | 46.8% | 59.6% |
Validating freshness
The HTTP response headers used for validating the responses stored within a cache are Last-Modified and ETag. The Last-Modified header does exactly what its name implies and provides the time that the object was last modified. The ETag header provides a unique identifier for the content.
For example, the response below was last modified on 25 Aug 2019 and it has an ETag value of "1566748830.0-3052-3932359948"
< HTTP/1.1 200
< Date: Sun, 13 Oct 2019 19:36:57 GMT
< Content-Type: application/javascript; charset=utf-8
< Content-Length: 3052
< Vary: Accept-Encoding
< Server: gunicorn/19.7.1
< Last-Modified: Sun, 25 Aug 2019 16:00:30 GMT
< Cache-Control: public, max-age=43200
< Expires: Mon, 14 Oct 2019 07:36:57 GMT
< ETag: "1566748830.0-3052-3932359948"A client could send a conditional request to validate a cached entry by using the Last-Modified value in a request header named If-Modified-Since. Similarly, it could also validate the resource with an If-None-Match request header, which validates against the ETag value the client has for the resource in its cache.
In the example below, the cache entry is still valid, and an HTTP 304 was returned with no content. This saves the download of the resource itself. If the cache entry was no longer fresh, then the server would have responded with a 200 and the updated resource which would have to be downloaded again.
> GET /static/js/main.js HTTP/1.1
> Host: www.httparchive.org
> User-Agent: curl/7.54.0
> Accept: */*
> If-Modified-Since: Sun, 25 Aug 2019 16:00:30 GMT
< HTTP/1.1 304
< Date: Thu, 17 Oct 2019 02:31:08 GMT
< Server: gunicorn/19.7.1
< Cache-Control: public, max-age=43200
< Expires: Thu, 17 Oct 2019 14:31:08 GMT
< ETag: "1566748830.0-3052-3932359948"
< Accept-Ranges: bytesOverall, 65% of responses are served with a Last-Modified header, 42% are served with an ETag, and 38% use both. However, 30% of responses include neither a Last-Modified or ETag header.
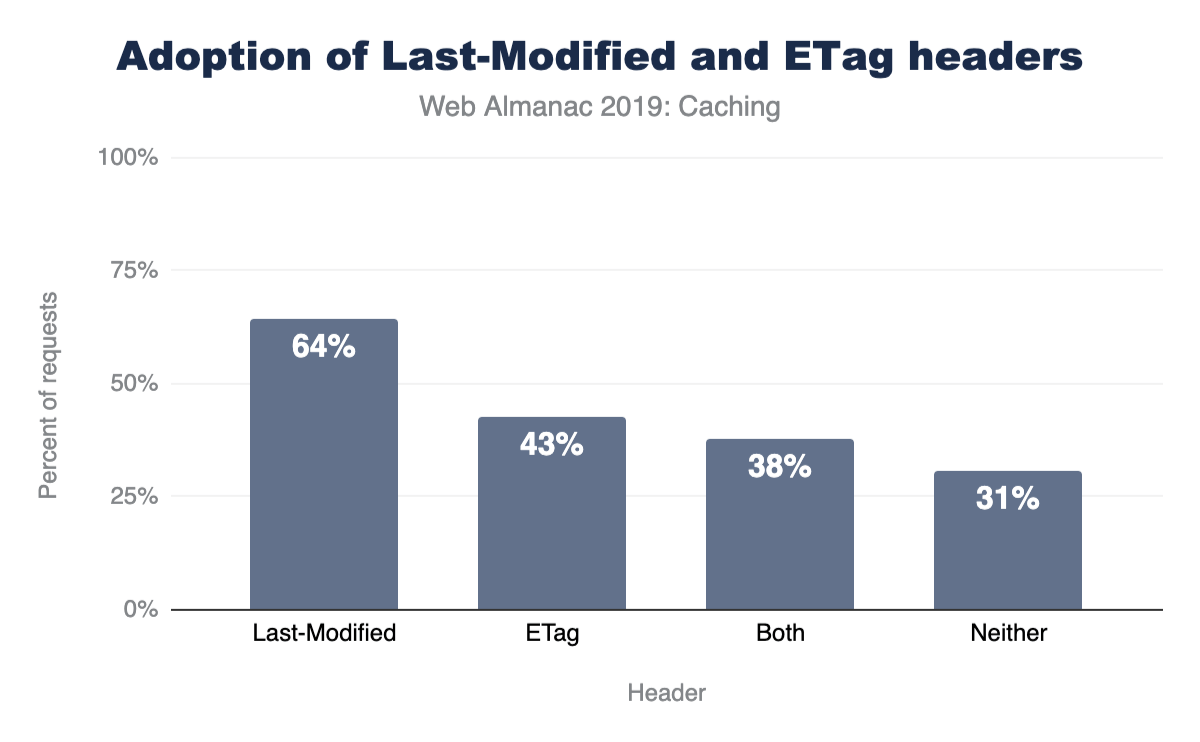
Last-Modified and ETag headers for desktop websites.
Validity of date strings
There are a few HTTP headers used to convey timestamps, and the format for these are very important. The Date response header indicates when the resource was served to a client. The Last-Modified response header indicates when a resource was last changed on the server. And the Expires header is used to indicate how long a resource is cacheable until (unless a Cache-Control header is present).
All three of these HTTP headers use a date formatted string to represent timestamps.
For example:
> GET /static/js/main.js HTTP/1.1
> Host: httparchive.org
> User-Agent: curl/7.54.0
> Accept: */*
< HTTP/1.1 200
< Date: Sun, 13 Oct 2019 19:36:57 GMT
< Content-Type: application/javascript; charset=utf-8
< Content-Length: 3052
< Vary: Accept-Encoding
< Server: gunicorn/19.7.1
< Last-modified: Sun, 25 Aug 2019 16:00:30 GMT
< Cache-Control: public, max-age=43200
< Expires: Mon, 14 Oct 2019 07:36:57 GMT
< ETag: "1566748830.0-3052-3932359948"Most clients will ignore invalid date strings, which render them ineffective for the response they are served on. This can have consequences on cacheability, since an erroneous Last-Modified header will be cached without a Last-Modified timestamp resulting in the inability to perform a conditional request.
The Date HTTP response header is usually generated by the web server or CDN serving the response to a client. Because the header is typically generated automatically by the server, it tends to be less prone to error, which is reflected by the very low percentage of invalid Date headers. Last-Modified headers were very similar, with only 0.67% of them being invalid. What was very surprising to see though, was that 3.64% Expires headers used an invalid date format!
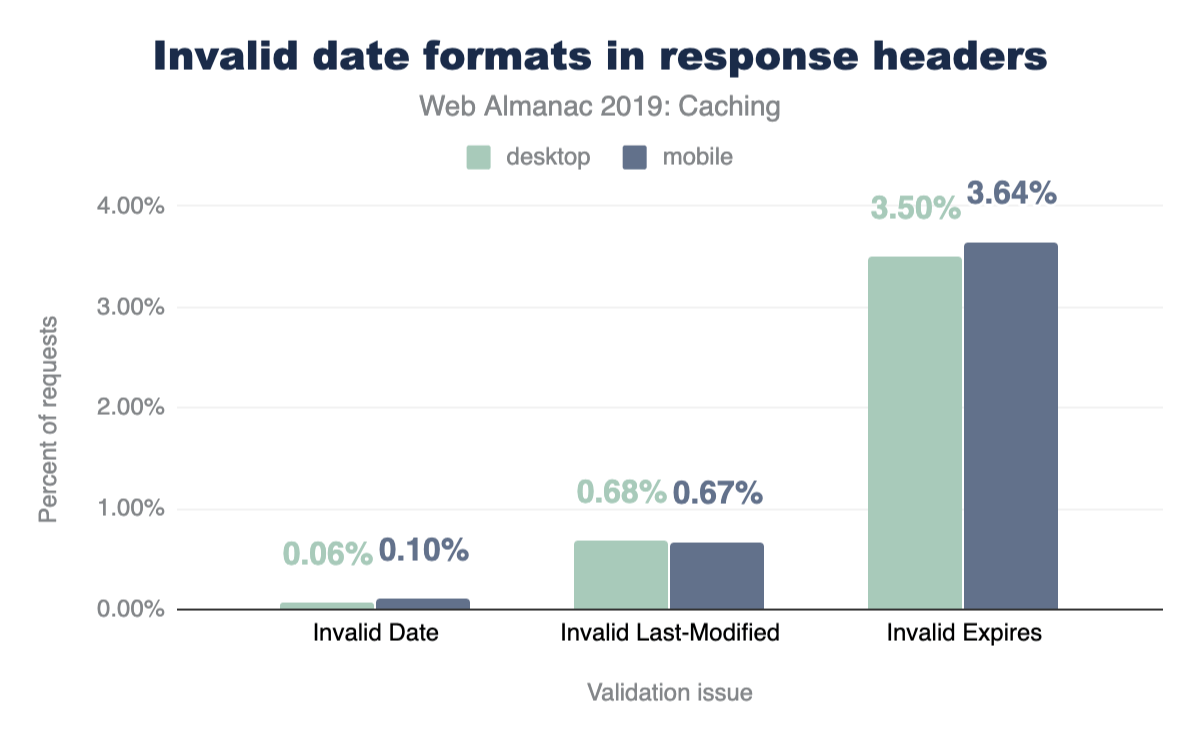
Examples of some of the invalid uses of the Expires header are:
- Valid date formats, but using a time zone other than GMT
- Numerical values such as 0 or -1
- Values that would be valid in a
Cache-Controlheader
The largest source of invalid Expires headers is from assets served from a popular third-party, in which a date/time uses the EST time zone, for example Expires: Tue, 27 Apr 1971 19:44:06 EST.
Vary header
One of the most important steps in caching is determining if the resource being requested is cached or not. While this may seem simple, many times the URL alone is not enough to determine this. For example, requests with the same URL could vary in what compression they used (Gzip, Brotli, etc.) or be modified and tailored for mobile visitors.
To solve this problem, clients give each cached resource a unique identifier (a cache key). By default, this cache key is simply the URL of the resource, but developers can add other elements (like compression method) by using the Vary header.
A Vary header instructs a client to add the value of one or more request header values to the cache key. The most common example of this is Vary: Accept-Encoding, which will result in different cached entries for Accept-Encoding request header values (i.e. gzip, br, deflate).
Another common value is Vary: Accept-Encoding, User-Agent, which instructs the client to vary the cached entry by both the Accept-Encoding values and the User-Agent string. When dealing with shared proxies and CDNs, using values other than Accept-Encoding can be problematic as it dilutes the cache keys and can reduce the amount of traffic served from cache.
In general, you should only vary the cache if you are serving alternate content to clients based on that header.
The Vary header is used on 39% of HTTP responses, and 45% of responses that include a Cache-Control header.
The graph below details the popularity for the top 10 Vary header values. Accept-Encoding accounts for 90% of Vary’s use, with User-Agent (11%), Origin (9%), and Accept (3%) making up much of the rest.
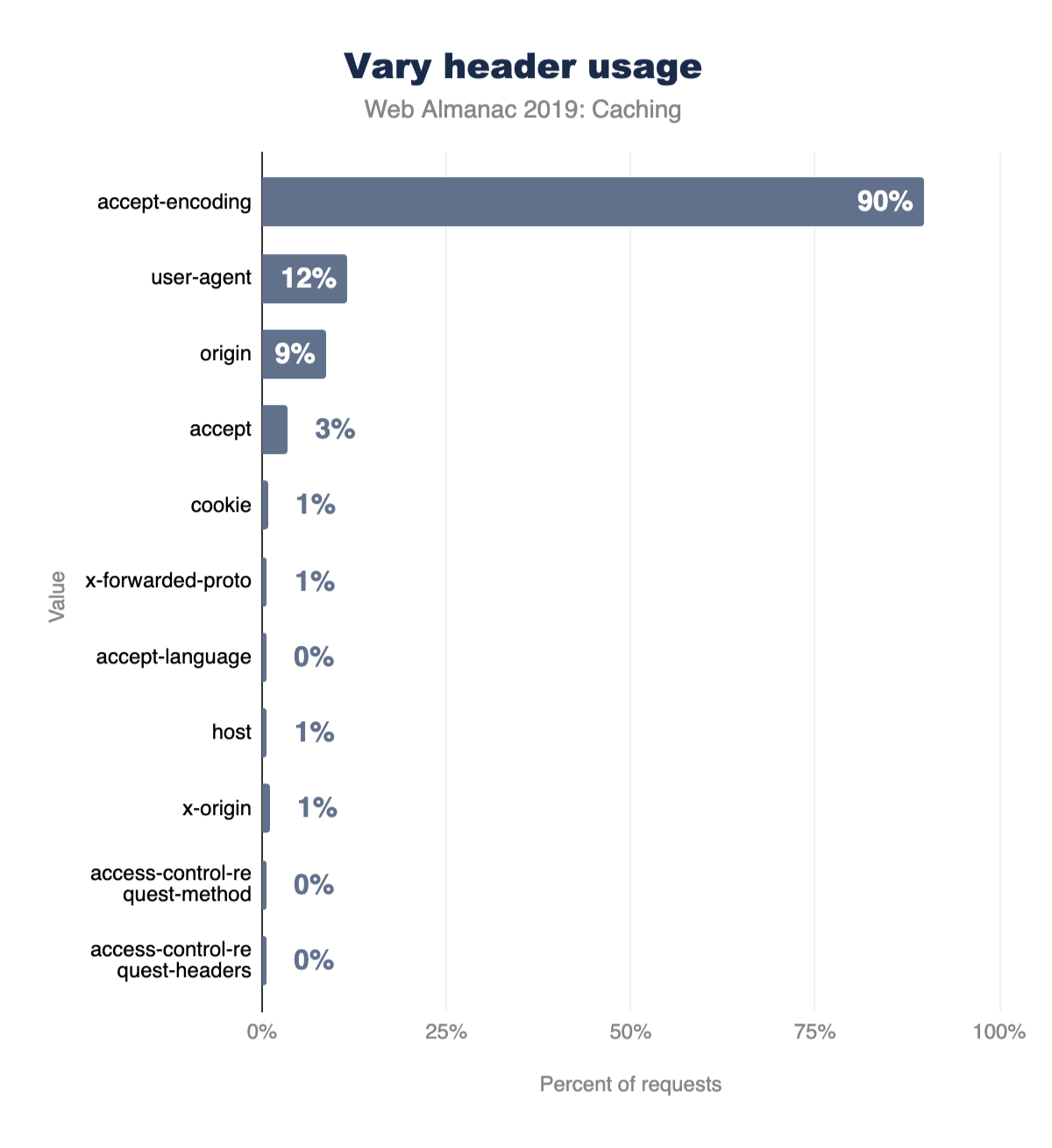
Setting cookies on cacheable responses
When a response is cached, its entire headers are swapped into the cache as well. This is why you can see the response headers when inspecting a cached response via DevTools.
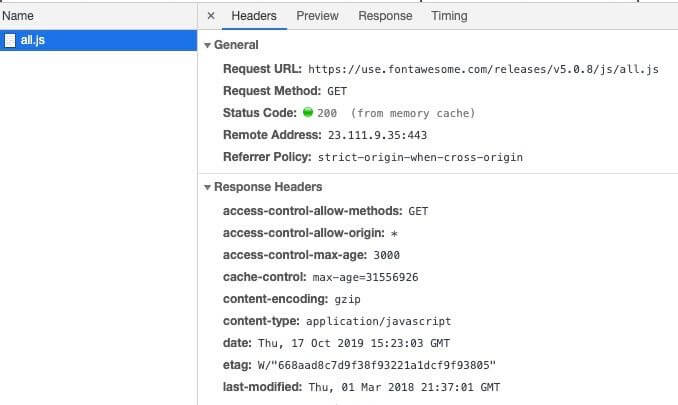
But what happens if you have a Set-Cookie on a response? According to RFC 7234 Section 8, the presence of a Set-Cookie response header does not inhibit caching. This means that a cached entry might contain a Set-Cookie if it was cached with one. The RFC goes on to recommend that you should configure appropriate Cache-Control headers to control how responses are cached.
One of the risks of caching responses with Set-Cookie is that the cookie values can be stored and served to subsequent requests. Depending on the cookie’s purpose, this could have worrying results. For example, if a login cookie or a session cookie is present in a shared cache, then that cookie might be reused by another client. One way to avoid this is to use the Cache-Control private directive, which only permits the response to be cached by the client browser.
3% of cacheable responses contain a Set-Cookie header. Of those responses, only 18% use the private directive. The remaining 82% include 5.3 million HTTP responses that include a Set-Cookie which can be cached by public and private cache servers.
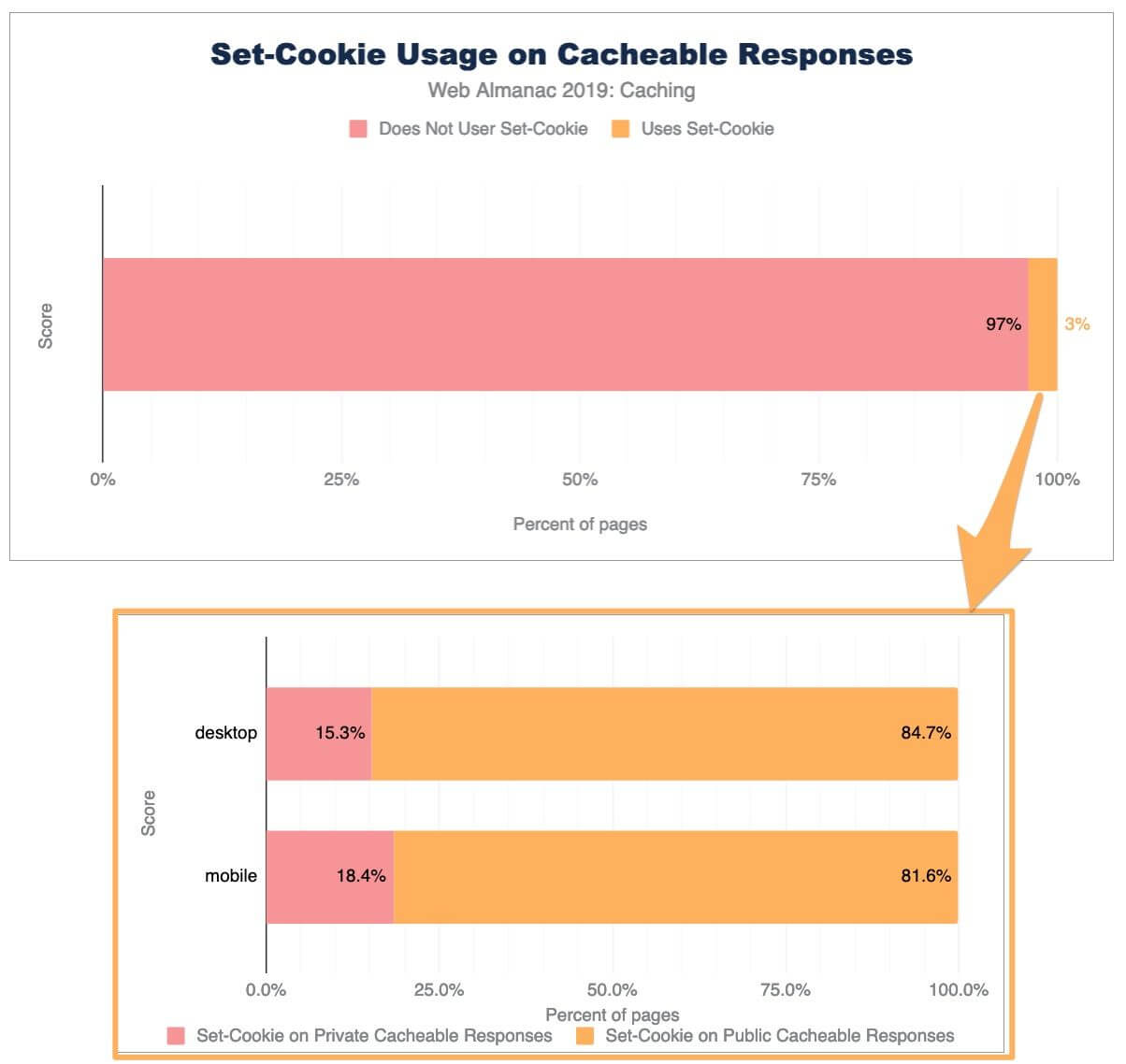
Set-Cookie responses.
AppCache and service workers
The Application Cache or AppCache is a feature of HTML5 that allows developers to specify resources the browser should cache and make available to offline users. This feature was deprecated and removed from web standards, and browser support has been diminishing. In fact, when its use is detected, Firefox v44+ recommends that developers should use service workers instead. Chrome 70 restricts the Application Cache to secure context only. The industry has moved more towards implementing this type of functionality with service workers - and browser support has been rapidly growing for it.
In fact, one of the HTTP Archive trend reports shows the adoption of service workers shown below:
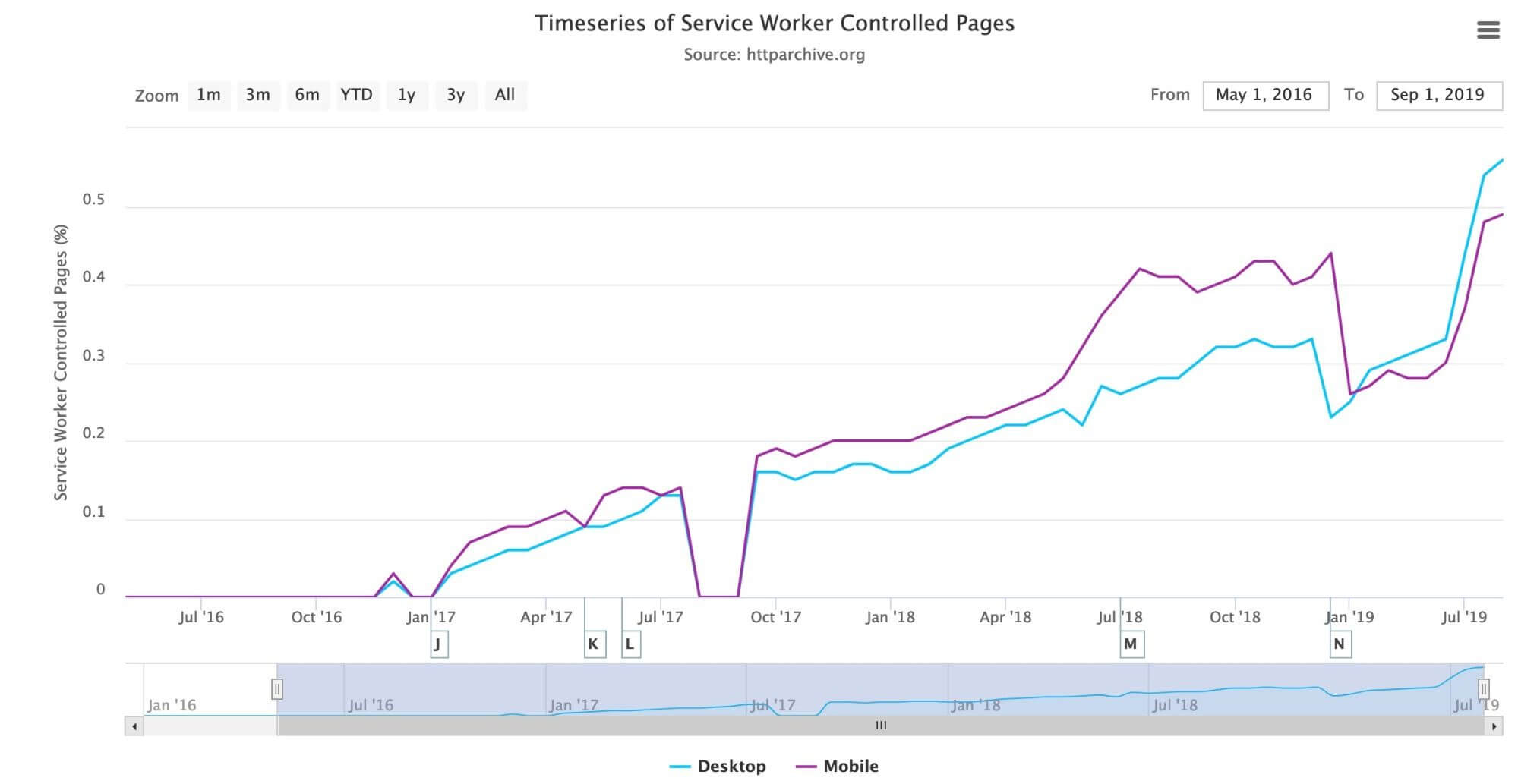
Adoption is still below 1% of websites, but it has been steadily increasing since January 2017. The Progressive Web App chapter discusses this more, including the fact that it is used a lot more than this graph suggests due to its usage on popular sites, which are only counted once in above graph.
In the table below, you can see a summary of AppCache vs service worker usage. 32,292 websites have implemented a service worker, while 1,867 sites are still utilizing the deprecated AppCache feature.
| Does Not Use Server Worker | Uses Service Worker | Total | |
|---|---|---|---|
| Does Not Use AppCache | 5,045,337 | 32,241 | 5,077,578 |
| Uses AppCache | 1,816 | 51 | 1,867 |
| Total | 5,047,153 | 32,292 | 5,079,445 |
If we break this out by HTTP vs HTTPS, then this gets even more interesting. 581 of the AppCache enabled sites are served over HTTP, which means that Chrome is likely disabling the feature. HTTPS is a requirement for using service workers, but 907 of the sites using them are served over HTTP.
| Does Not Use Service Worker | Uses Service Worker | ||
|---|---|---|---|
| HTTP | Does Not Use AppCache | 1,968,736 | 907 |
| Uses AppCache | 580 | 1 | |
| HTTPS | Does Not Use AppCache | 3,076,601 | 31,334 |
| Uses AppCache | 1,236 | 50 |
Identifying caching opportunities
Google’s Lighthouse tool enables users to run a series of audits against web pages, and the cache policy audit evaluates whether a site can benefit from additional caching. It does this by comparing the content age (via the Last-Modified header) to the cache TTL and estimating the probability that the resource would be served from cache. Depending on the score, you may see a caching recommendation in the results, with a list of specific resources that could be cached.
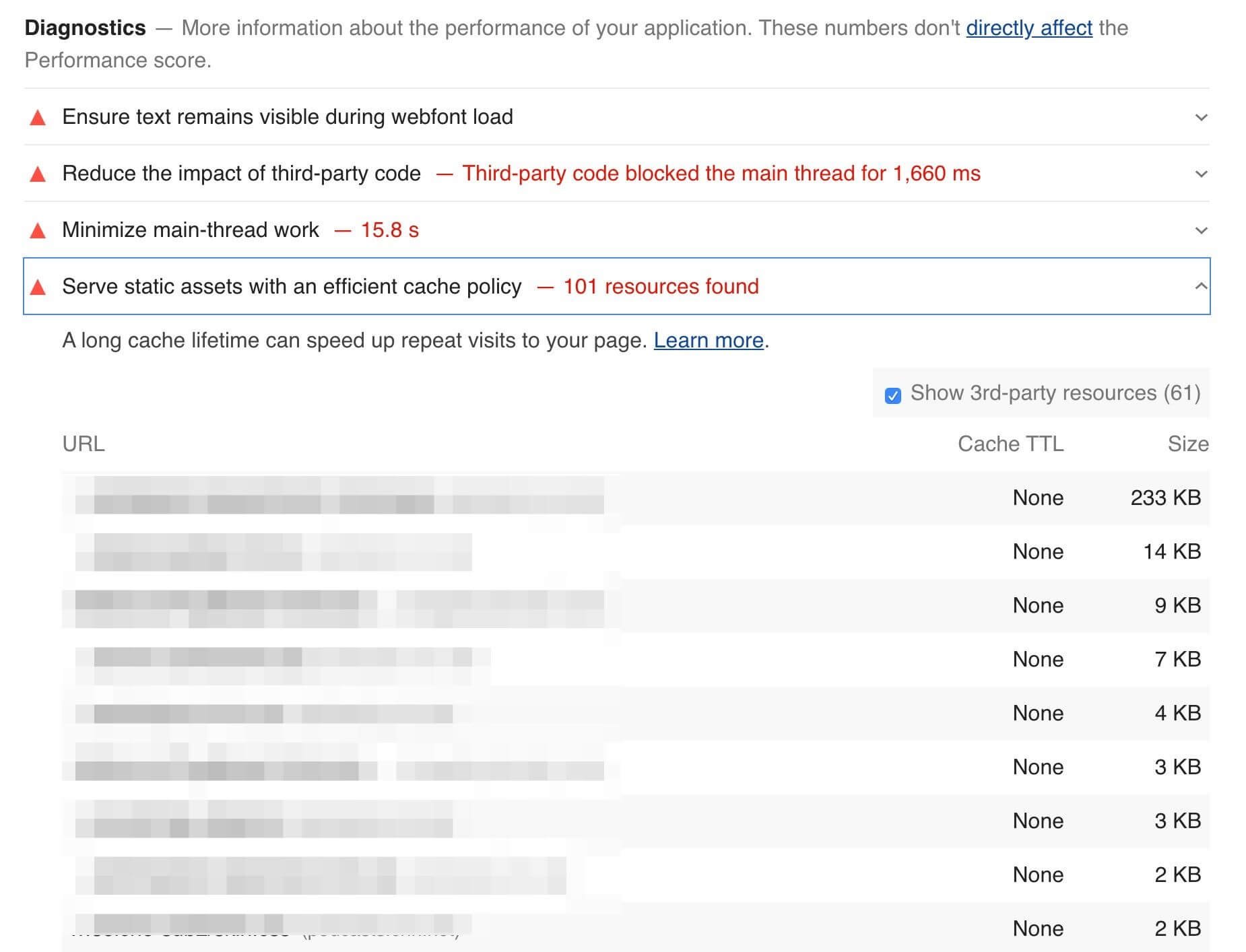
Lighthouse computes a score for each audit, ranging from 0% to 100%, and those scores are then factored into the overall scores. The caching score is based on potential byte savings. When we examine the Lighthouse results, we can get a perspective of how many sites are doing well with their cache policies.
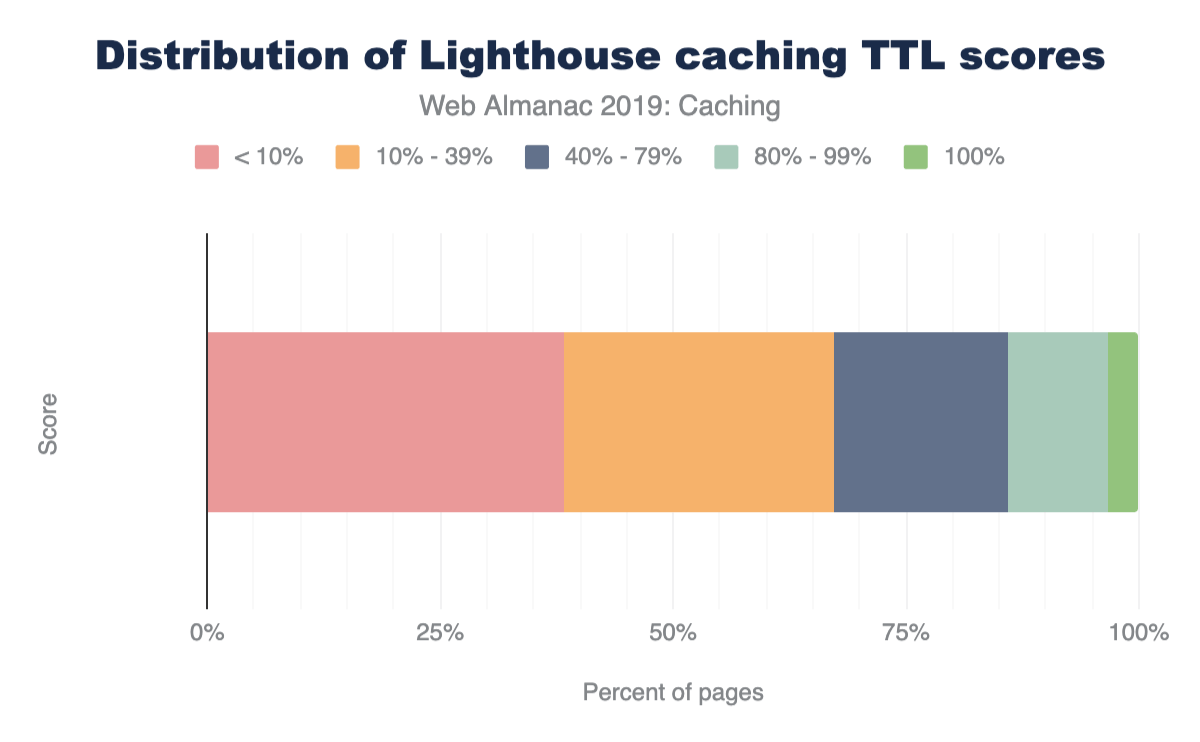
Only 3.4% of sites scored a 100%, meaning that most sites can benefit from some cache optimizations. A vast majority of sites sore below 40%, with 38% scoring less than 10%. Based on this, there is a significant amount of caching opportunities on the web.
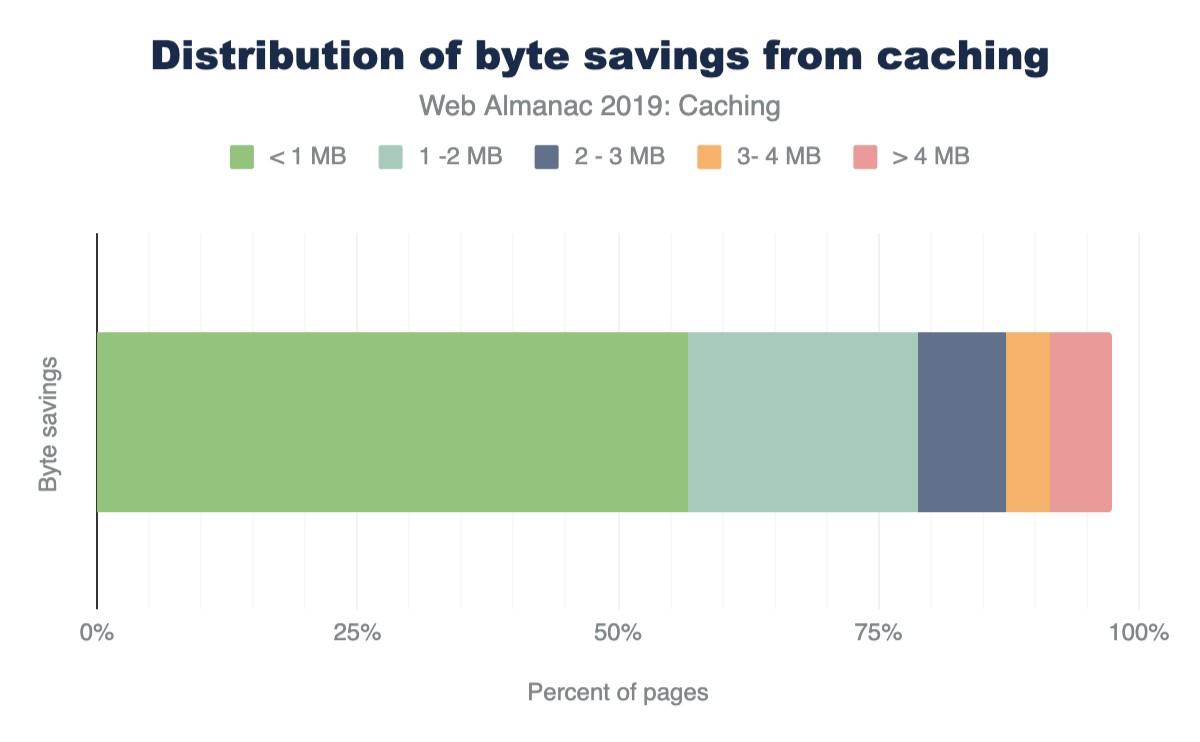
Lighthouse also indicates how many bytes could be saved on repeat views by enabling a longer cache policy. Of the sites that could benefit from additional caching, 82% of them can reduce their page weight by up to a whole Mb!
Conclusion
Caching is an incredibly powerful feature that allows browsers, proxies and other intermediaries (such as CDNs) to store web content and serve it to end users. The performance benefits of this are significant, since it reduces round trip times and minimizes costly network requests.
Caching is also a very complex topic. There are numerous HTTP response headers that can convey freshness as well as validate cached entries, and Cache-Control directives provide a tremendous amount of flexibility and control. However, developers should be cautious about the additional opportunities for mistakes that it comes with. Regularly auditing your site to ensure that cacheable resources are cached appropriately is recommended, and tools like Lighthouse and REDbot do an excellent job of helping to simplify the analysis.
