Caching
Introduction
Caching is a technique that enables the reuse of previously downloaded content. It involves something (a server which builds web pages, a proxy such as a CDN or the browser itself) storing ’content’ (web pages, CSS, JS, images, fonts, etc.) and tagging it appropriately, so it can be reused.
Here’s a very high-level example:
Jane visits the home page of the www.example.com website. Jane lives in Los Angeles, CA, and the example.com server is located in Boston, MA. Jane visiting www.example.com involves a network request which has to travel across the country.
On the example.com server (a.k.a. Origin server), the home page is retrieved. The server knows Jane is located in LA and adds dynamic content to the page—a list of upcoming events near her. Then the page is sent back across the country to Jane and displayed on her browser.
If there is no caching, if Carlos in LA also visits www.example.com after Jane, his request must travel across the country to the example.com server. The server has to build the same page, including the LA events list. It will have to send the page back to Carlos.
Worse, if Jane revisits the example.com home page, her subsequent requests will act like the first—the request must go across the country and the example.com server must rebuild the home page to send it back to her.
So without any caching, the example.com server builds each request from scratch. That’s bad for the server because it is more work. Additionally, any communication between either Jane or Carlos and the example.com server requires data to travel across the country. All of this can add up to a slow experience that’s bad for both of them.
However, with server caching, when Jane makes her first request the server builds the LA variant of the home page. It caches the data for reuse by all LA visitors. So when Carlos’s request gets to the example.com server, the server checks if it has the LA variant of the home page in its cache. Since that page is in cache as a result of Jane’s earlier request, the server saves time by returning the cached page.
More importantly, with browser caching, when Jane’s browser receives the page from the server for the first request, it caches the page. All of her future requests for the example.com home page will be served from her browser’s cache, without a network request. The example.com server also benefits by not having to process or deal with Jane’s request.
Jane is happy. Carlos is happy. The example.com folks are happy. Everyone is happy.
It should be clear then, that browser caching provides a significant performance benefit by avoiding costly network requests (though there are always edge cases). It also helps an application scale by reducing the traffic to a website’s origin infrastructure. Server caching also significantly reduces the load on the underlying application.
Caching benefits both the end users (they get their web pages quickly) and the companies serving the web pages (reducing the load on their servers). Caching really is a win-win!
Web architectures typically involve multiple tiers of caching. There are four main places or caching entities where caching can occur:
- An end user’s web browser.
- A service worker cache running in the end user’s web browser.
- A Content Delivery Network (CDN) or similar proxy, which sits between the end user’s web browser and the origin server.
- The origin server itself.
In this chapter, we will primarily be discussing caching within web browsers (1-2), as opposed to caching at the origin server or in a CDN. Nevertheless, many of the specific caching topics discussed in this chapter rely on the relationship between the browser and the server (or CDN, if one is used).
The key to understanding how caching, and the web in general, works is to remember that it all consists of transactions between a requesting entity (e.g. a browser) and a responding entity (e.g. a server). Each transaction consists of two parts:
- The request from the requesting entity: “I want object X”.
- The response from the responding entity: “Here is object X”.
When we talk about caching, it refers to the object (HTML page, image, etc.) cached by the requesting entity.
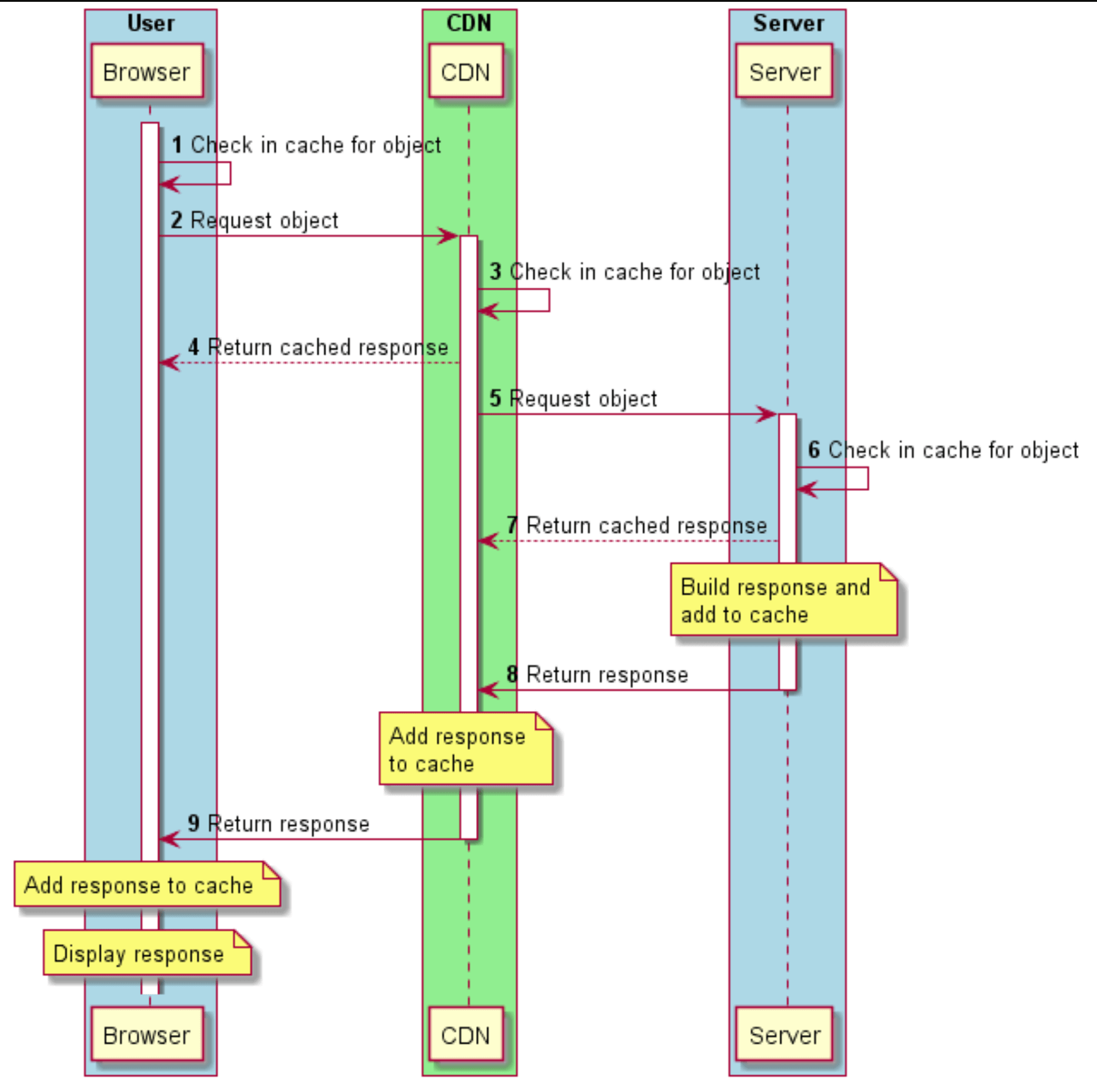
Below figure shows how a typical request/response flow works for an object (e.g. a web page). A CDN sits between the browser and the server. Note that at each point in the browser → CDN → server flow, each of the caching entities first checks whether it has the object in its cache. It returns the cached object to the requester if found, before forwarding the request to the next caching entity in the chain:
Caching guiding principles
There are three guiding principles to caching web content:
- Cache as much as you can
- Cache for as long as you can
- Cache as close as you can to end users
Cache as much as you can
When considering what to cache, it is important to understand whether the response content is static or dynamic.
Static content
An example of static content is an image. For instance, a picture of a cat in a cat.jpg file is usually the same regardless of who’s requesting it or where the requester is located (of course alternative formats or sizes may be delivered but usually from a different filename).

Static content is typically cacheable and often for long periods of time. It has a one-to-many relationship between the content (one) and the requests (many).
Dynamic content
An example of dynamic content is a list of events which are specific to a geographic location. The list will be different based on the requester’s location.
Dynamically generated content can be more nuanced and requires careful consideration. Some dynamic content can be cached, but often for a shorter period of time. The example of a list of upcoming events will change, possibly from day to day. Different variants of the list may also need to be cached and what’s cached in a user’s browser may be a subset of what’s cached on the server or CDN. Nevertheless, it is possible to cache some dynamic contents. It is incorrect to assume that “dynamic” is another word for “uncacheable”.
Cache for as long as you can
The length of time you would cache a resource is highly dependent on the content’s volatility, that is the likelihood and/or frequency of change. For example, an image or a versioned JavaScript file could potentially be cached for a very long time. An API response or a non-versioned JavaScript file may need a shorter cache duration to ensure users get the most up-to-date response. Some content might only be cached for a minute or less. And, of course, some content should not be cached at all. This is discussed in more detail in Identifying caching opportunities below.
Another point to bear in mind is that no matter how long you tell a browser to cache content for, the browser may evict that content from cache before that point in time. It may do so to make room for other content that is accessed more frequently for example. However, a browser will not use cache content for longer than it is told.
Cache as close to end users as you can
Caching content close to the end user reduces download times by removing latency. For example, if a resource is cached in a user’s browser, then the request never goes out to the network and it is available locally every time the user needs it. For visitors that don’t have entries in their browser’s cache, a CDN would be the next place a cached resource is returned from. In most cases, it will be faster to fetch a resource from a local cache or a CDN compared to an origin server.
Some terminology
Caching entity: The hardware or software that is doing the caching. Due to the focus of this chapter, we use “browser” as a synonym for “caching entity” unless otherwise specified.
Time-To-Live (TTL): The TTL of a cached object defines how long it can be stored in a cache, typically measured in seconds. After a cached object reaches its TTL, it is marked as ’stale’ by the cache. Depending on how it was added to the cache (see the details of the caching headers below), it may be evicted from cache immediately, or it may remain in the cache but marked as a ’stale’ object, requiring revalidation before reuse.
Eviction: The automated process by which an object is actually removed from a cache when/after it reaches its TTL or possibly when the cache is full.
Revalidation: A cached object that is marked as stale may need to be ’revalidated’ with the server before it can be displayed to the user. The browser must first check with the server that the object the browser has in its cache is still up-to-date and valid.
Overview of browser caching
When a browser makes a request for a piece of content (e.g. a web page), it will receive a response which includes not just the content itself (the HTML markup), but also a number of HTTP response headers which describe the content, including information about its cacheability.
The caching-related headers, or the absence of them, tell the browser three important pieces of information:
- Cacheability: Is this content cacheable?
- Freshness: If it is cacheable, how long can it be cached for?
- Validation: If it is cacheable, how do I subsequently ensure that my cached version is still fresh?
The two HTTP response headers typically used for specifying freshness are Cache-Control and Expires:
Expiresspecifies an explicit expiration date and time (i.e. when exactly the content expires)Cache-Controlspecifies a cache duration (i.e. how long the content can be cached in the browser relative to when it was requested)
Often, both these headers are specified; in that case Cache-Control takes precedence.
The full specifications for these caching headers are in RFC 7234, and discussed in sections 4.2 (Freshness) and 4.3 (Validation), but we will discuss them in more detail below.
Cache-Control vs Expires
In the early HTTP/1.0 days of the web, the Expires header was the only cache-related response header. As stated above, it is used to indicate the exact date/time after which the response is considered stale. Its value is a date and time, such as:
Expires: Thu, 01 Dec 1994 16:00:00 GMTThe Expires header can be thought of as a blunt instrument. If a relative cache TTL is required, then processing must be done on the server to generate an appropriate value based upon the current date/time.
HTTP/1.1 introduced the Cache-Control header, which is supported by all commonly used browsers for a long time. The Cache-Control header provides much more extensibility and flexibility than Expires via caching directives, several of which can be specified together. Details on the various directives are below.
> GET /static/js/main.js HTTP/2
> Host: www.example.org
> Accept: */*
< HTTP/2 200
< Date: Thu, 23 Jul 2020 03:04:17 GMT
< Expires: Thu, 23 Jul 2020 03:14:17 GMT
< Cache-Control: public, max-age=600The simple example above shows a request and response for a JavaScript file though some headers have been removed for clarity. The Date header indicates the current date (specifically, the date that the content was served). The Expires header indicates that it can be cached for 10 minutes (the difference between the Expires and Date headers). The Cache-Control header specifies the max-age directive, which indicates that the resource can be cached for 600 seconds (5 minutes). Since Cache-Control takes precedence over Expires, the browser will cache the response for 5 minutes, after which it will be marked as stale.
RFC 7234 says that if no caching headers are present in a response, then the browser is allowed to heuristically cache the response—it suggests a cache duration of 10% of the time since the Last-Modified header (if passed). In such cases, most browsers implement a variation of this suggestion, but some may cache the response indefinitely and some may not cache it at all. Because of this variation between browsers, it is important to explicitly set specific caching rules to ensure that you are in control of the cacheability of your content.
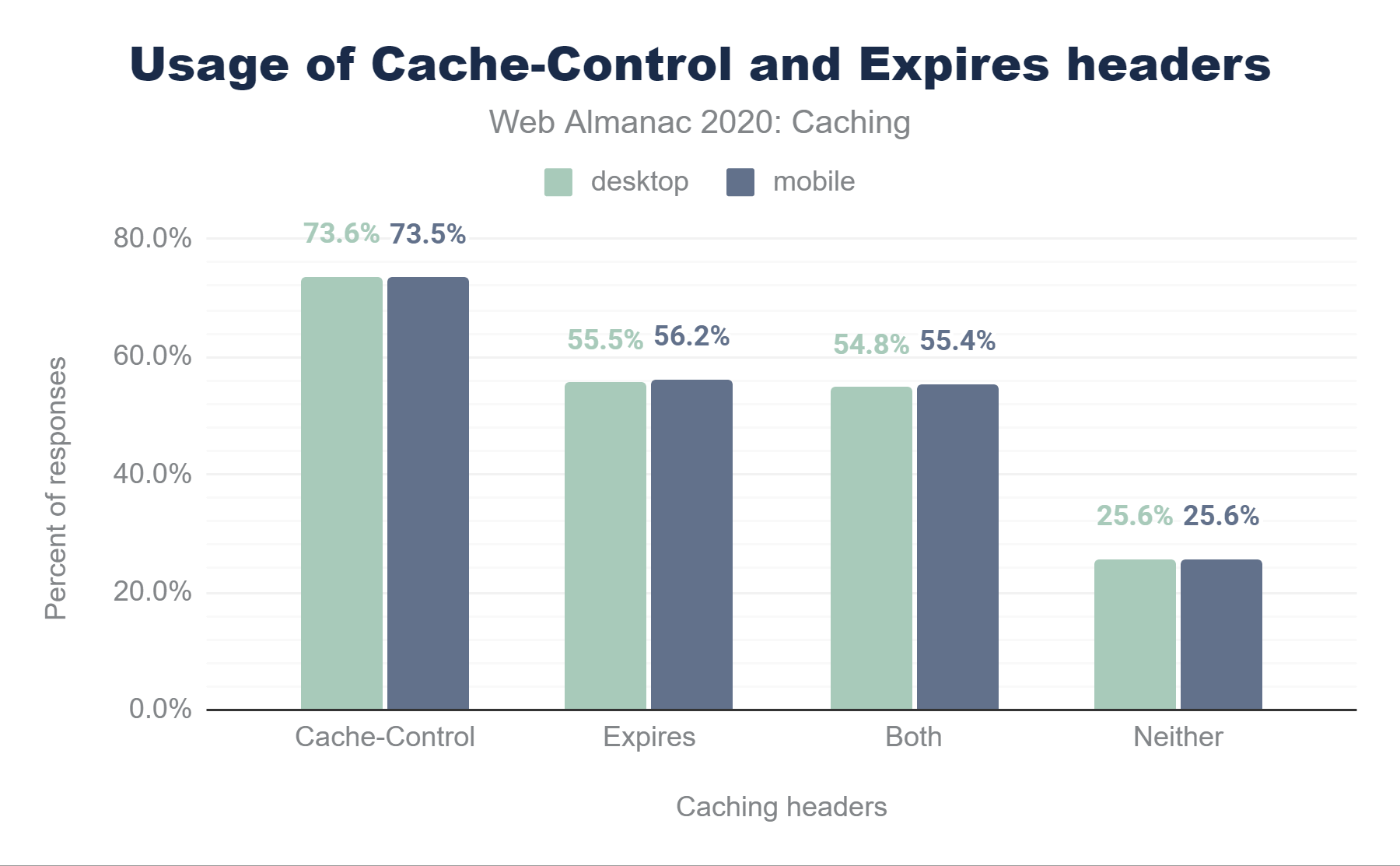
Cache-Control and Expires headers. In desktop, 73.6% of responses are served with a Cache-Control header. 55.5% are served with an Expires header, 54.8% use both Cache-Control and Expires header, and 25.6% did not include either header. In mobile, 73.5% of responses are served with a Cache-Control header, 56.2% are served with an Expires header, 55.4% use both Cache-Control and Expires header, and 25.6% did not include either header.Cache-Control and Expires headers.
As we can see 73.5% of mobile responses are served with a Cache-Control header, and 56.2% of responses are served with an Expires header and nearly all of those (55.4%) will not be used as the responses include both headers. 25.6% of responses did not include either header and are therefore subject to heuristic caching.
These statistics are interesting when compared with last years data:
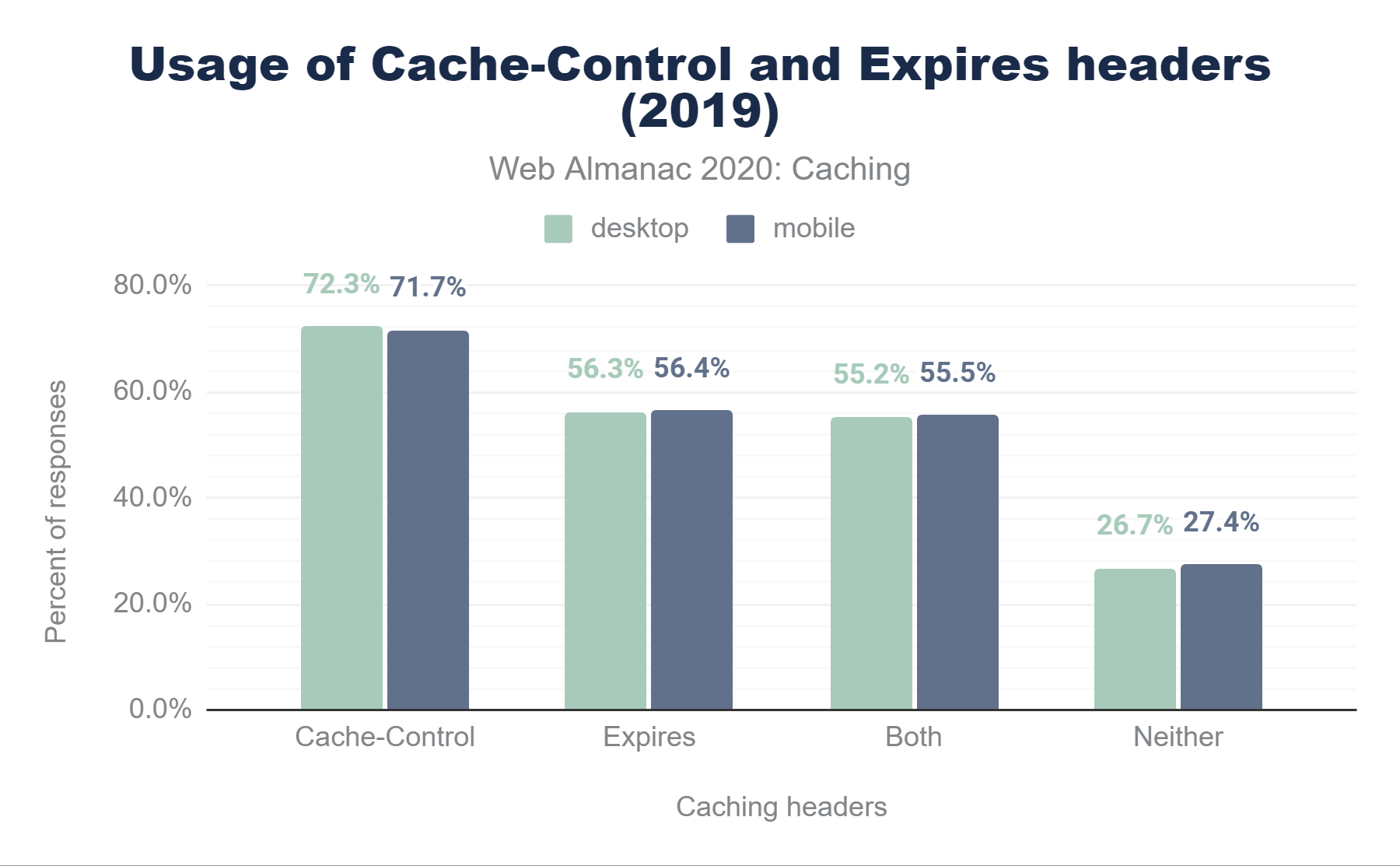
Cache-Control and Expires headers. In desktop, 72.3% of responses are served with a Cache-Control header. 56.3% are served with an Expires header, 55.2% use both Cache-Control and Expires header, and 26.7% did not include either header. In mobile, 71.7% of responses are served with a Cache-Control header, 56.4% are served with an Expires header, 55.5% use both Cache-Control and Expires header, and 27.4% did not include either header.Cache-Control and Expires headers in 2019.
While we see a slight increase in the use of the Cache-Control header (1.8%), we also see a minimal decrease in the use of the older Expires header (0.2%). On Desktop we actually see a marginal increase of Cache-Control (1.3%), with a smaller increase on Expires (0.8%) Effectively, more desktop sites look to be adding Cache-Control header without the Expires header.
As we delve into the various directives allowed in the Cache-Control header, we will see how its flexibility and power make it a better fit in many cases.
Cache-Control directives
When you use the Cache-Control header, you specify one or more directives—predefined values that indicate specific caching functionality. Multiple directives are separated by commas and can be specified in any order, although some of them ’clash’ with one another (e.g. public and private). Some directives take a value, such as max-age.
Below is a table showing the most common Cache-Control directives:
| Directive | Description |
|---|---|
max-age |
Indicates the number of seconds that a resource can be cached for, relative to the current time. For example max-age=86400. |
public |
Any cache may store the response, including the browser, and any proxies between the server and the browser, such as a CDN. This is assumed by default. |
no-cache |
A cached entry must be revalidated prior to its use, via a conditional request, even if it is not marked as stale. |
must-revalidate |
A stale cached entry must be revalidated prior to its use, via a conditional request. |
no-store |
Indicates that the response must not be cached. |
private |
The response is intended for a specific user and should not be stored by shared caches such as proxies and CDNs. |
proxy-revalidate |
Same as must-revalidate but applies to shared caches. |
s-maxage |
Same as max-age but applies to shared caches (e.g. CDN’s) only. |
immutable |
Indicates that the cached entry will never change during its TTL, and that revalidation is not necessary. |
stale-while-revalidate |
Indicates that the client is willing to accept a stale response while asynchronously checking in the background for a fresh one. |
stale-if-error |
Indicates that the client is willing to accept a stale response if the check for a fresh one fails. |
Cache-Control directives.
The max-age directive is the most commonly-found, since it directly defines the TTL, in the same way that the Expires header does.
Here is an example of a valid Cache-Control header with multiple directives:
Cache-Control: public, max-age=86400, must-revalidateThis indicates that the object can be cached for 86,400 seconds (1 day) and it can be stored by all caches between the server and the browser, as well as in the browser itself. Once it has reached its TTL and is marked as stale, it can remain in cache, but must be conditionally revalidated before reuse.
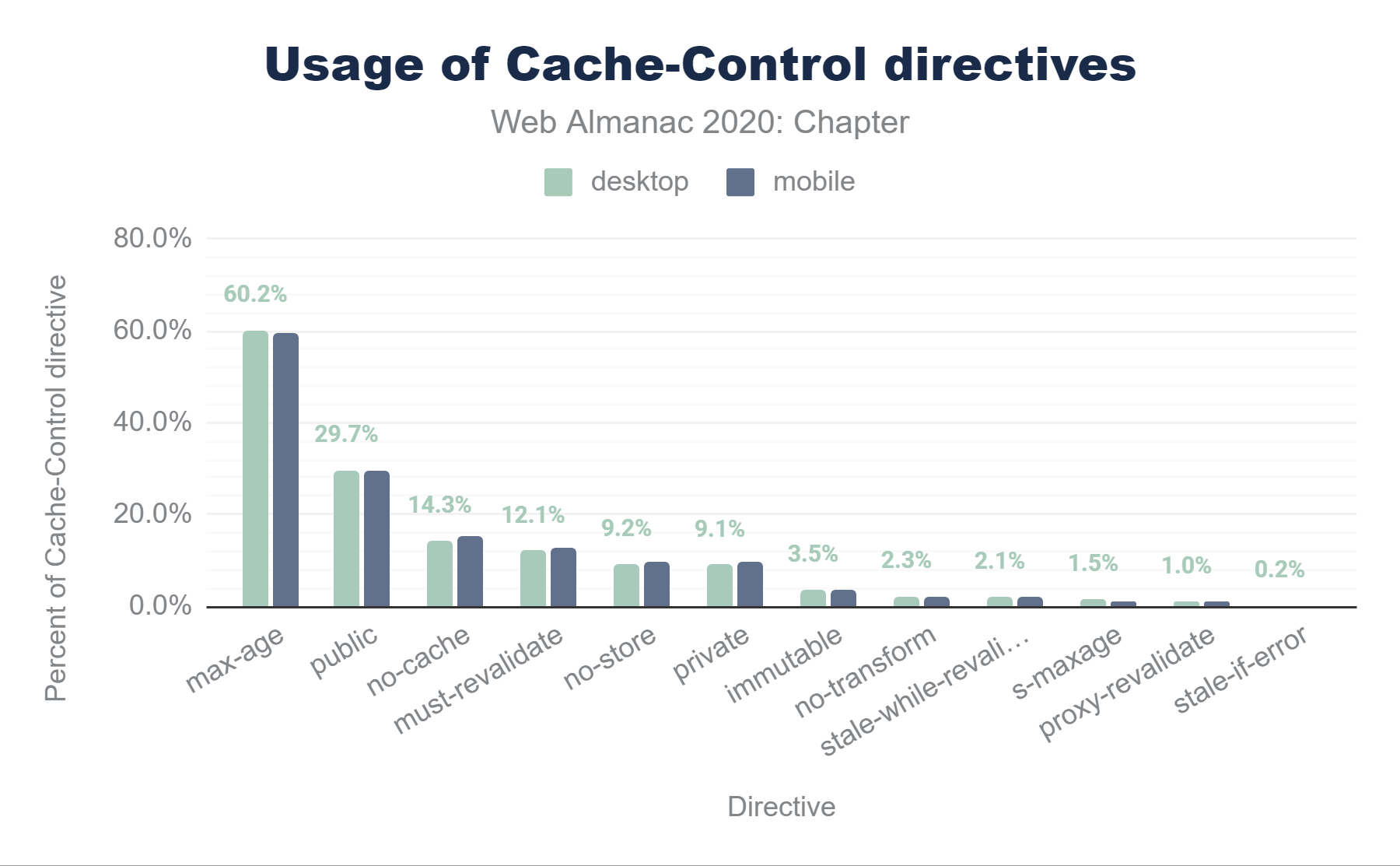
Cache-Control directives. The usage for desktop ranges from 60.2% for max-age, 29.7% for public, 14.3% for no-cache, 12.1% for must-revalidate, 9.2% for no-store, 9.1% for private, 3.5% for immutable, 2.3% for no-transform, 2.1% for stale-while-revalidate, 1.5% for s-maxage, 1.0% for proxy-revalidate, and 0.2% for stale-if-error. For mobile, the range is, 59.7% for max-age, 29.7% for public, 15.1% for no-cache, 12.5% for must-revalidate, 9.6% for no-store, 9.7% for private, 3.5% for immutable, 2.2% for no-transform, 2.2% for stale-while-revalidate, 1.2% for s-maxage, 1.1% for proxy-revalidate, and 0.2% for stale-if-error.Cache-Control directives.
The above figure illustrates the 11 Cache-Control directives in use on mobile and desktop websites. There are a few interesting observations about the popularity of these cache directives:
max-ageis used by about 59.66% of mobileCache-Controlheaders, andno-storeis used by about 9.64% (see below for some discussion on the meaning and use of theno-storedirective).- Explicitly specifying
publicisn’t ever really necessary since cached entries are assumedpublicunlessprivateis specified. Nevertheless, almost one third of responses includepublic—a waste of a few header bytes on every response :) - The
immutabledirective is relatively new, introduced in 2017 and is only supported on Firefox and Safari—its usage is still only at about 3.47%, but it is widely seen in responses from Facebook, Google, Wix, Shopify and others. It has the potential to greatly improve cacheability for certain types of requests.
As we head out to the long tail, there are a small percentage of invalid directives that can be found; these are ignored by browsers, and just end up wasting header bytes. Broadly they fall into two categories:
- Misspelled directives such as
nocacheands-max-ageand invalid directive syntax, such as using:instead of=or using_instead of-. - Non-existent directives such as
max-stale,proxy-public,surrogate-control.
The most interesting standout in the list of invalid directives is the use of no-cache="set-cookie"—even at only 0.2% of all Cache-Control header values, it still makes up more than all the other invalid directives combined. In some early discussions on the Cache-Control header, this syntax was raised as a possible way to ensure that any Set-Cookie response headers (which might be user-specific) would not be cached with the object itself by any intermediate proxies such as CDNs. However, this syntax was not included in the final RFC. Nearly equivalent functionality can be implemented using the private directive, and the no-cache directive does not allow a value.
Cache-Control: no-store, no-cache and max-age=0
When a response absolutely must not be cached, the Cache-Control: no-store directive should be used; if this directive is not specified, then the response is considered cacheable and may be cached. Note that if no-store is specified, it takes precedence over other directives. This makes sense, since serious privacy and security issues could occur if a resource is cached which should not be.
We can see a few common errors that are made when attempting to configure a response to be non-cacheable:
- Specifying
Cache-Control: no-cachemay sound like a directive to not cache the resource. However, as noted above, theno-cachedirective does allow the resource to be cached—it simply informs the browser to revalidate the resource prior to use and is not the same as stopping the resource from being cached at all. - Setting
Cache-Control: max-age=0sets the TTL to 0 seconds, but again, that is not the same as being non-cacheable. Whenmax-age=0is specified, the resource is cached, but is marked as stale, resulting in the browser having to immediately revalidate its freshness.
Functionally, no-cache and max-age=0 are similar, since they both require revalidation of a cached resource. The no-cache directive can also be used alongside a max-age directive that is greater than 0—this results in the object being cached for the specified TTL but being revalidated prior to every use.
When looking at the above three discussed directives, 2.7% of responses include the combination of all three no-store, no-cache and max-age=0 directives, 6.7% of responses include both no-store and no-cache, and a negligible number of responses (< 0.15%) include no-store alone.
As noted above, where no-store is specified with either/both of no-cache and max-age=0, the no-store directive takes precedence, and the other directives are ignored. Therefore, if you don’t want content to be cached anywhere, simply specifying Cache-Control: no-store is sufficient and is both simpler and uses the minimum number of header bytes.
The max-age=0 directive is present on less than 2% of responses where no-store is not specified. In such cases, the resource will be cached in the browser but will require revalidation as it is immediately marked as stale.
Conditional requests and revalidation
There are often cases where a browser has previously requested an object and already has it in its cache but the cache entry has already exceeded its TTL (and is therefore marked as stale) or where the object is defined as one that must be revalidated prior to use.
In these cases, the browser can make a conditional request to the server—effectively saying “I have object X in my cache—can I use it, or do you have a more recent version I should use instead?”. The server can respond in one of two ways:
- “Yes, the version of object X you have in cache is fine to use”: In this case the server response consists of a
304 Not Modifiedstatus code and response headers, but no response body - “No, here is a more recent version of object X—use this instead”: In this case the server response consists of a
200 OKstatus code, response headers, and a new response body (the actual new version of object X)
In either case, the server can optionally include updated caching response headers, possibly extending the TTL of the object so the browser can use the object for a further period of time without needing to make more conditional requests.
The above is known as revalidation and if implemented correctly can significantly improve perceived performance since a 304 Not Modified response consists only of headers, it is much smaller than a 200 OK response, resulting in reduced bandwidth and a quicker response.
So how does the server identify a conditional request from a regular request?
It actually all comes down to the initial request for the object. When a browser requests an object which it does not already have in its cache, it simply makes a GET request, like this (again, some headers removed for clarity):
> GET /index.html HTTP/2
> Host: www.example.org
> Accept: */*If the server wants to allow the browser to make use of conditional requests (this decision is entirely up to the server!), it can include one or both of two response headers which identify the object as being eligible for subsequent conditional requests. The two response headers are:
Last-Modified: This indicates when the object was last changed. Its value is a date timestamp.ETag(Entity Tag): This provides a unique identifier for the content as a quoted string. It can take any format that the server chooses; it is typically a hash of the file contents, but it could be a timestamp or a simple string.
If both headers are present, ETag takes precedence.
Last-Modified
When the server receives the request for the file, it can include the date/time that the file was most recently changed as a response header, like this:
< HTTP/2 200
< Date: Thu, 23 Jul 2020 03:04:17 GMT
< Last-Modified: Mon, 20 Jul 2020 11:43:22 GMT
< Cache-Control: max-age=600
...lots of html here...The browser will cache this object for 600 seconds (as defined in the Cache-Control header), after which it will mark the object as stale. If the browser needs to use the file again, it requests the file from the server just as it did initially, but this time it includes an additional request header, called If-Modified-Since, which it sets to the value that was passed in the Last-Modified response header in the initial response:
> GET /index.html HTTP/2
> Host: www.example.org
> Accept: */*
> If-Modified-Since: Mon, 20 Jul 2020 11:43:22 GMTWhen the server receives this request, it can check whether the object has changed by comparing the If-Modified-Since header value with the date that it most recently changed the file.
If the two values are the same, then the server knows that the browser has the latest version of the file and the server can return a 304 Not Modified response with just headers (including the same Last-Modified header value) and no response body:
< HTTP/2 304
< Date: Thu, 23 Jul 2020 03:14:17 GMT
< Last-Modified: Mon, 20 Jul 2020 11:43:22 GMT
< Cache-Control: max-age=600However, if the file on the server has changed since it was last requested by the browser, then the server returns a 200 OK response consisting of headers (including an updated Last-Modified header) and the new version of the file in the body:
< HTTP/2 200
< Date: Thu, 23 Jul 2020 03:14:17 GMT
< Last-Modified: Thu, 23 Jul 2020 03:12:42 GMT
< Cache-Control: max-age=600
...lots of html here...As you can see, the Last-Modified response header and If-Modified-Since request header work as a pair.
Entity Tag (ETag)
The functionality here is almost exactly the same as the date-based Last-Modified / If-Modified-Since conditional request processing described above.
However, in this case, the Server sends an ETag response header—rather than a date timestamp. An ETag is simply a string and is often a hash of the file contents or a version number calculated by the server. The format of this string is entirely up to the server. The only important fact is that the server changes the ETag value whenever it changes the file.
In this example, when the server receives the initial request for the file, it can return the file’s version in an ETag response header, like this:
< HTTP/2 200
< Date: Thu, 23 Jul 2020 03:04:17 GMT
< ETag: "v123.4.01"
< Cache-Control: max-age=600
...lots of html here...As with the If-Modified-Since example above, the browser will cache this object for 600 seconds, as defined in the Cache-Control header. When it needs to request the object from the server again, it includes an additional request header, called If-None-Match, which has the value passed in the ETag response header in the initial response:
> GET /index.html HTTP/2
> Host: www.example.org
> Accept: */*
> If-None-Match: "v123.4.01"When the server receives this request, it can check whether the object has changed by comparing the If-None-Match header value with the current version it has of the file.
If the two values are the same, then the browser has the latest version of the file and the server can return a 304 Not Modified response with just headers:
< HTTP/2 304
< Date: Thu, 23 Jul 2020 03:14:17 GMT
< ETag: "v123.4.01"
< Cache-Control: max-age=600However, if the values are different, then the version of the file on the server is more recent than the version that the browser has, so the server returns a 200 OK response consisting of headers (including an updated ETag header) and the new version of the file:
< HTTP/2 200
< Date: Thu, 23 Jul 2020 03:14:17 GMT
< ETag: "v123.5.06"
< Cache-Control: public, max-age=600
...lots of html here...Again, we see a pair of headers being used for this conditional request processing—the ETag response header and the If-None-Match request header.
In the same way that the Cache-Control header has more power and flexibility than the Expires header, the ETag header is in many ways an improvement over the Last-Modified header. There are two reasons for this:
-
The server can define its own format for the
ETagheader. The example above shows a version string, but it could be a hash, or a random string. By allowing this, versions of an object are not explicitly linked to dates, and this allows a server to create a new version of a file and yet give it the same ETag as the prior version—perhaps if the file change is unimportant. -
ETag’s can be defined as either ’strong’ or ’weak’, which allows browsers to validate them differently. A full understanding and discussion of this functionality is beyond the scope of this chapter but can be found in RFC 7232.
However, since the ETag is often based on last modified time of the server, it may effectively be the same in a lot of implementations, and worse than that various bugs in server implementations (Apache in particular), can mean it is less effective to use ETag’s.
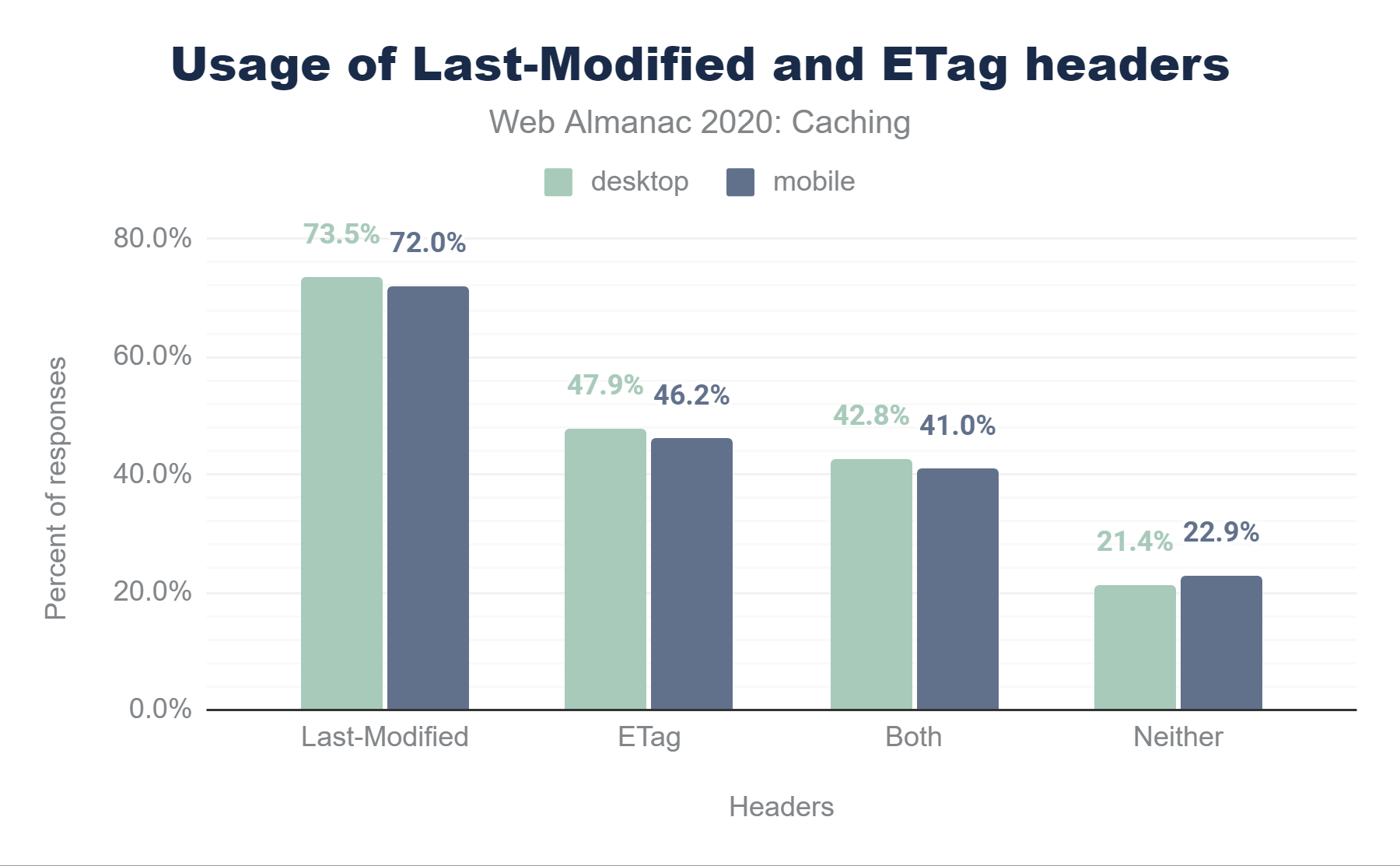
Last-Modified, 47.9% have an ETag, 42.8% have both, and 21.4% have neither. The stats for mobile are almost identical at 72.0% for Last-Modified, 46.2% for ETag, 41.0% for both, and 22.9% for neither.Last-Modified and ETag headers.
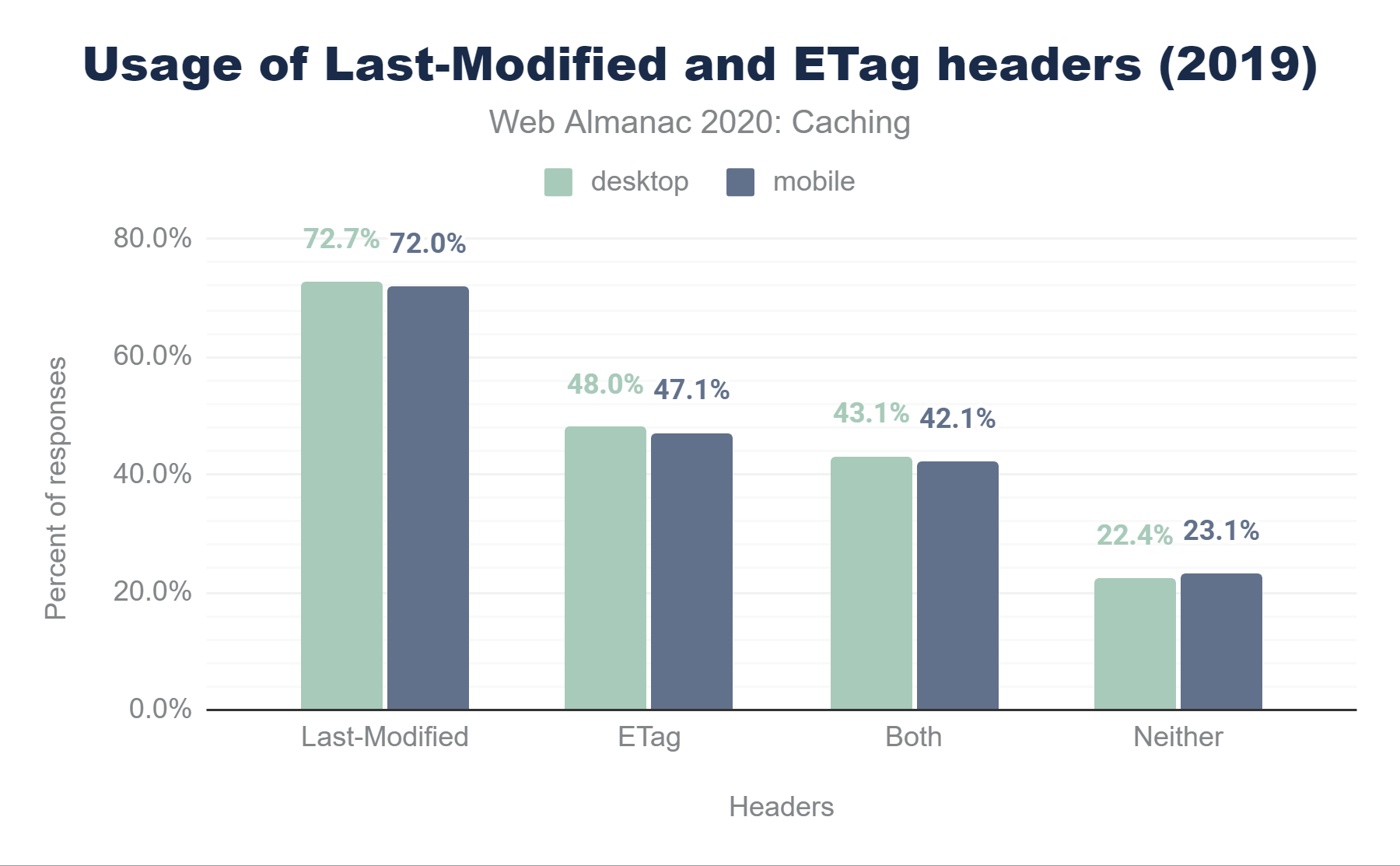
Last-Modified, 48.0% have an ETag, 43.1% have both, and 22.4% have neither. The stats for mobile are almost identical at 72.0% for Last-Modified, 47.1% for ETag, 42.1% for both, and 23.1% for neither.Last-Modified and ETag headers in 2019.
We can see 72.0% of mobile responses are served with a Last-Modified header. In comparison to 2019, its usage on mobile has remained static, but it has increased marginally (by < 1%) on desktop.
Looking at ETag headers, 46.2% of responses on mobiles are using this. Out of these responses, 34.38% are strong, 9.81% are weak, and the remaining 1.98% are invalid. In contrast with Last-Modified, the usage of ETag headers has marginally decreased (by <1%) in comparison to 2019.
41.0% of mobile responses are served with both headers and, as noted above, the ETag header takes precedence in this case. 22.9% of mobile responses include neither a Last-Modified or ETag header.
Correctly-implemented revalidation using conditional requests can significantly reduce bandwidth (304 responses are typically much smaller than 200 responses), load on servers (only a small amount of processing is required to compare change dates or hashes) and improve perceived performance (servers respond more quickly with a 304). However, as we can see from the above statistics, more than a fifth of all requests are not using any form of conditional requests.
Only 0.1% of the responses had a 304 Not Modified status in our crawl, though this is not unexpected as our crawl is using an empty cache and 304 responses are mostly useful for subsequent visits that our Methodology does not test for. Still we analyzed these to see how the 304 was used.
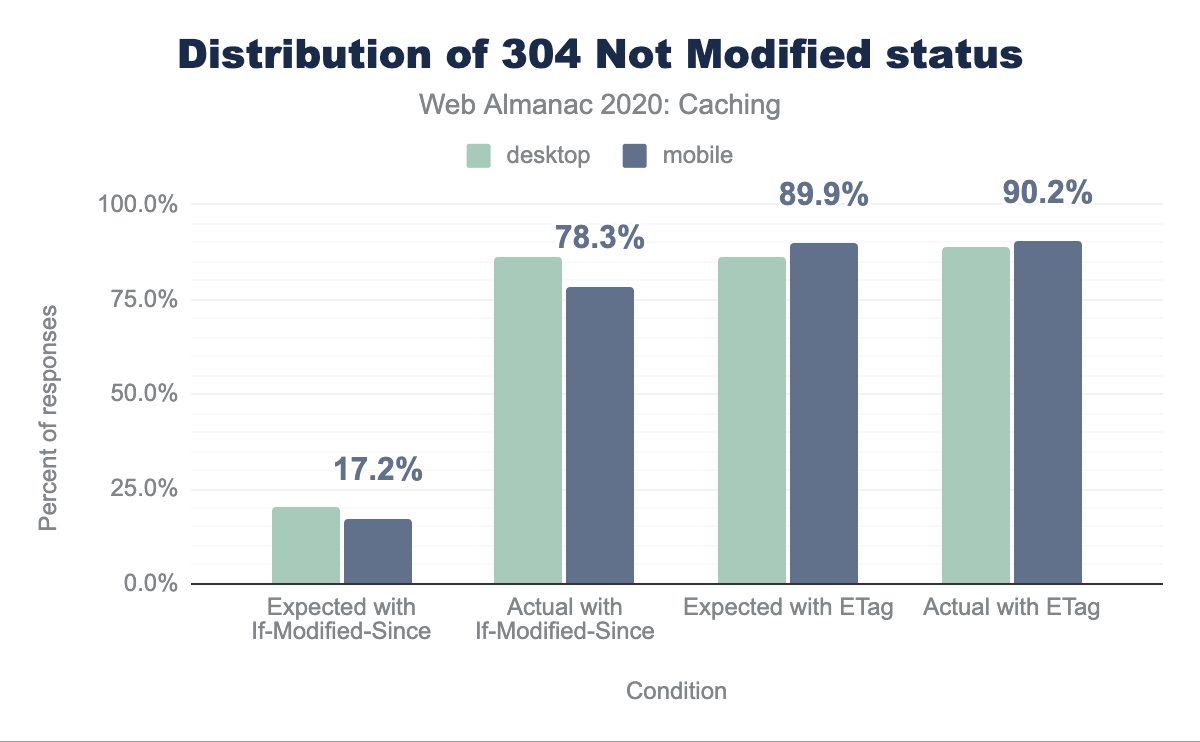
304 Not Modified status. 20.5% of the desktop responses had no ETag header and contained the same Last-Modified value, passed in the If-Modified-Since header of the corresponding request. Out of these, 86% had a 304 Not Modified status. 86.1% of the responses contained the same ETag value, passed in the If-None-Match header of the corresponding request. Out of these, 88.9% had a 304 Not Modified status. 17.2% of the mobile responses had no ETag header and contained the same Last-Modified value, passed in the If-Modified-Since header of the corresponding request. Out of these, 78.3% had a 304 Not Modified status. 89.9% of the responses contained the same ETag value, passed in the If-None-Match header of the corresponding request. Out of these, 90.2% had a 304 Not Modified status.304 Not Modified status.
We see that 17.2% of the mobile responses (20.5% on desktop) had no ETag header and contained the same Last-Modified value, passed in the If-Modified-Since header of the corresponding request. Out of these, 78.3% (86% on desktop) had a 304 Not Modified status.
89.9% of the mobile responses (86.1% on desktop) contained the same ETag value, passed in the If-None-Match header of the corresponding request. If the If-Modified-Since header is also present, ETag takes precedence. Out of these, 90.2% (88.9% on desktop) had a 304 Not Modified status.
Validity of date strings
Throughout this document, we have discussed several caching-related HTTP headers used to convey timestamps:
- The
Dateresponse header indicates when the resource was served to a client. - The
Last-Modifiedresponse header indicates when a resource was last changed on the server. - The
Expiresheader is used to indicate for how long a resource is cacheable.
All three of these HTTP headers use a date formatted string to represent timestamps. The date-formatted string is defined in RFC 2616, and must specify a GMT timestamp string. For example:
> GET /index.html HTTP/2
> Host: www.example.org
> Accept: */*
< HTTP/2 200
< Date: Thu, 23 Jul 2020 03:14:17 GMT
< Cache-Control: max-age=600
< Last-Modified: Mon, 20 Jul 2020 11:43:22 GMTInvalid date strings are ignored by most browsers, which can affect the cacheability of the response on which they are served. For example, an invalid Last-Modified header will result in the browser being unable to subsequently perform a conditional request for the object, since it is cached without that invalid timestamp.
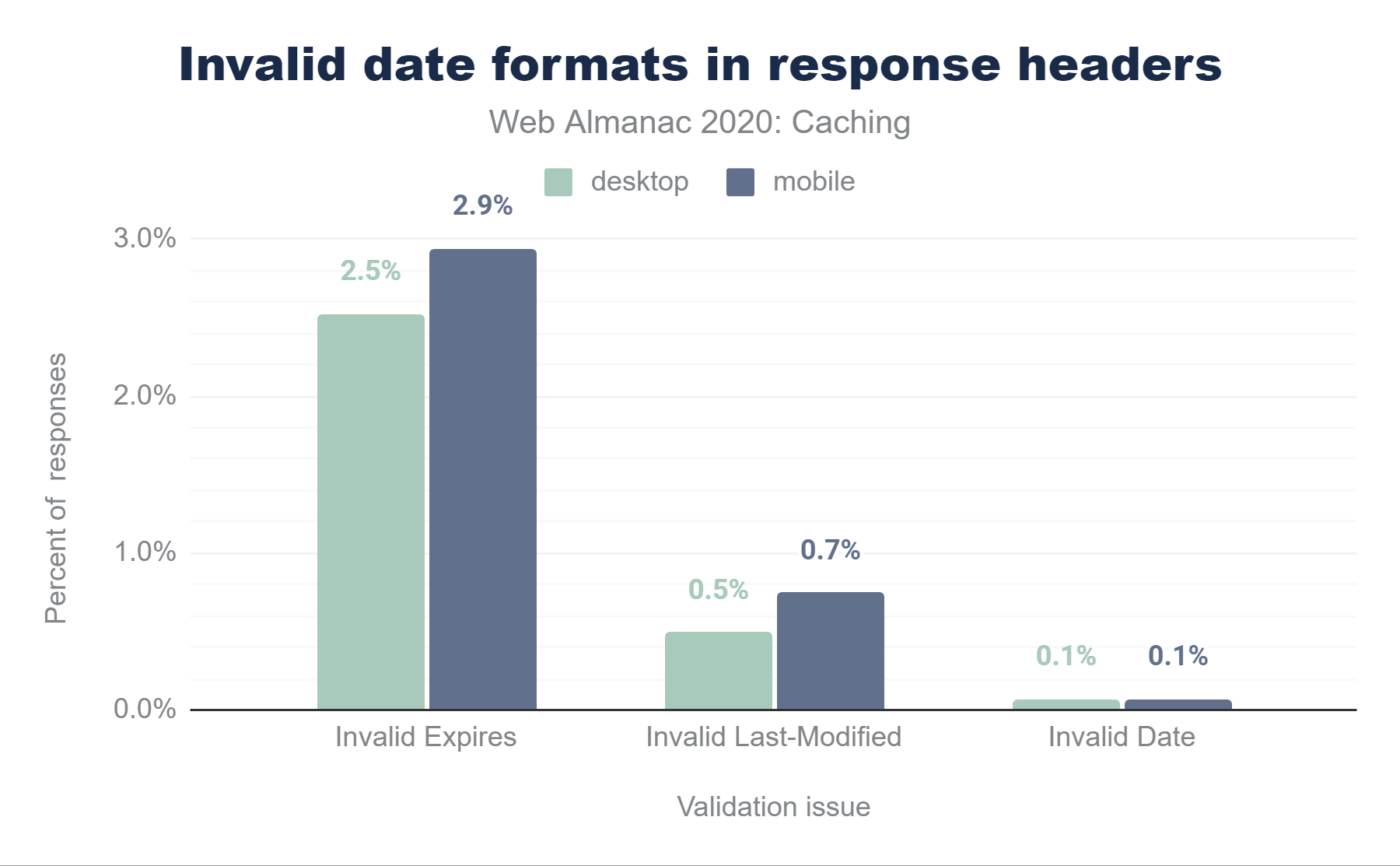
Date, 0.5% in Last-Modified and 2.5% in Expires. The stats for mobile are very similar with 0.1% of responses have an invalid date in Date, 0.7% in Last-Modified and 2.9% in Expires.Because the Date HTTP response header is almost always generated automatically by the web server, invalid values are extremely rare. Similarly Last-Modified headers had a very low percentage (0.75% on mobile and 0.5% on desktop) of invalid values. What was very surprising to see though, was that a relatively high 2.94% of Expires headers used an invalid date format (2.5% in desktop).
Examples of some of the invalid uses of the Expires header are:
- Valid date formats, but using a time zone other than GMT
- Numerical values such as 0 or -1
- Values that would be valid in a
Cache-Controlheader
One large source of invalid Expires headers is from assets served from a popular third party, in which a date/time uses the EST time zone, for example Expires: Tue, 27 Apr 1971 19:44:06 EST. Note that some browsers may understand and accept this date format, on the principle of robustness, but it should not be assumed that this will be the case.
The Vary header
We have discussed how a caching entity can determine whether a response object is cacheable, and for how long it can be cached. However, one of the most important steps the caching entity must take is determining if the resource being requested is already in its cache. While this may seem simple, many times the URL alone is not enough to determine this. For example, requests with the same URL could vary in what compression they used (Gzip, Brotli, etc.) or could be returned in different encodings (XML, JSON etc.).
To solve this problem, when a caching entity caches an object, it gives the object a unique identifier (a cache key). When it needs to determine whether the object is in its cache, it checks for the existence of the object using the cache key as a lookup. By default, this cache key is simply the URL used to retrieve the object, but servers can tell the caching entity to include other attributes of the response (such as compression method) in the cache key, by including the Vary response header. The Vary header identifies variants of the object, based on factors other than the URL.
The Vary response header instructs the browser to add the value of one or more request header values to the cache key. The most common example of this is Vary: Accept-Encoding, which will result in the browser caching the same object in different formats, based on the different Accept-Encoding request header values (i.e. gzip, br, deflate).
A caching entity sends a request for an HTML file, indicating that it will accept a gzipped response:
> GET /index.html HTTP/2
> Host: www.example.org
> Accept-Encoding: gzipThe server responds with the object and indicates that the version it is sending should include the value of the Accept-Encoding request header.
< HTTP/2 200 OK
< Content-Type: text/html
< Vary: Accept-EncodingIn this simplified example, the caching entity would cache the object using a combination of the URL and the Vary header.
Another common value is Vary: Accept-Encoding, User-Agent, which instructs the client to include both the Accept-Encoding and User-Agent values in the cache key. However, when discussing shared proxies and CDNs, using values other than Accept-Encoding can be problematic as it dilutes or fragments the cache and can reduce the amount of traffic served from cache. For instance, there are several thousand different varieties of User-Agent, so if a CDN attempts to cache many different variants of an object, it may end up filling up the cache with many almost identical (or indeed, identical) cached objects. This is very inefficient and can lead to very sub-optimal caching within the CDN, resulting in fewer cache hits and greater latency.
In general, you should only vary the cache if you are serving alternate content to clients based on that header.
The Vary header is used on 43.4% of HTTP responses, and 84.2% of these responses include a Cache-Control header.
The graph below details the popularity for the top 10 Vary header values. Accept-Encoding accounts for almost 92% of Vary’s use, with User-Agent at 10.7%, Origin (used for CORS processing) at 8%, and Accept at 4.1% making up much of the rest.
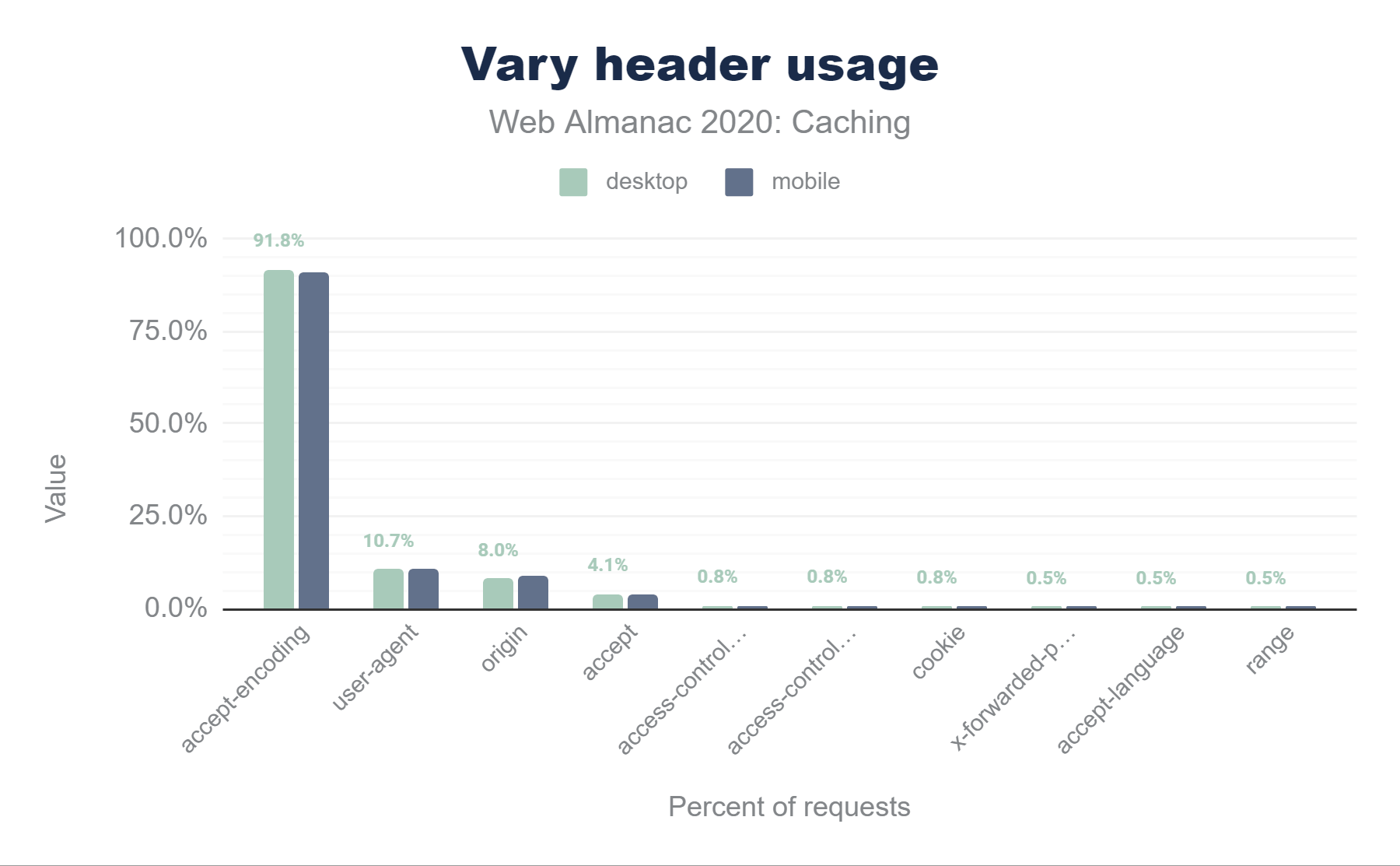
Vary header. 91.8% of desktop responses use of Accept-Encoding, much smaller values for the rest with 10.7% for User-Agent, approximately 8.0% for Origin, and 0.5%-4.1% for Accept, Access-Control-Request-Headers,Access-Control-Request-Method, Cookie, X-Forwarded-Proto, Accept-Language, and Range. 91.3% of mobile responses use of Accept-Encoding, much smaller values for the rest with 11.0% for User-Agent, approximately 9.1% for Origin, and 0.6%-3.9% for Accept, Access-Control-Request-Headers, Access-Control-Request-Method, Cookie, X-Forwarded-Proto, Accept-Language, and Range.Vary header usage.
Setting cookies on cacheable responses
When a response is cached, its entire set of response headers are included with the cached object as well. This is why you can see the response headers when inspecting a cached response in Chrome via DevTools:
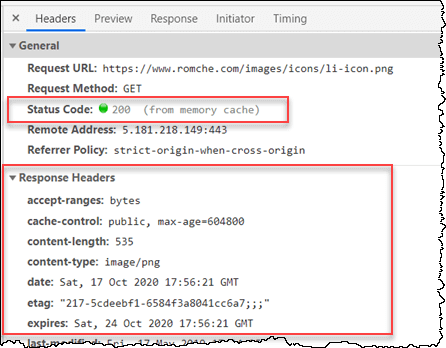
But what happens if you have a Set-Cookie on a response? According to RFC 7234 Section 8, the presence of a Set-Cookie response header does not inhibit caching. This means that a cached entry might contain a Set-Cookie response header. The RFC goes on to recommend that you should configure appropriate Cache-Control headers to control how responses are cached.
Since we have primarily been talking about browser caching, you may think this isn’t a big issue—the Set-Cookie response headers that were sent by the server to me in responses to my requests clearly contain my cookies, so there’s no problem if my browser caches them. However, if there is a CDN between myself and the server, the server must indicate to the CDN that the response should not be cached in the CDN itself, so that the response meant for me is not cached and then served (including my Set-Cookie headers!) to other users.
For example, if a login cookie or a session cookie is present in a CDN’s cached object, then that cookie could potentially be reused by another client. The primary way to avoid this is for the server to send the Cache-Control: private directive, which tells the CDN not to cache the response, because it may only be cached by the client browser.
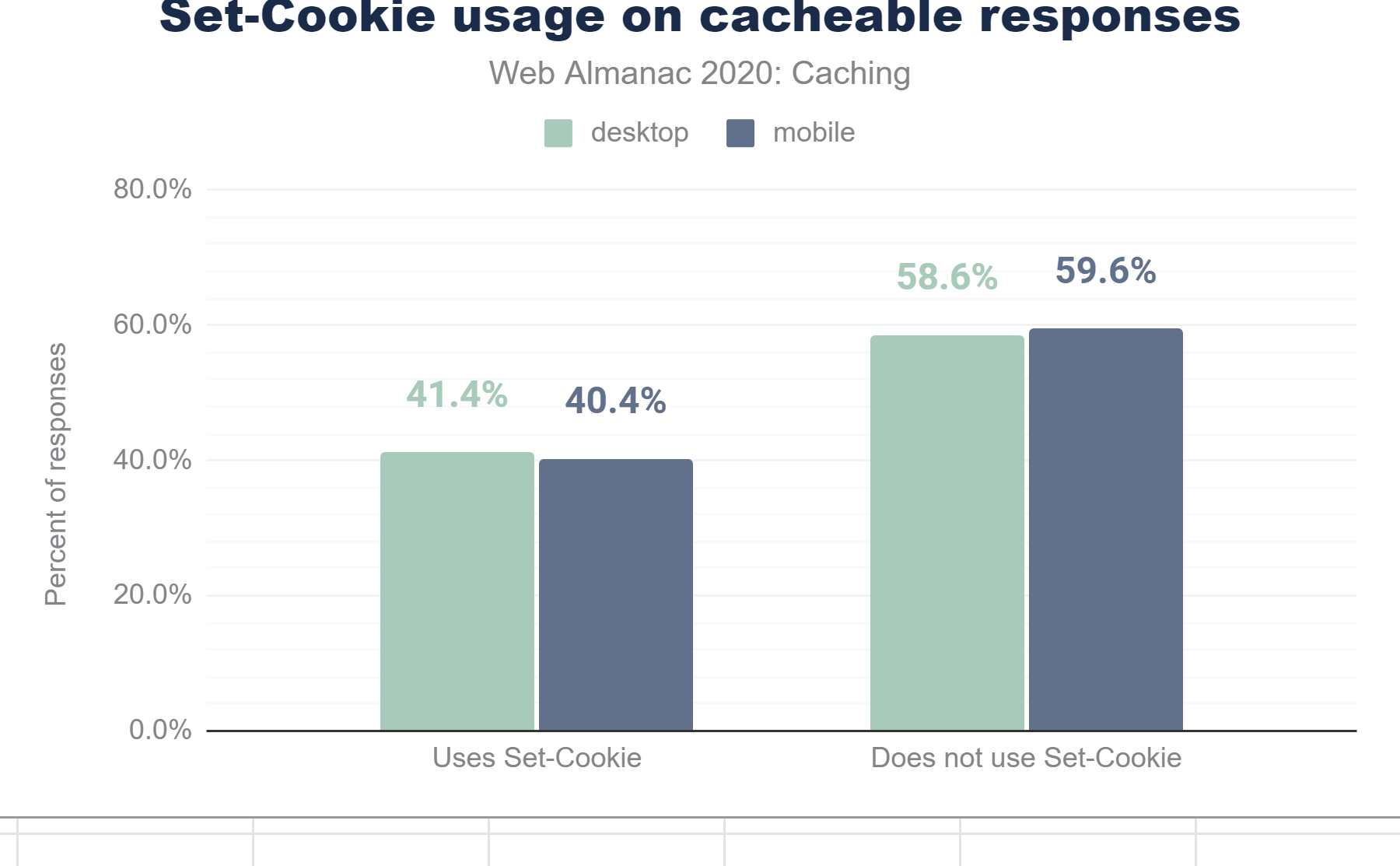
Set-Cookie usage on cacheable responses. 41.4% of cacheable desktop responses and 40.4% of cacheable mobile responses contain a Set-Cookie header.Set-Cookie in cacheable responses.
40.4% of cacheable mobile responses contain a Set-Cookie header. Of those responses, only 4.9% use the private directive. The remaining 95.1% (198.6 million HTTP responses) contain at least one Set-Cookie response header and can be cached by both public cache servers, such as CDNs. This is concerning and may indicate a continued lack of understanding about how cacheability and cookies coexist.

Set-Cookie usage in private and non-private cacheable responses. Of the desktop responses containing a Set-Cookie header, 4.6% use the private directive. 95.4% responses can be cached by both private and public cache servers. Of the mobile responses containing a Set-Cookie header, 4.9% use the private directive. 95.1% responses can be cached by both private and public cache servers.Set-Cookie in private and non-private cacheable responses.
Service workers
Service workers are a feature of HTML5 that allow front-end developers to specify scripts that should run outside the normal request/response flow of web pages, communicating with the web page via messages. Common uses of service workers are for background synchronization and push notifications and, obviously, for caching—and browser support has been rapidly growing for them.
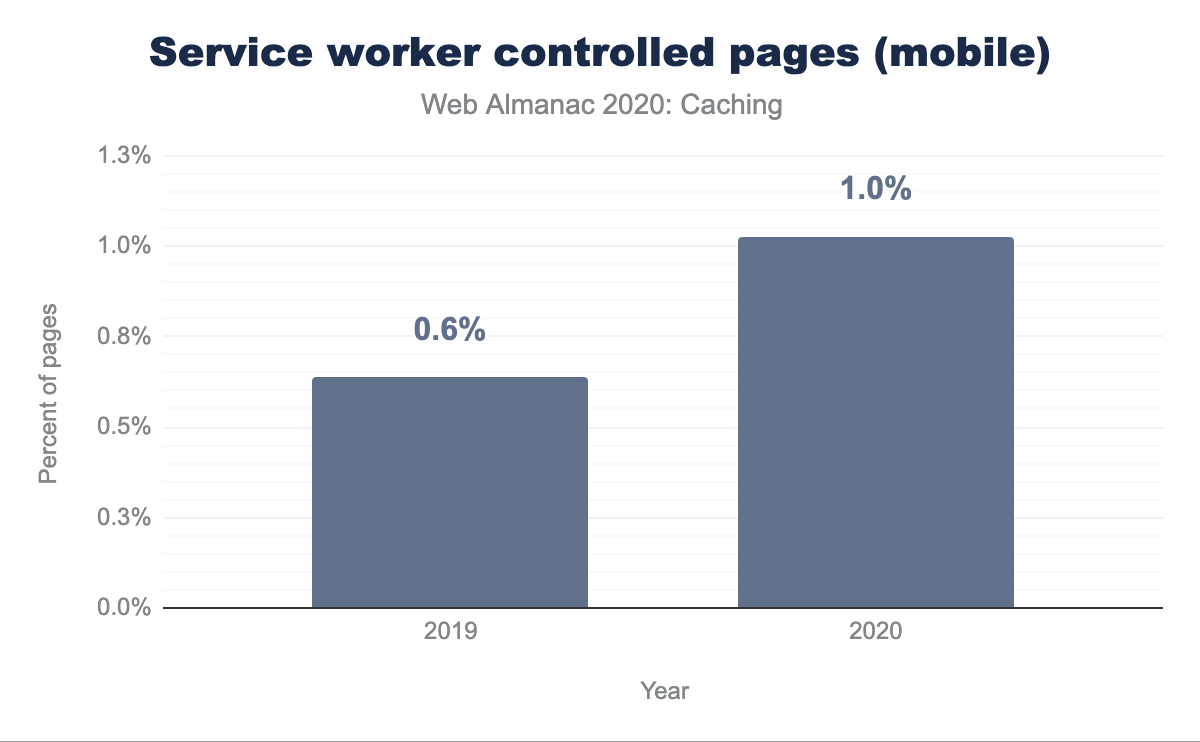
Adoption is just at 1% of websites, but it has been steadily increasing since July 2019. The Progressive Web App chapter discusses this more, including the fact that it is used a lot more than this graph suggests due to its usage on popular sites, which are only counted once in the above graph.
| Sites not using service workers | Sites using service workers | Total sites |
|---|---|---|
| 6,225,774 | 64,373 | 6,290,147 |
In the table above, you can see that 64,373 site out of a total of 6,290,147 websites have implemented a service worker.
| HTTP Sites | HTTPS Sites | Total Sites |
|---|---|---|
| 1,469 | 62,904 | 64,373 |
If we break this out by HTTP vs HTTPS, then this gets even more interesting. Even though HTTPS is a requirement for using service workers, the following table shows that 1,469 of the sites using them are served over HTTP.
What type of content are we caching?
As we have seen, a cacheable resource is stored by the browser for a period of time and is available for reuse on subsequent requests.
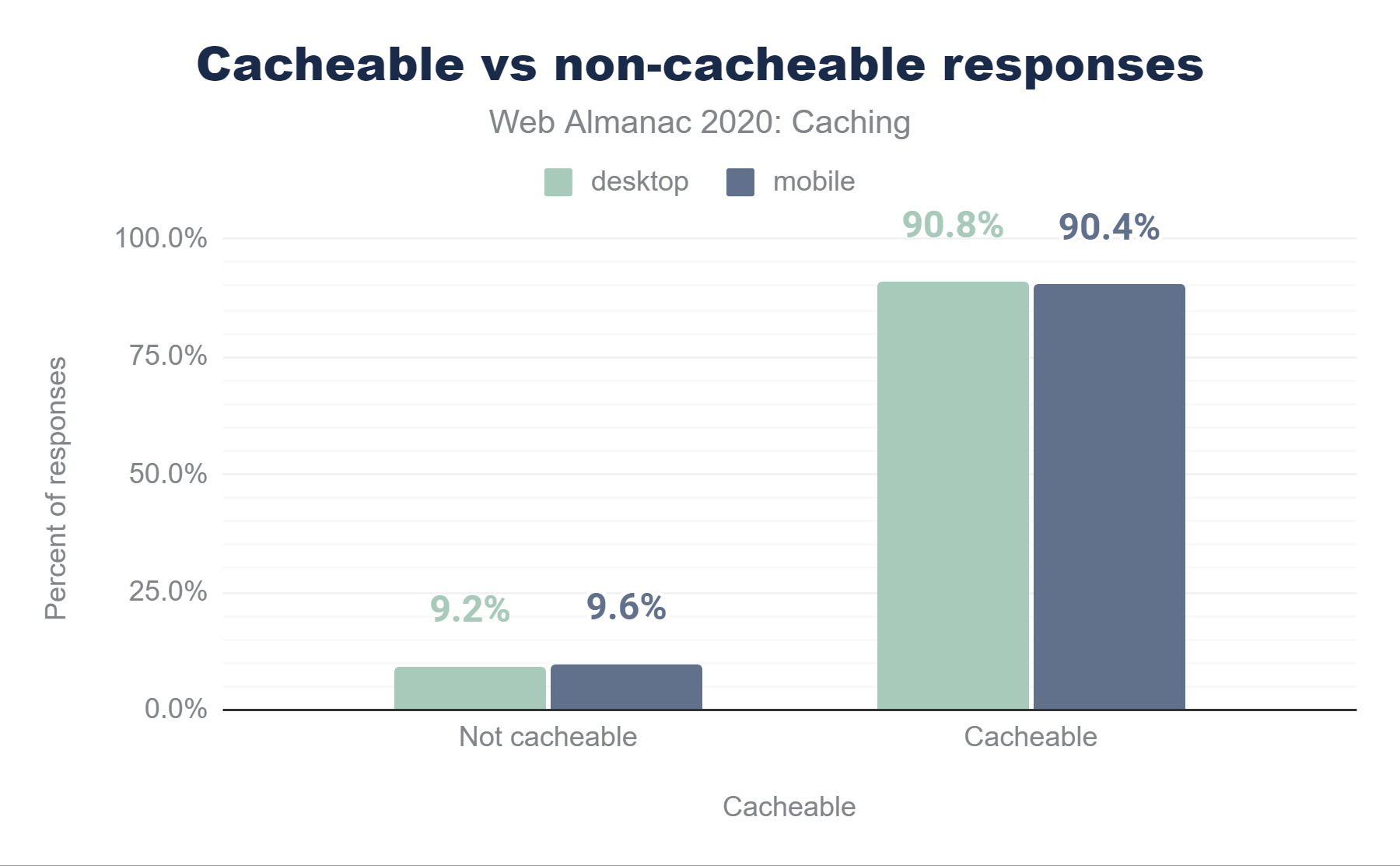
Across all HTTP(S) requests, 90.4% of responses are considered cacheable, meaning that a cache is permitted to store them. The remaining 9.6% of responses are not permitted to be stored in browser caches—typically because of Cache-Control: no-store.
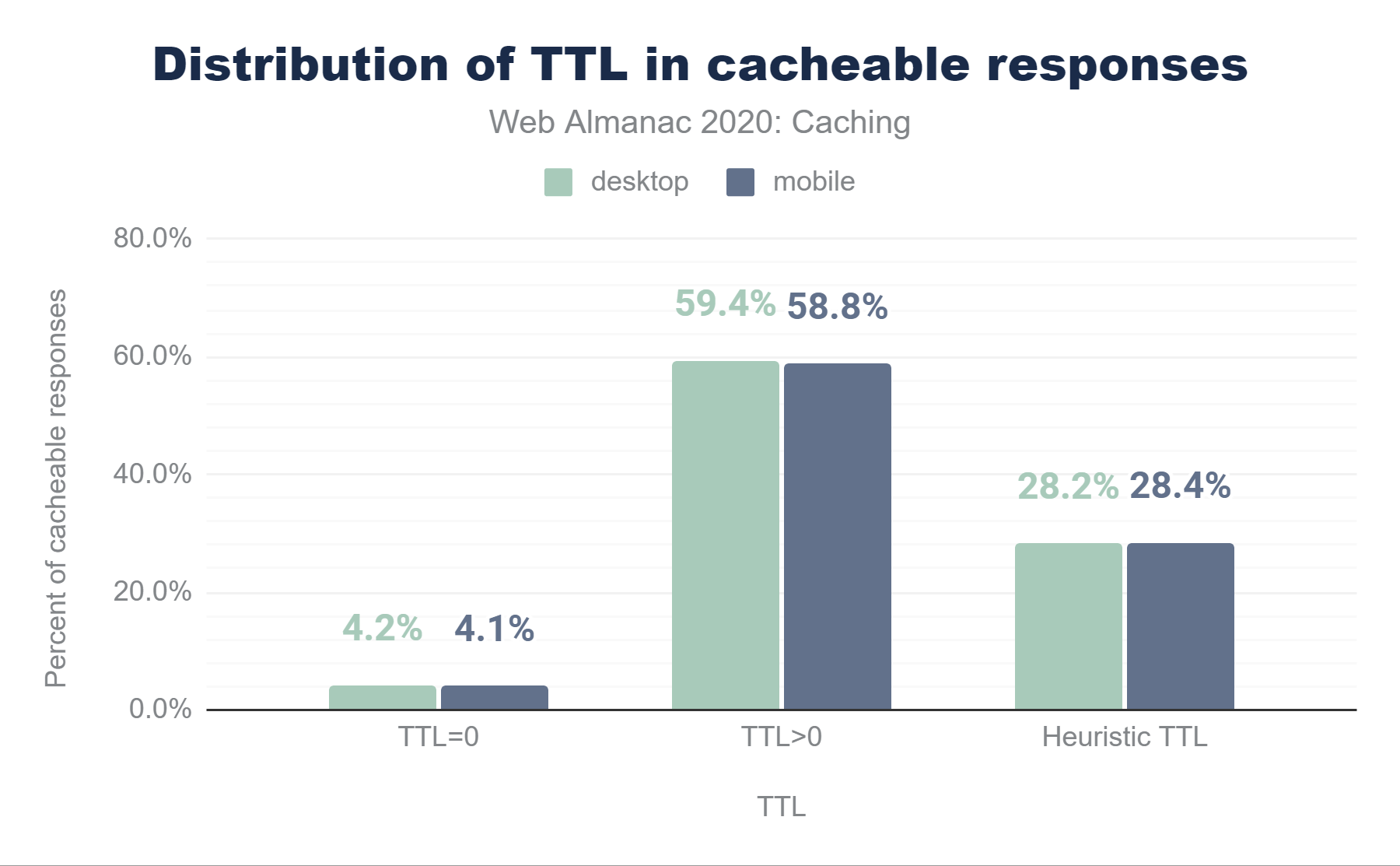
Digging a little deeper, we see that 4.1% of requests have a TTL of 0 seconds, which causes the object to be added to cache, but immediately marked as stale, requiring revalidation. 28.4% are cached heuristically because of a lack of either a Cache-Control or Expires header and 58.8% are cached for more than 0 seconds.
The table below details the cache TTL values for mobile requests by type:
| Type | 10 | 25 | 50 | 75 | 90 |
|---|---|---|---|---|---|
| Audio | 6 | 6 | 240 | 744 | 8,760 |
| CSS | 24 | 24 | 720 | 8,760 | 8,760 |
| Font | 720 | 8,760 | 8,760 | 8,760 | 8,760 |
| HTML | 0 | 3 | 336 | 8,760 | 8,600 |
| Image | 6 | 168 | 720 | 8,760 | 8,766 |
| Other | 0 | 3 | 31 | 336 | 23,557 |
| Script | 0 | 4 | 720 | 8,760 | 8,760 |
| Text | 0 | 1 | 6 | 24 | 8,760 |
| Video | 6 | 336 | 336 | 336 | 8,674 |
| XML | 1 | 24 | 24 | 24 | 720 |
While most of the median TTLs are high, the lower percentiles highlight some of the missed caching opportunities. For example, the median TTL for images is 720 hours (1 month); however the 25th percentile is just 168 hours (1 week) and the 10th percentile has dropped to just a few hours. Compare this with fonts, which have a very high TTL of 8,760 hours (1 year) all the way down to the 25th percentile, with even the 10th percentile showing a TTL of 1 month.
By exploring the cacheability by content type in more detail in figure below, we can see that while fonts, video and audio, and CSS files are browser cached at close to 100% (which makes sense, since these files are typically very static), approximately one third of all HTML responses are considered non-cacheable.
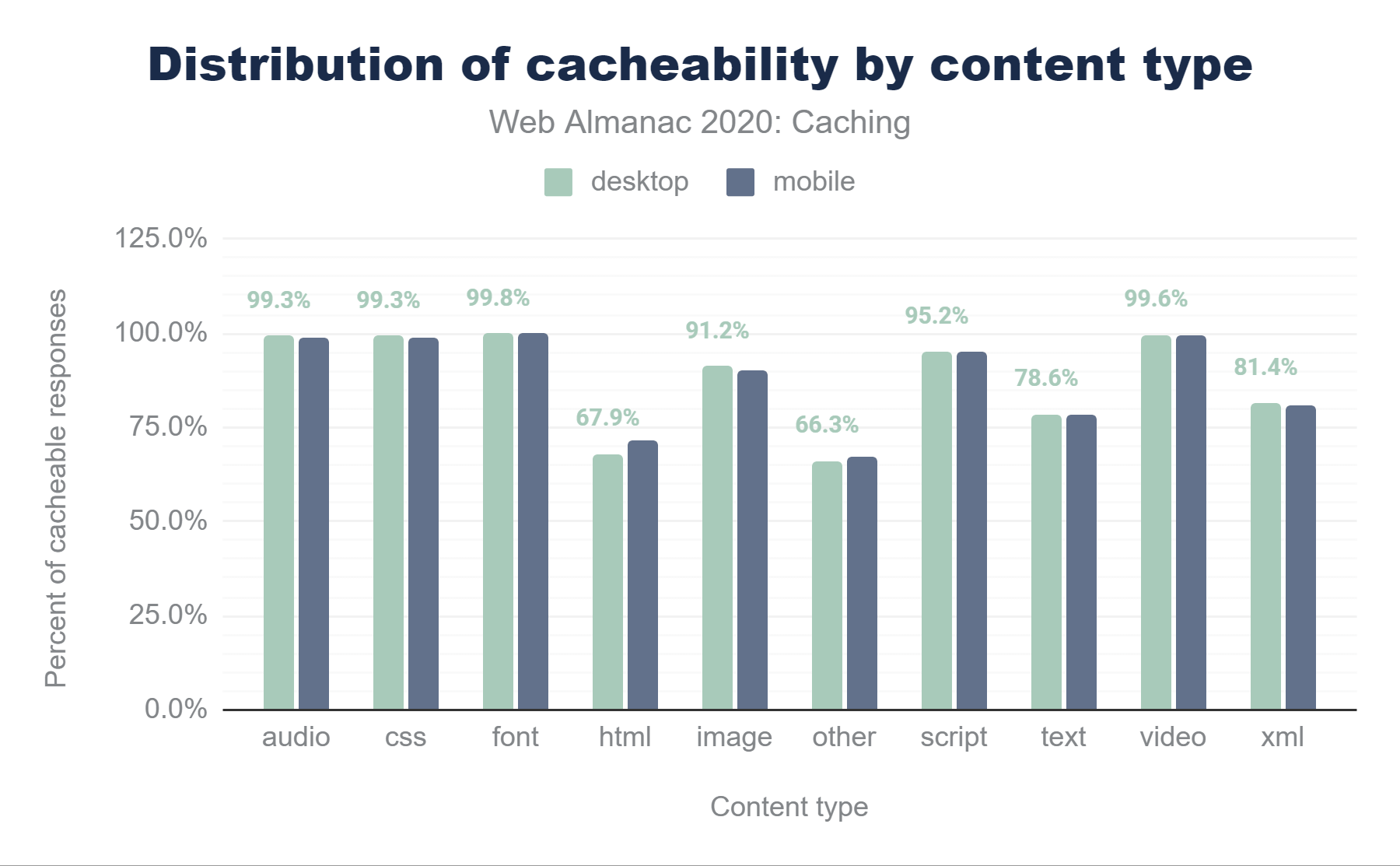
Additionally, 10.1% of images and 4.9% scripts on desktop are non-cacheable. There is likely some room for improvement here, since no doubt some of these objects are also static and could be cached at a higher rate—remember: cache as much as you can for as long as you can!
How do cache TTLs compare to resource age?
So far we’ve talked about how servers tell a client what is cacheable, and how long it has been cached for. When designing cache rules, it is also important to understand how old the content you are serving is.
When you are selecting a cache TTL to specify in response headers to send back to the client, ask yourself: “how often am I updating these assets?” and “what is their content sensitivity?”. For example, if a hero image is going to be modified infrequently, then it could be cached with a very long TTL. By contrast, if a JavaScript file will change frequently, then either it should be versioned, for instance with a unique query string, and cached with a long TTL or it should be cached with a much shorter TTL.
The graphs below illustrate the relative age of resources by content type.
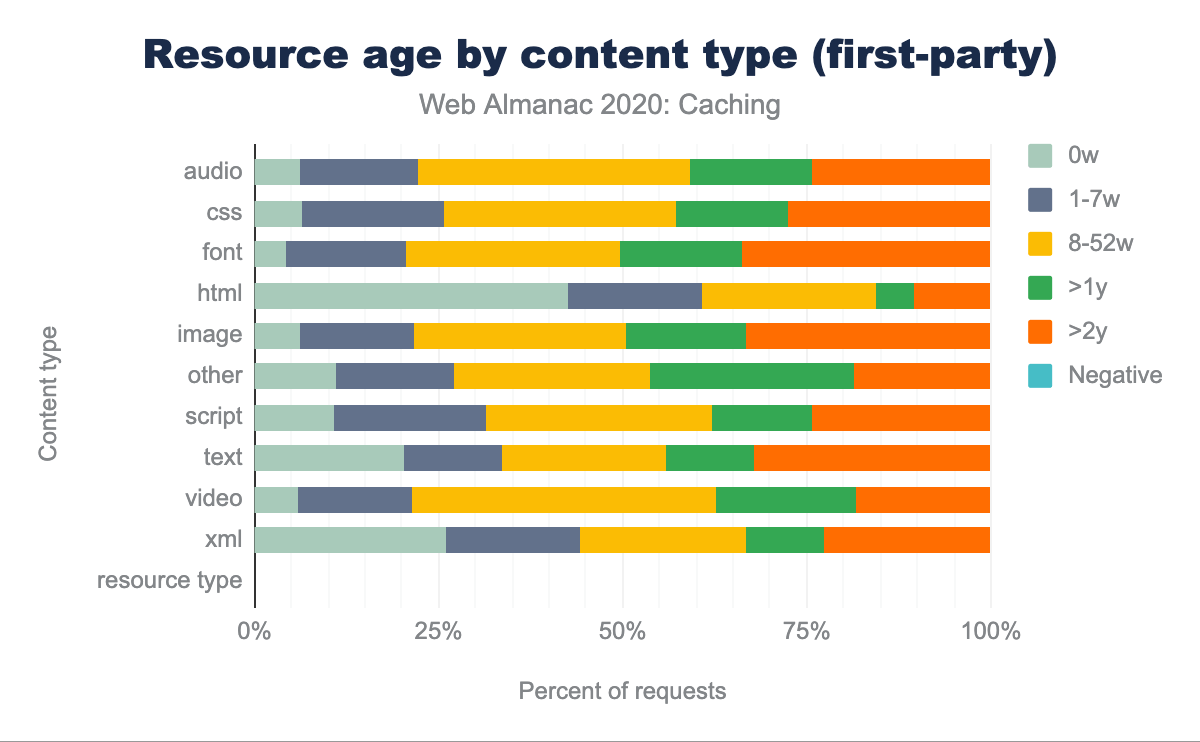
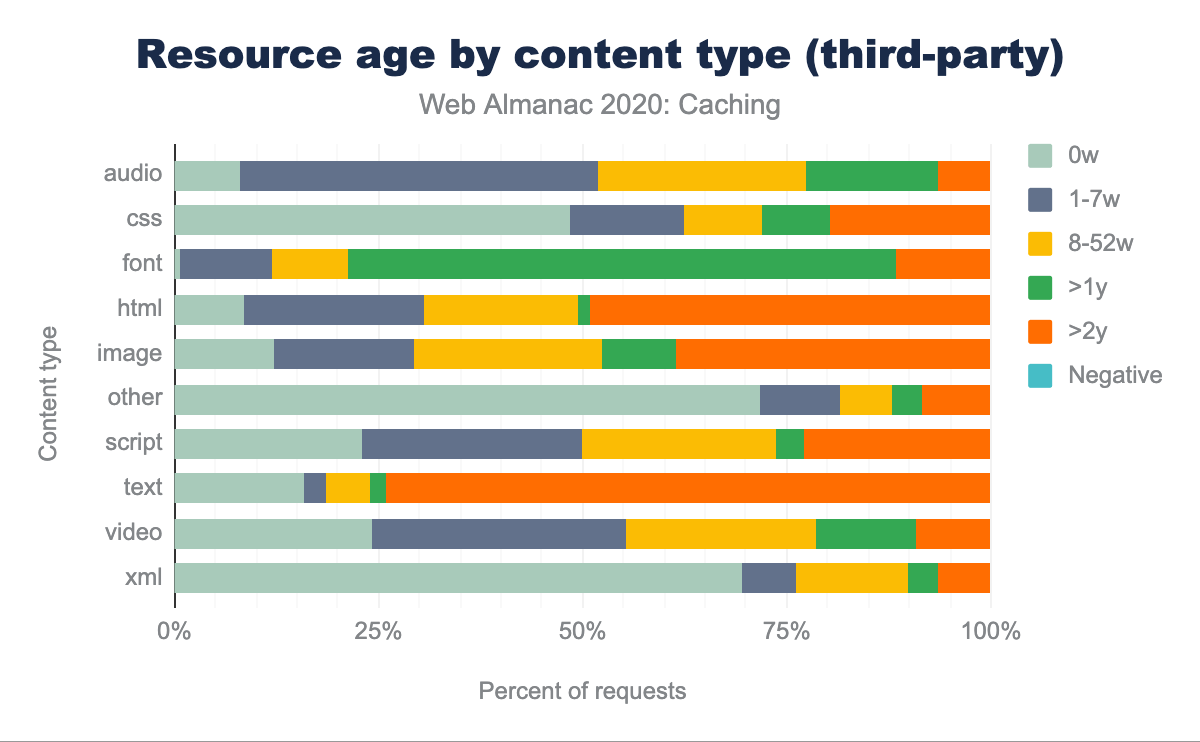
Some of the interesting observations in this data are:
- First-party HTML is the content type with the shortest age, with 41.1% of the requests having an age less than a week. In most of the other content types, third-party content has a smaller resource age than first party content.
- Some of the longest aged first-party content on the web, with age eight weeks or more, are the traditionally cacheable objects like images (78.9%), scripts (68.7%), CSS (74.9%), web fonts (80.4%), audio (78.2%) and video (79.3%).
- There is a significant gap in some first vs. third-party resources having an age of more than a week. 93.4% of first-party CSS are older than one week compared to 48.0% of third-party CSS, which are older than one week.
By comparing a resource’s cacheability to its age, we can determine if the TTL is appropriate or too low.
For example, the resource served below on 18 Oct 2020 was last modified on 30 Aug 2020, which means that it was well over a month old at the time of delivery—this indicates that it is an object which does not change frequently. However, the Cache-Control header says that the browser can cache it for only 86,400 seconds (one day). This is a case where a longer TTL might be appropriate, to avoid the browser needing to re-request it, even conditionally—especially if the website is one that a user might visit multiple times over the course of several days.
> HTTP/1.1 200
> Date: Sun, 18 Oct 2020 19:36:57 GMT
> Content-Type: text/html; charset=utf-8
> Content-Length: 3052
> Vary: Accept-Encoding
> Last-Modified: Sun, 30 Aug 2020 16:00:30 GMT
> Cache-Control: public, max-age=86400Overall, 60.2% of mobile resources served on the web have a cache TTL that could be considered too short compared to its content age. Furthermore, the median delta between the TTL and age is 25 days—again, an indication of significant under-caching.
| Client | 1st party | 3rd party | Overall |
|---|---|---|---|
| desktop | 61.6% | 59.3% | 60.7% |
| mobile | 61.8% | 57.9% | 60.2% |
When we break this out by first-party vs third-party in the above table, we can see that almost two-thirds (61.8%) of first-party resources can benefit from a longer TTL. This clearly highlights a need to spend extra attention focusing on what is cacheable, and then ensuring that caching is configured correctly.
Identifying caching opportunities
Google’s Lighthouse tool enables users to run a series of audits against web pages, and the cache policy audit evaluates whether a site can benefit from additional caching. It does this by comparing the content age (via the Last-Modified header) to the cache TTL and estimating the probability that the resource would be served from cache. Depending on the score, you may see a caching recommendation in the results, with a list of specific resources that could be cached.
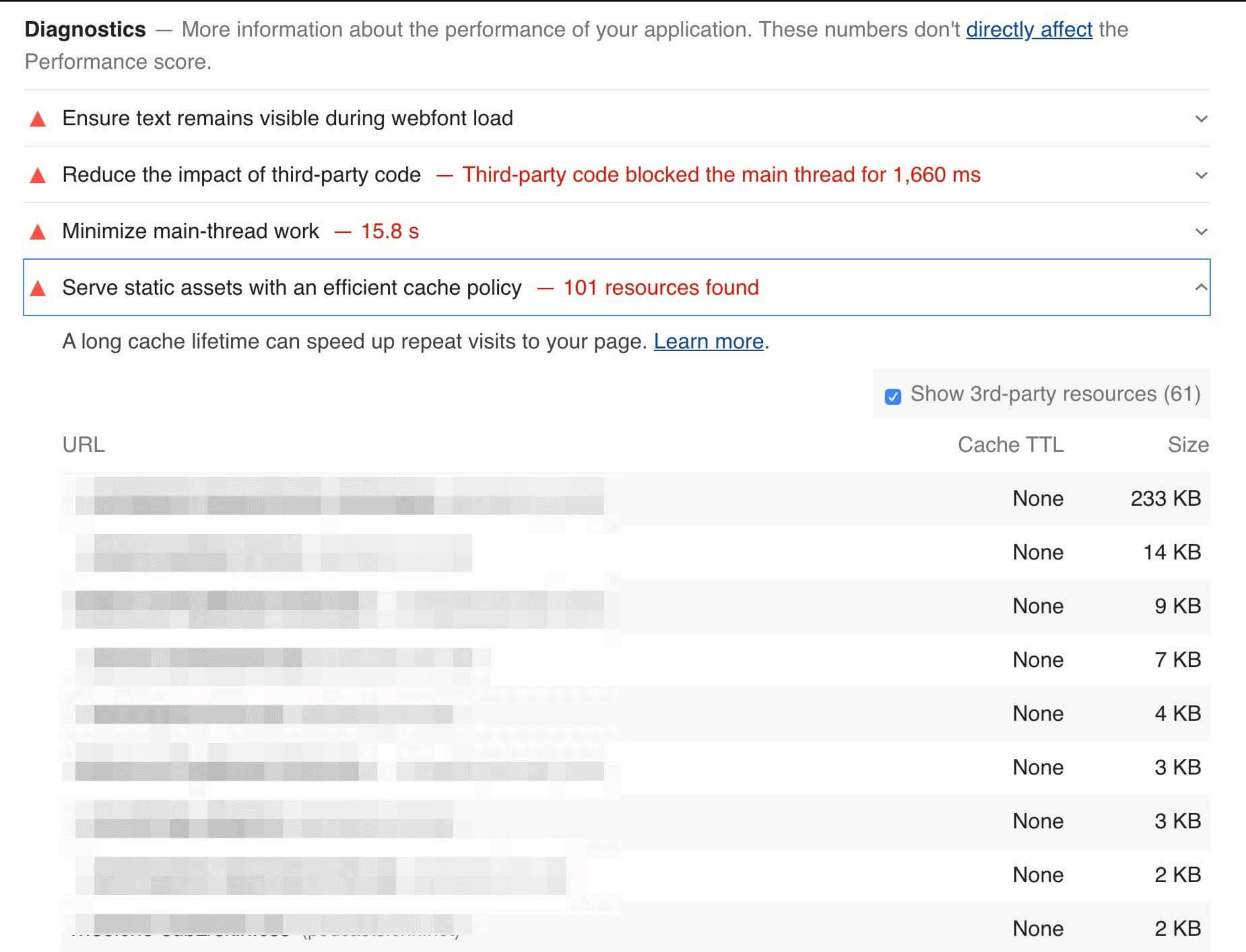
Lighthouse computes a score for each audit, ranging from 0% to 100%, and those scores are then factored into the overall scores. The caching score is based on potential byte savings. When we examine the Lighthouse results, we can get a perspective of how many sites are doing well with their cache policies.
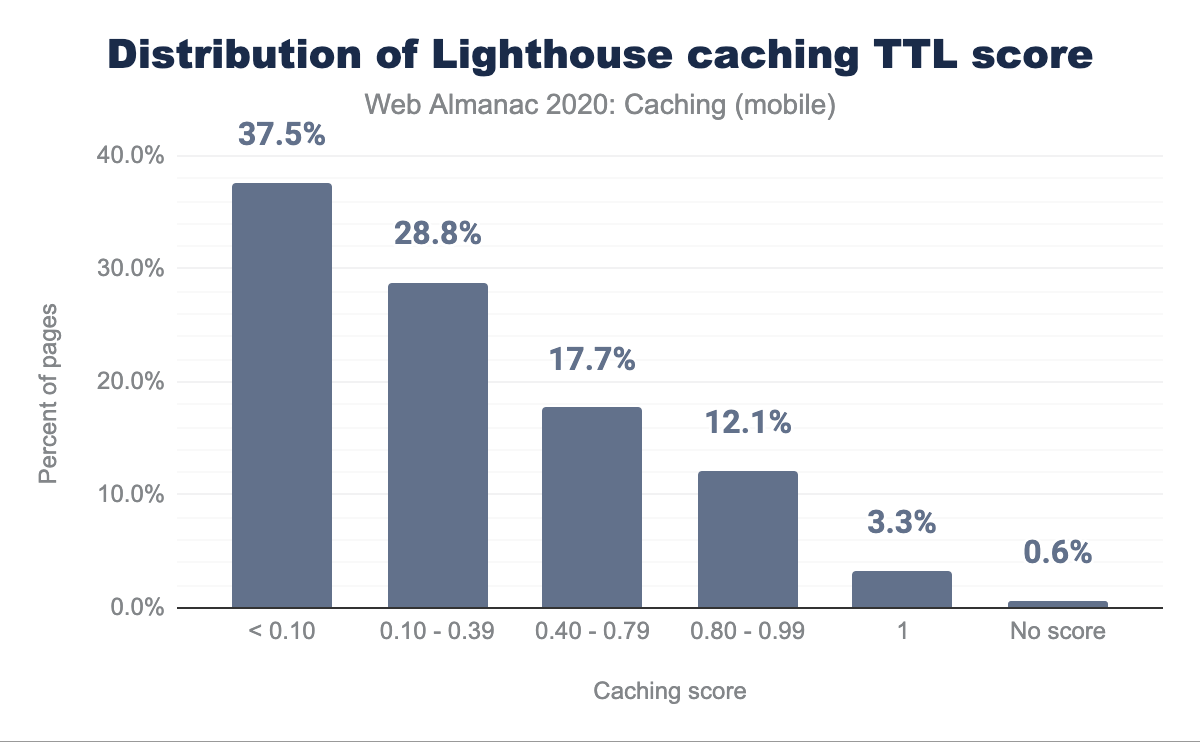
uses-long-cache-ttl for mobile web pages. 37.5% of the responses have a score less than 0.10, 28.8% have a score between 0.10-0.39, 17.7% have a score between 0.40-0.79, and 12.1% have a score between 0.80-0.99. 3.3% have a score of 1 and 0.6% have no score.Only 3.3% of sites scored a 100%, meaning that the vast majority of sites can probably benefit from some cache optimizations. Approximately two-thirds of sites score below 40%, with almost one-third of sites scoring less than 10%. Based on this, there is a significant amount of under-caching, resulting in excess requests and bytes being served across the network.
Lighthouse also indicates how many bytes could be saved on repeat views by enabling a longer cache policy:
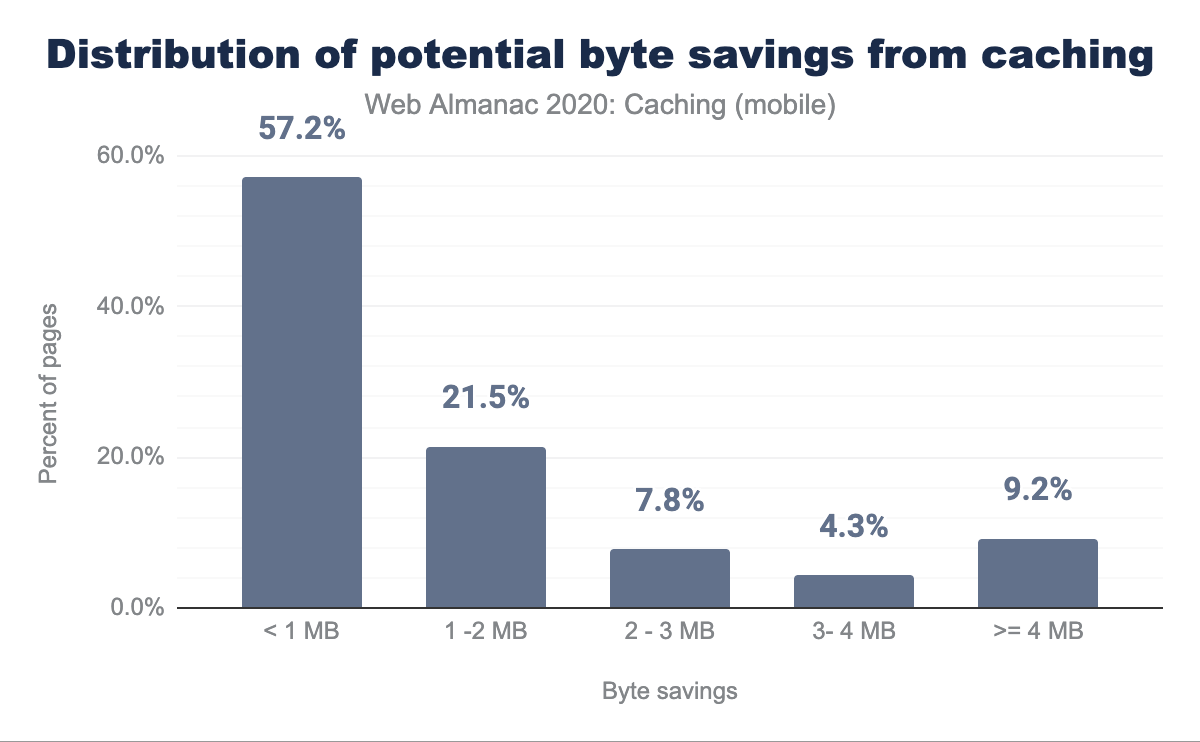
Of the sites that could benefit from additional caching, more than one-fifth can reduce their page weight by over 2 MB!
Conclusion
Caching is an incredibly powerful feature that allows browsers, proxies and other intermediaries such as CDNs to store web content and serve it to end users. The performance benefits of this are significant, since it reduces round-trip times and minimizes costly network requests.
Caching is also a very complex topic, and one that is often left until late in the development cycle (due to requirements by site developers to see the very latest version of a site while it is still being designed), then being added in at the last minute. Additionally, caching rules are often defined once and then never changed, even as the underlying content on a site changes. Frequently a default value is chosen without careful consideration.
To correctly cache objects, there are numerous HTTP response headers that can convey freshness as well as validate cached entries, and Cache-Control directives provide a tremendous amount of flexibility and control.
Many object types and content that are typically considered to be uncacheable can actually be cached (remember: cache as much as you can!) and many objects are cached for too short a period of time, requiring repeated requests and revalidation (remember: cache for as long as you can!). However, website developers should be cautious about the additional opportunities for mistakes that come with over-caching content.
If the site is intended to be served through a CDN, additional opportunities for caching at the CDN to reduce server load and provide faster response to end-users should be considered, along with the related risks of accidentally caching private information, such as cookies.
However, powerful and complex do not necessarily imply difficult. Like most everything else, caching is controlled by rules which can be defined fairly easily to provide the best mix of cacheability and privacy. Regularly auditing your site to ensure that cacheable resources are cached appropriately is recommended, and tools like Lighthouse do an excellent job of helping to simplify such an analysis.

