Caching
Introduction
Over the last two decades, the way we experience web applications has changed, giving us richer and more interactive content. Unfortunately, this content comes with a cost in both data storage and bandwidth. Most of the time, this makes it harder for many of us to fully experience a web product when the network we use is degraded, or our device doesn’t have enough space. Caching is both a solution to and the cause of some of these problems. Learning to navigate the multitude of choices will enable you to build not only for high-end devices but also for the next billion users that access your product from low-end devices.
Caching is a technique that enables the reuse of previously downloaded content, from simple static assets like JavaScript, CSS files or basic string values to more complex JSON API responses.
At its core, caching avoids making specific HTTP requests and allows an application to feel more responsive and reliable to the user. Each request is usually cached in two main places:
- Content Delivery Networks (CDNs) is usually a third-party company with the primary goal of replicating your data as closely as possible to where the user is accessing the application. Most CDNs have some default behavior, but mainly you can give them instructions on how to cache by using headers.
- Browsers will either respect the HTTP headers you defined to optimize the experience, or apply some internal defaults. On top of that, browsers provide access to additional manual caching strategies including storing simple strings in cookies, complex API responses in IndexedDB, or entire resources using CacheStorage with a service worker.
In this chapter, we will mostly focus on the HTTP headers used between the browser and the CDN, briefly mentioning service worker caching strategies.
CDN cache adoption
A Content Delivery Network (CDN) is a group of servers spread out over several locations that usually store copies of data. This allows servers to fulfill requests based on the server closest to the end-user.
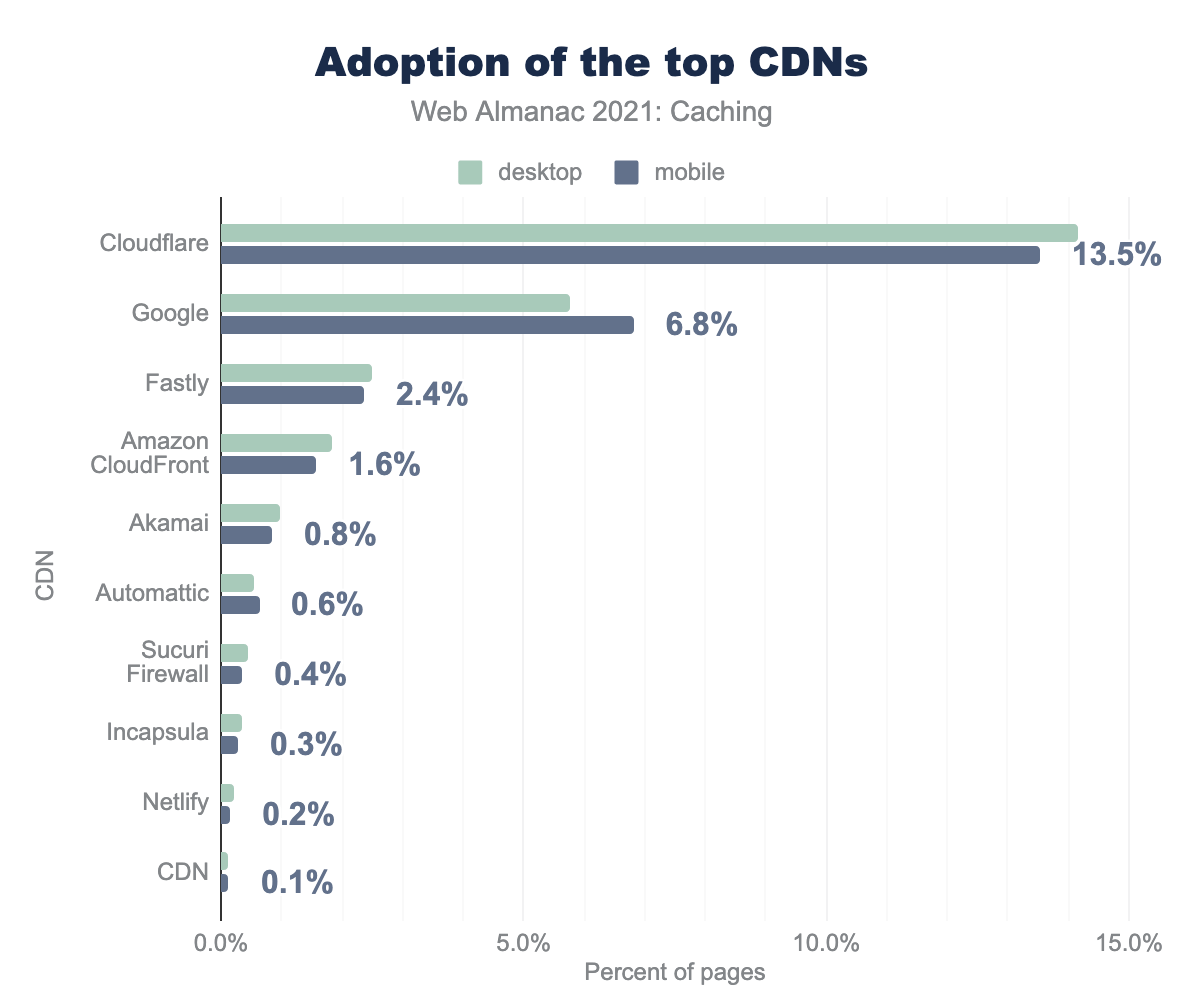
Across the web in 2021, the most popular CDN used for Desktop was Cloudflare with 14% of total pages, followed by Google with 6%. While Cloudflare and Google are the most popular, a large variety of solutions remain available beyond these two including Fastly, Amazon CloudFront, Akamai, and many others.
Service worker adoption
The adoption of service workers has continued to steadily increase.
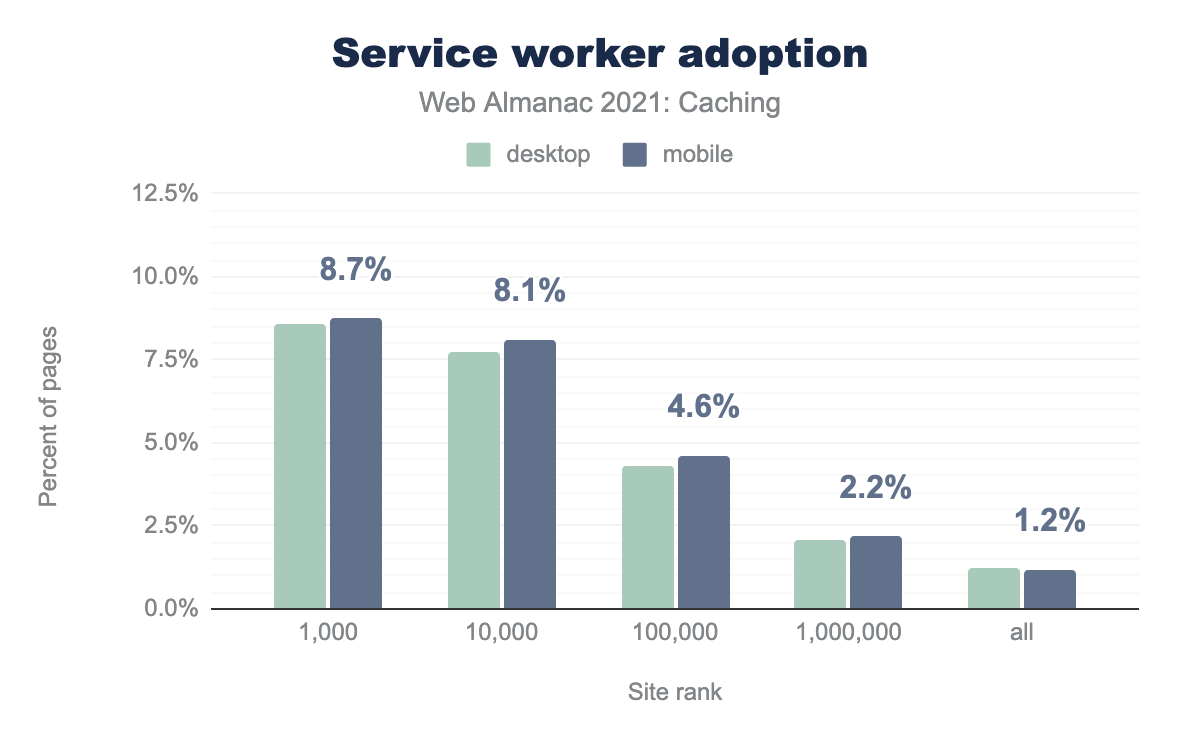
While just over 1% of pages registered a service worker, nearly 9% of pages ranked in the top 1,000 most visited domains registered one.
This higher adoption of service workers, particularly in the top 1,000 pages, could be related to the world-wide trend towards remote-first and by association, mobile-friendly. As our reliance on working and living in one place throughout the entire year shifts, we need our devices to work even harder and smarter to keep up with us. Service workers are a tool that can improve performance when the user is dealing with unreliable networks or low-end devices.
The primary way to cache resources within a service worker is by using the CacheStorage API. This allows a developer to create a custom cache strategy for any requests passing through the worker; some well-known ones are stale-while-revalidate, Cache Falling Back to Network, Network Falling Back to Cache, and Cache Only. In recent years it has become even easier to adopt those strategies thanks to the increased popularity of Workbox, which helps you decide what cache you want to plug and play.
Service workers, and Workbox, are discussed in more detail in the PWA chapter.
Caching headers adoption
With both a CDN and the Browser, HTTP headers are the primary tool a developer must master to properly cache resources. Headers are simply instructions read from the HTTP request or response, and some of them help control the cache strategy used.
The caching-related headers, or the absence of them, tell the browser or CDN three essential pieces of information:
- Cacheability: Is this content cacheable?
- Freshness: If it is cacheable, how long can it be cached for?
- Validation: If it is cacheable, how do I ensure that my cached version is still fresh?
Headers are meant to be used either alone or together. To determine if the content is cacheable and fresh, we have:
Expiresspecifies an explicit expiration date and time (i.e., when precisely the content expires).Cache-Controlspecifies a cache duration (i.e., how long the content can be cached in the browser relative to when it was generated).
When both are specified, Cache-Control takes precedence.
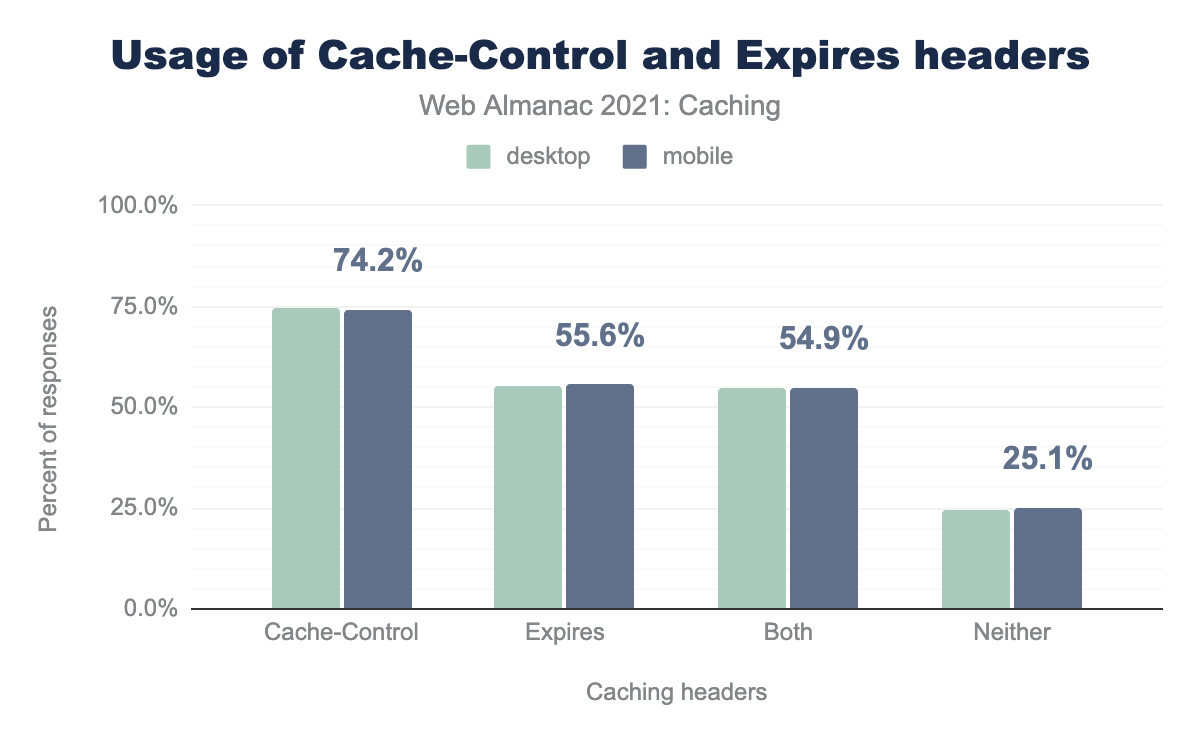
Cache-Control and Expires headers.
Usage of the Cache-Control header has increased steadily since 2019. 74.2% of responses on mobile requests included the Cache-Control header, while 74.8% of responses on desktop requests utilized the header.
Since 2020, the usage of this specific header increased by 0.71% for mobile and by 1.13% for desktop. But on mobile, we still have 25.1% of requests using neither Cache-Control nor Expires headers. This leads us to believe there has been an increase in awareness in the community around proper usage of Cache-Control, but we still have a long way to go to full adoption of these headers.
To validate the content, we have:
Last-Modifiedindicates when the object was last changed. Its value is a date timestamp.ETag(Entity Tag) provides a unique identifier for the content as a quoted string. It can take any format the server chooses. It is typically a hash of the file contents, but it can be a timestamp or a simple string.
When both are specified, ETag takes precedence.
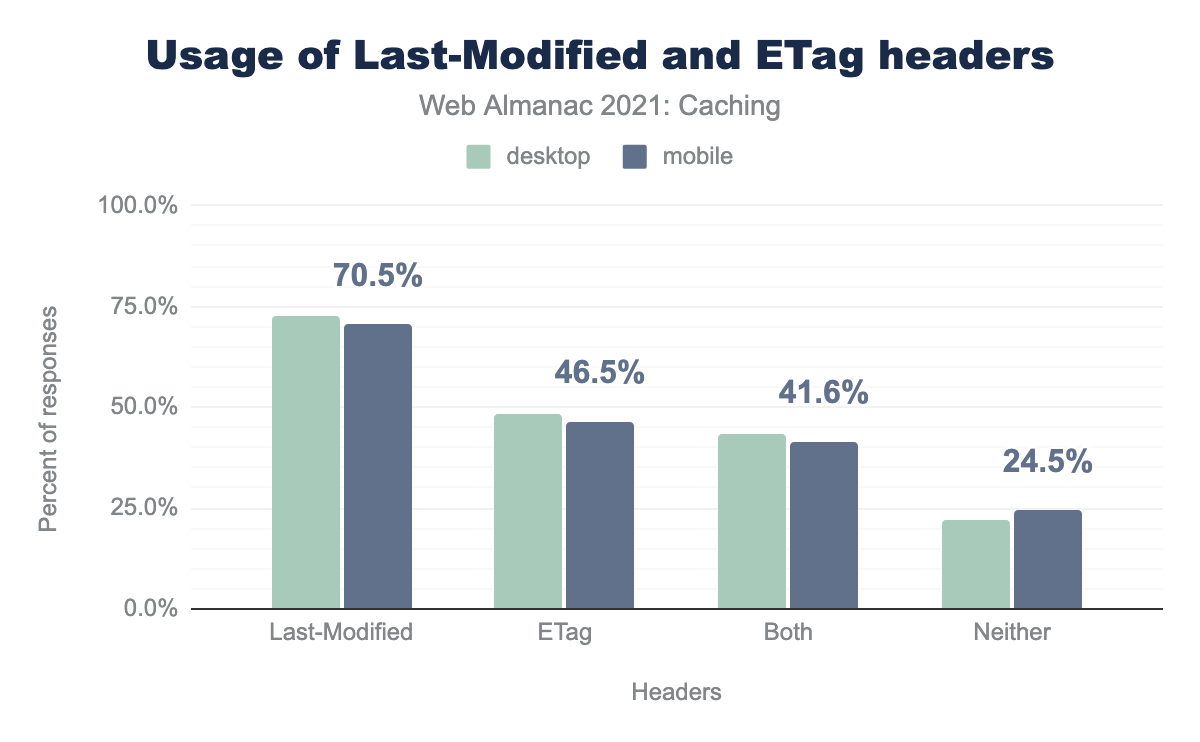
Last-Modified and ETag headers. For desktop and mobile, 70.5% use Last-Modified, 46.5% us ETag, 41.6% use both, and 24.5% use neither.Last-Modified and ETag headers.
Comparing 2020 and 2021, we notice a recurring trend from past years with the ETag becoming slightly more popular each year, and Last-Modified being used 1.5% less. What we should probably keep an eye on next year is a new trend of 1.4% more responses using neither ETag nor Last-Modified headers, as this could imply a challenge in the community understanding the value of these headers.
Cache-Control directives
When using the Cache-Control header, you specify one or more directives—predefined values that indicate specific caching functionality. Multiple directives are separated by commas and can be set in any order, although some clash with one another (e.g., public and private). In addition, some directives take a value, such as max-age.
Below is a table showing the most common Cache-Control directives:
| Directive | Description |
|---|---|
max-age |
Indicates the number of seconds that a resource can be cached for relative to the current time. For example, max-age=86400. |
public |
Indicates that any cache can store the response, including the browser and the CDN. This is assumed by default. |
no-cache |
A cached resource must be revalidated before its use, via a conditional request, even if it is not marked as stale. |
must-revalidate |
A stale cached entry must be revalidated before its use, via a conditional request. |
no-store |
Indicates that the response must not be cached. |
private |
The response is intended for a specific user and should not be stored by shared caches such as CDNs. |
immutable |
Indicates that the cached entry will never change during its TTL, and that revalidation is not necessary. |
Cache-Control directives.
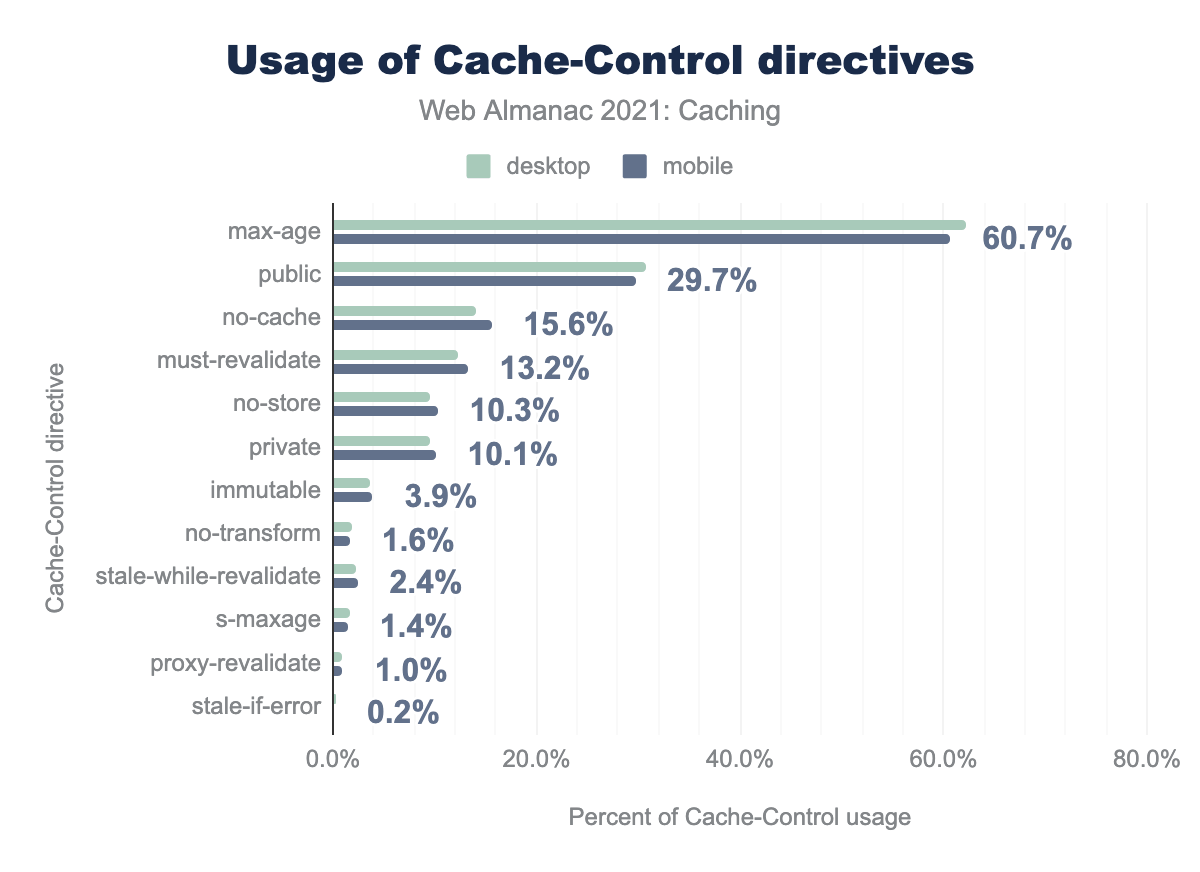
Cache-Control directives. The usage for desktop ranges from 62.2% for max-age, 29.7% for public, 16.5% for no-cache, 12.2% for must-revalidate, 9.6% for no-store, 9.5% for private, 3.5% for immutable, 1.8% for no-transform, 2.3% for stale-while-revalidate, 1.6% for s-maxage, 0.9% for proxy-revalidate , and 0.2% for stale-if-error. Usage for mobile ranges from 60.7% for max-age, 29.7% for public, 15.6% for no-cache, 13.2% for must-revalidate, 10.3% for no-store, 10.1% for private, 3.9% for immutable, 1.6% for no-transform, 2.4% for stale-while-revalidate, 1.4% for s-maxage, 1.0% for proxy-revalidate , and 0.2% for stale-if-error.Cache-Control directives.
The max-age directive is the most commonly found with 62.2% of desktop requests including a Cache-Control response header with this directive.
Compared to 2020, max-age adoption increased by 2% on desktop, along with most of the top seven directives in the above chart.
The immutable directive is relatively new and can significantly improve cacheability for certain types of requests. However, it is still only supported by a few browsers, and we see most requests coming from host networks like Wix with 16.4%, Facebook with 8.6%, Tawk with 2.8%, and Shopify with 2.4%.
The most misused Cache-Control directive continues to be set-cookie, used for 0.07% of total directives for desktop and 0.08% for mobile. However, we are pleased to see a meaningful 0.16% reduction of usage from 2020.
When we take a look when no-cache, max-age=0 and no-store are used together, we also see a growing trend year after year, in which no-store is specified with either/both of no-cache and max-age=0, the no-store directive takes precedence, and the other directives are ignored. Driving more awareness around using these directives, for example during larger conferences, could help avoid accidentally wasted bytes.
max-age.
Fun fact: The most common max-age value is 30 days, and the largest value is 51 trillion years.
304 Not Modified status
When it comes to size, 304 Not Modified responses are much smaller than 200 OK responses, so it follows that page performance can be sped up by only delivering the necessary size of data. This is where correctly using conditional requests comes in. Revalidation, and therefore data savings, can be done by using either an ETag or Last-Modified header.
The Last-Modified response header works in conjunction with the If-Modified-Since request header to let the browser know if any changes have been made to the requested file.
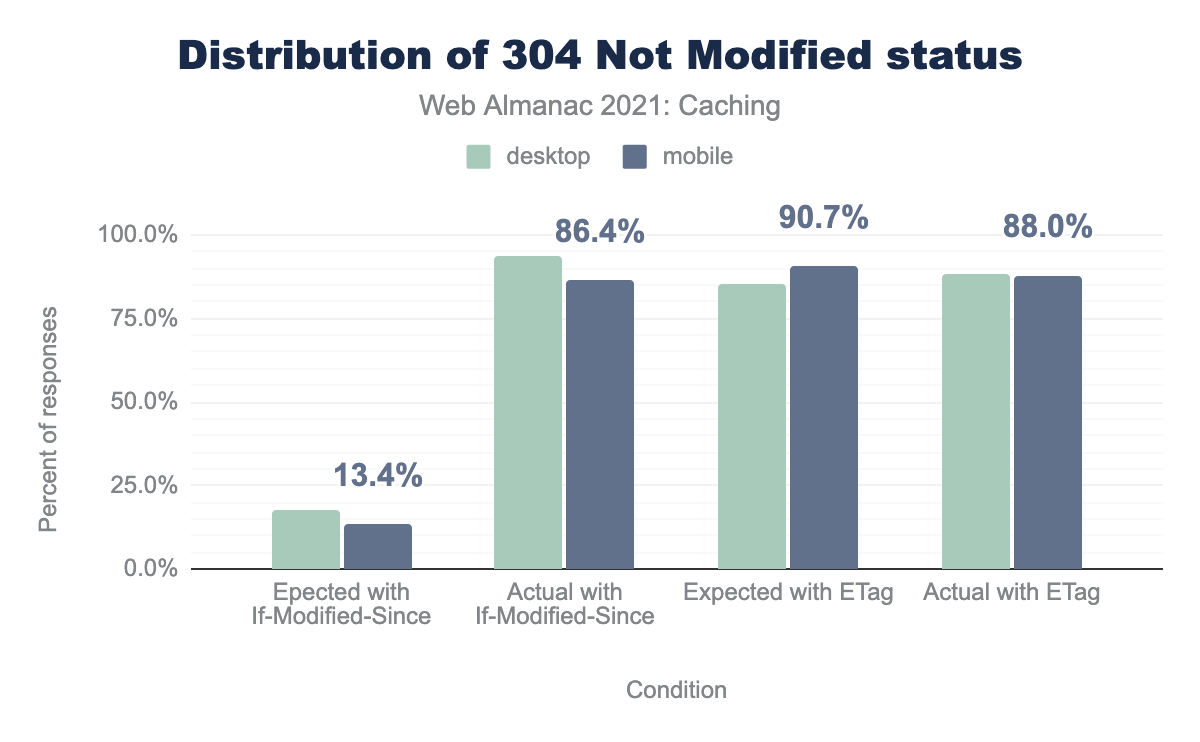
If-Modified-Since, 94% for Actual with If-Modified-Since, 84% for Expected with ETag, and 88% for Actual with ETag. Usage for mobile ranges from 13% for Expected with If-Modified-Since, 86% for Actual with If-Modified-Since, 91% for Expected with ETag, and 88% for Actual with ETag We saw the distribution of 304 responses increase by 7.7% for If-Modified-Since between 2020 and 2021. This shows that the community is capitalizing on these data savings.
Validity of date strings
The three main HTTP headers used to represent timestamps, Date, Last-Modified, and Expires all use a date formatted string. The Date HTTP response header is almost always generated automatically by the web server, meaning that invalid values are extremely rare. Still, in the event that the date is set incorrectly it can affect cacheability on the response on which it is served.
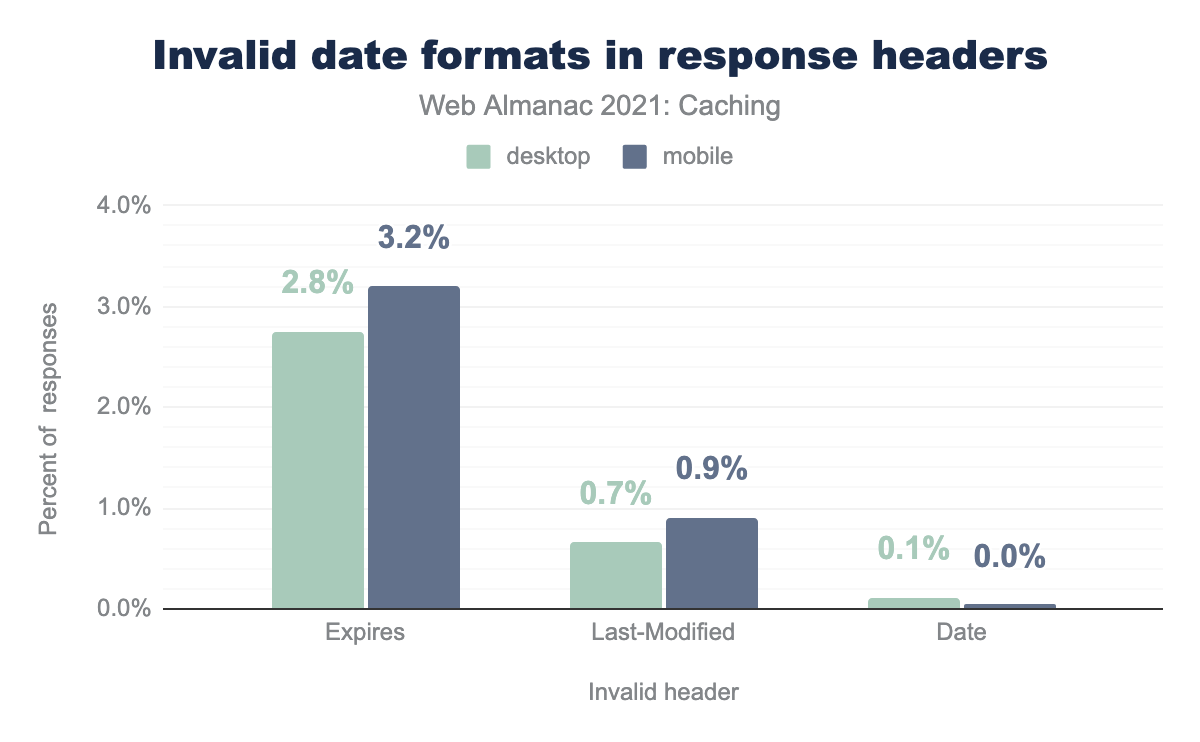
Expires, 0.7% for Last-Modified, and 0.1% for Date. The percent of responses for mobile range from 3.2% for Expires, 0.9% for Last-Modified, and 0.0% for Date.Between 2020 and 2021, the percent using invalid Date improved by 0.5% but worsened for Last-Modified and Expires showing that it was related to how the date was set on caching.
This shows us that automation of the date-based headers could benefit from further attention.
Vary
An essential step in caching a resource is understanding if it was previously cached. The browser typically uses the URL as the cache key. At the same time, requests for the same URLs but with different Accept-Encoding will result in different responses and so could be cached incorrectly. That’s why we use the Vary header to instruct the browser to add a value of one or more headers to the cache key.
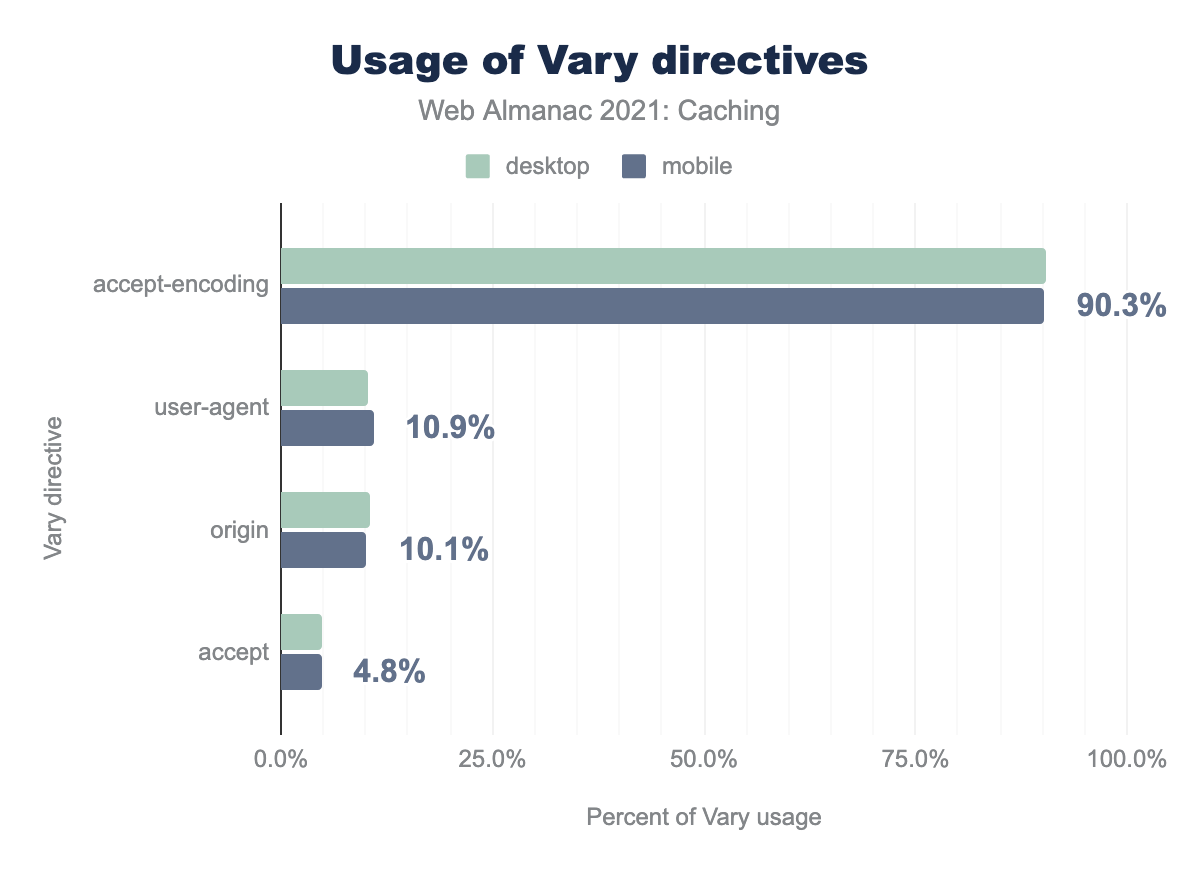
Vary header. 90.4% of desktop responses use Accept-Encoding, much smaller values for the rest with 10.2% for User-Agent, approximately 10.5% for Origin, and 5.0% for Accept. 90.3% of mobile responses use of Accept-Encoding, much smaller values for the rest with 10.9% for User-Agent, approximately 10.1% for Origin, and 4.8% for Accept.Vary directives.
The most popular Vary header is Accept-Encoding with 90.3% usage, followed by User-Agent with 10.9%, Origin with 10.1%, and Accept with 4.8%.
We saw a 1.5% decrease in use of Accept-Encoding from 2020.
Vary header.
It’s important to point out that only 46.25% of total requests audited use the Vary header, but when compared to 2020, we see an overall increase by 2.85%.
Vary header that also set Cache-Control.
Of the requests using the Vary header, 83.4% also have the Cache-control. This shows us a 2.1% improvement from 2020.
Setting cookies on cacheable responses
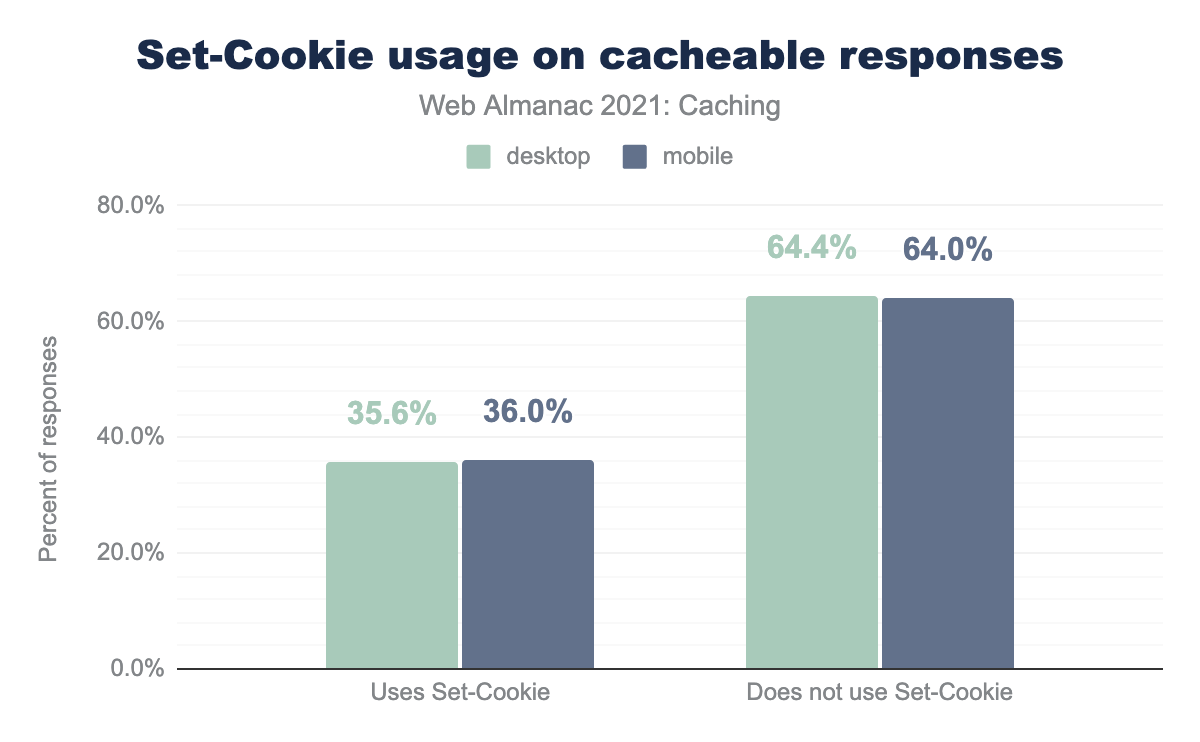
In the 2020 Caching chapter, we were reminded to be aware of using set-cookie with cacheable responses because only 4.9% of responses used the private directive, putting a user’s private data at risk of being accidentally served to a different user via a CDN.
Set-Cookie.
In 2021, we see an increase in awareness regarding set-cookie and caching coexisting. While still only 5% of web pages are using the private directive with set-cookie, the total number of cacheable set-cookie responses decreased by 4.41%.
What type of content are we caching?
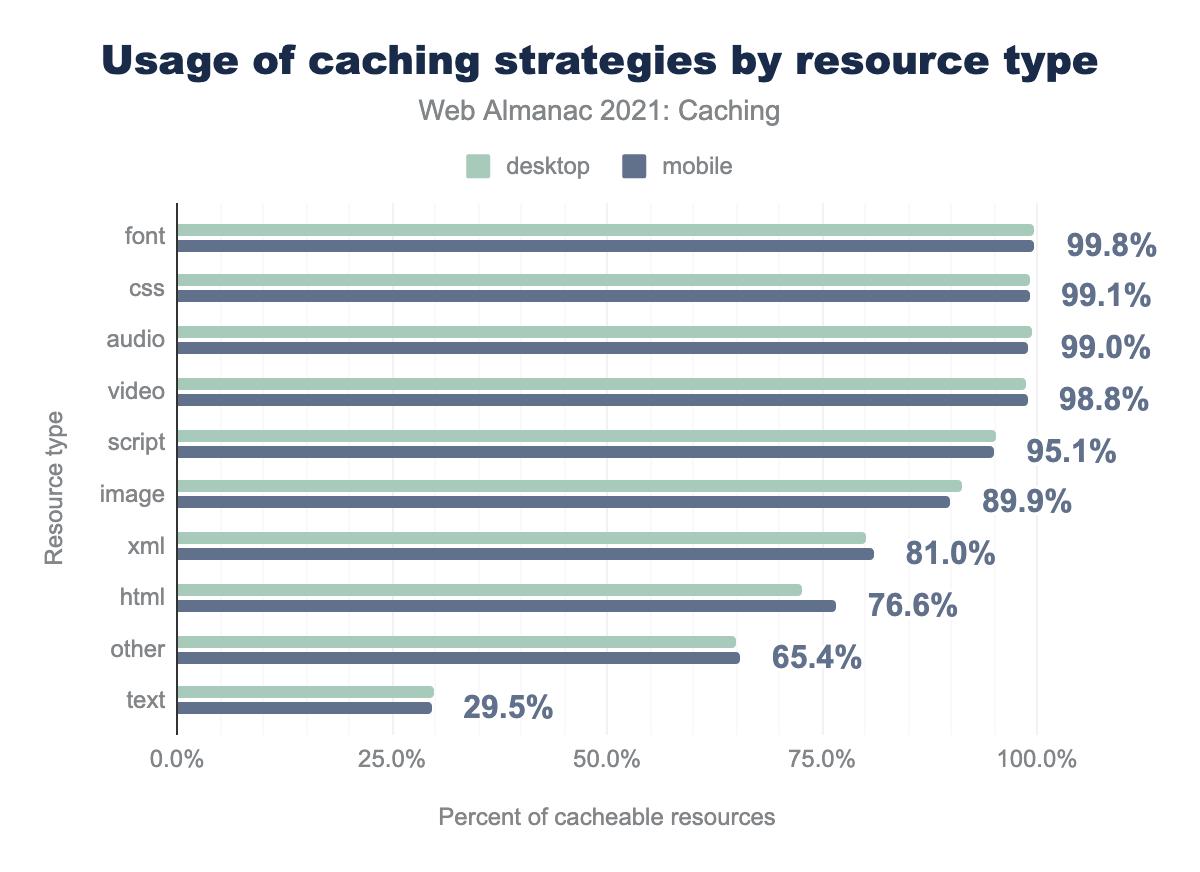
Font, CSS, and audio files are over 99% cacheable, with almost 100% of pages currently caching fonts. This is likely due to their static nature, making them prime choices for caching.
However, some of our most commonly used resources are non-cacheable, likely due to their dynamic nature. Notably, HTML saw some of the highest percentage of non-cacheable resources at 23.4%, followed closely by images with 10.1%.
When we compare the mobile data between 2020 and 2021, we notice a 5.1% increase in cacheable HTML. This tells us we may be moving towards better usage of our CDNs to cache HTML pages, like those generated by Server-Side Rendered applications. Pages are typically generated by SSR if the content of a particular web page doesn’t change frequently. The URL can potentially serve the same HTML for weeks or even months, making that content highly cacheable.
| Type | Desktop | Mobile |
|---|---|---|
| Text | 0.2 | 0.2 |
| XML | 1 | 1 |
| Other | 1 | 1 |
| Video | 4 | 8 |
| HTML | 3 | 14 |
| Audio | 0.2 | 30 |
| CSS | 30 | 30 |
| Image | 30 | 30 |
| Script | 30 | 30 |
| Font | 365 | 365 |
Taking a look at the median Time To Live (TTL) across all resource types, we see that even if we cache a similar percentage in total, there is a much longer cache for mobile, particularly for HTML, audio and video.
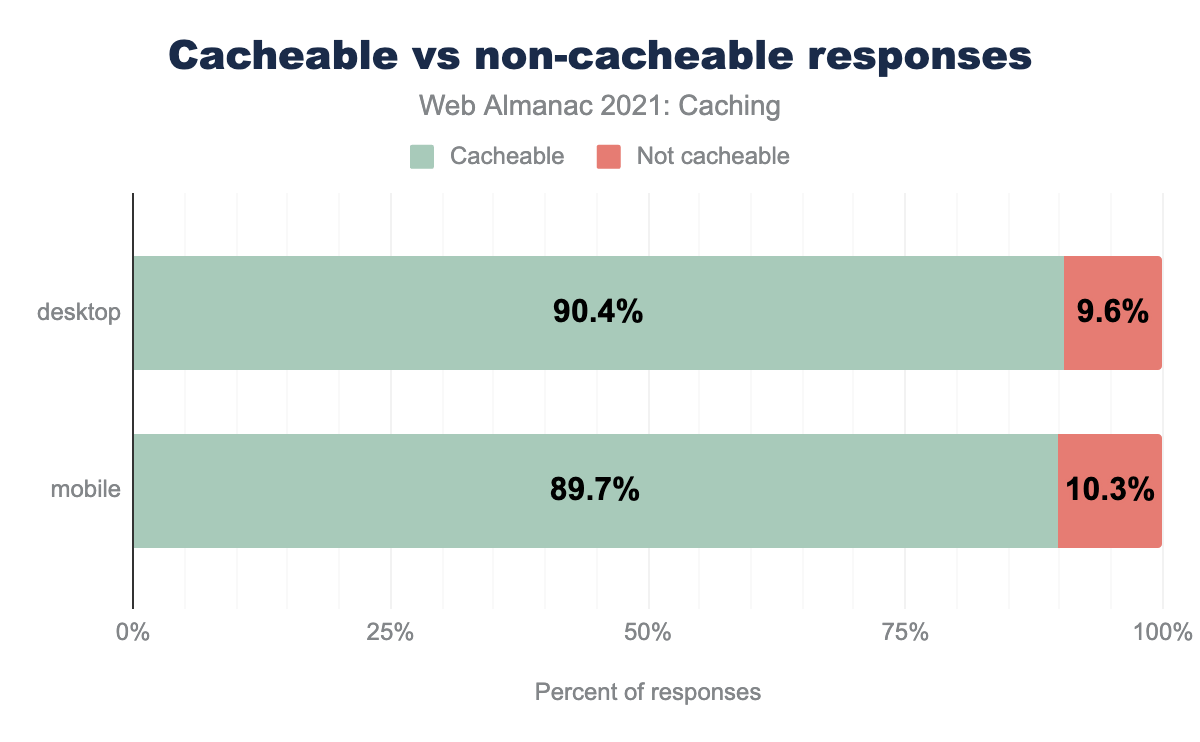
That said, even as we continue to optimize for the mobile experience, it’s interesting to note that the potential amount of cacheable desktop resources remains slightly higher than those for mobile.
How do cache TTLs compare to resource age?
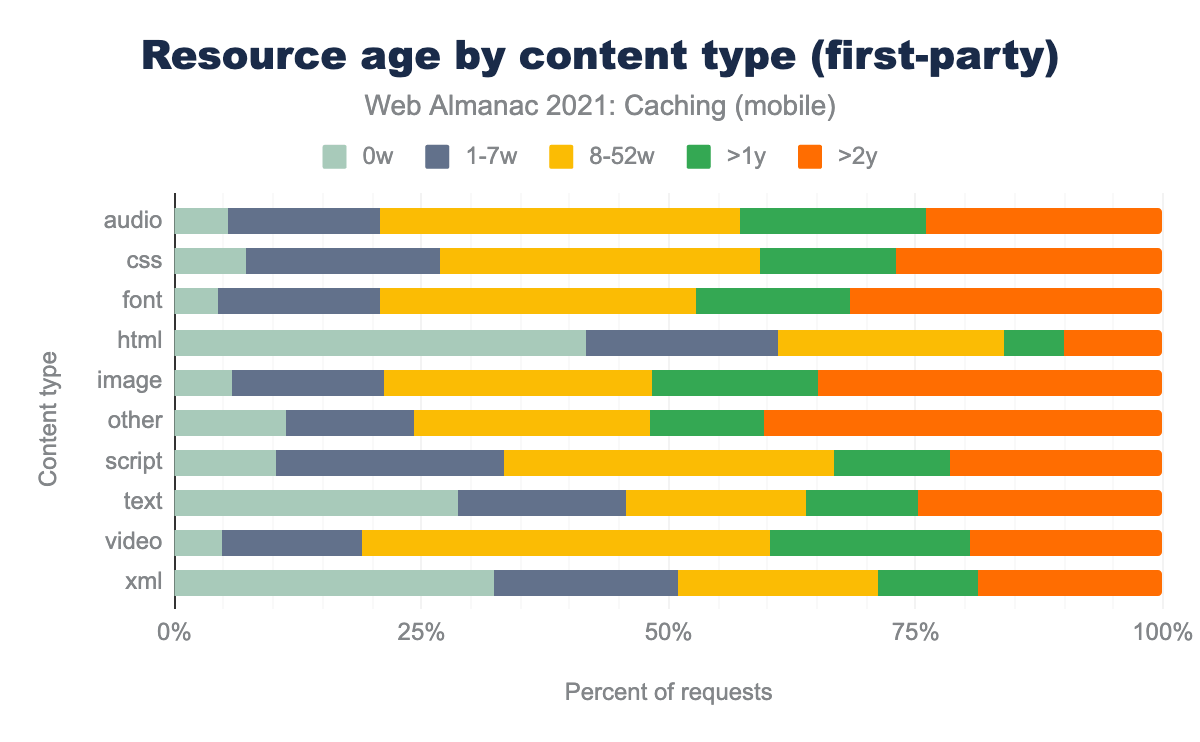
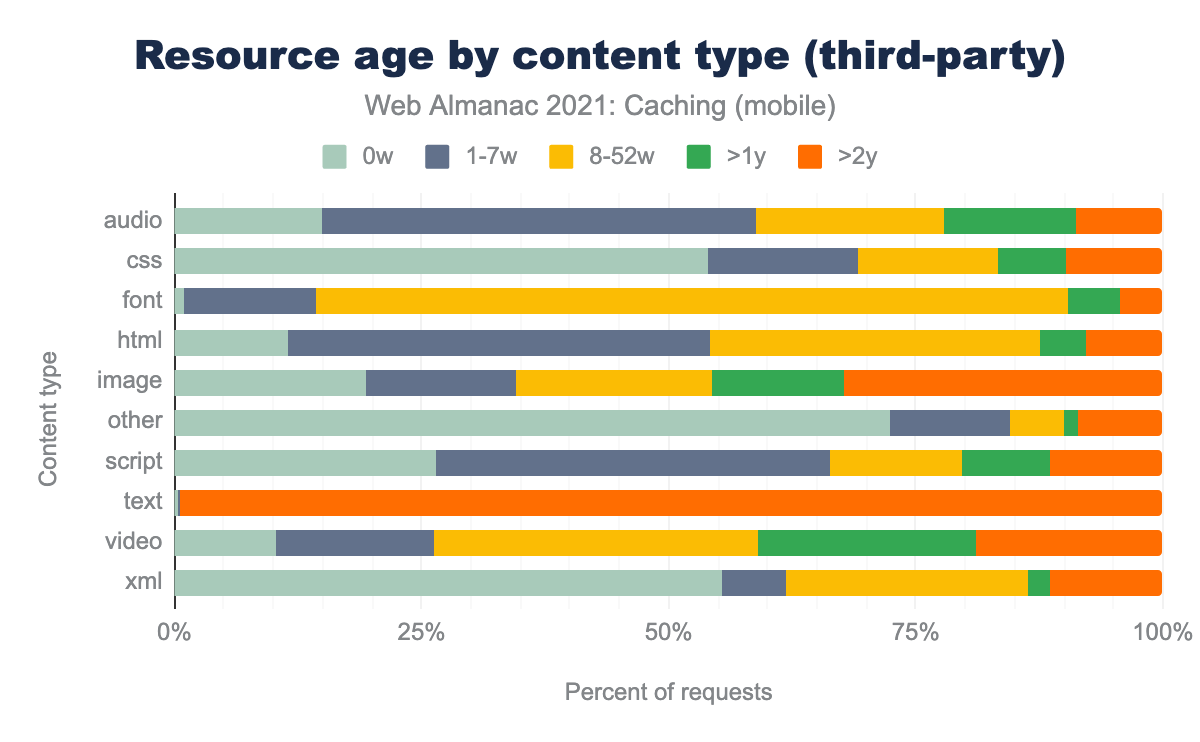
We see that images and videos maintained the same average age whether from first or third-party sources. Images consistently had a resource age of 2 years, while most video resources were between 8-52 weeks old.
Breaking down the other types of content, we discovered fonts for third-parties are cached the most between 8-52 weeks at 72.4%. However, for first-party the largest resource age groups is evenly split between 8-52 weeks and over 2 years- quite a large variance. We see similar results for audio and scripts where the majority of first-party are between 8-52 weeks old while for third-party they are between 1-7 weeks.
Audio was the most highly cached resource across both first and third parties. However, the resource age varied greatly between first-party (averaging 8-52 weeks) and third-party, at only 1-7 weeks. Audio resources in first-party situations tend to be updated less frequently (why?), so third parties may be capitalizing on a caching opportunity by offering fresher resources.
The largest group of cached first-party CSS (32.2%) tended to be 8-52 weeks old, while the largest group for 3rd parties was less than a week with 51.8% of resources cached for that duration.
Finally, HTML has the largest first-party group served with less than a week with 42.7% and third-party’s largest group is between 1-7 weeks with 43.1%.
Considerations after reviewing this data:
- The freshest content for first-party is HTML while for third-party it is CSS.
- The stalest content for both first and third-party is images.
This data shows us that first parties have prioritized refreshing HTML content, which usually holds the link to JS and CSS files, while third-party providers that are mostly CSS and script-driven, like browser extensions, have prioritized keeping their CSS up to date. When we consider the origins behind first parties vs. third parties, it follows that the way content is delivered may be more important to third parties than the actual content, thus making their presentation and optimization of it, all the more important.
Mobile resources with a cache TTL that was considered too short compared to its content age have seen an improvement since 2020. This data is exciting because it hints at the community’s growing understanding of appropriately relative caching.
While a cache TTL that is too long may serve stale content, there is no benefit for the end user if it is too short. The connection between cache TTL and content age is slowly closing this gap, moving from 60.2% in 2020 to 54.3% in 2021. The more attentive we can be towards to content age (i.e. how often we revamp a page’s HTML, CSS etc.), the more accurately we can set cache limits.
Developers are getting better at setting the cache duration more accurately to the content age, resulting in more responsible, and therefore more effective, caching.
| Client | First-party | Third-party | Overall |
|---|---|---|---|
| Desktop | 59.5% | 46.2% | 54.3% |
| Mobile | 60.1% | 44.7% | 54.3% |
When we split the data between first and third-party providers, the largest improvements come from 3rd parties where we have a 13.2% improvement. It is highly encouraging to see companies around the world building products for developers that are optimizing caching. It’s possible that the developer community’s increased attention towards improving performance has encouraged and even incentivized 3rd parties to optimize their caching strategies.
However, the challenge remains for how first parties can effectively improve over the coming years.
Identifying caching opportunities
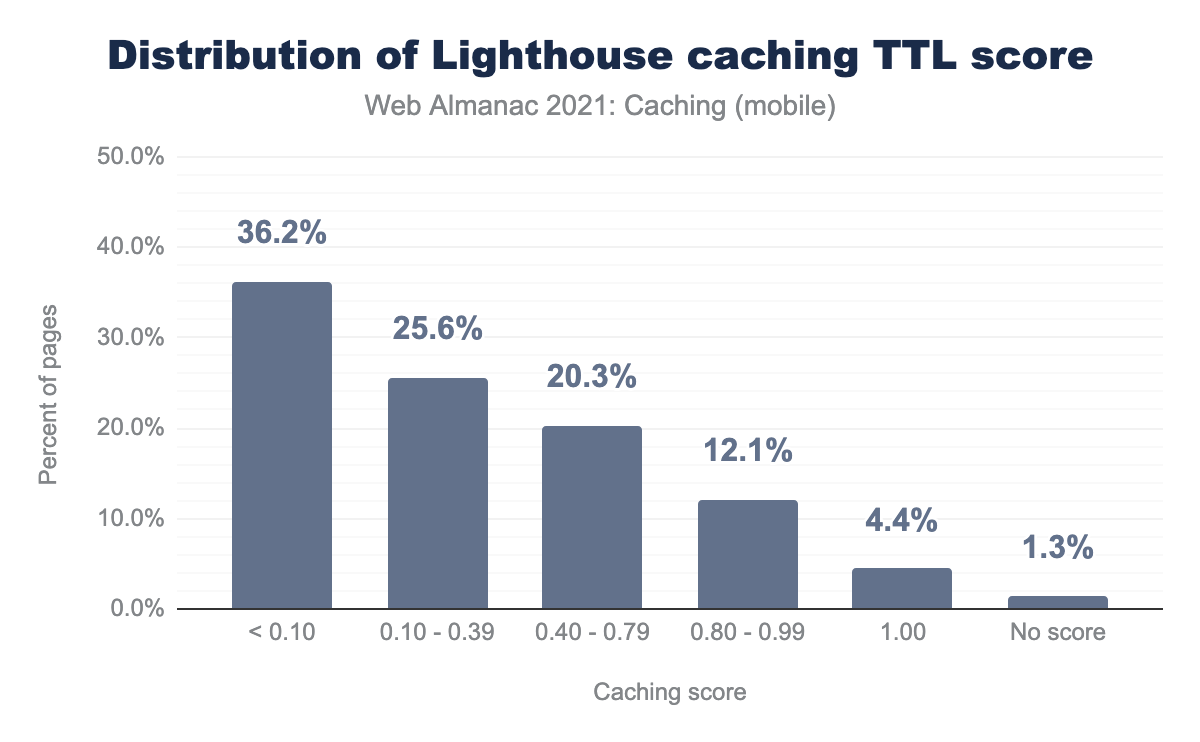
uses-long-cache-ttl for mobile web pages. 36.2% of the responses have a score less than 0.10, 25.6% have a score between 0.10-0.39, 20.3% have a score between 0.40-0.79, and 12.1% have a score between 0.80-0.99. 4.4% have a score of 1 and 1.3% have no score.Based on the Lighthouse caching TTL score, we have seen an improvement in pages ranked with a perfect score of 100 increase from 3.3% in 2020 to 4.4% in 2021.
The score reflects whether the pages can benefit from additional caching policy improvements. Even though we are excited to see 31% of pages scoring above the 50th percentile score, a large potential for improvement exists for the 52% of pages that are ranking below the 25th percentile.
This makes us consider that even though web pages have some level of caching, the way the policies are used is outdated and not optimized to the latest state of their products.
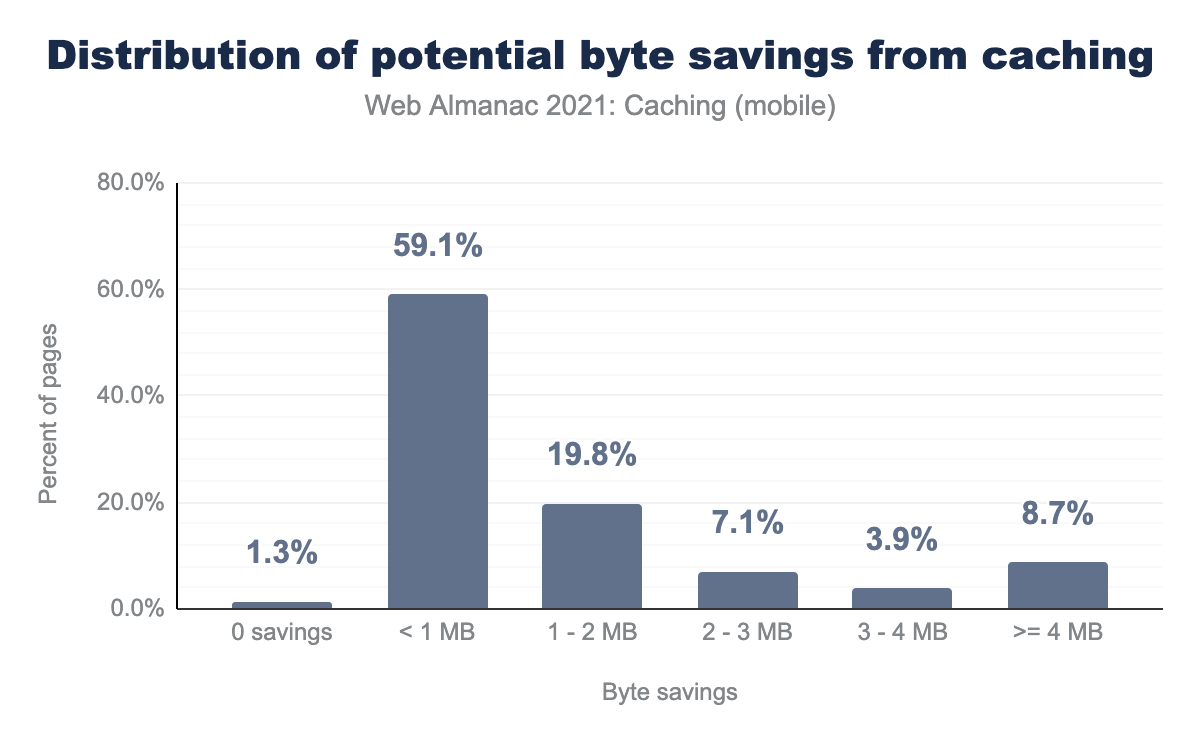
Based on Lighthouse wasted bytes audit from 2020 to 2021, there was a 3.28% improvement in wasted bytes across all audited pages on repeated views. This lowers the percentage of pages that waste 1 MB from 42.8% to 39.5%, showing a considerable trend from the community towards building products that are less costly for international users with paid internet data plans.
The current percentage of pages audited that have 0 wasted bytes is still relatively low at 1.34%. In the coming years, we’re looking forward to seeing an increase in that percentage as the community continues to focus on optimizing web performance.
Conclusion
The late, great Phil Karlton famously said, “There are only two hard things in Computer Science: cache invalidation and naming things.”, and in all honesty I have always wondered why caching is so hard. My take is that to do caching well, you need two key ingredients: to keep it simple and to understand all potential edge cases.
Unfortunately, when we try to make the cache too clever, we can end up caching the wrong things or, worse, caching too much. On a similar note, understanding all the edge cases requires extensive research, testing, and slow incremental improvements. Even with that, you have to hope that an old browser will not throw you under the bus. But the reason we still chase great caching strategies is that the ultimate reward is very high, with a significant reduction in round-trip requests, high savings for your server, less data required from your users, and ultimately a better user experience.
No matter the case, make sure to have a playbook for how to best use caching:
- Prioritize caching work at an early stage of the development cycle, and after a product is shipped
- Write end-to-end tests to recreate major edge cases
- Regularly audit the site and update cache rules that might be outdated or missing
Ultimately, caching can be made less complex if we spread the knowledge by mentoring our peers and writing good documentation that is simple to understand. Caching is not something that should only be mastered by a few. Our goal is to move towards it being common knowledge across an entire company. Because at the end of the day, what we really want to focus on is building easy and frictionless experiences for our users.

