Privacy
Introduction
“On the Internet, nobody knows you’re a dog.” While it might be true that you could try to remain anonymous to use the Internet as such, it can be quite hard to keep your personal data fully private.
A whole industry is dedicated to tracking users online, to build detailed user profiles for purposes such as targeted advertising, fraud detection, price differentiation, or even credit scoring. Sharing geolocation data with websites can prove very useful in day-to-day life, but may also allow companies to see your every movement. Even if a service treats a user’s private information diligently, the mere act of storing personal data provides hackers with an opportunity to breach services and leak millions of personal records online.
Recent legislative efforts such as the GDPR in Europe, CCPA in California, LGPD in Brazil, or the PDP Bill in India all strive to require companies to protect personal data and implement privacy by default, including online. Major technology companies such as Google, Facebook and Amazon have already received massive fines for alleged violations of user privacy.
These new laws have given users a much larger say in how comfortable they are with sharing personal data. You probably already have clicked through quite a few cookie consent banners that enable this choice. Furthermore, web browsers are implementing technological solutions to improve user privacy, from blocking third-party cookies over hiding sensitive data to innovative ways to balance legitimate use cases on personal attributes with individual user privacy.
In this chapter, we give an overview of the current state of privacy on the web. We first consider how user privacy can be harmed: we discuss how websites profile you through online tracking, and how they access your sensitive data. Next, we dive into ways websites protect sensitive data and give you a choice through privacy preference signals. We close with an outlook on the efforts that browsers are making to safeguard your privacy in the future.
How websites profile you: online tracking
The HTTP protocol is inherently stateless, so by default there is no way for a website to know whether two visits to two different websites, or even two visits to the same website, are from the same user. However, such information could be useful for websites to build more personalized user experiences, and for third parties building profiles of user behavior across websites to fund content on the web through targeted advertising or providing services such as fraud detection.
Unfortunately, obtaining this information currently often relies on online tracking, around which many large and small companies have built their business. This has even led to calls to ban targeted advertising, since invasive tracking is at odds with users’ privacy. Users might not want anyone to follow their tracks across the web—especially when visiting websites on sensitive topics. We’ll look at the main companies and technologies that make up the online tracking ecosystem.
Third-party tracking
Online tracking is often done through third-party libraries. These libraries usually provide some (useful) service, but in the process some of them also generate a unique identifier for each user, which can then be used to follow and profile users across websites. The WhoTracksMe project is dedicated to discovering the most widely deployed online trackers. We use WhoTracksMe’s classification of trackers but restrict ourselves to four categories, because they are the most likely to cover services where tracking is part of the primary purpose: advertising, pornvertising, site analytics and social media.
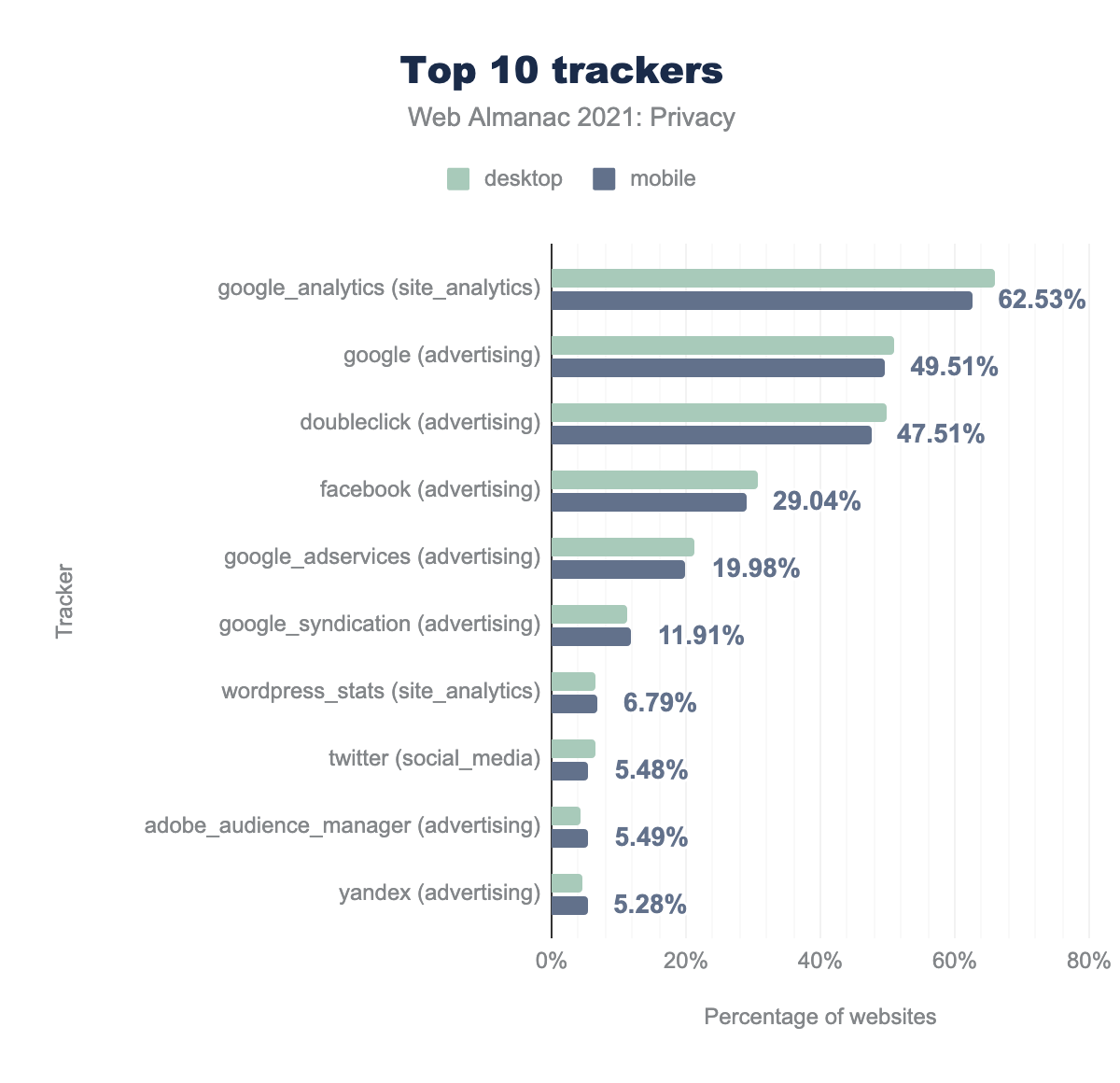
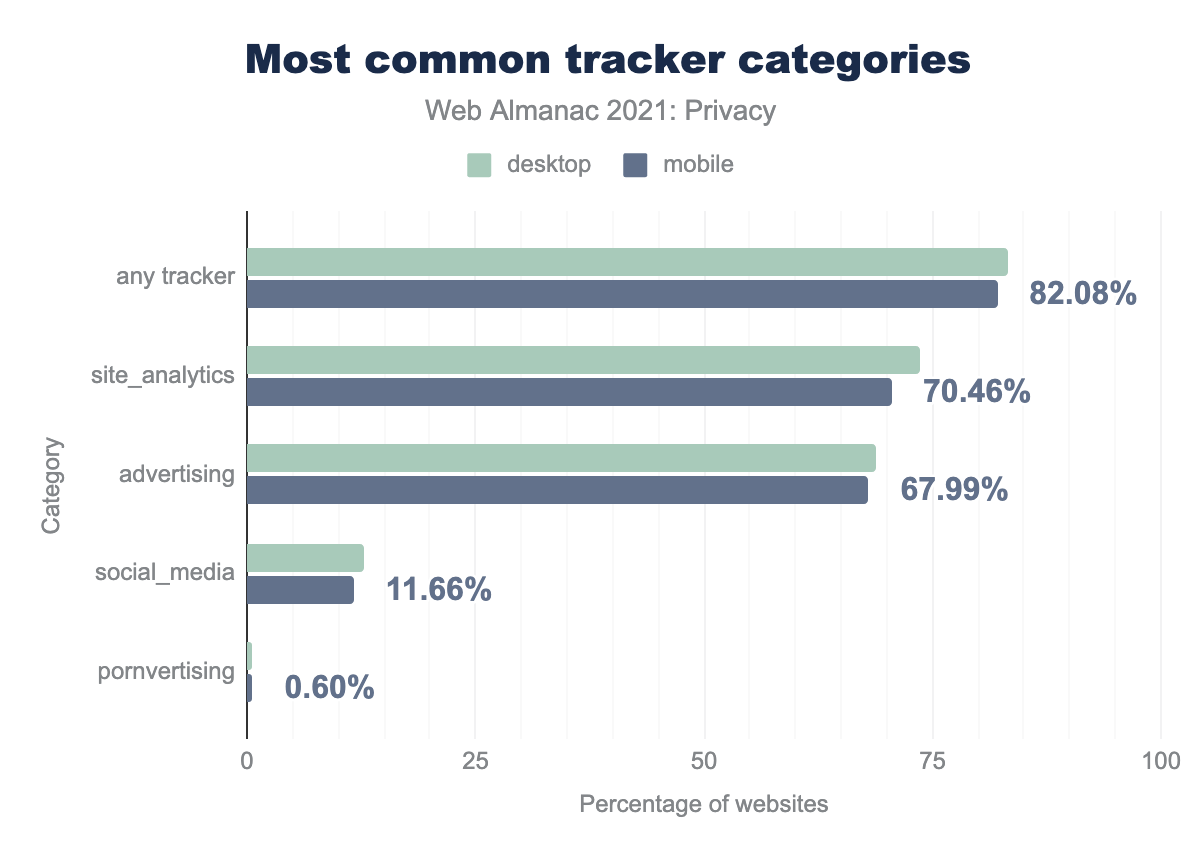
We see that Google-owned domains are prevalent in the online tracking market. Google Analytics, which reports website traffic, is present on almost two-thirds of all websites. Around 30% of sites include Facebook libraries, while other trackers only reach single-digit percentages.
site_analytics is used on 73.53% and 70.46% respectively, advertising on 68.83% and 67.99%, social_media on 12.89% and 11.66%, and finally pornvertising on 0.56% and 0.60%.Overall, 82.08% of mobile sites and 83.33% of desktop sites include at least one tracker, usually for site analytics or advertising purposes.
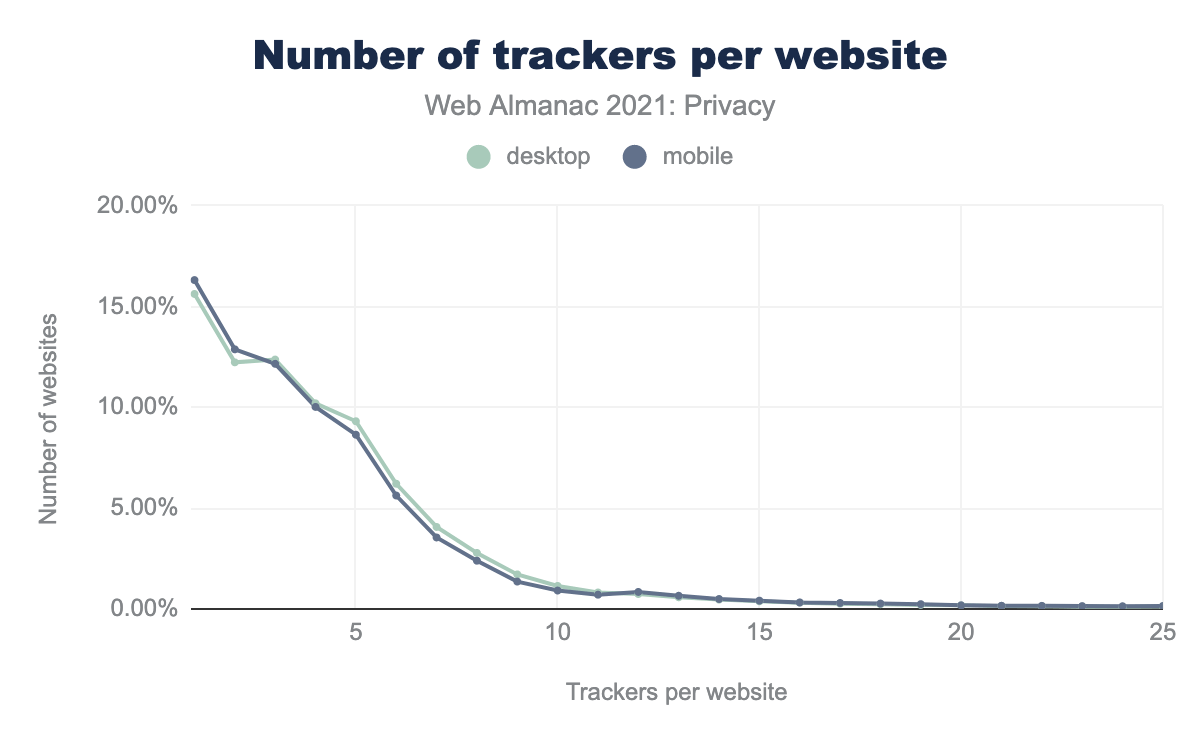
Three out of four websites have fewer than 10 trackers, but there is a long tail of sites with many more trackers: one desktop site contacted 133 (!) distinct trackers.
Third-party cookies
The main technical approach to store and retrieve cross-site user identifiers is through cookies that are persistently stored in your browser. Note that while third-party cookies are often used for cross-site tracking, they can also be used for non-tracking use cases, like state sharing for a third-party widget across sites. We searched for the cookies that appear most often while browsing the web, and the domains that set them.
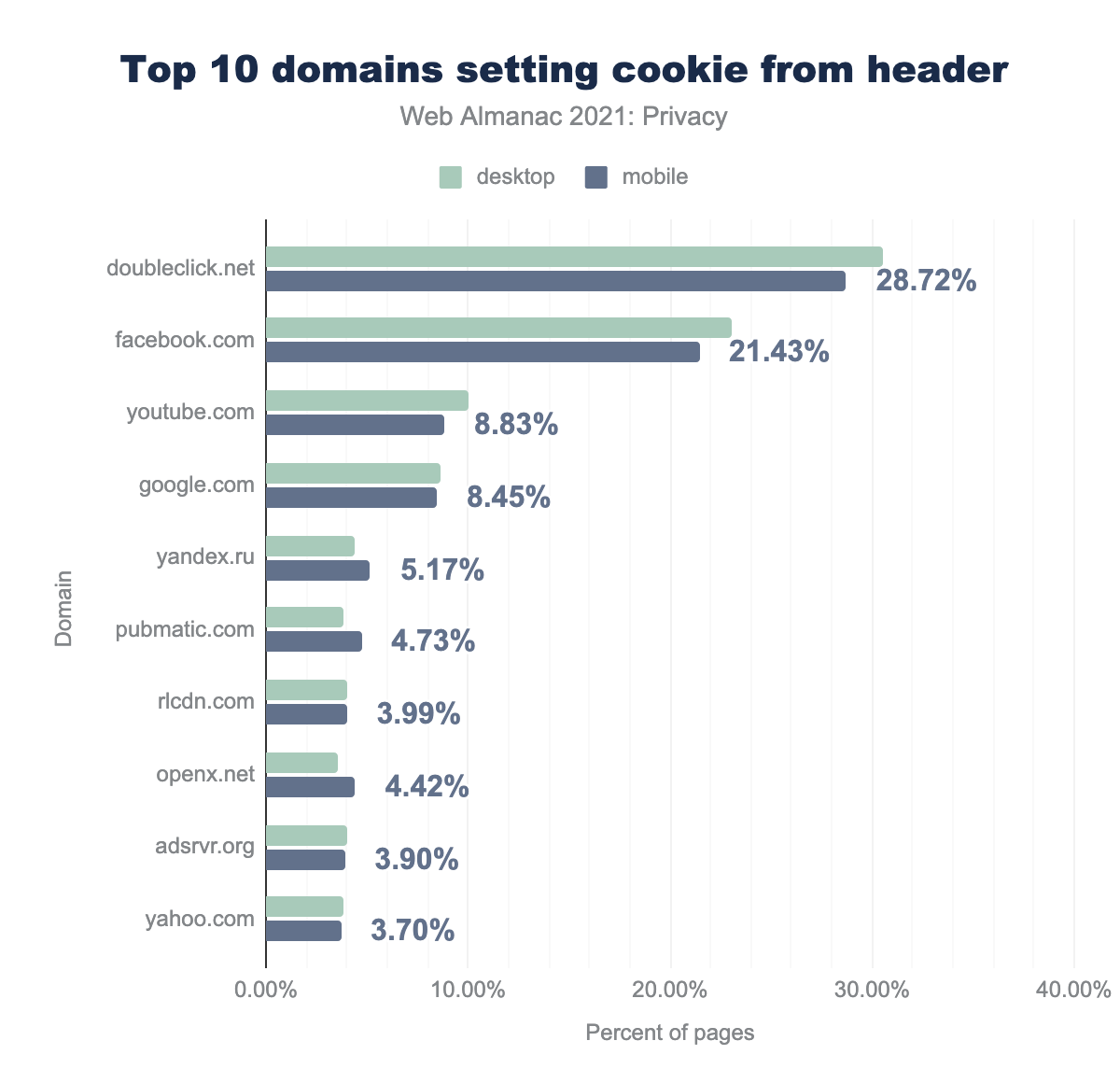
doubleclick.net is used on 30.49% of desktop pages and 28.72% of mobile pages, facebook.com on 23.07 and 21.43% respectively, youtube.com on 10.02% and 8.83%, google.com on 8.62% and 8.45%, yandex.ru on 4.42% and 5.17%, pubmatic.com on 3.82% and 4.73%, rlcdn.com on 4.01% and 3.99%, openx.net on 3.57% and 4.42%, adsrvr.org on 4.00% and 3.90%, and finally yahoo.com on 3.80% and 3.70%.Google’s subsidiary DoubleClick takes the top spot by setting cookies on 31.4% of desktop websites and 28.7% on mobile websites. Another major player is Facebook, which stores cookies on 21.4% of mobile websites. Most of the other top domains setting cookies are related to online advertising.
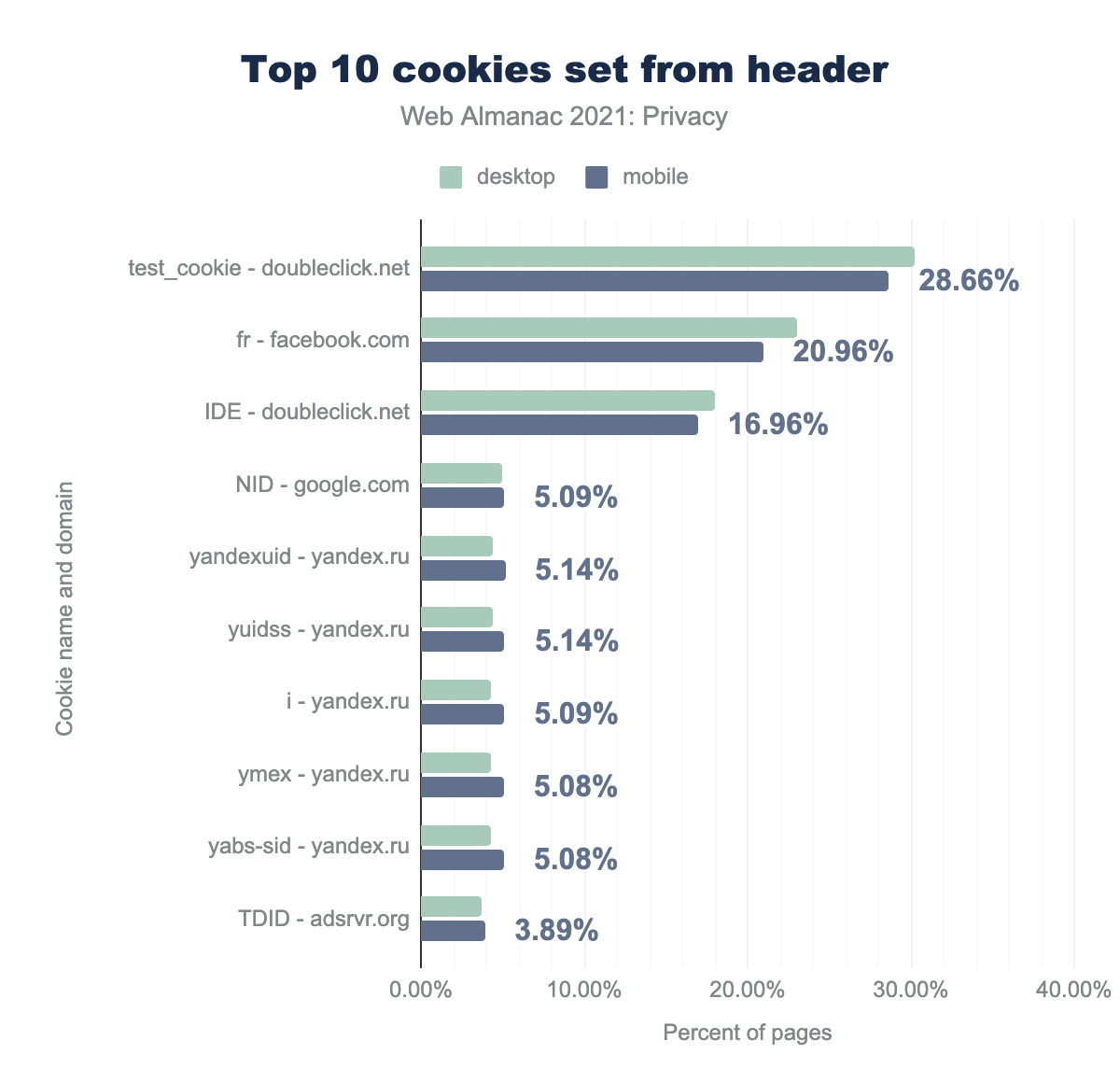
test_cookie for doubleclick.net is used by 30.20% of desktop sites and 28.66% of mobile sites, fr for facebook.com by 23.04% and 20.96% respectively, IDE for doubleclick.net by 18.03% and 16.96%, NID for google.com by 4.92% and 5.09%, yandexuid for yandex.ru by 4.38% and 5.14%, yuidss for yandex.ru by 4.38% and 5.14%, i for yandex.ru by 4.34% and 5.09%, ymex for yandex.ru by 4.32% and 5.08%, yabs-sid for yandex.ru by 4.32% and 5.08%, TDID for adsrvr.org by 3.71% and 3.89%.Looking at the specific cookies that these websites set, the most common cookie from a tracker is the test_cookie from doubleclick.net. The next most common cookies are advertising-related and remain on a user’s device much longer: Facebook’s fr cookie persists for 90 days, while DoubleClick’s IDE cookie stays for 13 months in Europe and 2 years elsewhere.
With Lax becoming the default value of the SameSite cookie attribute, sites that want to continue sharing third-party cookies across websites must explicitly set this attribute to None. For third parties, 85% have done this so far on mobile and 64% on desktop, potentially for tracking purposes. You can read more about the SameSite cookie attribute over at the Security chapter.
Fingerprinting
With the rise of privacy-protecting tools such as ad blockers and initiatives to phase out third-party cookies from major browsers such as Firefox, Safari, and by 2023 also Chrome, trackers are looking for more persistent and stealthy ways to track users across sites.
One such technique is browser fingerprinting. A website collects information about the user’s device, such as the user agent, screen resolution and installed fonts, and uses the often unique combination of those values to create a fingerprint. This fingerprint is recreated every time a user visits the website and can then be matched to identify the user. While this method can be used for fraud detection, it is also used to persistently track recurring users, or to track users across sites.
Detecting fingerprinting is complex: it is effective through a combination of method calls and event listeners that may also be used for non-tracking purposes. Instead of focusing on these individual methods, we therefore focus on five popular libraries that make it easy for a website to implement fingerprinting.
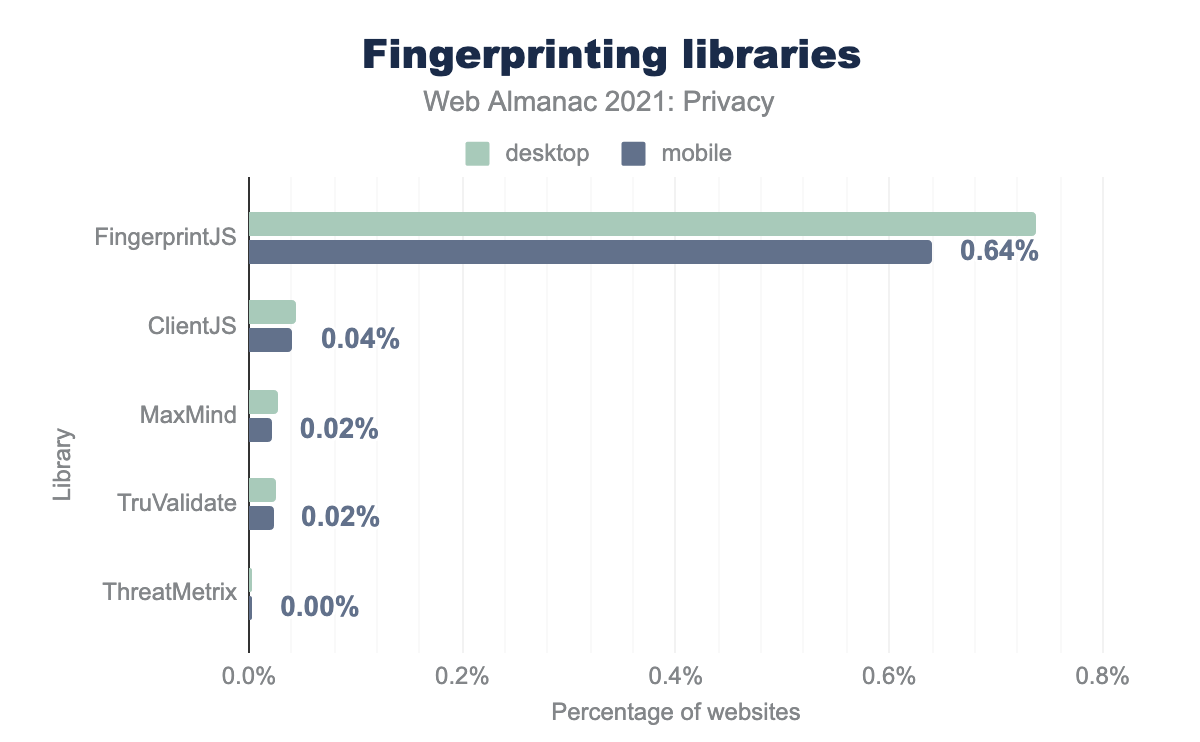
From the percentage of websites using these third-party services, we can see that the most widely used library, Fingerprint.js, is used 19 times more on desktop than the second most popular library. However, the overall percentage of websites that use an external library to fingerprint their users is quite small.
CNAME tracking
Continuing with techniques that circumvent blocks on third-party tracking, CNAME tracking is a novel approach where a first-party subdomain masks the use of a third-party service using a CNAME record at the DNS level. From the viewpoint of the browser, everything happens within a first-party context, so none of the third-party countermeasures are applied. Major tracking companies such as Adobe and Oracle are already offering CNAME tracking solutions to their customers. For the results on CNAME-based tracking included in this chapter, we refer to research completed by one of this chapter’s authors (and others) where they developed a method to detect CNAME-based tracking, based on DNS data and request data from HTTP Archive.
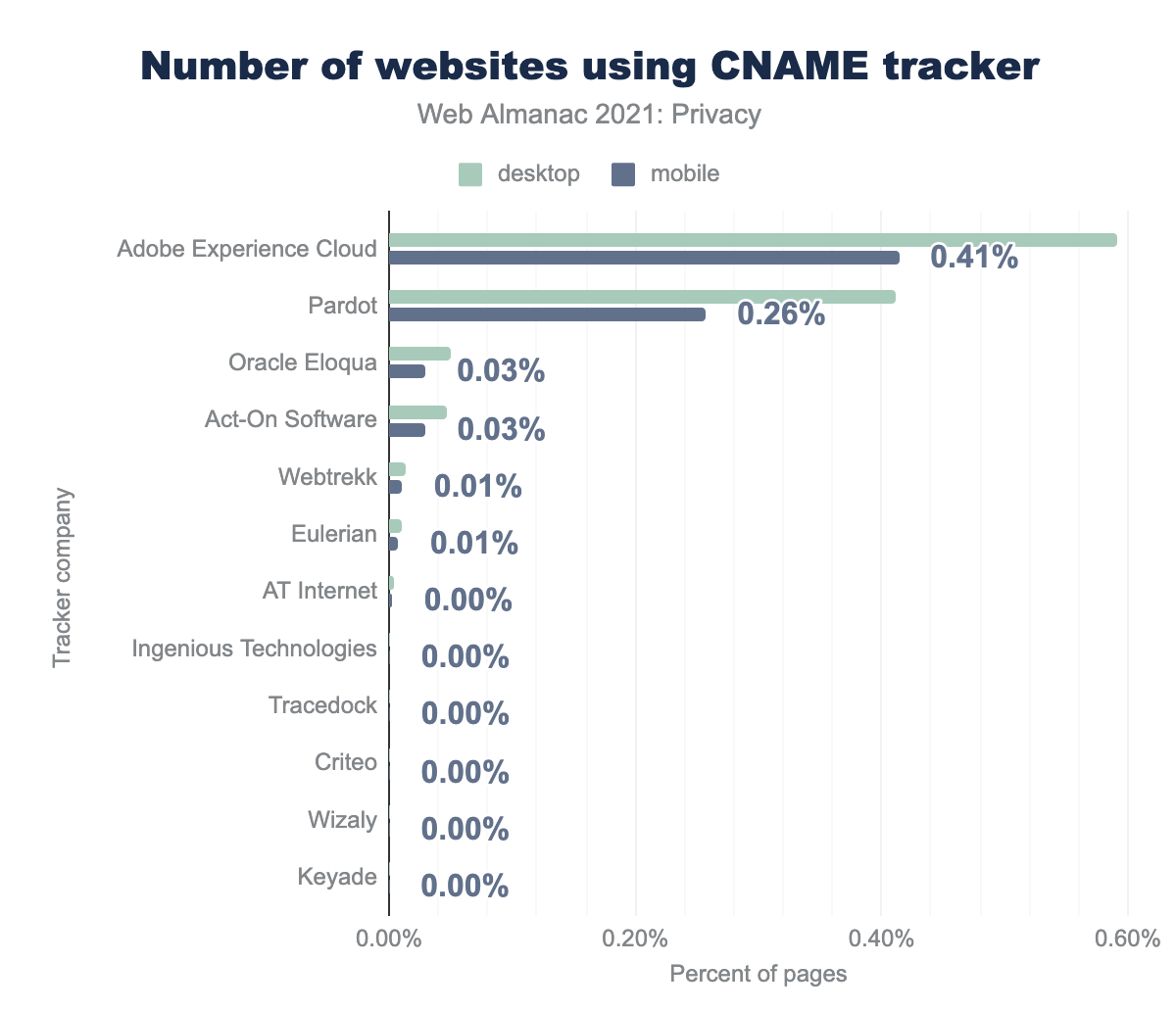
The most popular company performing CNAME-based tracking is Adobe, which is present on 0.59% of desktop websites, and 0.41% of mobile websites. Also notable in size is Pardot, with 0.41% and 0.26% respectively.
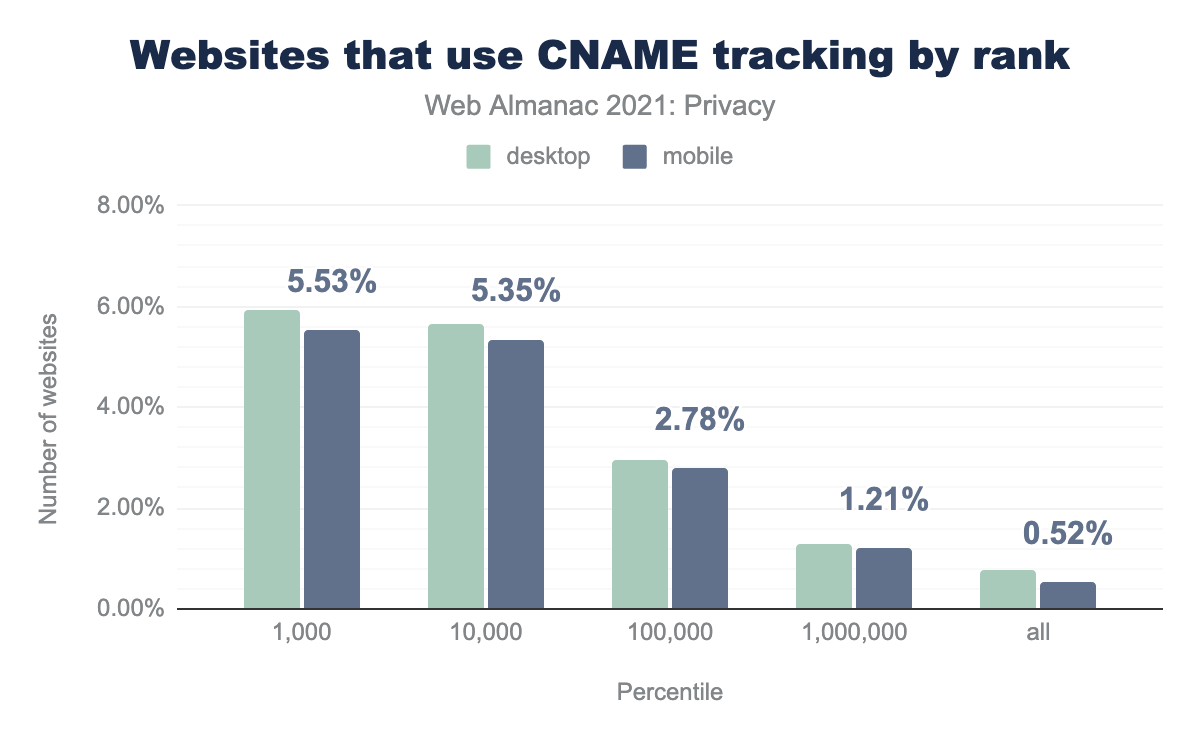
Those numbers may seem a small percentage, but that opinion changes when segregating the data by site popularity.
When we look at the rank of the websites that use CNAME-based tracking, we see that 5.53% of the top 1,000 websites on mobile embed a CNAME tracker. In the top 100,000, that number falls to 2.78% of websites, and when looking at the full data set it falls to 0.52%.
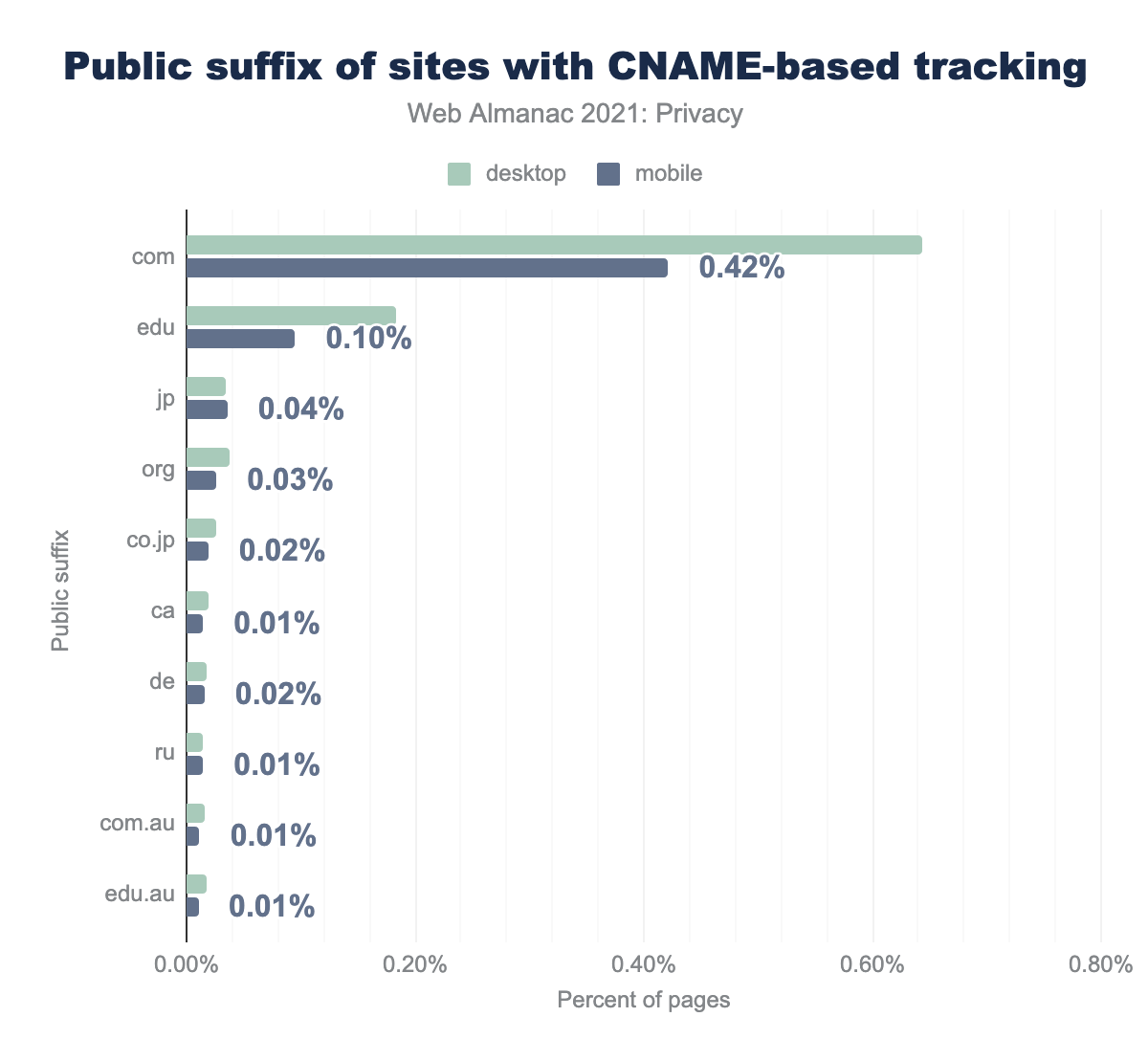
com suffix use CNAME tracking, for edu it’s 0.18% and 0.10% respectively, for jp it’s 0.03% and 0.04%, for org 0.04% and 0.03%, for co.jp 0.03% and 0.02%, for ca 0.02% and 0.01%, for de 0.02% and 0.02%, for ru 0.01% and 0.01%, for com.au 0.02% and 0.01%, and finally for edu.au 0.02% and 0.01%.Apart from the .com suffix, a large number of the websites using CNAME-based tracking have a .edu domain. Also, a notable amount of CNAME trackers are prevalent on .jp and .org websites.
CNAME-based tracking can be a countermeasure to when the user might have enabled tracking protection against third-party tracking. Since few tracker-blocking tools and browsers have already implemented a defense against CNAME tracking, it is prevalent on a number of websites up to date.
(Re)targeting
Advertisement retargeting refers to the practice of keeping track of the products that a user has looked at but has not purchased and following up with ads about these products on different websites. Instead of opting for an aggressive marketing strategy while the user is visiting, the website chooses to nudge the user into buying the product by continuously reminding them of the brand and product.
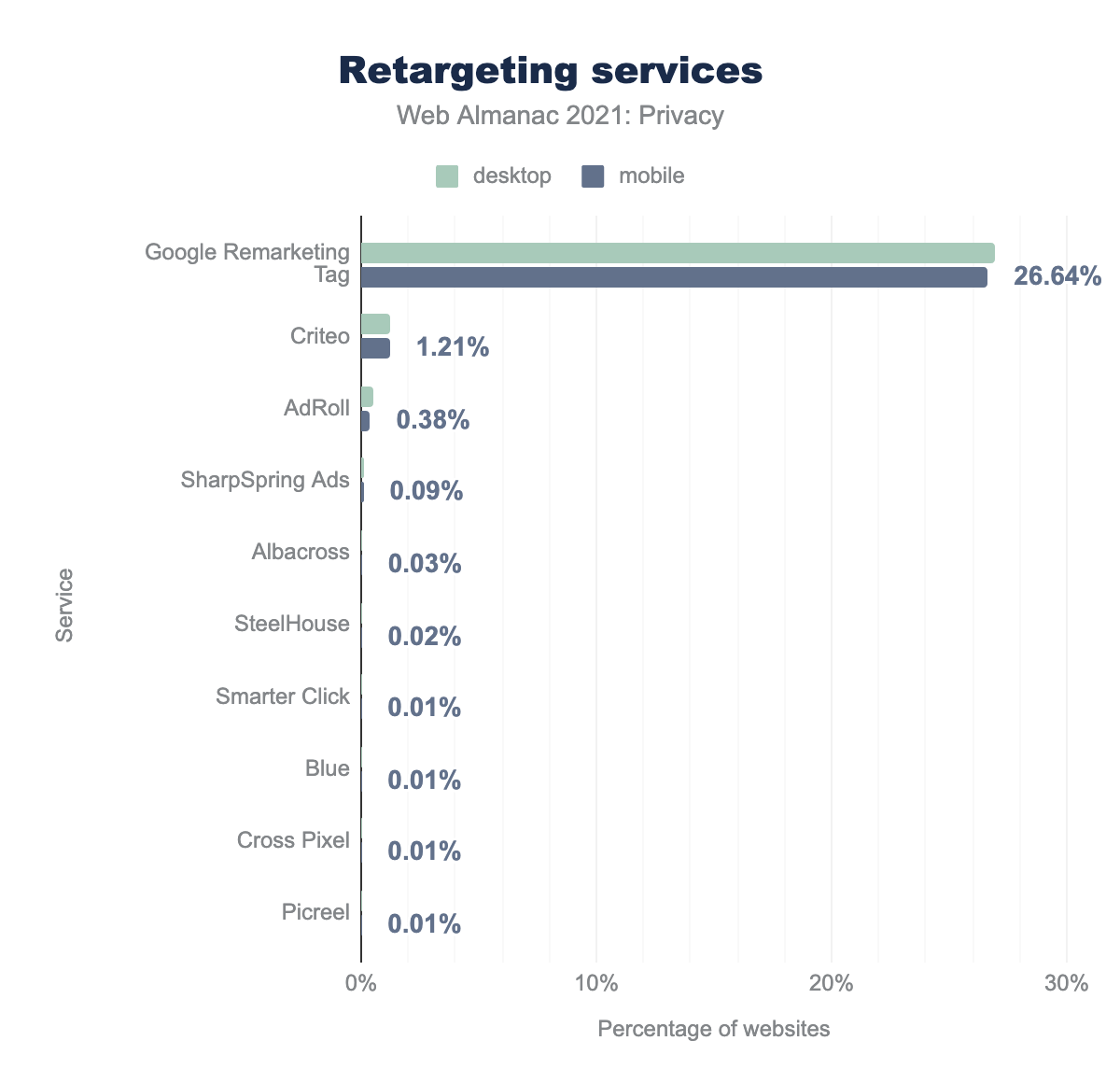
A number of trackers provide a solution for ad retargeting. The most widely used one, Google Remarketing Tag, is present on 26.92% of websites on desktop and 26.64% of websites on mobile, far and above all other services which are used by less than 1.25% of sites each.
How websites handle your sensitive data
Some websites request access to specific features and browser APIs that can impact the user’s privacy, for instance by accessing the geolocation data, microphone, camera, etc. These features usually serve very useful purposes, such as discovering nearby points of interest or allowing people to communicate with each other. While these features are only activated when a user consents, there is a risk of exposing sensitive data if the user does not fully understand how those resources are used, or if a site misbehaves.
We looked at how often websites request access to sensitive resources. Moreover, any time a service stores sensitive data, there is the danger of hackers stealing and leaking that data. We’ll look at recent data breaches that prove that this danger is real.
Device sensors
Sensors can be useful to make a website more interactive but could also be abused for fingerprinting users. Based on the use of JavaScript event listeners, the orientation of the device is accessed the most, both on mobile and on desktop clients. Note that we searched for the presence of event listeners on websites, but we do not know if the code is actually executed. Therefore, the access to device sensor events in this section is an upper bound.
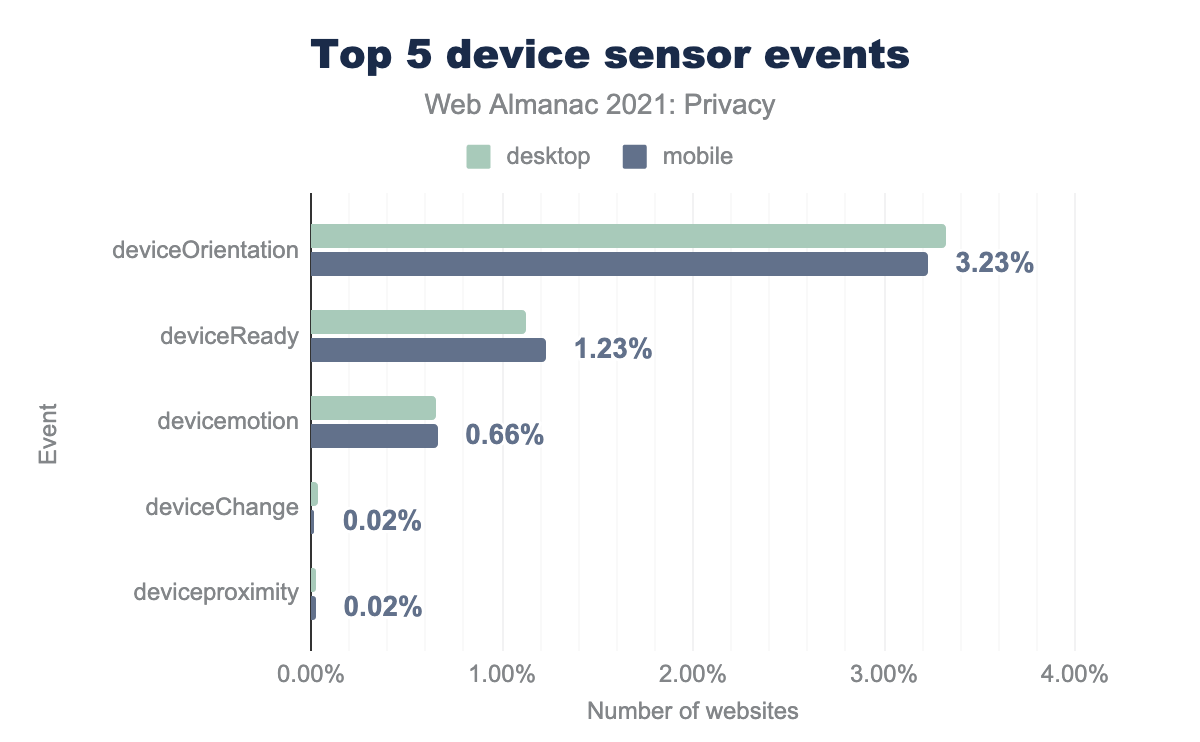
deviceOrientation is found on 3.32% of desktop sites and 3.23% of mobile sites, deviceReady on 1.12% and 1.23%, devicemotion on 0.65% and 0.66%, deviceChange on 0.03% and 0.02%, and finally deviceproximity on 0.03% and 0.02%.Media devices
The MediaDevices API can be used to access connected media input such as cameras, microphones and screen sharing.
EnumerateDevices API.
On 7.23% of desktop websites, and 5.33% of mobile websites the enumerateDevices() method is called, which provides a list of the connected input devices.
Geolocation-as-a-service
Geolocation services provide GPS and other location data (such as IP address) of the user and can be used by trackers to provide more relevant content to the user among other things. Therefore, we analyze the use of “geolocation-as-a-service” technologies on websites, based on libraries detected through Wappalyzer.
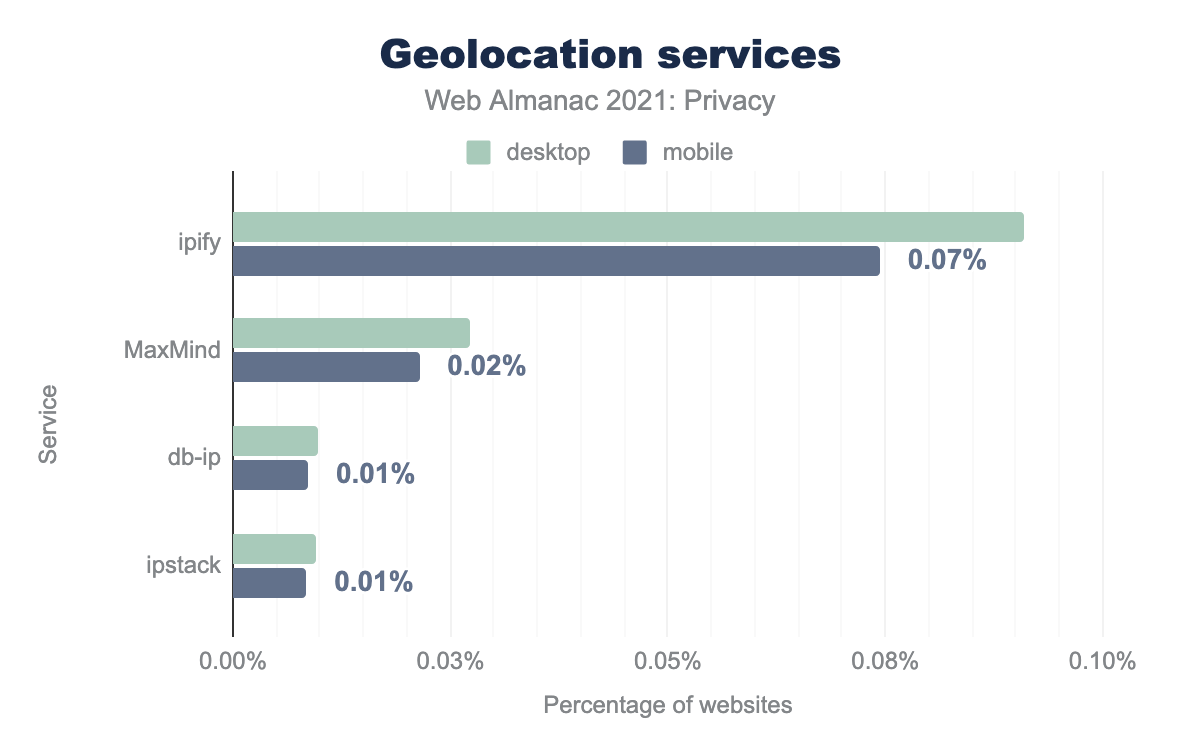
We find that the most popular service, ipify, is used on 0.09% of desktop websites and 0.07% of mobile websites. So, it would appear that few websites use geolocation services.
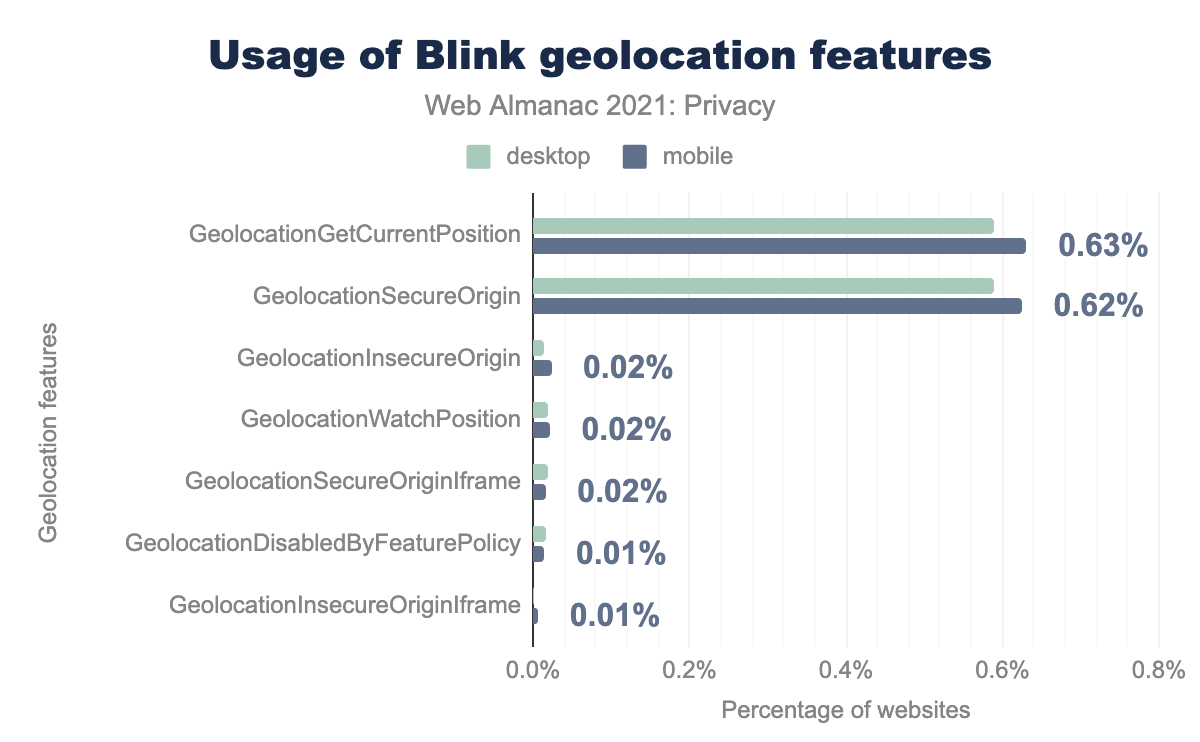
GeolocationGetCurrentPosition is used by 0.59% of desktop sites and 0.63% of mobile sites, GeolocationSecureOrigin by 0.59% and 0.62% respectively, GeolocationInsecureOrigin by 0.01% and 0.02%, GeolocationWatchPosition by 0.02% and 0.02%, GeolocationSecureOriginIframe by 0.02% and 0.02%, GeolocationDisabledByFeaturePolicy by 0.02% and 0.01%, and finally GeolocationInsecureOriginIframe by 0.00% and 0.01%.Geolocation data can also be accessed by websites through a web browser API. We find that 0.59% of websites on a desktop client and 0.63% of websites on a mobile client access the current position of the user (based on Blink features).
Data breaches
Poor security management within a company can have a significant impact on its customers’ private data. Have I Been Pwned allows users to check whether their email address or phone number was leaked in a data breach. At the time of this writing, Have I Been Pwned has tracked 562 breaches, leaking 640 million records. In 2020 alone, 40 services were breached and personal data about millions of users leaked. Three of these breaches were marked as sensitive, referring to the possibility of a negative impact on the user if someone were to find that user’s data in the breach. One example of a sensitive breach is “Carding Mafia”, a platform where stolen credit cards are traded.
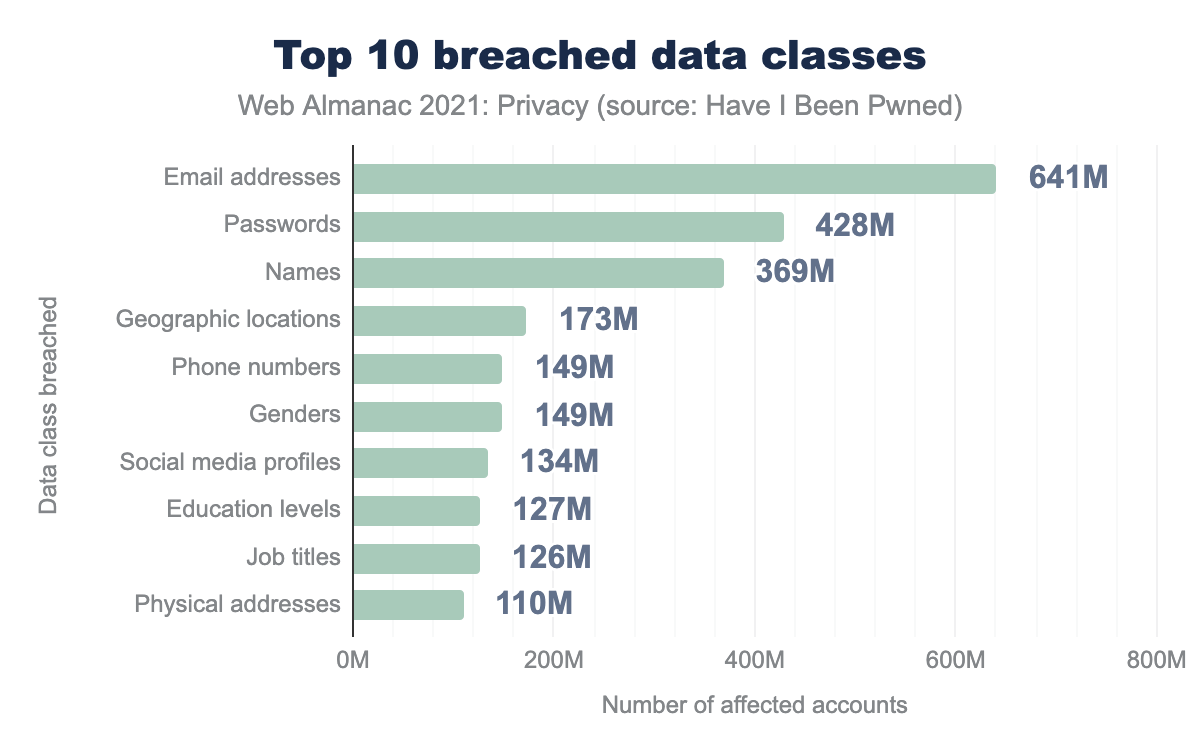
Every data breach tracked by Have I Been Pwned leaks email addresses, since this is how users query whether their data was breached. Leaked email addresses are already a huge privacy risk, since many users employ their full name or credentials to set up their email address. Furthermore, a lot of other highly sensitive information is leaked in some breaches, such as users’ genders, bank account numbers and even full physical addresses.
How websites protect your sensitive data
While you’re browsing the web, there is certain data that you might want to keep private: the web pages that you visit, any sensitive data that you enter into forms, your location, and so on. Over at the Security chapter, you can learn how 91.1% of mobile sites have enabled HTTPS to protect your data from snooping while it traverses the Internet. Here, we’ll focus on how websites can further instruct browsers to ensure privacy for sensitive resources.
Permissions Policy / Feature Policy
The Permissions Policy (previously called Feature Policy) provides a way for websites to define which web features they intend to use, and which features will need to be explicitly approved by the user—when requested by third parties for instance. This gives websites control over what features embedded third-party scripts can request to access. For example, a permissions policy can be used by a website to ensure that no third-party requests microphone access on their site. The policy allows developers to granularly choose web APIs they intend to use, by specifying them with the allow attribute.
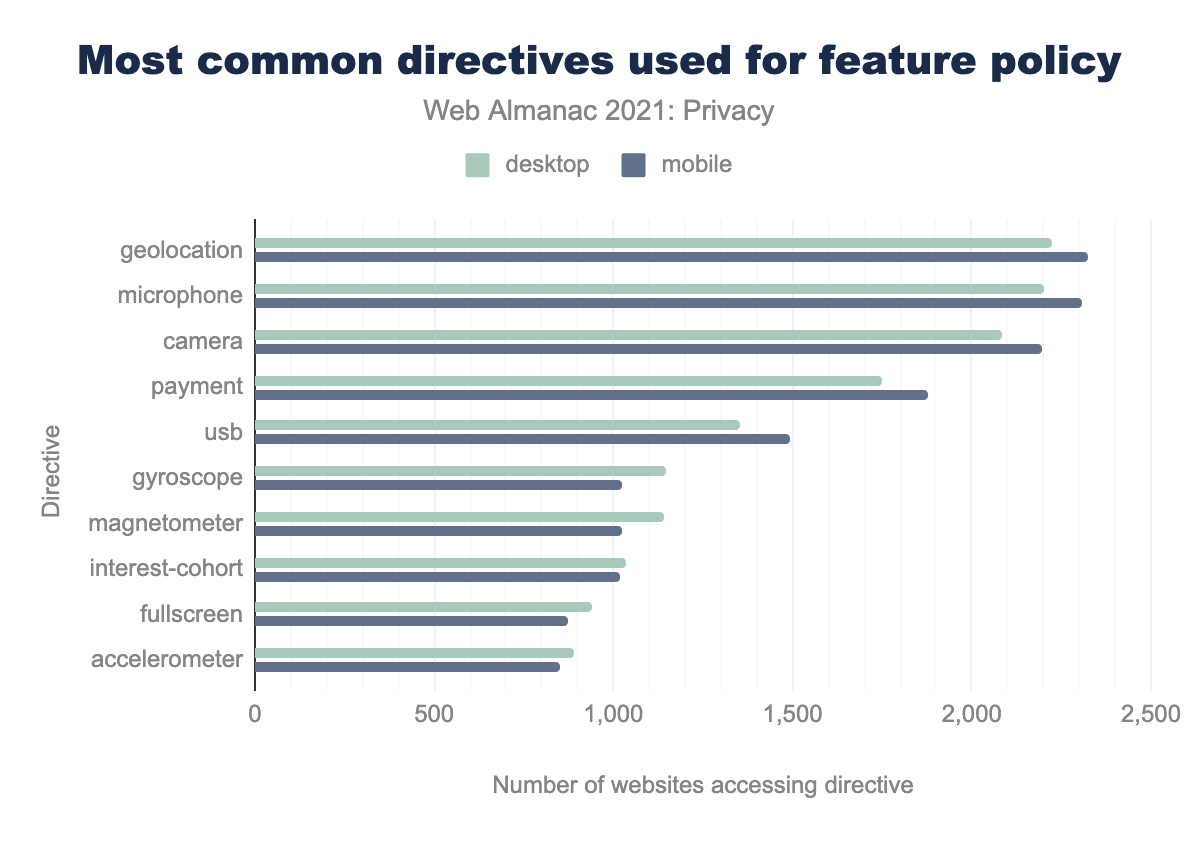
geolocation is used by 2,222 desktop sites and 2,323 mobile sites, microphone by 2,199 and 2,310 respectively, camera by 2,082 and 2,197, payment by 1,748 and 1,879, usb by 1,354 and 1,492, gyroscope by 1,145 and 1,025, magnetometer by 1,141 and 1,024, interest-cohort by 1,037 and 1,019, fullscreen by 940 and 873, accelerometer by 892 and 852.The most commonly used directives with relation to the feature policy are shown above. On 3,049 websites on mobile and 2,901 websites on desktop, the use of the microphone feature is specified. A tiny subset of our dataset, showing this is still a niche technology. Other often restricted features are geolocation, camera and payment.
To gain a deeper understanding of how the directives are used, we looked at the top 3 most used directives and the distribution of the values assigned to these directives.
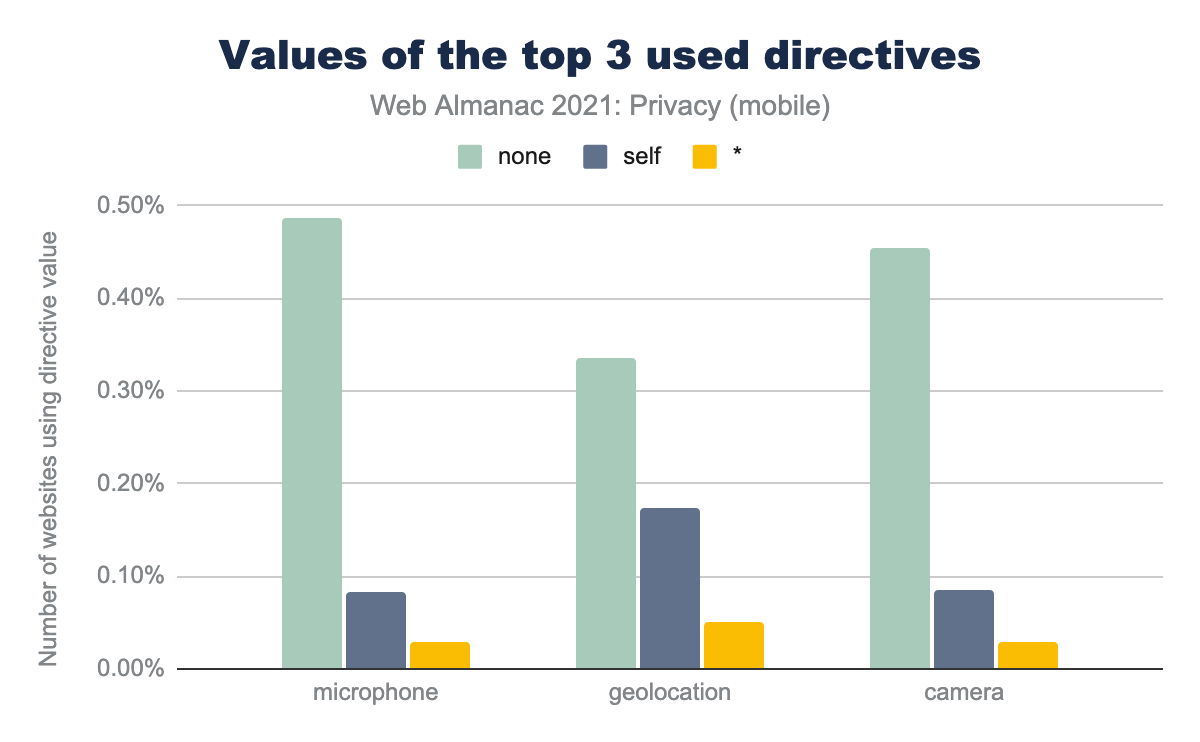
microphone is set to self for 0.08% of mobile sites, it is set to none for 0.49% of sites, and is set to * for 0.03% of sites. geolocation is set to self for 0.17% of mobile sites, it is set to none for 0.34% of sites, and is set to * for 0.05% of sites. camera is set to self for 0.09% of mobile sites, it is set to none for 0.46% of sites, and is set to * for 0.03% of sites.none is the most used value. This specifies that the feature is disabled in top-level and nested browsing contexts. The second most used value, self is used to specify that the feature is allowed in the current document and within the same origin, while * allows full, cross-origin access.
Referrer Policy
HTTP requests may include the optional Referer header, which indicates the origin or web page URL a request was made from. The Referer header might be present in different types of requests:
- Navigation requests, when a user clicks a link.
- Subresource requests, when a browser requests images, iframes, scripts, and other resources that a page needs.
For navigations and iframes, this data can also be accessed via JavaScript using document.referrer.
The Referer value can be insightful. But when the full URL including the path and query string is sent in the Referer across origins, this can be privacy-hindering: URLs can contain private information—sometimes even identifying or sensitive information. Leaking this silently across origins can compromise users’ privacy and pose security risks. The Referrer-Policy HTTP header allows developers to restrict what referrer data is made available for requests made from their site to reduce this risk.
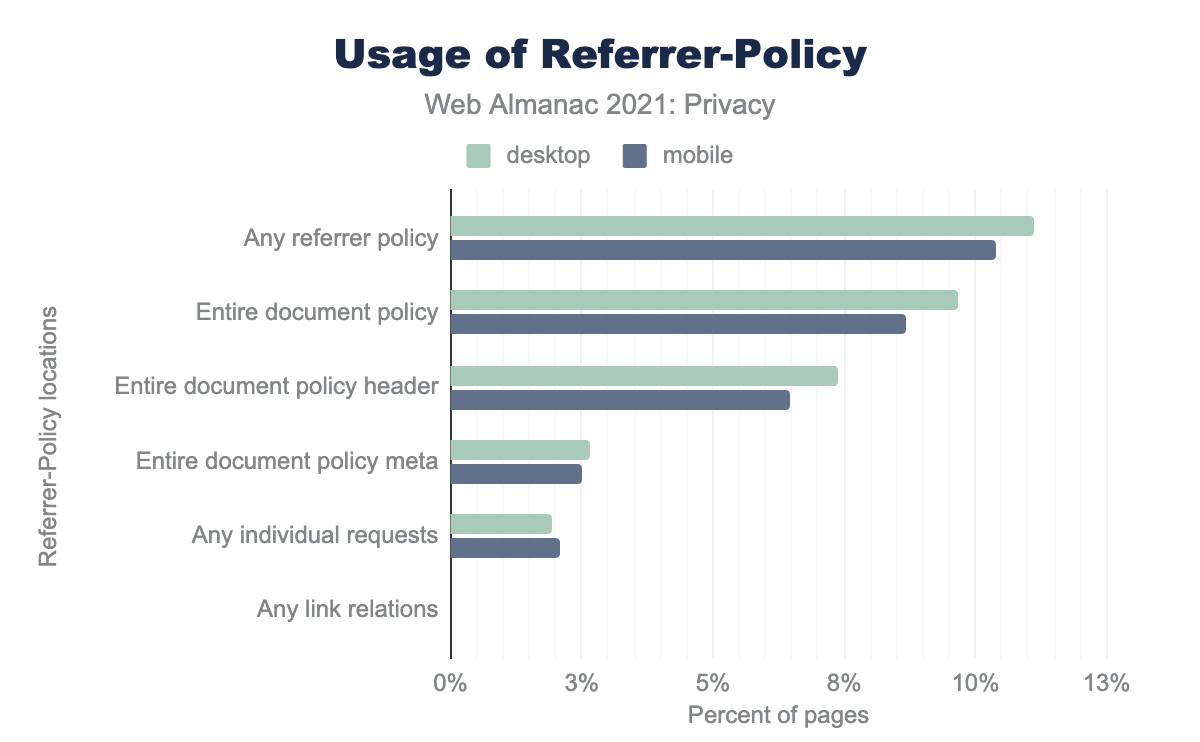
A first point to note is that most sites do not explicitly set a Referrer Policy. Only 11.12% of desktop websites and 10.38% of mobile websites explicitly define a Referrer Policy. The rest of them (the other 88.88% on desktop and 89.62% on mobile) will fall back to the browser’s default policy. Most major browsers recently introduced a default policy of strict-origin-when-cross-origin, such as Chrome in August 2020 and Firefox in March 2021. strict-origin-when-cross-origin removes the path and query fragments of the URL on cross-origin requests, which reduces security and privacy risks.
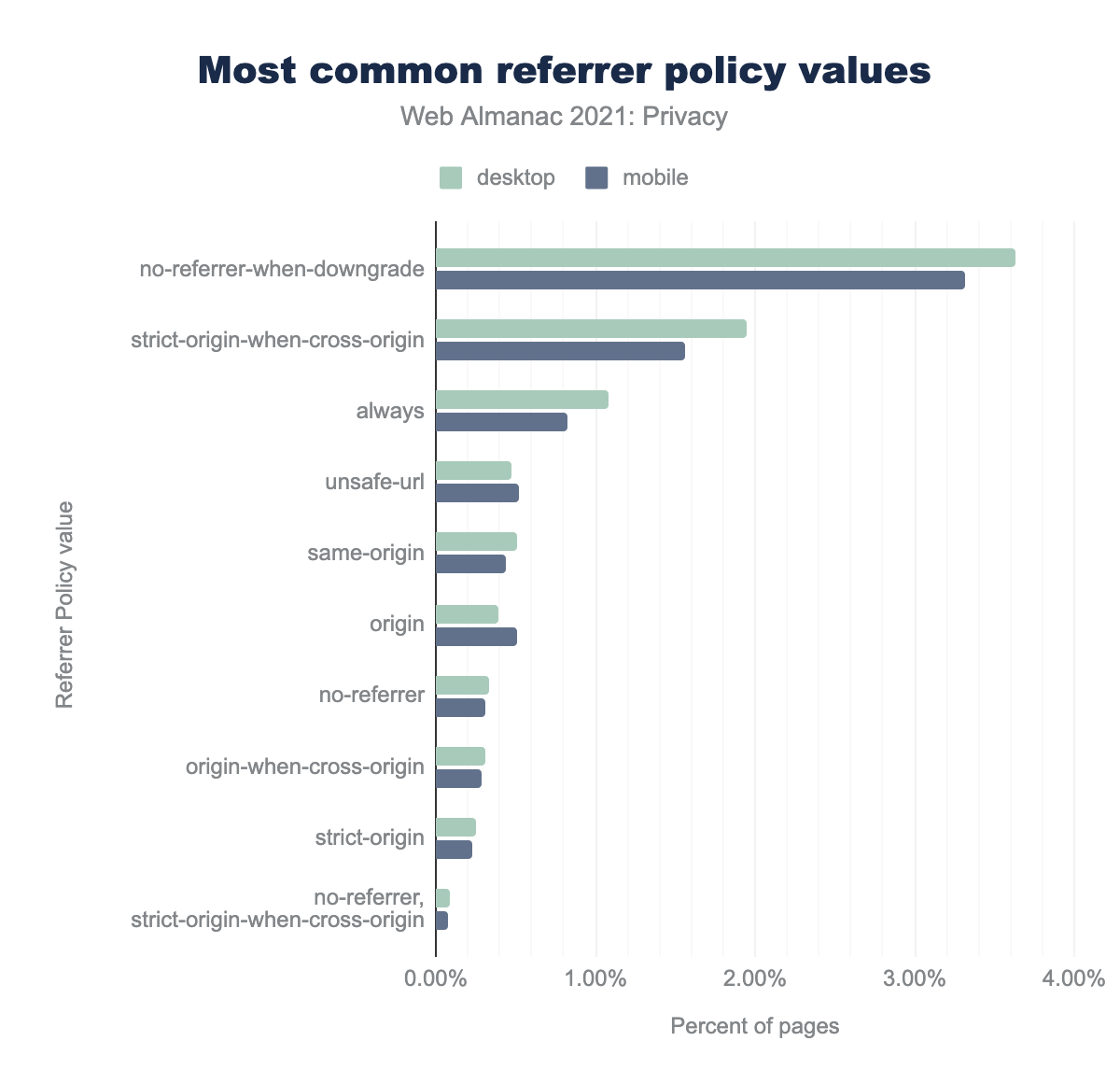
no-referrer-when-downgrade is used on 3.63% of desktop sites and 3.31% of mobile sites, strict-origin-when-cross-origin on 1.95% and 1.56% respectively, always on 1.08% and 0.82%, unsafe-url on 0.47% and 0.52%, same-origin on 0.51% and 0.44%, origin on 0.39% and 0.51%, no-referrer on 0.34% and 0.31%, origin-when-cross-origin on 0.31% and 0.29%, strict-origin on 0.26% and 0.23%, and finally no-referrer, strict-origin-when-cross-origin on 0.09% and 0.08%.The most common Referrer Policy that is explicitly set is no-referrer-when-downgrade. It’s set on 3.38% of websites on mobile clients and 3.81% of websites on desktop clients. no-referrer-when-downgrade is not privacy-enhancing. With this policy, full URLs of pages a user visits on a given site are shared in cross-origin HTTPS requests (the vast majority of requests), which makes this information accessible to other parties (origins).
In addition, around 0.5% of websites set the value of the referrer policy to unsafe-url, which allows the origin, host and query string to be sent with any request, regardless of the security level of the receiver. In this case, a referrer could be sent in the clear, potentially leaking private information. Worryingly, sites are actively being configured to enable this behavior.
User-Agent Client Hints
When a web browser makes an HTTP request, it will include a User-Agent header that provides information about the client’s browser, device and network capabilities. However, this can be abused for profiling users or uniquely identifying them through fingerprinting.
User-Agent Client Hints enable access to the same information as the User-Agent string, but in a more privacy-preserving way. This will in turn enable browsers to eventually reduce the amount of information provided by default by the User-Agent string, as Chrome is proposing with a gradual plan for User Agent Reduction.
Servers can indicate their support for these Client Hints by specifying the Accept-CH header. This header lists the attributes that the server requests from the client in order to serve a device-specific or network-specific resource. In general, Client Hints provide a way for servers to obtain only the minimum information necessary to serve content in an efficient manner.
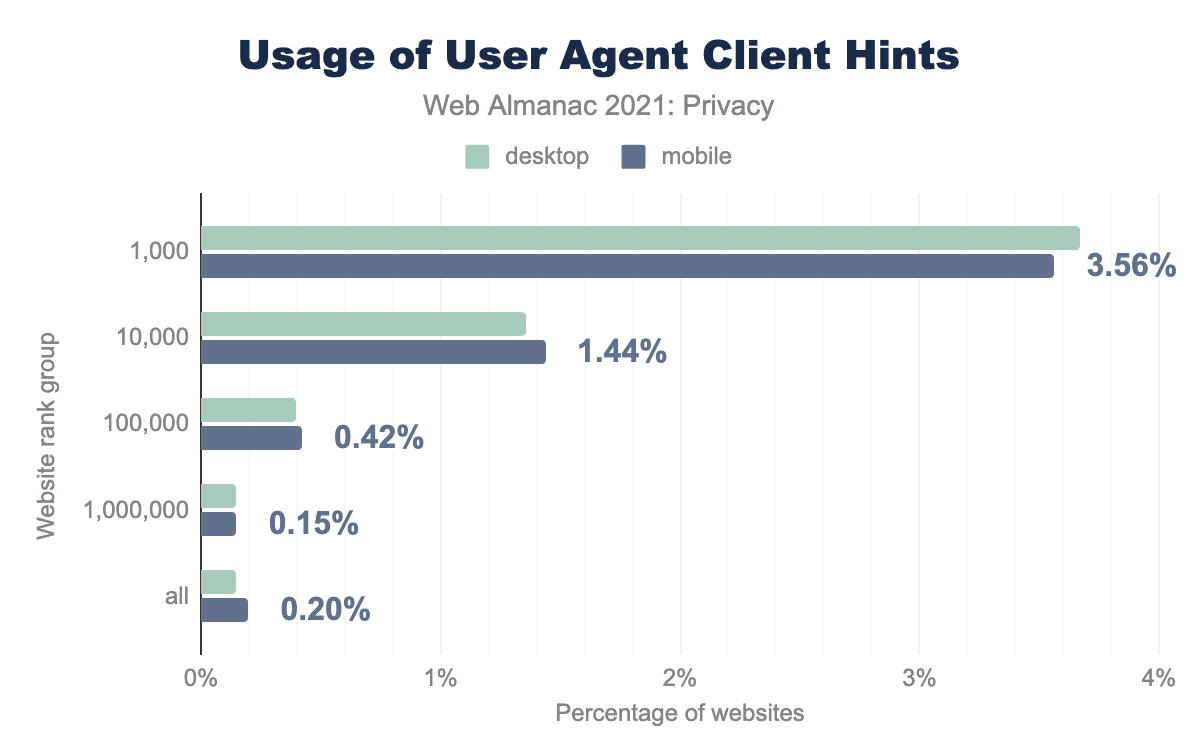
However, at this point, few websites have implemented Client Hints. We also see a big difference between the use of Client Hints on popular websites and on less popular ones. 3.67% of the top 1,000 most popular websites on mobile request Client Hints. In the top 10,000 websites, the implementation rate drops to 1.44%.
How websites give you a privacy choice: Privacy preference signals
In light of the recent introduction of privacy regulations, such as those mentioned in the introduction, websites are required to obtain explicit user consent about the collection of personal data for any non-essential features such as marketing and analytics.
Therefore, websites turned to the use of cookie consent banners, privacy policies and other mechanisms (which have evolved over time) to inform users about what data these sites process, and give them a choice. In this section, we look at the prevalence of such tools.
Consent Management Platforms
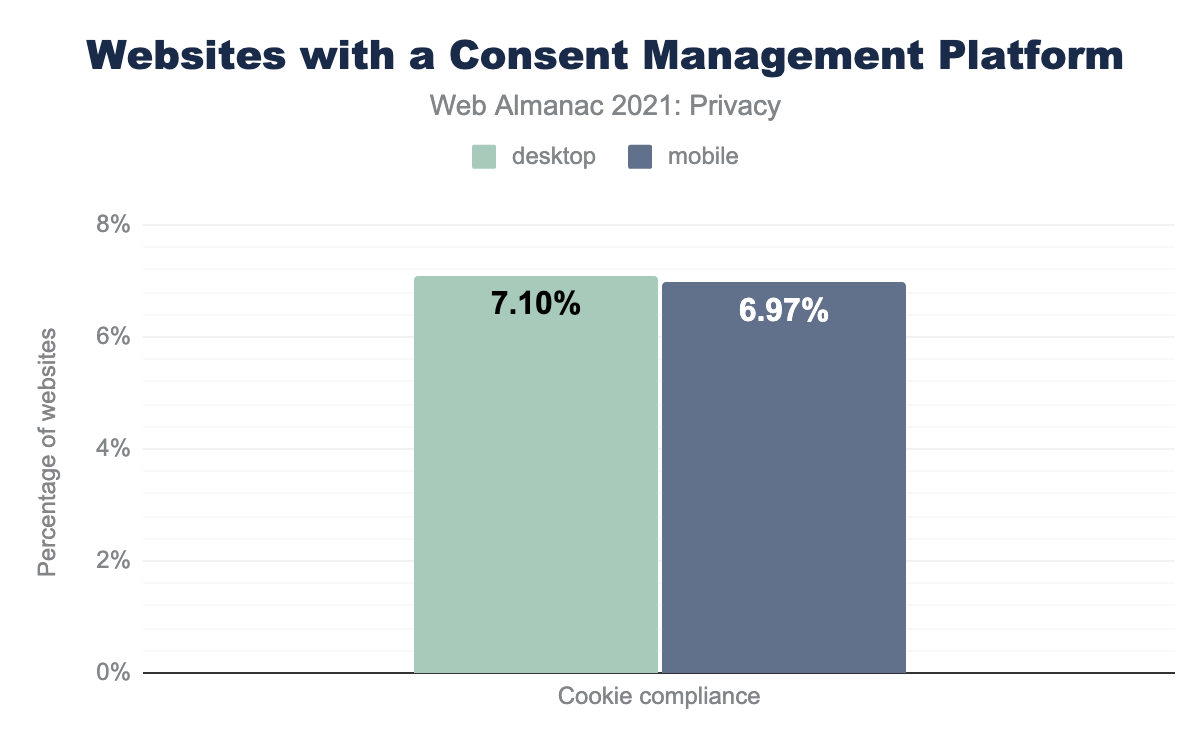
Consent Management Platforms (CMPs) are third-party libraries that websites can include to provide a cookie consent banner for users. We saw around 7% of websites using a Consent Management Platform.
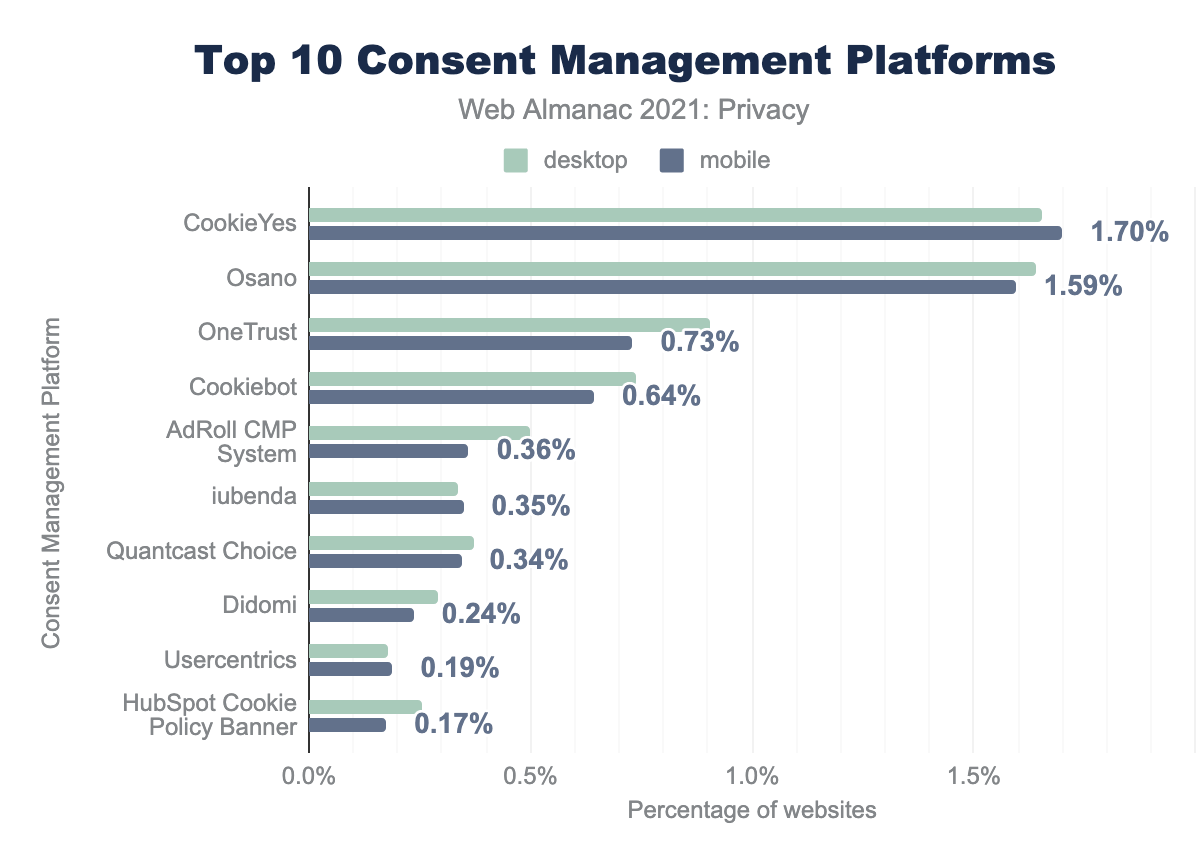
The most popular libraries are CookieYes and Osano, but we found more than twenty different libraries that allow websites to include cookie consent banners. Each library was only present on a small share of websites, at less than 2% each.
IAB’s Consent Frameworks
The Transparency and Consent Framework (TCF) is an initiative of the Interactive Advertising Bureau Europe (IAB) for providing an industry standard for communicating user consent to advertisers. The framework consists of a Global Vendor List, in which vendors can specify the legitimate purpose of the processed data, and a list of CMPs who act as an intermediary between the vendors and the publishers. Each CMP is responsible for communicating the legal basis and storing the consent option provided by the user in the browser. We refer to the stored cookie as the consent string.
TCF is meant as a GDPR-compliant mechanism in Europe, although a recent decision by the Belgian Data Protection Authority found that this system is still infringing. When the CCPA came into play in California, IAB Tech Lab US developed the U.S. Privacy (USP) technical specifications, using the same concepts.
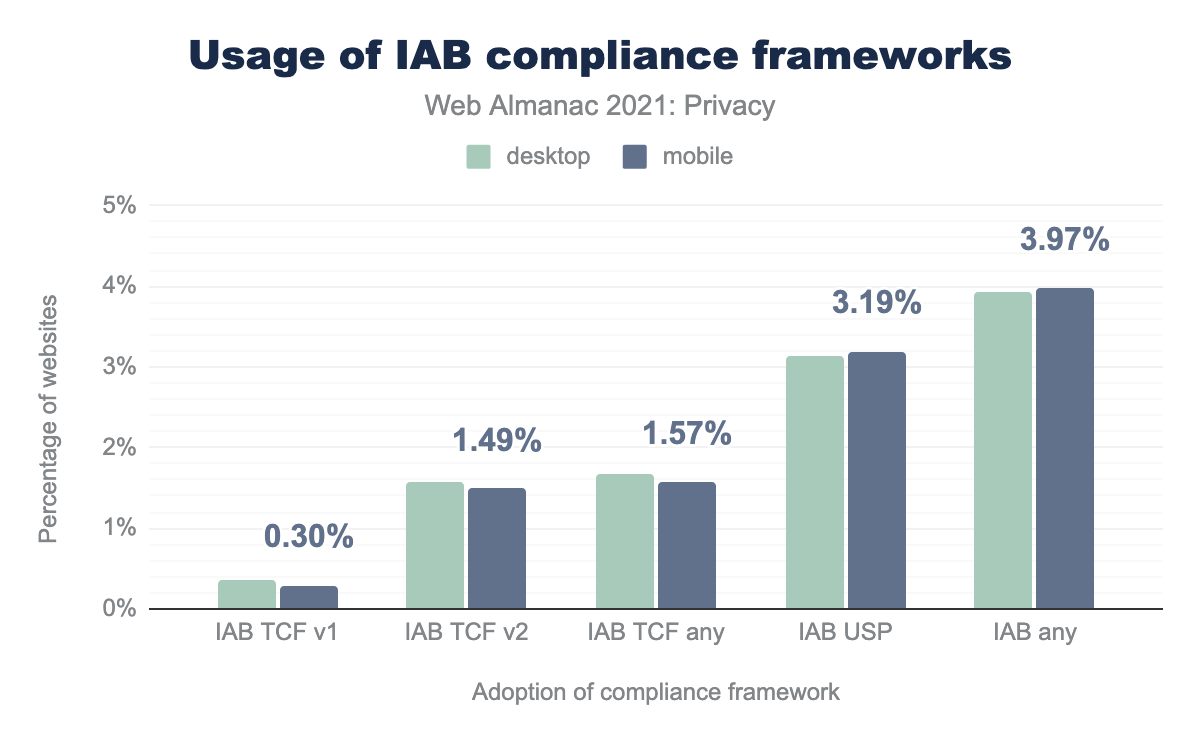
Above, we show the distribution of the usage of both versions of TCF and of USP. Note that the crawl is US-based, therefore we do not expect many websites to have implemented TCF. Fewer than 2% of websites use any TCF version, while twice as many websites use the US Privacy framework.
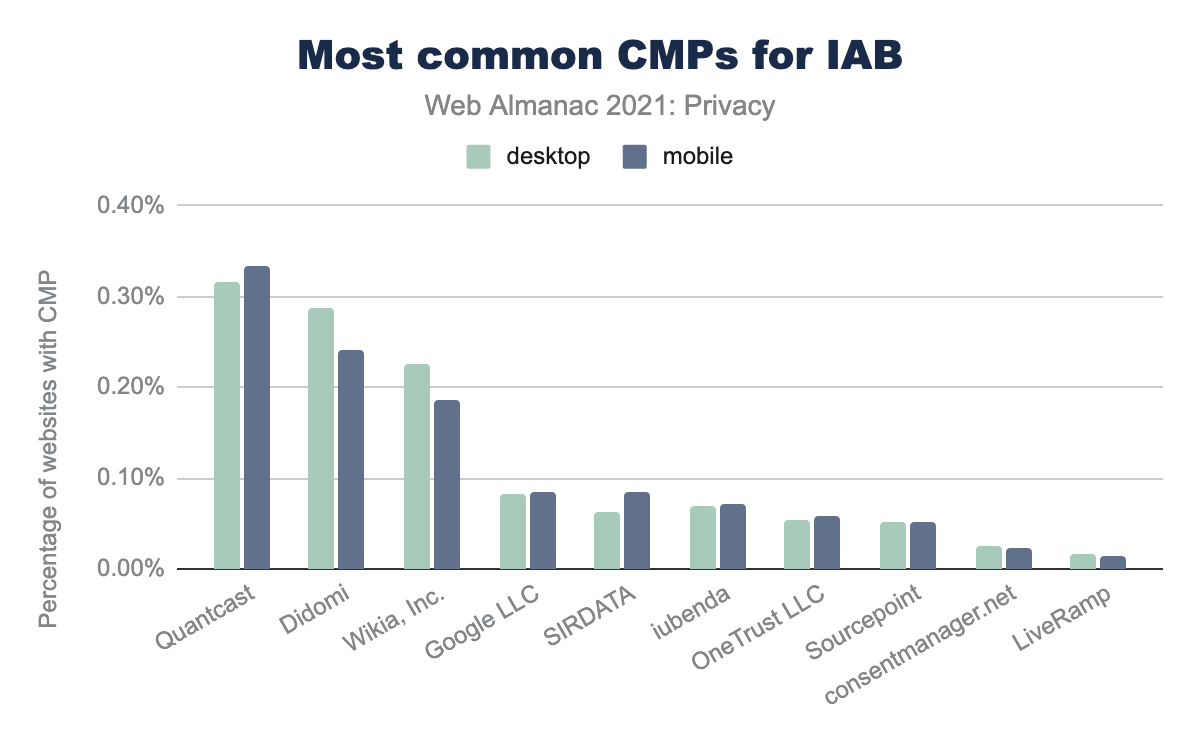
In the 10 most popular consent management platforms that are part of the framework, at the top we find Quantcast with 0.34% on mobile. Other popular solutions are Didomi with 0.24%, and Wikia, with 0.30%.
In the USP framework, the website’s and user’s privacy settings are encoded in a privacy string.
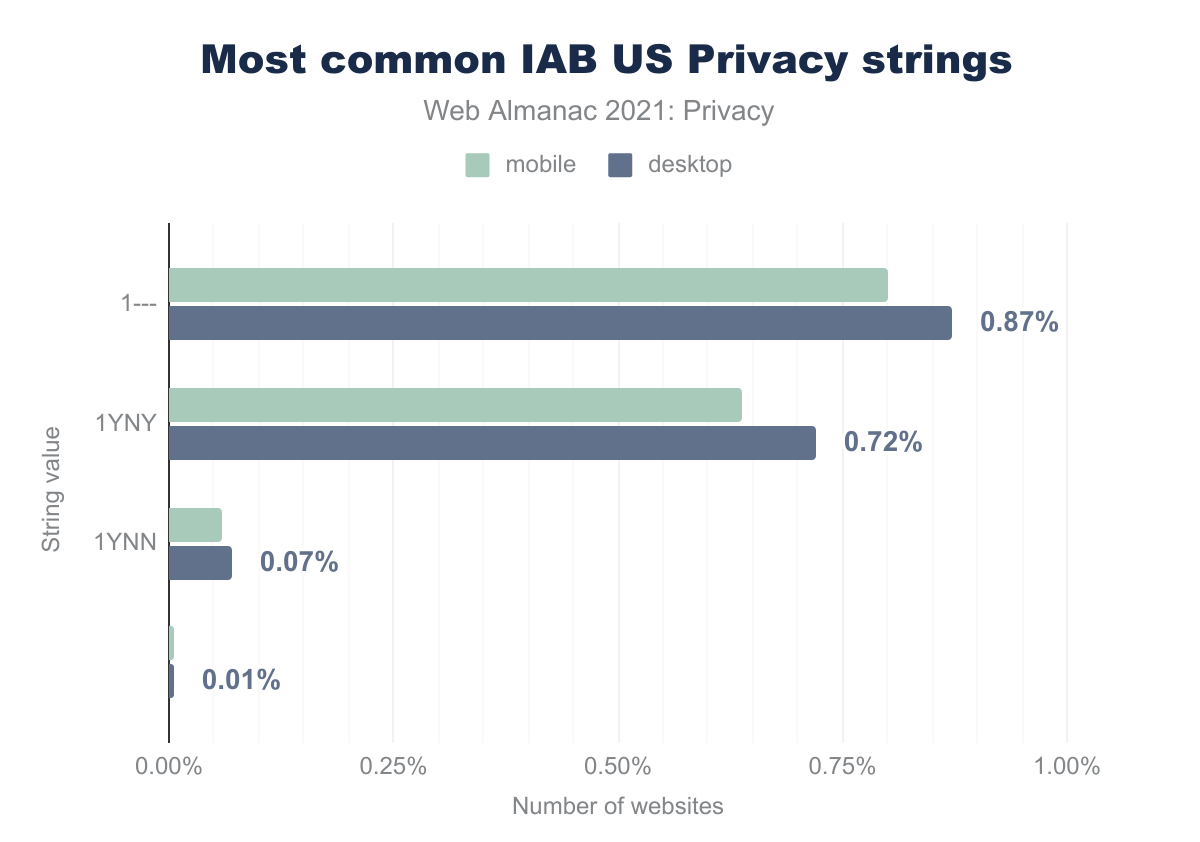
1--- is used by 0.87% of desktop websites and 0.80% of mobile websites, 1YNY is 0.72% and 0.64% respectively, 1YNN is 0.07% and 0.06%, and blank is 0.01% and 0.00%.The most common privacy string is 1---. This indicates that CCPA does not apply to the website and therefore the website not obliged to provide an opt-out for the user. CCPA only applies to companies whose main business involves selling personal data, or to companies that process data and have an annual turnover of more than $25 million. The second most recurring string is 1YNY. This indicates that the website provided “notice and opportunity to opt-out of sale of data”, but that the user has not opted out of the sale of their personal data.
Privacy policies
Nowadays, most websites have a privacy policy, where users can learn about the types of information that is stored and processed about them.
By looking for keywords such as “privacy policy”, “cookie policy”, and more, in a number of languages, we see that 39.70% of mobile websites, and 43.02% of desktop sites refer to some sort of privacy policy. While some websites are not required to have such a policy, many websites handle personal data and should therefore have a privacy policy to be fully transparent towards their users.
Do Not Track - Global Privacy Control
The Do Not Track (DNT) HTTP header can be used to communicate to websites that a user does not wish to be tracked. We can see the number of sites that appear to access the current value for DNT below, based on the presence of the Navigator.doNotTrack JavaScript call.
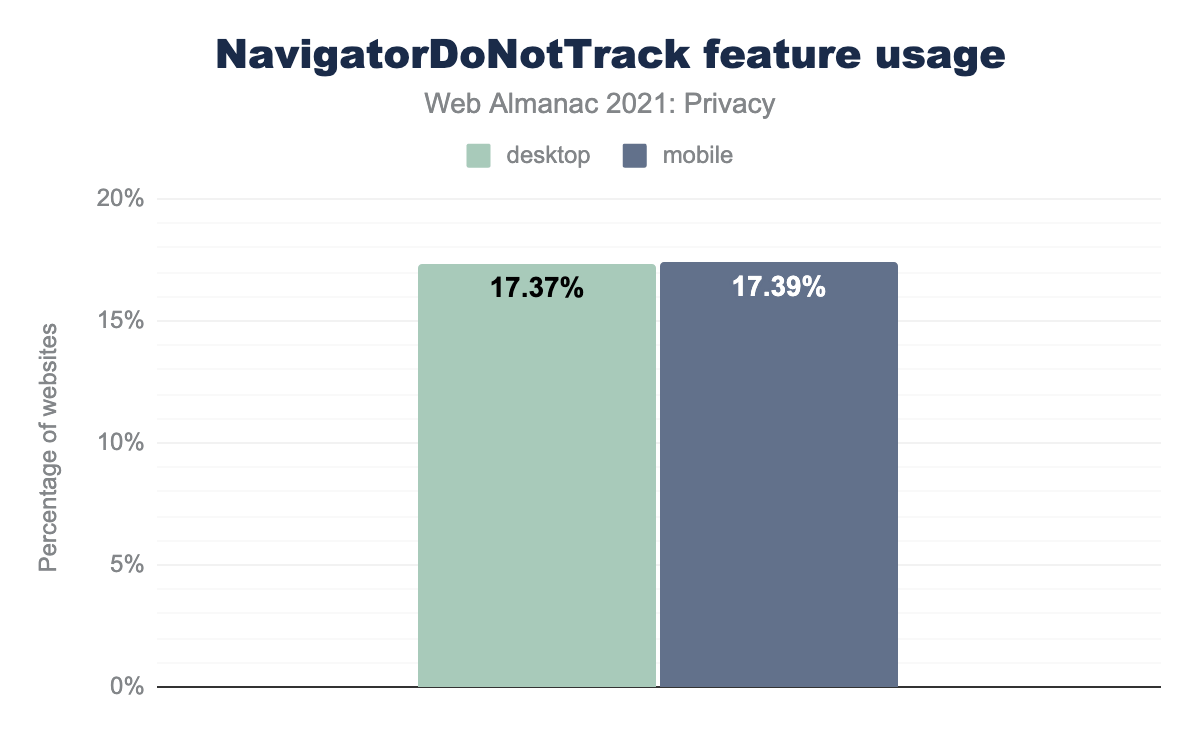
NavigatorDoNotTrack feature. 17.37% of desktop sites and 17.39% of mobile sites access this.Around the same percentage of pages on mobile and desktop clients use DNT. However, in practice hardly any websites actually respect the DNT opt-outs. The Tracking Protection Working Group, which specifies DNT, closed down in 2018, due to “lack of support”. Safari then stopped supporting DNT to prevent potential abuse for fingerprinting.
DNT’s successor Global Privacy Control (GPC) was released in October 2020 and is meant to provide a more enforceable alternative, with the hopes of better adoption. This privacy preference signal is implemented with a single bit in all HTTP requests. We did not yet observe any uptake, but we can expect this to improve in future as major browsers are now starting to implement GPC.
How browsers are evolving their privacy approaches
Given the push to better protect users’ privacy while browsing the web, major browsers are implementing new features that should better safeguard users’ sensitive data. We already covered ways in which browsers have started enforcing more privacy-preserving default settings for Referrer-Policy headers and SameSite cookies.
Furthermore, Firefox and Safari seek to block tracking through Enhanced Tracking Protection and Intelligent Tracking Prevention respectively.
Beyond blocking trackers, Chrome has launched the Privacy Sandbox to develop new web standards that provide more privacy-friendly functionality for various use cases, such as advertising and fraud protection. We’ll look more closely at these up-and-coming technologies that are designed to reduce the opportunity for sites to track users.
Privacy Sandbox
To seek ecosystem feedback, early and experimental versions of Privacy Sandbox APIs are made available initially behind feature flags for testing by individual developers, and then in Chrome via origin trials. Sites can take part in these origin trials to test experimental web platform features, and give feedback to the web standards community on a feature’s usability, practicality, and effectiveness, before it’s made available to all websites by default.
FLoC
One of the most hotly debated Privacy Sandbox experiments has been Federated Learning of Cohorts, or FLoC for short. The origin trial for FLoC ended in July 2021.
Interest-based ad selection is commonly used on the web. FLoC provided an API to meet that specific use case without the need to identify and track individual users. FLoC has taken some flak: Firefox and other Chromium-based browsers have declined to implement it, and the Electronic Frontier Foundation has voiced concerns that it might introduce new privacy risks. However, FLoC was a first experiment. Future iterations of the API could alleviate these concerns and see wider adoption.
With FLoC, instead of assigning unique identifiers to users, the browser determined a user’s cohort: a group of thousands of people who visited similar pages and may therefore be of interest to the same advertisers.
Since FLoC was an experiment, it was not widely deployed. Instead, websites could test it by enrolling in an origin trial. We found 62 and 64 websites that tested FLoC across desktop and mobile respectively.
Here is how the first FLoC experiment worked: as a user moved around the web, their browser used the FLoC algorithm to work out its interest cohort, which was the same for thousands of browsers with a similar recent browsing history. The browser recalculated its cohort periodically, on the user’s device, without sharing individual browsing data with the browser vendor or other parties. When working out its cohort, a browser was choosing between cohorts that didn’t reveal sensitive categories.
Individual users and websites could opt out of being included in the cohort calculation.
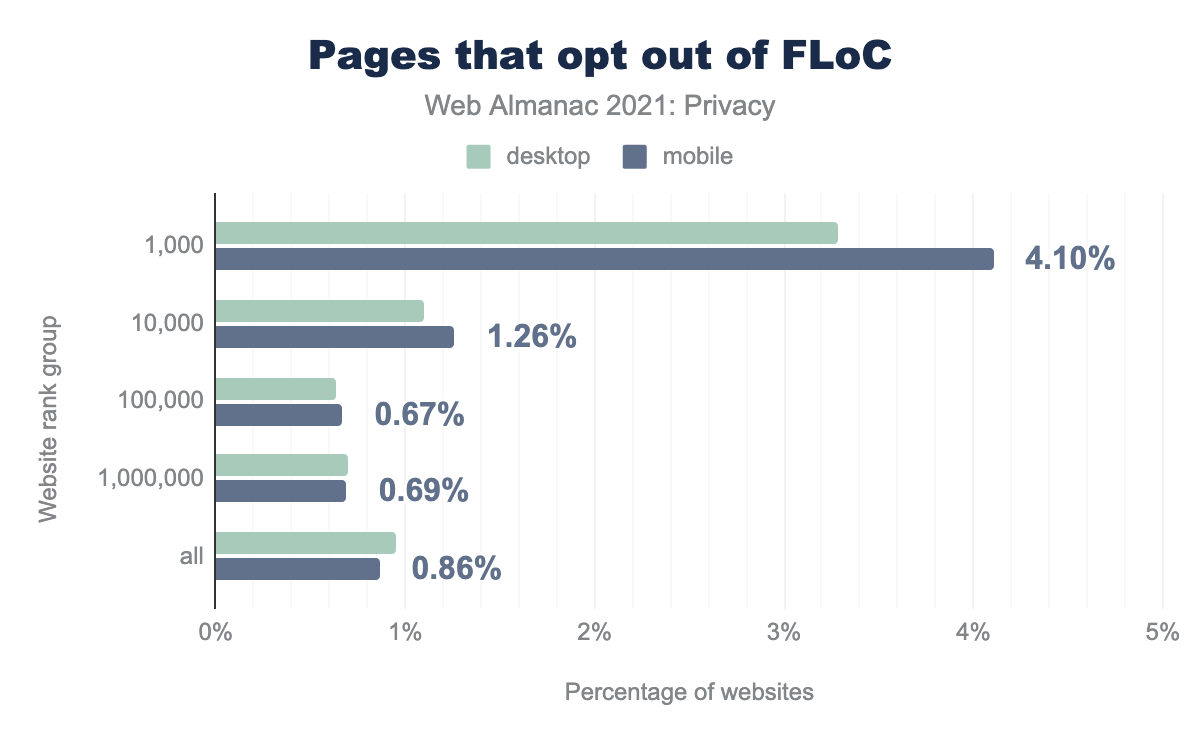
We saw that 4.10% of the top 1,000 websites have opted out of FLoC. Across all websites, under 1% have opted out.
Other Privacy Sandbox experiments
Within Google’s Privacy Sandbox initiative, a number of experiments are in various stages of development.
The Attribution Reporting API (previously called Conversion Measurement) makes it possible to measure when user interaction with an ad leads to a conversion—for example, when an ad click eventually led to a purchase. We saw the first origin trial (which ended in October 2021) enabled on 10 origins.
FLEDGE (First “Locally-Executed Decision over Groups” Experiment) seeks to address ad targeting. The API can be tested in current versions of Chrome locally by individual developers but there is no origin trial as of October 2021.
Trust Tokens enable a website to convey a limited amount of information from one browsing context to another to help combat fraud, without passive tracking. We saw the first origin trial (which will end in May 2022) enabled on 7 origins that are likely embedded in a number of sites as third-party providers.
CHIPS (Cookies Having Independent Partitioned State) allows websites to mark cross-site cookies as “Partitioned”, putting them in a separate cookie jar per top-level site. (Firefox has already introduced the similar Total Cookie Protection feature for cookie partitioning.) As of October 2021, there is no origin trial for CHIPS.
Fenced Frames protect frame access to data from the embedding page. As of October 2021, there is no origin trial.
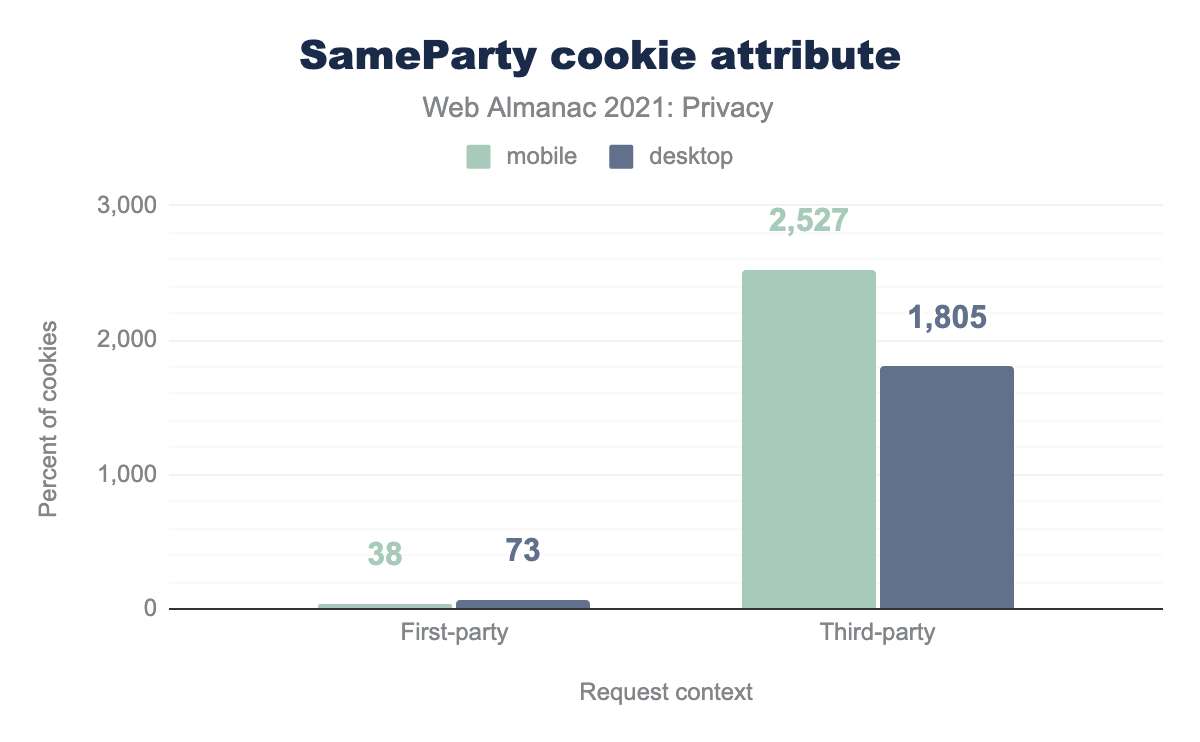
SameParty is used on 38 desktop sites and 73 mobile sites, for third-party cookies it’s used on 2,527 desktop sites and 1,805 mobile sites.
Finally, First-Party Sets allow website owners to define a set of distinct domains that actually belong to the same entity. Owners can then set a SameParty attribute on cookies that should be sent across cross-site contexts, as long as the sites are in the same first-party set. A first origin trial ended in September 2021. We saw the SameParty attribute on a few thousand cookies.
Conclusion
Users’ privacy remains at risk on the web today: over 80% of all websites have some form of tracking enabled, and novel tracking mechanisms such as CNAME tracking are being developed. Some sites also handle sensitive data such as geolocation, and if they’re not careful, potential breaches could result in users’ personal data being exposed.
Fortunately, increased awareness about the need for privacy on the web has led to concrete action. Websites now have access to features that allow them to safeguard access to sensitive resources. Legislation across the globe enforces explicit user consent for sharing personal data. Websites are implementing privacy policies and cookie banners to comply. Finally, browsers are proposing and developing innovative technologies to continue supporting use cases such as advertising and fraud detection in a more privacy-friendly way.
Ultimately, users should be empowered to have a say in how their personal data is treated. Meanwhile, browsers and website owners should develop and deploy the technical means to guarantee that users’ privacy is protected. By incorporating privacy throughout our interactions with the web, users can feel more certain that their personal data is well protected.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}