HTTP/2
Introdução
O HTTP/2 foi a primeira grande atualização do principal protocolo de transporte da web em quase 20 anos. Ele chegou com muitas expectativas: prometia um aumento de desempenho gratuito e sem desvantagens. Mais do que isso, poderíamos deixar de lado todos as adaptações e saídas mirabolantes a que o HTTP/1.1 nos forçava, devido às suas ineficiências. Técnicas como bundling, spriting, inlining e até mesmo sharding se tornariam não canônicas em um mundo com HTTP/2, visto que a performance otimizada já seria fornecida por padrão.
Isso significava que mesmo aqueles sem as habilidades e os recursos para se concentrar na performance na web de repente teriam sites com bom desempenho. Contudo, a realidade foi, como sempre, um pouco mais sutil do que isso. Já se passaram mais de quatro anos desde a aprovação formal do HTTP/2 como um padrão em maio de 2015 como RFC 7540, assim agora é um bom momento para verificar como essa tecnologia relativamente nova se saiu no mundo real.
O que é HTTP/2?
Para aqueles que não estão familiarizados com a tecnologia, um pouco de experiência é útil para aproveitar ao máximo as métricas e descobertas neste capítulo. Até recentemente, o HTTP sempre foi um protocolo baseado em texto. Um cliente HTTP como um navegador web abria uma conexão TCP com um servidor, e então enviava um comando como GET /index.html para solicitar um recurso.
Isso foi aprimorado no HTTP/1.0 ao adicionar HTTP headers (cabeçalhos HTTP), asim várias partes de metadados poderiam ser incluídas além da requisição, como qual é o navegador, que formatos entende, etc. Esses cabeçalhos também eram baseados em texto e e separados por caracteres de nova linha. Os servidores analisavam as requisições recebidas, lendo a requisição e quaisquer cabeçalhos linha por linha, e em seguida respondiam com seus próprios cabeçalhos HTTP de resposta junto ao recurso de fato sendo solicitado.
O protocolo parecia simples, mas também apresentava limitações. Como o HTTP era essencialmente síncrono, uma vez que uma requisição HTTP era feita, toda a conexão TCP ficava basicamente fora do alcance de qualquer outra coisa até que a resposta fosse retornada, lida e processada. Isso era incrivelmente ineficiente e exigia múltiplas conexões TCP (os navegadores normalmente usam 6) para permitir uma forma limitada de paralelização.
Isso por si só já trás seus próprios problemas considerando que as conexões TCP demandam tempo e recursos para serem estabelecidas e obter eficiência total, especialmente ao usar HTTPS, que requer etapas adicionais para configurar a criptografia. O HTTP/1.1 melhorou isso em alguma medida, permitindo a reutilização de conexões TCP para requisições subsequentes, mas ainda não resolveu a dificuldade em paralelização.
Apesar do HTTP ser baseado em texto, a realidade é que ele raramente era usado para transportar texto, ao menos em seu formato puro. Embora fosse verdade que os cabeçalhos ainda eram texto, os payloads em si frequentemente não eram. Arquivos de texto como HTML, JS e CSS costumam ser compactados para transporte em formato binário usando Gzip, Brotli ou similar. Arquivos não textuais como imagens e vídeos são distribuidos em seus próprio formatos. A mensagem HTTP completa é então costumeiramente encapsulada em HTTPS para criptografar as mensagens por razões de segurança.
Portanto, a web tinha basicamente movido de um transporte baseado em texto há muito tempo, mas o HTTP não. Uma razão para essa estagnação foi porque era muito difícil introduzir qualquer alteração significativa em um protocolo tão onipresente como o HTTP (esforços anteriores haviam tentado e falhado). Muitos roteadores, firewalls e outros dispositivos de rede entendiam o HTTP e reagiriam mal a grandes mudanças maiores. Atualizar todos eles para suportar uma nova versão simplesmente não era impossível.
Em 2009, a Google anunciou que estava trabalhando em uma alternativa ao HTTP baseado em texto chamada SPDY, que já foi descontinuada. Isso tiraria vantagem do fato de que as mensagens HTTP eram frequentemente criptografadas em HTTPS, o que evita que sejam lidas ou sofram interferência no trajeto.
A Google controlava um dos navegadores mais populares (Chrome) e alguns dos sites mais polulares (Google, YouTube, Gmail, etc) — logo, ambas as extremidades da conexão quando usados juntos. A ideia da Google era empacotar mensagens HTTP em um formato propriertário, enviá-las através da internet e desempacotá-las do outro lado. O formato proprietário, SPDY, era baseado em binário ao invés de texto. Isso resolveu alguns dos principais problemas de desempenho com o HTTP/1.1 ao permitir o uso mais eficiente de uma única conexão TCP, desprezando a necessidade de abrir as seis conexões que se tornaram regra no HTTP/1.1.
Ao usar SPDY no mundo real, eles conseguiram provar que era mais eficiente para usuários reais, e não apenas por causa de alguns resultados experimentais baseados em laboratório. Depois da implantação do SPDY em todos os sites da Google, outros servidores e navegadores começaram a implementá-lo e, então, era hora de padronizar este formato proprietário em um padrão na internet, e assim nasceu o HTTP/2.
O HTTP/2 tem os seguintes conceitos-chave:
- Formato binário
- Multiplexação
- Controle de fluxo
- Priorização
- Compressão de cabeçalho
- Push
Formato binário significa que as mensagens HTTP/2 são encapsuladas em quadros de um formato predefinido, fazendo com que as mensagens HTTP sejam mais fáceis de analisar e não precisem mais da verificação de caracteres de nova linha. Isso é melhor para a segurança já que havia um número considerável de exploits para as versões anteriores do HTTP. Isso também quer dizer que as conexões HTTP/2 podem ser multiplexadas. Quadros diferentes para fluxos diferentes podem ser enviados na mesma conexão sem a interferência de um no outro, pois cada quadro inclui um identificador de fluxo e seu comprimento. A multiplexação permite o uso bem mais eficiente de uma única conexão TCP sem a sobrecarga de abrir conexões adicionais. Idealmente, abriríamos uma única conexão por domínio ou mesmo para vários domínios!
Ter fluxos separados introduz algumas complexidades junto com alguns benefícios potenciais. O HTTP/2 precisa do conceito de controle de fluxo para permitir que os diferentes fluxos enviem dados em taxas diferentes, enquanto anteriormente, com apenas uma resposta em movimento a qualquer momento, isso era controlado a nível de conexão pelo controle de fluxo do TCP. Da mesma forma, a priorização permite que múltiplas requisições sejam enviadas juntas, mas com as requisições mais importantes obtendo mais largura de banda.
Por fim, o HTTP/2 introduziu dois novos conceitos: compactação de cabeçalho e HTTP/2 push. A compactação de cabeçalho permitiu que os cabeçalhos HTTP baseados em texto fossem enviados com mais eficiência, usando um formato HPACK específico do HTTP/2 por motivos de segurança. O HTTP/2 push permitia que mais de uma resposta fosse enviada em retorno a uma requisição, permitindo que o servidor enviasse recursos antes mesmo que o cliente soubesse que precisava deles. O push deveria acabar com a solução alternativa de performance de ter de incorporar recursos como CSS e JavaScript diretamente no HTML para evitar que a página fique suspensa enquanto esses recursos são solicitados. Com o HTTP/2, o CSS e o JavaScript podem permanecer como arquivos externos, mas ser enviados junto com o HTML inicial para que estejam disponíveis imediatamente. As requisições subsequentes da página não enviariam esses recursos, uma vez que agora eles estariam armazenados na cache e, portanto, não desperdiçariam largura de banda.
Este passeio rápido pelo HTTP/2 fornece a história e os conceitos principais do protocolo mais recente. Como deve ficar claro a partir dessa explicação, o principal benefício do HTTP/2 é abordar as limitações de desempenho do protocolo HTTP/1.1. Também houve melhorias de segurança — talvez o mais importante é tratar dos problemas de desempenho do uso de HTTPS, uma vez que HTTP/2, mesmo sobre HTTPS, costuma ser muito mais rápido do que o HTTP simples. Exceto pelo navegador web que empacota as mensagens HTTP no novo formato binário e pelo servidor web que as desempacota no outro lado, os princípios básicos do próprio HTTP permaneceram praticamente os mesmos. Isso significa que os aplicativos web não precisam fazer quaisquer alterações para suportar o HTTP/2, uma vez que o navegador e o servidor cuidam disso. Ativá-lo deve ser um aumento de desempenho gratuito, portanto, a adoção deve ser relativamente fácil. Obviamente, existem maneiras dos desenvolvedores web otimizarem para HTTP/2 para aproveitar ao máximo suas diferenças.
Adoção do HTTP/2
Como mencionado acima, os protocolos da internet são frequentemente difíceis de adotar, uma vez que estão enraizados em grande parte da infraestrutura que compõe a internet. Isso torna a introdução de quaisquer mudanças lenta e difícil. O IPv6, por exemplo, existe há 20 anos, mas tem dificuldade de ser adotado.
O HTTP/2, contudo, era diferente, visto que estava efetivamente oculto em HTTPS (pelo menos para os casos de uso do navegador), removendo as barreiras para adoção, desde que o navegador e o servidor o suportassem. O suporte do navegador tem sido muito forte há algum tempo e o advento da atualização automática nos navegadores, evergreen, significou que cerca de 95% dos usuários globais agora suportam HTTP/2.
Nossa análise é proveniente do HTTP Archive, que testa aproximadamente 5 milhões dos principais sites para desktop e dispositivos móveis (mobile) no navegador Chrome. (Saiba mais sobre nossa metodologia.)
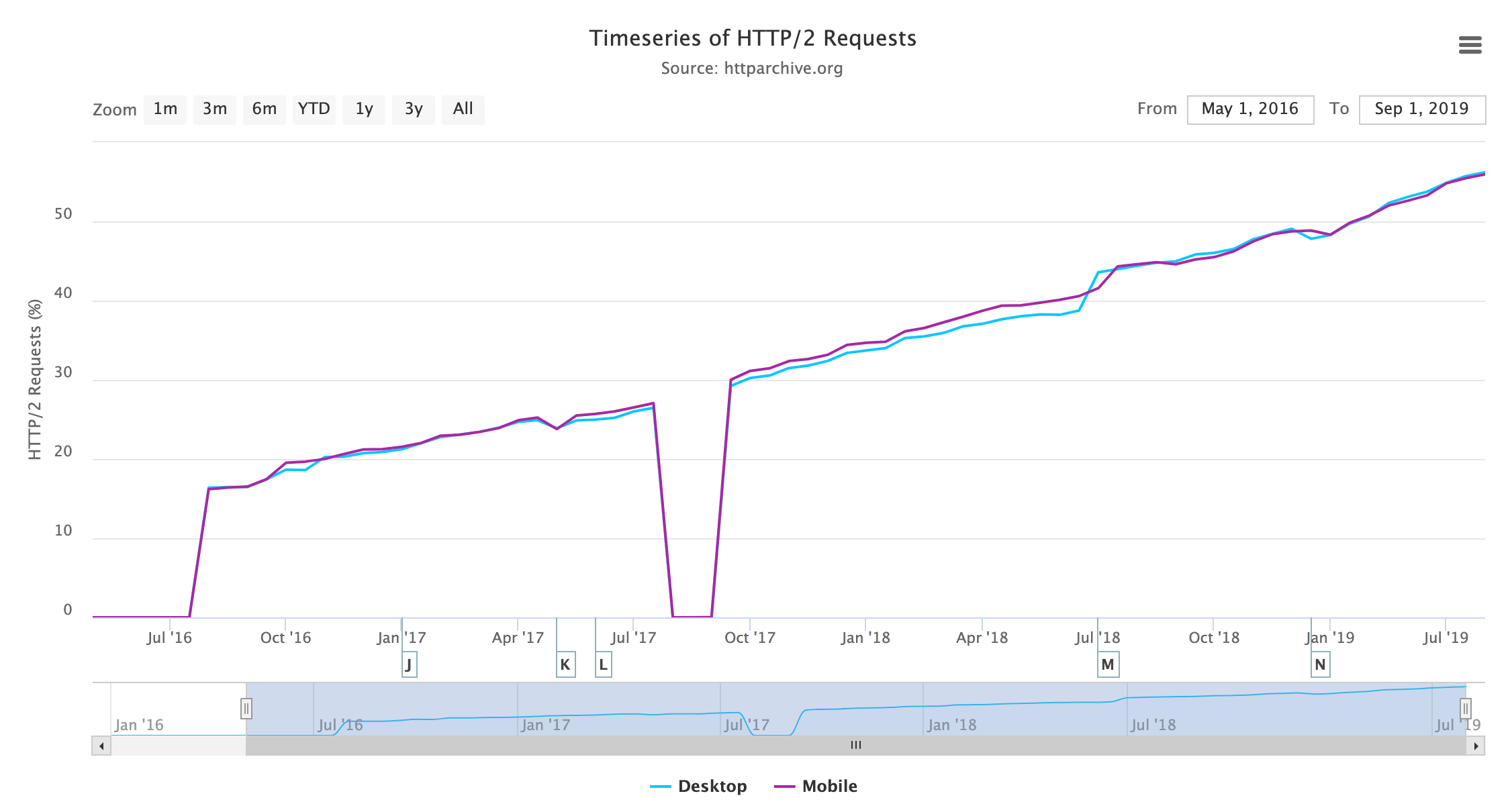
Os resultados mostram que o uso do protocolo HTTP/2 agora é majoritário — um feito impressionante 4 anos após apenas a padronização formal! Olhando para o detalhamento de todas as versões de HTTP por requisição, vemos o seguinte:
| Protocol | Desktop | Mobile | Ambos |
|---|---|---|---|
| 5.60% | 0.57% | 2.97% | |
| HTTP/0.9 | 0.00% | 0.00% | 0.00% |
| HTTP/1.0 | 0.08% | 0.05% | 0.06% |
| HTTP/1.1 | 40.36% | 45.01% | 42.79% |
| HTTP/2 | 53.96% | 54.37% | 54.18% |
A Figura 20.3 mostra que o HTTP/1.1 e o HTTP/2 são as versões usadas pela grande maioria das requisições conforme o esperado. Há apenas um número muito pequeno de requisições nos protocolos HTTP/1.0 e HTTP/0.9 mais antigos. Incomodamente, há uma porcentagem maior em que o protocolo não foi mapeado corretamente pelo rastreamento do HTTP Archive, especialmente no desktop. Investigar isso mostrou várias razões, algumas das quais podem ser explicadas e outras não. Com base em verificações pontuais, eles geralmente parecem ser requisições HTTP/1.1 e, presumindo que sejam, o uso de desktop e mobile é semelhante.
Não obstante haja uma porcentagem um pouco maior de ruído do que gostaríamos, isso não altera a mensagem geral transmitida aqui. Fora isso, a semelhança mobile/desktop não é inesperada; Testes do HTTP Archive com Chrome, que oferece suporte a HTTP/2 para desktop e dispositivo móvel. O uso no mundo real pode ter estatísticas ligeiramente diferentes com alguns usos mais antigos de navegadores em ambos, mas mesmo assim o suporte é generalizado, logo, não esperamos uma grande variação entre desktop e mobile.
No momento, o HTTP Archive não rastreia HTTP no QUIC (em breve padronizado como HTTP/3) separadamente, então, essas requisições estão listadas no momento sob HTTP/2, mas veremos outras maneiras de medir isso posteriormente neste capítulo.
Olhar para o número de requisições distorce um pouco os resultados devido a requisições populares. Por exemplo, muitos sites carregam o Google Analytics, que suporta o HTTP/2 e, portanto, seria exibido como uma requisição HTTP/2, mesmo se o próprio site incorporando não oferecer suporte ao HTTP/2. Por outro lado, sites populares que tendem a oferecer suporte a HTTP/2 também são sub-representados nas estatísticas acima, pois são medidos apenas uma vez (por exemplo, “google.com” e “obscuresite.com” recebem pesos iguais). Há mentiras, mentiras tremendas e estatísticas.
No entanto, nossas descobertas são corroboradas por outras fontes, como telemetria da Mozilla, que analisa o uso em cenário real através do navegador Firefox.
| Protocolo | Desktop | Mobile | Ambos |
|---|---|---|---|
| 0.09% | 0.08% | 0.08% | |
| HTTP/1.0 | 0.09% | 0.08% | 0.09% |
| HTTP/1.1 | 62.36% | 63.92% | 63.22% |
| HTTP/2 | 37.46% | 35.92% | 36.61% |
Ainda é interessante olhar as páginas iniciais apenas para obter uma estimativa aproximada do número de sites que suportam HTTP/2 (pelo menos em sua página inicial). A Figura 20.4 mostra menos suporte do que as requisições gerais, conforme esperado, em torno de 36%.
HTTP/2 só é suportado pelos navegadores em HTTPS, embora oficialmente HTTP/2 possa ser usado em HTTPS ou em conexões sem HTTPS, não criptografadas. Conforme mencionado anteriormente, ocultar o novo protocolo em conexões HTTPS criptografadas evita que os dispositivos de rede que não compreendem esse novo protocolo interfiram no (ou rejeitem!) seu uso. Além disso, o handshake executado no HTTPS permite um método fácil do cliente e do servidor concordarem em usar HTTP/2.
| Protocolo | Desktop | Mobile | Ambos |
|---|---|---|---|
| 0.09% | 0.10% | 0.09% | |
| HTTP/1.0 | 0.06% | 0.06% | 0.06% |
| HTTP/1.1 | 45.81% | 44.31% | 45.01% |
| HTTP/2 | 54.04% | 55.53% | 54.83% |
A web está mudando para HTTPS e o HTTP/2 vira de cabeça para baixo o argumento tradicional de que o HTTPS piora o desempenho. Nem todo site fez a transição para HTTPS, portanto, HTTP/2 nem estará disponível para aqueles que não transicionaram. Olhando apenas para os sites que usam HTTPS, na Figura 20.5 vemos uma maior adoção de HTTP/2 em cerca de 55%, semelhante à porcentagem de todas as requisições na Figura 20.2.
Mostramos que o suporte do navegador para HTTP/2 é forte e que há um caminho seguro para a adoção, então por que nem todo site (ou pelo menos todo site HTTPS) suporta HTTP/2? Bem, aqui chegamos ao requisito final para o suporte que ainda não medimos: suporte do servidor.
Isso é mais problemático do que o suporte do navegador, pois, diferente dos navegadores modernos, os servidores geralmente não são atualizados de maneira automática para a versão mais recente. Mesmo quando o servidor passa por manutenção e é corrigido regularmente, isso comumente apenas aplicará as atualizações de segurança em vez de novas funcionalidades como o HTTP/2. Vejamos primeiro os cabeçalhos HTTP no servidor para aqueles sites que oferecem suporte a HTTP/2.
| Servidor | Desktop | Mobile | Ambos |
|---|---|---|---|
| nginx | 34.04% | 32.48% | 33.19% |
| cloudflare | 23.76% | 22.29% | 22.97% |
| Apache | 17.31% | 19.11% | 18.28% |
| 4.56% | 5.13% | 4.87% | |
| LiteSpeed | 4.11% | 4.97% | 4.57% |
| GSE | 2.16% | 3.73% | 3.01% |
| Microsoft-IIS | 3.09% | 2.66% | 2.86% |
| openresty | 2.15% | 2.01% | 2.07% |
| … | … | … | … |
O Nginx fornece repositórios de pacotes que facilitam a instalação ou atualização para a versão mais recente, portanto, não é nenhuma surpresa vê-lo liderando o caminho aqui. Cloudflare é o CDN mais popular e habilita HTTP/2 por padrão, então, novamente, não surpreende ver que hospeda uma grande porcentagem dos sites com HTTP/2. A propósito, a Cloudflare usa uma versão altamente personalizada do nginx como seu servidor web. Depois disso, vemos o Apache com cerca de 20% de uso, seguido por alguns servidores que optam por ocultar o que são, e então os players menores, como LiteSpeed, IIS, Google Servlet Engine e openresty, que é baseado em nginx.
O mais interessante são os servidores que não suportam o HTTP/2:
| Servidor | Desktop | Mobile | Ambos |
|---|---|---|---|
| Apache | 46.76% | 46.84% | 46.80% |
| nginx | 21.12% | 21.33% | 21.24% |
| Microsoft-IIS | 11.30% | 9.60% | 10.36% |
| 7.96% | 7.59% | 7.75% | |
| GSE | 1.90% | 3.84% | 2.98% |
| cloudflare | 2.44% | 2.48% | 2.46% |
| LiteSpeed | 1.02% | 1.63% | 1.36% |
| openresty | 1.22% | 1.36% | 1.30% |
| … | … | … | … |
Parte disso será tráfego sem HTTPS que usaria HTTP/1.1 mesmo que o servidor suportasse HTTP/2, mas um problema maior são aqueles que não suportam HTTP/2 de jeito nenhum. Nesses dados, vemos uma participação muito maior para o Apache e o IIS, que provavelmente estão executando versões mais antigas.
Para o Apache em particular, geralmente não é fácil adicionar suporte ao HTTP/2 a uma instalação existente, já que o Apache não fornece um repositório oficial para instalar a partir dele. Isso usualmente significa recorrer à compilação da fonte ou confiar em um repositório de terceiros, nenhum dos quais é particularmente atraente para muitos administradores.
Apenas as versões mais recentes de distribuições Linux (RHEL e CentOS 8, Ubuntu 18 e Debian 9) vêm com uma versão do Apache que suporta HTTP/2, e muitos servidores ainda não estão rodando nelas. No lado da Microsoft, apenas o Windows Server 2016 e superior oferecem suporte a HTTP/2, portanto, novamente aqueles que rodam versões mais antigas não oferecem suporte ao protocolo no IIS.
Mesclando essas duas estatísticas, podemos ver a porcentagem de instalações por servidor, que usam HTTP/2:
| Servidor | Desktop | Mobile |
|---|---|---|
| cloudflare | 85.40% | 83.46% |
| LiteSpeed | 70.80% | 63.08% |
| openresty | 51.41% | 45.24% |
| nginx | 49.23% | 46.19% |
| GSE | 40.54% | 35.25% |
| 25.57% | 27.49% | |
| Apache | 18.09% | 18.56% |
| Microsoft-IIS | 14.10% | 13.47% |
| … | … | … |
É claro que o Apache e o IIS ficam para trás com 18% e 14%, respectivamente, sobre seu suporte na instalação com base em HTTP/2, o que deve ser (ao em parte) uma consequência de ser mais difícil atualizá-los. Frequentemente, é necessária uma atualização completa do sistema operacional no caso de vários servidores para conseguir esse suporte facilmente. Com sorte, isso se tornará mais fácil à medida que as novas versões de sistemas operacionais se tornarem regra.
Nada disso é um comentário sobre as implementações HTTP/2 aqui (acho que o Apache tem uma das melhores implementações), mas mais sobre a facilidade de habilitar o HTTP/2 em cada um desses servidores — ou a falta dela.
Impacto do HTTP/2
O impacto do HTTP/2 é muito mais difícil de medir, especialmente usando o HTTP Archive metodologia. Idealmente, os sites seriam rastreados com ambos HTTP/1.1 e HTTP/2 e a diferença medida, mas isso não é possível com as estatísticas que estamos investigando aqui. Além disso, medir se o site com HTTP/2 médio é mais rápido do que o site com HTTP/1.1 médio apresenta muitas outras variáveis que requerem um estudo mais exaustivo do que podemos cobrir aqui.
Um impacto que pode ser medido é a mudança no uso de HTTP, agora que estamos em um mundo do HTTP/2. Várias conexões eram uma solução alternativa com o HTTP/1.1 para permitir uma forma limitada de paralelização, mas isso é na verdade o oposto do que geralmente funciona melhor com HTTP/2. Uma única conexão reduz a sobrecarga da configuração do TCP, a inicialização lenta do TCP e a negociação HTTPS, além de permitir o potencial de priorização de requisições cruzadas.
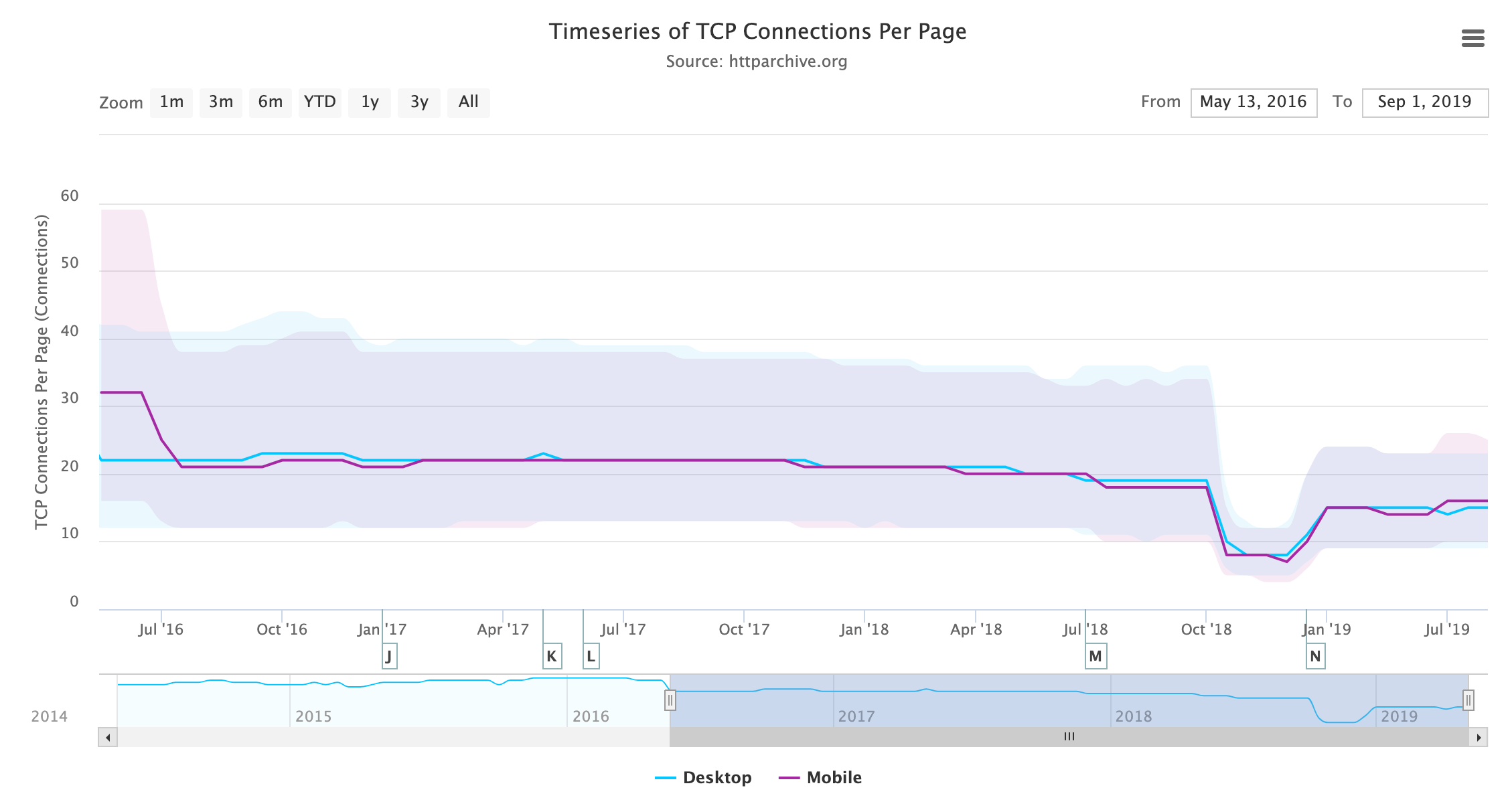
O HTTP Archive mede o número de conexões TCP por página, e isso está caindo constantemente à medida que mais sites suportam HTTP/2 e usam sua única conexão em vez de seis conexões separadas.
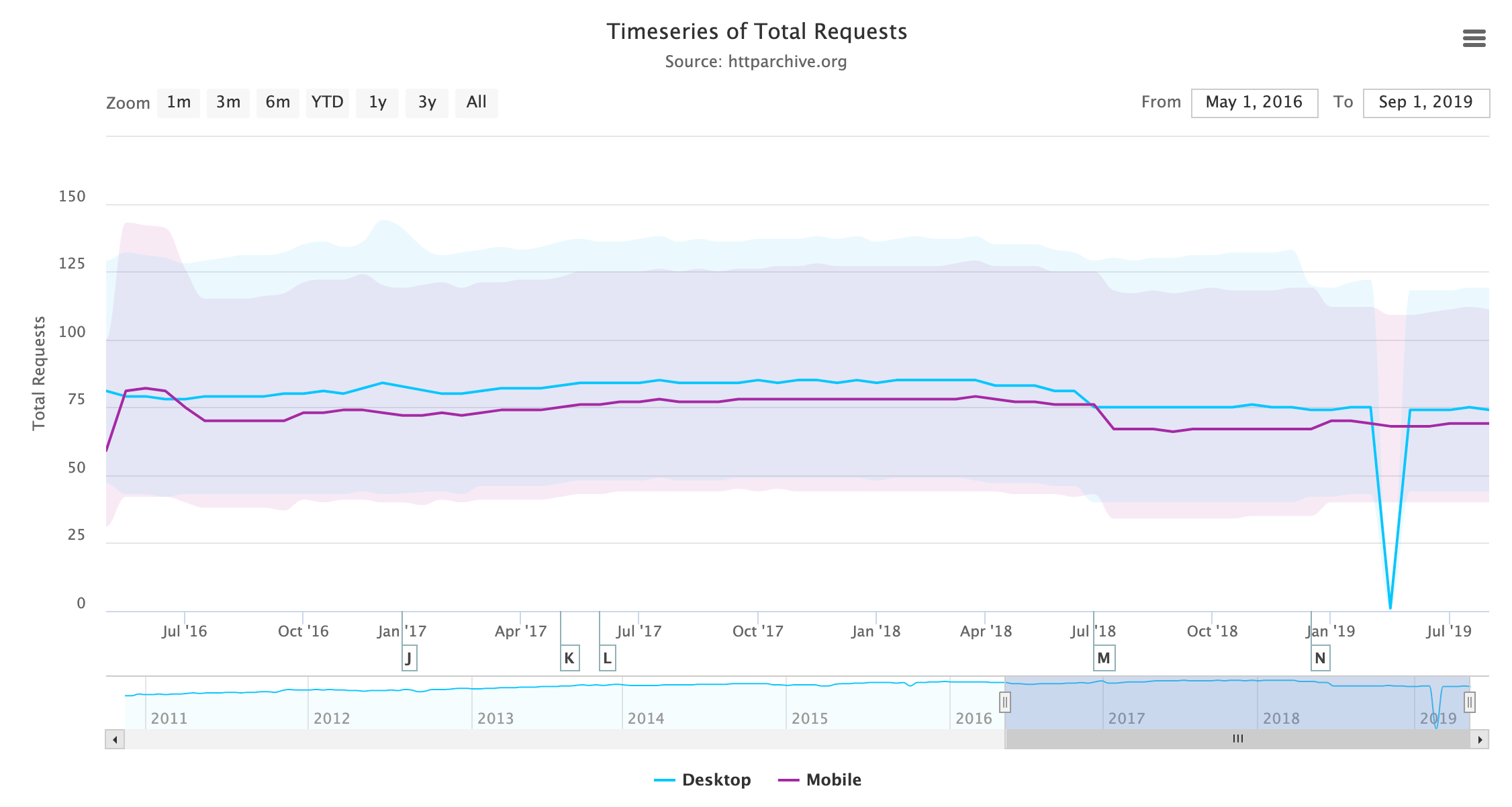
O agrupamento (e minificação) de recursos para obter menos requisições era outra solução alternativa do HTTP/1.1 que tinha muitos nomes: agrupamento, concatenação, empacotamento, spriting etc. Isso é menos necessário ao usar HTTP/2, pois há menos sobrecarga com requisições, mas deve ser observado que as requisições não são gratuitas em HTTP/2 e aqueles que experimentaram remover o agrupamento completamente notaram uma perda de desempenho. Observando o número de requisições carregadas por página ao longo do tempo, vemos uma ligeira queda, em vez do aumento esperado.
Essa baixa taxa de mudança pode talvez ser atribuída às observações mencionadas acima de que o agrupamento não pode ser removido (pelo menos, não completamente) sem um impacto negativo na performance e que muitas ferramentas de compilação atualmente agrupam por motivos históricos com base nas recomendações ao HTTP/1.1. Também é provável que muitos sites não estejam dispostos a penalizar os usuários do HTTP/1.1 desfazendo suas adaptações de desempenho do HTTP/1.1 ainda, ou pelo menos que eles não tenham a confiança (ou tempo!) pra sentir que isso vale a pena.
O fato do número de requisições permanecer praticamente estático é interessante, dado o peso da página sempre crescente, embora talvez isso não esteja totalmente relacionado ao HTTP/2.
HTTP/2 Push
O processo de HTTP/2 push tem uma história mista, apesar de ser uma funcionalidade nova muito elogiada do HTTP/2. Os outros recursos eram basicamente melhorias de desempenho sob o capô, mas o push era um conceito totalmente novo que quebrou completamente a natureza de requisição única para resposta única do HTTP. Isso permitiu que respostas extras fossem retornadas; quando você pedisse pela página web, o servidor poderia responder com a página HTML como de costume, mas também enviá-lo o CSS e o JavaScript críticos, evitando assim quaisquer viagens de ida e volta adicionais para determinados recursos. Teoricamente, isso nos permitiria parar de inserir CSS e JavaScript diretamente no HTML e ainda obter os mesmos ganhos de desempenho de fazê-lo. Resolver isso, poderia depois levar a todos os tipos de casos de uso novos e interessantes.
A realidade tem sido, bem, um pouco decepcionante. O HTTP/2 push provou ser muito mais difícil de usar de maneira efetiva do que o previsto originalmente. Parte disso foi atribuído à complexidade de como o HTTP/2 push funciona e aos problemas de implementação devido a isso.
Uma preocupação maior é que o push pode facilmente causar, em vez de resolver, problemas de desempenho. O excesso de push é um risco real. Frequentemente, o navegador está no melhor lugar para decidir o que solicitar, e tão crucialmente quando solicitá-lo, mas o HTTP/2 push coloca essa responsabilidade no servidor. Enviar recursos que um navegador já possui em seu cache é um desperdício de largura de banda (embora, em minha opinião, igualmente seja incluir CSS diretamente no HTML, mas isso é menos difícil do que o HTTP/2 push!).
As propostas de informar o servidor sobre o status do cache do navegador foram bloqueadas especialmente em questões de privacidade. Mesmo sem esse problema, existem outros problemas potenciais se o push não for usado corretamente. Por exemplo, enviar imagens grandes e, portanto, impedir o envio de CSS e JavaScript essenciais levará a sites mais lentos do que se você nem tivesse feito push!
Também há muito pouca evidência até o momento de que o push, mesmo quando implementado corretamente, resulta no aumento de desempenho prometido. Esta é uma área em que, novamente, o HTTP Archive não está na melhor posição para responder, devido à natureza de como ele é executado (um rastreamento de sites populares usando o Chrome em um estado), então não vamos nos aprofundar muito aqui. No entanto, basta dizer que os ganhos de performance estão longe de ser claros e os problemas potenciais são reais.
Deixando isso de lado, vamos analisar o uso do HTTP/2 push.
| Cliente | Sites Usando o HTTP/2 Push | Sites Usando o HTTP/2 Push (%) |
|---|---|---|
| Desktop | 22,581 | 0.52% |
| Mobile | 31,452 | 0.59% |
| Cliente | Méd. de Requisições Enviadas | Méd. de KB Enviados |
|---|---|---|
| Desktop | 7.86 | 162.38 |
| Mobile | 6.35 | 122.78 |
Essas estatísticas mostram que a aceitação do HTTP/2 push é muito baixa, provavelmente por causa dos problemas descritos anteriormente. No entanto, quando os sites usam push, eles tendem a usá-lo bastante, em vez de para um ou recursos, conforme mostrado na Figura 20.12.
Essa é uma preocupação, pois o conselho anterior era ser conservador com o push e “enviar apenas recursos suficientes para preencher o tempo de rede ocioso e nada mais”. As estatísticas acima sugerem que muitos recursos de um tamanho combinado significativo são enviados.
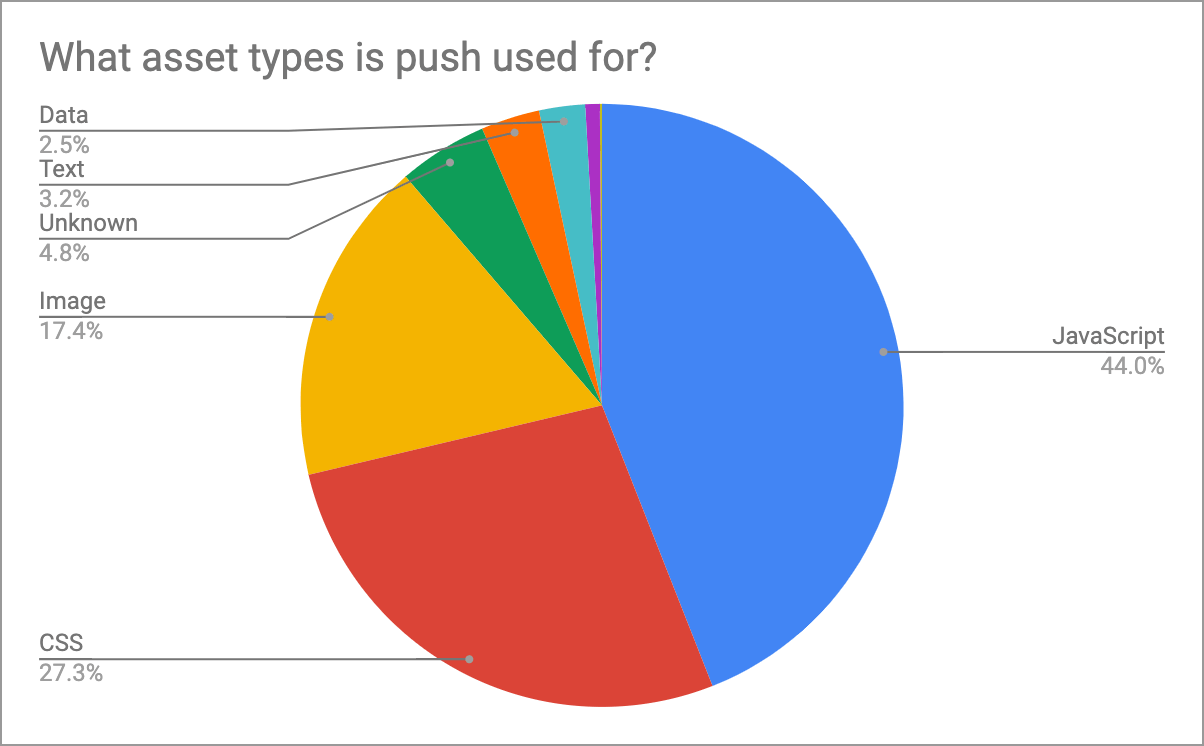
A Figura 20.13 nos mostra quais recursos são mais comumente enviados. JavaScript e CSS são a esmagadora maioria dos itens enviados, tanto por volume quanto por bytes. Depois disso, há uma variedade de imagens, fontes e dados. No final, vemos cerca de 100 sites enviando vídeo, o que pode ser intencional ou pode ser um sinal de excesso de envio dos tipos de recurso errados!
Uma preocupação levantada por alguns é que as implementações HTTP/2 redesignaram o link do cabeçalho preload do HTTP como um sinal para o push. Um dos usos mais populares da dica de recurso preload é informar o navegador sobre recursos descobertos posteriormente, como fontes e imagens, que o navegador não perceberá até que o CSS tenha sido solicitado, baixado e analisado. Se agora eles são enviados com base nesse cabeçalho, havia uma preocupação de que reutilizá-los poderia resultar em muitos envios indesejados.
No entanto, o uso relativamente baixo de fontes e imagens pode significar que o risco não está sendo percebido tanto quanto se temia. As tags <link rel="preload"...> são comumente usadas no HTML ao invés dos cabeçalhos link no HTTP e as meta tags não são um sinal de envio. As estatísticas no capítulo de Sugestão de Recursos mostram que menos de 1% dos sites usam o cabeçalho link do HTTP pré-carregado e aproximadamente a mesma quantidade usam pré-conexão, que não tem significado algum no HTTP/2, portanto, isso sugeriria que não é tanto um problema. Embora haja uma número de fontes e outros recursos sendo enviados, o que pode ser um sinal disso.
Como um contra argumento a essas reclamações, se um recurso é importante o suficiente para pré-carregar, então pode-se argumentar que esses recursos devem ser enviados se possível, já que os navegadores tratam uma sugestão de pré-carregamento como requisições de prioridade muito alta de qualquer forma. Qualquer preocupação com o desempenho é, portanto (mais uma vez, sem dúvida), no uso excessivo do pré-carregamento, em vez do HTTP/2 push que resulta disso.
Para contornar esse push não intencional, você pode fornecer o atributo nopush em seu cabeçalho de pré-carregamento:
link: </assets/jquery.js>; rel=preload; as=script; nopush5% dos cabeçalhos HTTP pré-carregados usam esse atributo, que é maior do que eu esperava, pois consideraria isso uma otimização de nicho. Então, novamente, também é o uso de cabeçalhos HTTP pré-carregados e/ou HTTP/2 push em si!
Problemas do HTTP/2
O HTTP/2 é principalmente parte de uma atualização contínua que, uma vez que seu servidor suporte, você pode fazer uso sem a necessidade de alterar seu site ou aplicativo. Você pode otimizar para HTTP/2 ou parar de usar as soluções alternativas do HTTP/1.1, mas em geral, um site normalmente funcionará sem a necessidade de nenhuma alteração — será apenas mais rápido. Entretanto, existem algumas pegadinhas de que você deve ter ciência, que podem afetar qualquer atualização, e alguns sites descobriram isso da maneira mais difícil.
Uma das causas de problemas no HTTP/2 é o suporte insuficiente para a priorização do HTTP/2. Este recurso permite que múltiplas requisições em andamento façam o uso apropriado da conexão. Isso é especialmente importante por que o HTTP/2 aumentou enormemente o número de requisições que podem ser executadas na mesma conexão. Ter 100 ou 128 como limites de requisição paralela são comuns em implementações de servidor. Anteriormente, o navegador tinha no máximo seis conexões por domínio e, portanto, usava sua habilidade e julgamento para decidir a como melhor usar essas conexões. Agora, raramente precisa fazer fila e pode enviar todas as requisições assim que as reconhece delas. Isso pode fazer com que a largura de banda seja “desperdiçada” em requisições de prioridade mais baixa, enquanto requisições críticas são atrasadas (e, incidentalmente, também podem levar a sobrecarga do seu servidor de back-end com mais requisições que o usado!).
O HTTP/2 tem um modelo de priorização complexo (muitos dizem que é demasiado complexo — daí por que está sendo reconsiderado para o HTTP/3!), porém, poucos servidores o empregam adequadamente. Isso pode ser porque suas implementações do HTTP/2 não estão à altura ou por causa do chamado bufferbloat, em que as respostas já estão a caminho antes que o servidor perceba que há uma requisição de prioridade mais alta. Devido à natureza variável dos servidores, pilhas TCP e localizações, é difícil medir isso para a maioria dos sites, mas com CDNs isso deve ser mais consistente.
Patrick Meenan criou uma página de teste de exemplo, que deliberadamente tenta baixar uma carga de recursos de baixa prioridade, imagens fora do foco da tela, antes de fazer a requisição de algumas imagens de alta prioridade, na tela. Um bom servidor HTTP/2 deve ser capaz de reconhecer isso e enviar as imagens de alta prioridade logo após solicitadas, às custas das imagens de baixa prioridade. Um servidor HTTP/2 ruim apenas responderá na ordem de requisição e ignorará quaisquer sinais de prioridade. Andy Davies tem uma página rastreando o status de vários CDNs para o teste de Patrick. O HTTP Archive identifica quando um CDN é usado como parte do seu rastreamento e a fusão desses dois conjuntos de dados pode nos dizer a porcentagem de páginas que usam um CDN aprovado ou com falha.
| CDN | Prioriza Corretamente? | Desktop | Mobile | Ambos |
|---|---|---|---|---|
| Sem uso de CDN | Desconhecido | 57.81% | 60.41% | 59.21% |
| Cloudflare | Passa | 23.15% | 21.77% | 22.40% |
| Falha | 6.67% | 7.11% | 6.90% | |
| Amazon CloudFront | Falha | 2.83% | 2.38% | 2.59% |
| Fastly | Passa | 2.40% | 1.77% | 2.06% |
| Akamai | Passa | 1.79% | 1.50% | 1.64% |
| Desconhecido | 1.32% | 1.58% | 1.46% | |
| WordPress | Passa | 1.12% | 0.99% | 1.05% |
| Sucuri Firewall | Falha | 0.88% | 0.75% | 0.81% |
| Incapsula | Falha | 0.39% | 0.34% | 0.36% |
| Netlify | Falha | 0.23% | 0.15% | 0.19% |
| OVH CDN | Desconhecido | 0.19% | 0.18% | 0.18% |
A Figura 20.14 mostra que uma parte bastante significativa do tráfego está sujeita ao problema identificado, totalizando 26,82% em desktop e 27,83% em dispositivos móveis. O quão problemático isso é depende exatamente de como a página é carregada e se os recursos de alta prioridade são descobertos tardiamente ou não para os sites afetados.
Outro problema é com o cabeçalho upgrade do HTTP sendo usado incorretamente. Os servidores web podem responder às requisições com um cabeçalho upgrade, sugerindo que ele suporta um protocolo melhor que o cliente pode desejar usar (por exemplo, indicar HTTP/2 para um cliente usando apenas HTTP/1.1). Você pode pensar que isso seria útil como um método de informar ao navegador que um servidor suporta HTTP/2, mas como os navegadores só suportam HTTP/2 sobre HTTPS e como o uso de HTTP/2 pode ser negociado por meio do handshake do HTTPS, o uso do cabeçalho upgrade para anunciar o HTTP/2 é bastante limitado (para navegadores, pelo menos).
Pior do que isso, é quando um servidor envia um cabeçalho upgrade com erro. Isso pode ocorrer porque um servidor de back-end com suporte a HTTP/2 está enviando o cabeçalho e, em seguida, um servidor de borda com suporte apenas para HTTP/1.1 o está encaminhando cegamente ao cliente. O Apache emite o cabeçalho upgrade quando mod_http2 está habilitado e o HTTP/2 não está sendo usado, e uma instância nginx colocada na frente de tal instância Apache felizmente encaminha este cabeçalho mesmo quando o nginx não suporta HTTP/2. Essa propaganda enganosa, então, leva os clientes a tentar (sem sucesso!) usar HTTP/2 conforme recomendado.
108 sites usam HTTP/2, embora também sugiram a atualização para HTTP/2 no cabeçalho upgrade. Outros 12.767 sites no desktop (15.235 em dispositivos móveis) sugerem atualizar uma conexão HTTP/1.1 entregue por HTTPS para HTTP/2 quando está claro que não estava disponível, ou já teria sido usado. Essa é uma pequena minoria dos 4,3 milhões de sites rastreados em desktop e 5,3 milhões de sites rastreados em dispositivos móveis, mas mostra que esse ainda é um problema que afeta vários sites por aí. Os navegadores lidam com isso de maneira inconsistente, com o Safari em particular tentando atualizar e, em seguida, se metendo em uma bagunça e se recusando de vez a exibir o site.
Tudo isso antes de entrarmos nos poucos sites que recomendam a atualização para http1.0, http://1.1, ou mesmo -all,+TLSv1.3,+TLSv1.2. Existem claramente alguns erros de digitação nas configurações do servidor web acontecendo aqui!
Existem outros problemas além de implementação que podemos analisar. Por exemplo, HTTP/2 é muito mais restrito sobre os nomes de cabeçalho HTTP, rejeitando a requisição inteira se você responder com espaços, dois pontos ou outros nomes de cabeçalho HTTP inválidos. Os nomes de cabeçalho também são convertidos em letras minúsculas, o que pega alguns de surpresa se sua aplicação assumir certa capitalização. Isso nunca foi garantido anteriormente, já que o HTTP/1.1 afirma especificamente que os nomes dos cabeçalhos não diferenciam maiúsculas de minúsculas, mas ainda assim alguns dependeram disso. O HTTP Archive também pode ser usado para identificar esses problemas, embora alguns deles não sejam aparentes na página inicial, mas não nos aprofundamos nisso este ano.
HTTP/3
O mundo não para e, apesar do HTTP/2 não ter sequer completado seu quinto aniversário, as pessoas já o estão vendo como uma notícia velha e ficando mais entusiasmadas com seu sucessor, o HTTP/3. O HTTP/3 baseia-se nos conceitos do HTTP/2, mas vai do trabalho sobre conexões TCP que o HTTP sempre usou para um protocolo baseado em UDP chamado QUIC. Isso nos permite corrigir um caso em que o HTTP/2 é mais lento que o HTTP/1.1, quando há uma grande perda de pacotes e a natureza garantidora do TCP retém e restringe todos os fluxos. Também nos permite abordar algumas ineficiências do TCP e do HTTPS, como a consolidação em um só handshake para ambos e o suporte a muitas ideias para TCP que se mostraram difíceis de implementar na vida real (TCP fast open, 0-RTT, etc.).
O HTTP/3 também elimina algumas sobreposições entre o TCP e o HTTP/2 (por exemplo, controle de fluxo sendo implementado em ambas as camadas), mas conceitualmente é muito semelhante a HTTP/2. Os desenvolvedores web que entendem e otimizam soluções para HTTP/2 não devem fazer mais alterações para HTTP/3. No entanto, operadores de servidor terão mais trabalho a fazer já que as diferenças entre TCP e QUIC são bem mais inovadoras. Elas tornarão a implementação mais difícil, de modo que o lançamento de HTTP/3 pode demorar consideravelmente mais do que HTTP/2 e, inicialmente, ser limitado àqueles com certa experiência no campo, como os CDNs.
O QUIC foi implementado pela Google por vários anos e agora está passando por um processo de padronização semelhante ao que o SPDY fez em seu caminho para HTTP/2. O QUIC tem ambições além de apenas HTTP, mas é o caso de uso que sendo trabalhado atualmente. Quando este capítulo estava sendo escrito, Cloudflare, Chrome e Firefox anunciaram suporte ao HTTP/3, apesar do fato de que o HTTP/3 ainda não está formalmente completo ou aprovado como padrão. Isso é bem-vindo, pois estava faltando suporte ao QUIC fora da Google até recentemente e definitivamente fica atrás do suporte a SPDY e HTTP/2 de um estágio semelhante de padronização.
Como o HTTP/3 usa QUIC sobre UDP em vez de TCP, ele torna a descoberta do suporte HTTP/3 um desafio maior do que a descoberta para o HTTP/2. Com HTTP/2, podemos usar principalmente o handshake do HTTPS, mas como o HTTP/3 está em uma conexão completamente diferente, que essa não é uma opção aqui. HTTP/2 também usa o cabeçalho HTTP upgrade para informar ao navegador sobre o suporte HTTP/2, e embora isso não seja tão útil para HTTP/2, um mecanismo semelhante foi colocado em prática para QUIC que é mais útil. O cabeçalho alternative services (serviços alternativos) do HTTP (alt-svc) anuncia protocolos alternativos que podem ser usados em conexões completamente diferentes, ao contrário de protocolos alternativos que podem ser usados nesta conexão, que é para o que o cabeçalho upgrade do HTTP é usado.
A análise desse cabeçalho mostra que 7,67% dos sites em desktop e 8,38% dos sites em dispositivos móveis já suportam QUIC, o que representa aproximadamente a porcentagem de tráfego do Google, o que não é novidade, já que ele vem usando isso há algum tempo. E 0,04% já suportam HTTP/3. Eu imagino que até o Web Almanac do próximo ano, esse número terá aumentado significativamente.
Conclusão
Esta análise das estatísticas disponíveis no projeto HTTP Archive mostrou o que muitos de nós na comunidade HTTP já sabíamos: o HTTP/2 está aqui e está provando ser muito popular. Já é o protocolo dominante em termos de número de requisições, mas ainda não superou o HTTP/1.1 em termos de número de sites que o suportam. A extensão da internet significa que muitas vezes leva um tempo exponencialmente mais longo para obter ganhos perceptíveis nos sites menos bem mantidos do que nos sites mais reconhecidos e de alto volume.
Também falamos sobre como (ainda!) não é fácil conseguir suporte ao HTTP/2 em algumas instalações. Desenvolvedores de servidores, distribuidores de sistemas operacionais e clientes finais, todos têm um papel a desempenhar para tornar isso mais fácil. Atrelar software a sistemas operacionais sempre aumenta o tempo de implantação. De fato, um dos principais motivos a favor o QUIC é quebrar uma barreira similar com a implantação de alterações do TCP. Em muitos casos, não há razão real para vincular as versões do servidor web aos sistemas operacionais. O Apache (para usar um dos exemplos mais populares) rodará com suporte a HTTP/2 em sistemas operacionais mais antigos, mas obter uma versão atualizada no servidor não deve exigir a experiência ou o risco que exige atualmente. O Nginx se sai muito bem aqui, hospedando repositórios para as distribuições comuns de Linux para tornar a instalação mais fácil, e se a equipe do Apache (ou os fornecedores de distribuição Linux) não oferecerem algo semelhante, então eu só posso ver o uso do Apache continuando a diminuir enquanto luta para manter a relevância e mudar sua reputação de ser antigo e lento (com base em instalações mais antigas), embora as versões atualizadas tenham uma das melhores implementações do HTTP/2. Eu vejo isso como um problema menor para o IIS, já que geralmente é o servidor web preferido no lado do Windows.
Fora isso, o HTTP/2 tem sido um caminho de atualização relativamente fácil, e é por isso que teve a forte aceitação que já viu. Para a maior parte, é uma ativação fácil e, portanto, para a maioria, revelou-se um aumento de desempenho descomplicado que requer pouca reflexão, uma vez que seu servidor ofereça suporte. Contudo, o diabo está nos detalhes (como sempre), e pequenas diferenças entre as implementações de servidor podem resultar em melhor ou pior uso do HTTP/2 e, em última análise, na experiência do usuário final. Também houve uma série de bugs e até mesmo problemas de segurança, como deve ser esperado com qualquer protocolo novo.
Garantir que você esteja usando uma implementação forte, atualizada e bem mantida de qualquer protocolo novato, como o HTTP/2, garantirá que você fique atento a esses problemas. No entanto, isso pode exigir experiência e gerenciamento. A implementação do QUIC e do HTTP/3 provavelmente será ainda mais complicada e exigirá mais experiência. Talvez seja melhor deixar isso para provedores de serviços terceirizados, como CDNs, que têm esse conhecimento e podem fornecer ao seu site acesso fácil a esses recursos. Entretanto, mesmo quando deixado para os especialistas, não há garantia (como mostram as estatísticas de priorização), mas se você escolher seu provedor de servidor com sabedoria e se envolver com eles sobre quais são suas prioridades, a implementação deve ser mais fácil.
Por falar nisso, seria ótimo se os CDNs priorizassem esses problemas (trocadilho definitivamente intencional!), embora eu suspeite que com o advento de um novo método de priorização no HTTP/3, muitos vão segurar firme. O próximo ano será uma época ainda mais interessante no mundo do HTTP.
