SEO
Introduzione
Search Engine Optimization (SEO) è la pratica per ottimizzare la configurazione tecnica dei siti Web, la pertinenza dei contenuti e la popolarità dei link per rendere le loro informazioni facilmente reperibili e più pertinenti per soddisfare le esigenze di ricerca degli utenti. Di conseguenza, i siti web migliorano la loro visibilità nei risultati dei motori di ricerca per le query pertinenti degli utenti riguardanti i loro contenuti e la loro attività, aumentando il loro traffico, conversioni e profitti.
Nonostante la sua complessa natura multidisciplinare, negli ultimi anni il SEO si è evoluta fino a diventare una delle strategie e dei canali di marketing digitale più popolari.
L’obiettivo del capitolo SEO di Web Almanac è identificare e valutare gli elementi e le configurazioni principali che giocano un ruolo nell’ottimizzazione della ricerca organica di un sito web. Identificando questi elementi, speriamo che i siti web possano sfruttare i nostri risultati per migliorare la loro capacità di essere scansionati, indicizzati e classificati dai motori di ricerca. In questo capitolo, forniamo un’istantanea del loro stato nel 2020 e un riepilogo di ciò che è cambiato dal 2019.
È importante notare che questo capitolo si basa sull’analisi di Lighthouse sui siti per dispositivi mobile, sul rapporto sull’esperienza utente di Chrome su dispositivi mobile e desktop, nonché elementi HTML non elaborati e visualizzati dall’HTTP Archive su dispositivi mobile e desktop. Nel caso di HTTP Archive e Lighthouse, è limitato ai dati identificati solo dalle home page dei siti Web, non alle scansioni a livello di sito. Ne abbiamo tenuto conto durante le valutazioni. Questa distinzione è importante quando si traggono conclusioni dai nostri risultati. Puoi saperne di più sulla nostra pagina Metodologia.
Esaminiamo i risultati principali dell’ottimizzazione della ricerca organica di quest’anno.
Fondamenti
Questa sezione presenta i risultati relativi all’ottimizzazione delle configurazioni Web e degli elementi che costituiscono la base per i motori di ricerca per eseguire correttamente la scansione, l’indicizzazione e il posizionamento dei siti Web per fornire agli utenti i migliori risultati per le loro query.
Scansione e indicizzabilità
I motori di ricerca utilizzano web crawler (chiamati anche spider) per scoprire contenuti nuovi o aggiornati da siti web, navigando sul web seguendo i link tra le pagine. La scansione è il processo di ricerca di contenuti web nuovi o aggiornati (siano essi pagine web, immagini, video, ecc.).
I crawler scoprono i contenuti seguendo i link tra gli URL, nonché utilizzando fonti aggiuntive che i proprietari di siti web possono fornire, come la generazione di sitemap XML, che sono elenchi di URL che il proprietario di un sito web desidera che i motori di ricerca indicizzino o tramite richieste di scansione dirette tramite strumenti dei motori di ricerca, come la Search Console di Google.
Una volta che i motori di ricerca accedono ai contenuti web, devono eseguire il render, in modo simile a quello che fanno i browser web, e indicizzarli. I motori di ricerca analizzeranno e catalogheranno le informazioni identificate, cercando di comprenderle come fanno gli utenti, per poi memorizzarle nel loro indice, o database web.
Quando gli utenti inseriscono una query, i motori di ricerca eseguono una ricerca nel loro indice per trovare il contenuto migliore da visualizzare nelle pagine dei risultati di ricerca per rispondere alle loro domande, utilizzando una varietà di fattori per determinare quali pagine vengono visualizzate prima delle altre.
Per i siti web che cercano di ottimizzare la loro visibilità nei risultati di ricerca, è importante seguire alcune best practice di crawlability e indicizzabilità: configurazione corretta di robots.txt, tag robots meta, intestazioni HTTP X-Robots-Tag e tag canonici, tra gli altri. Queste best practice aiutano i motori di ricerca ad accedere più facilmente ai contenuti web e a indicizzarli in modo più accurato. Un’analisi approfondita di queste configurazioni è fornita nelle sezioni seguenti.
robots.txt
Situato alla radice di un sito, un file robots.txt è uno strumento efficace per controllare con quali pagine deve interagire un crawler del motore di ricerca, quanto velocemente scansionarle e cosa fare con il contenuto scoperto.
Google ha formalmente proposto di rendere robots.txt uno standard Internet ufficiale nel 2019. La bozza di giugno 2020 include una chiara documentazione sui requisiti tecnici per il file robots.txt. Ciò ha richiesto informazioni più dettagliate su come i crawler dei motori di ricerca dovrebbero rispondere a contenuti non standard.
Un file robots.txt deve essere di testo normale, codificato in UTF-8 e rispondere alle richieste con un codice di stato HTTP 200. Un robots.txt non valido, una risposta 4XX (errore del client) o più di cinque reindirizzamenti vengono interpretati dai crawler dei motori di ricerca come full allow, il che significa che tutti i contenuti possono essere sottoposti a scansione. Una risposta 5XX (errore del server) è intesa come full disallow, il che significa che nessun contenuto può essere sottoposto a scansione. Se il file robots.txt è irraggiungibile per più di 30 giorni, Google ne utilizzerà l’ultima copia memorizzata nella cache, come descritto nelle loro specifiche.
Complessivamente, l’80.46% delle pagine per dispositivi mobile ha risposto a robots.txt con una risposta 2XX. Di questi, il 25.09% non è stato riconosciuto valido. Questo è leggermente migliorato rispetto al 2019, quando è stato rilevato che 27.84% dei siti per dispositivi mobile aveva un robots.txt valido.
Lighthouse, la fonte di dati per testare la validità di robots.txt, ha introdotto un robots.txt audit come parte dell’aggiornamento v6. Questa inclusione evidenzia che una richiesta risolta con successo non significa che il file caposaldo sarà in grado di fornire le direttive necessarie ai web crawler.
| Codice di risposta | Mobile | Desktop |
|---|---|---|
| 2XX | 80.46% | 79.59% |
| 3XX | 0.01% | 0.01% |
| 4XX | 17.67% | 18.64% |
| 5XX | 0.15% | 0.12% |
| 6XX | 0.00% | 0.00% |
| 7XX | 0.15% | 0.12% |
robots.txt .
Oltre al comportamento del codice di stato simile, l’uso dell’istruzione Disallow era coerente tra le versioni mobile e desktop dei file robots.txt.
La dichiarazione User-agent più diffusa era il carattere jolly, User-agent: *, che appariva sul 74.40% delle richieste di dispositivi mobile e sul 73.16% delle richieste desktop robots.txt. La seconda dichiarazione più diffusa è stata adsbot-google, che compare nel 5.63% delle richieste di dispositivi mobile e nel 5.68% delle richieste desktop robots.txt. Google AdsBot ignora le dichiarazioni con caratteri jolly e deve essere denominato in modo specifico poiché il bot controlla la qualità della pagina web e dell’annuncio dell’app sui dispositivi.
Le direttive utilizzate più di frequente si concentrano sui motori di ricerca e sulle loro controparti di marketing a pagamento. Gli strumenti SEO Ahref e Majestic erano tra le prime cinque dichiarazioni Disallow per entrambi i dispositivi.
% di robots.txt |
||
|---|---|---|
User-agent |
Mobile | Desktop |
* |
74.40% | 73.16% |
| adsbot-google | 5.63% | 5.68% |
| mediapartners-google | 5.55% | 3.83% |
| mj12bot | 5.49% | 5.30% |
| ahrefsbot | 4.80% | 4.66% |
robots.txt User-agent.
Analizzando l’utilizzo dell’istruzione Disallow in robots.txt utilizzando i dati di oltre 6 milioni di siti basati su Lighthouse, si è riscontrato che il 97.84% di essi era completamente sottoponibile a scansione, con solo l’1.05% che utilizzava un’istruzione Disallow.
È stata eseguita anche un’analisi dell’utilizzo dell’istruzione robots.txt Disallow lungo le direttive meta robots indexability, trovando l’1.02% dei siti tra cui un’istruzione Disallow lungo le pagine indicizzabili con una direttiva meta robots index, con solo lo 0.03% dei siti che utilizza l’istruzione Disallow in robots.txt lungo le pagine noindexed tramite la direttiva meta robots noindex.
L’utilizzo maggiore dell’istruzione Disallow sulle pagine indicizzabili rispetto a quelle noindexed è notevole poiché la documentazione di Google afferma che i proprietari dei siti non dovrebbero utilizzare robots.txt come mezzo per nascondere le pagine web dalla Google Search, poiché il collegamento interno con testo descrittivo potrebbe comportare l’indicizzazione della pagina senza che un crawler visiti la pagina. Invece, i proprietari dei siti dovrebbero usare altri metodi, come una direttiva noindex tramite meta robots.
I Meta robot
Il meta tag robots e l’intestazione HTTP X-Robots-Tag sono un’estensione del proposto Robots Exclusion Protocol (REP), che consente di configurare le direttive a un livello più granulare. Il supporto della direttiva varia a seconda del motore di ricerca poiché REP non è ancora uno standard Internet ufficiale.
I metatag erano il metodo dominante di esecuzione granulare con il 27.70% delle pagine desktop e il 27.96% delle pagine mobile che utilizzavano il tag. Le direttive X-Robots-Tag sono state trovate rispettivamente sullo 0.27% e sullo 0.40% di desktop e dispositivi mobile.
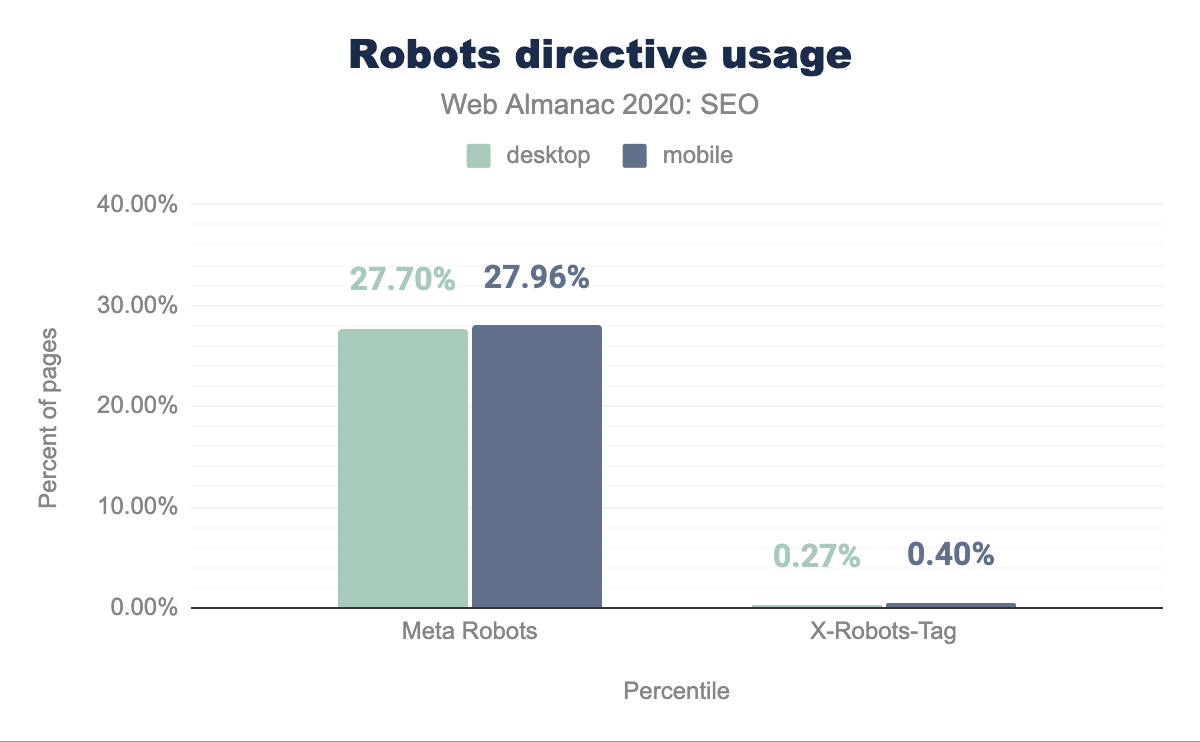
X-Robots-Tag.
Durante l’analisi dell’utilizzo del meta tag robots nei test di Lighthouse, lo 0.47% delle pagine sottoponibili a scansione risulta essere noindexed. Lo 0.44% di queste pagine utilizzava una direttiva noindex e non impediva la scansione della pagina nel file robots.txt.
La combinazione di Disallow all’interno della direttiva robots.txt e noindex nei meta robots è stata trovata solo nello 0.03% delle pagine. Sebbene questo metodo offra la ridondanza di belt e suspenders, una pagina non deve essere bloccata da un file robots.txt affinché una direttiva noindex sulla pagina sia efficace.
È interessante notare che il rendering ha modificato il tag meta robots nello 0.16% delle pagine. Sebbene non vi siano problemi intrinseci con l’utilizzo di JavaScript per aggiungere un meta tag robots a una pagina o modificarne il contenuto, i SEO dovrebbero essere giudiziosi nell’esecuzione. Se una pagina viene caricata con una direttiva noindex nel tag meta robots prima del rendering, i motori di ricerca non eseguiranno il JavaScript che modifica il valore del tag o indicizza la pagina.
Canonicalizzazione
I tag canonici, come descritto da Google, vengono utilizzati per specificare ai motori di ricerca qual è la versione preferita dell’URL canonico per l’indice e ranking per una pagina, quella che è considerata meglio rappresentativa di essa, quando ci sono molti URL che presentano contenuti uguali o molto simili. È importante notare che:
- La configurazione del tag canonico viene utilizzata insieme ad altri segnali per selezionare l’URL canonico di una pagina; non è l’unico.
- Sebbene a volte vengano utilizzati tag canonici autoreferenziali, questi tag non sono un requisito.
Nel capitolo dello scorso anno, è stato rilevato che il 48.34% delle pagine per dispositivi mobile utilizzava un tag canonico. Quest’anno il numero di pagine per dispositivi mobile con un tag canonico è cresciuto al 53.61%.
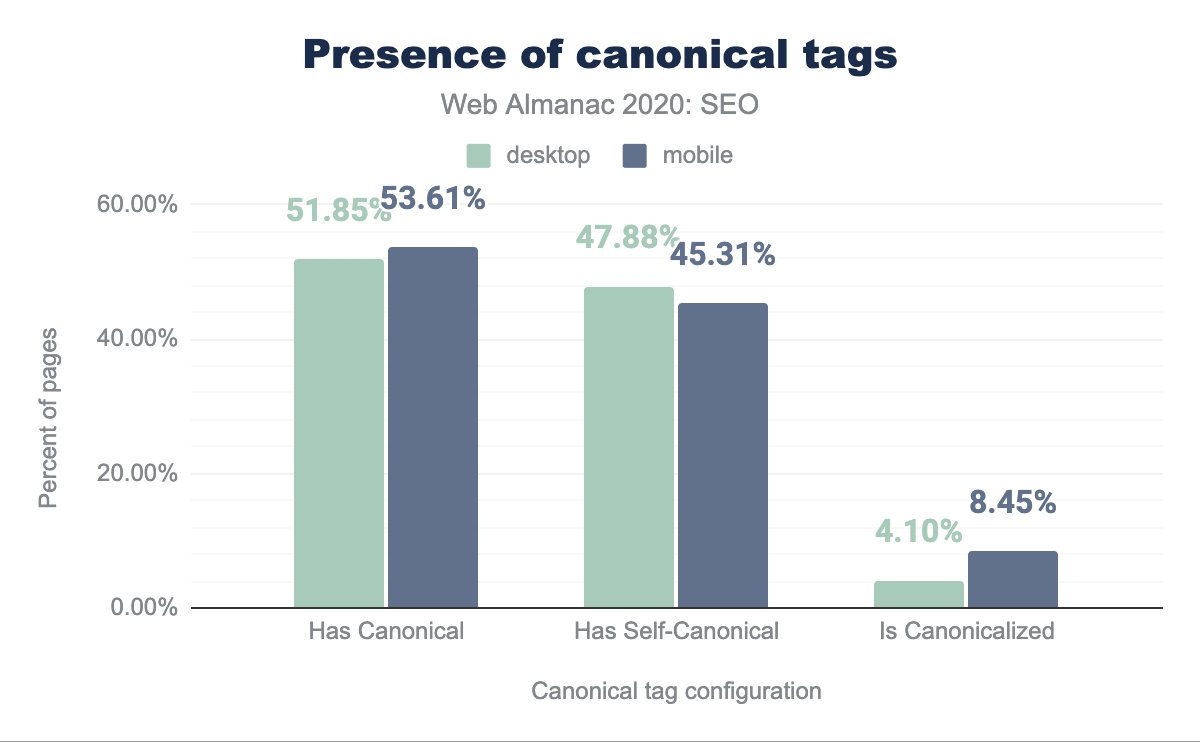
Analizzando la configurazione dei tag canonici delle pagine mobile di quest’anno, è stato rilevato che il 45.31% di esse era autoreferenziale e l’8.45% puntava a URL diversi come quelli canonici.
D’altra parte, quest’anno il 51.85% delle pagine desktop presentava un tag canonico, con il 47.88% autoreferenziale e il 4.10% che punta a un URL diverso.
Non solo le pagine per dispositivi mobile includono più tag canonici rispetto a quelle desktop (53.61% contro 51.85%), ma ci sono relativamente più home page per dispositivi mobile che possono essere canonizzate ad altri URL rispetto alle loro controparti desktop (8.45% contro 4.10%). Ciò potrebbe essere spiegato dall’utilizzo di una versione Web mobile indipendente (o separata) da parte di alcuni siti che devono essere canonizzati in base agli URL desktop alternativi.
Gli URL canonici possono essere specificati attraverso diversi metodi: utilizzando il link canonico tramite le intestazioni HTTP o l’head HTML di una pagina, o inviandoli in sitemap XML. Analizzando qual è il metodo di implementazione del link canonico più popolare, è stato riscontrato che solo l’1.03% delle pagine desktop e lo 0.88% di quelle mobile si affidano alle intestazioni HTTP per la loro implementazione, il che significa che i tag canonici sono implementati in modo prominente tramite HTML head di una pagina.
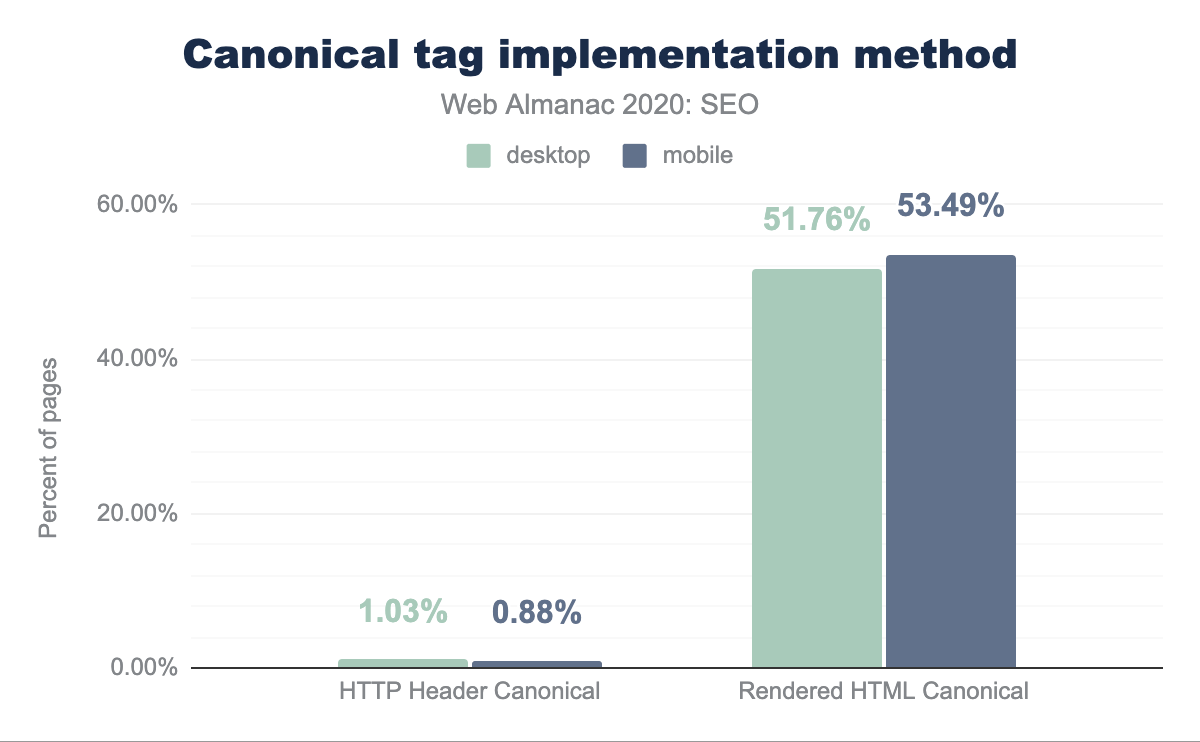
head.
Analizzando il tag canonico implementato nell’HTML grezzo rispetto a quelli che si basano sul rendering JavaScript lato client, abbiamo identificato che lo 0.68% delle pagine per dispositivi mobile e lo 0.54% di quelle desktop includono un tag canonico nell’HTML renderizzato ma non nell’HTML grezzo. Ciò significa che solo un numero molto ridotto di pagine si basa su JavaScript per implementare i tag canonici.
D’altra parte, nello 0.93% delle pagine mobile e nello 0.76% di quelle desktop, abbiamo visto tag canonici implementati sia tramite l’HTML grezzo che tramite l’HTML renderizzato con un conflitto che si verifica tra l’URL specificato nell’HTML grezzo e nell’HTML renderizzato delle stesse pagine. Ciò può generare problemi di indicizzazione poiché vengono inviate informazioni miste ai motori di ricerca su quale sia l’URL canonico della stessa pagina.
Un conflitto simile può essere trovato con i diversi metodi di implementazione, con lo 0.15% delle pagine mobile e lo 0.17% di quelle desktop che mostrano conflitti tra i tag canonici implementati tramite le loro intestazioni HTTP e HTML head.
Contenuto
Lo scopo principale che servono sia i motori di ricerca che la Search Engine Optimization è dare visibilità ai contenuti di cui gli utenti hanno bisogno. I motori di ricerca estraggono funzionalità dalle pagine per determinare di cosa tratta il contenuto. In questo modo, i due sono simbiotici. Le caratteristiche estratte si allineano con i segnali che indicano la pertinenza e informano la classifica.
Per capire cosa sono in grado di estrarre efficacemente i motori di ricerca, abbiamo suddiviso i componenti di quel contenuto ed esaminato il tasso di incidenza di tali caratteristiche tra i contesti mobile e desktop. Abbiamo anche esaminato la disparità tra i contenuti per dispositivi mobile e desktop. La disparità tra dispositivi mobile e desktop è particolarmente importante perché Google è passato a mobile-first indexing (MFI) per tutti i nuovi siti e, a partire da marzo 2021, passerà a un mobile-only index in cui i contenuti che non vengono visualizzati nel contesto dei dispositivi mobile non verranno valutati per il ranking.
Contenuto di testo sottoposto a rendering contro contenuto di testo non sottoposto a rendering
L’utilizzo delle tecnologie Single Page Application (SPA) JavaScript è esploso con la crescita del web. Questo modello di progettazione introduce difficoltà per gli spider dei motori di ricerca perché sia l’esecuzione di trasformazioni JavaScript in fase di esecuzione sia le interazioni dell’utente con la pagina dopo il caricamento possono causare la visualizzazione o il rendering di contenuto aggiuntivo.
I motori di ricerca incontrano le pagine attraverso la loro attività di scansione, ma possono o meno scegliere di implementare un secondo passaggio di rendering di una pagina. Di conseguenza, potrebbero esserci disparità tra il contenuto che un utente vede e il contenuto che un motore di ricerca indicizza e considera per le classifiche.
Abbiamo valutato il conteggio delle parole come un’euristica di tale disparità.
| Valori | Desktop | Mobile | Differenza |
|---|---|---|---|
| Non elaborate | 360 | 312 | -13.33% |
| Renderizzate | 402 | 348 | -13.43% |
| Differenza | 11.67% | 11.54% |
Quest’anno, la pagina desktop mediana è stata trovata con 402 parole e la pagina mobile aveva 348 parole. Mentre l’anno scorso, la pagina desktop mediana aveva 346 parole e la pagina mobile mediana aveva un conteggio parole leggermente inferiore a 306 parole. Ciò rappresenta rispettivamente una crescita del 16.2% e del 13.7%.
Abbiamo scoperto che il sito desktop medio presenta l’11.67% di parole in più quando la pagina è renderizzata rispetto a una scansione iniziale del suo HTML grezzo. Abbiamo anche scoperto che il sito per dispositivi mobile mediano mostra il 13.33% di contenuto di testo in meno rispetto alla sua controparte desktop. Il sito mobile mediano mostra anche l’11.54% di parole in più quando la pagina è renderizzata rispetto alla sua controparte HTML grezzo.
Nel nostro esempio, ci sono disparità nella combinazione di dispositivi mobile/desktop e renderizzati/non-renderizzati. Ciò suggerisce che, sebbene i motori di ricerca stiano migliorando continuamente in quest’area, la maggior parte dei siti sul Web sta perdendo l’opportunità di migliorare la visibilità della ricerca organica attraverso una maggiore attenzione per garantire che i loro contenuti siano disponibili e indicizzabili. Questa è anche una preoccupazione perché la maggior parte degli strumenti SEO disponibili non scansiona i contenuti e lo identifica automaticamente come un problema.
Le intestazioni
Gli elementi di intestazione (H1-H6) agiscono come un meccanismo per indicare visivamente la struttura nel contenuto di una pagina. Sebbene questi elementi HTML non abbiano il peso che avevano una volta nelle classifiche di ricerca, agiscono strutturando le pagine e segnalando altri elementi nelle pagine dei risultati dei motori di ricerca (SERP) come featured snippet o altri metodi di estrazione che si allineano con l’indicizzazione dei nuovi passaggi di Google.
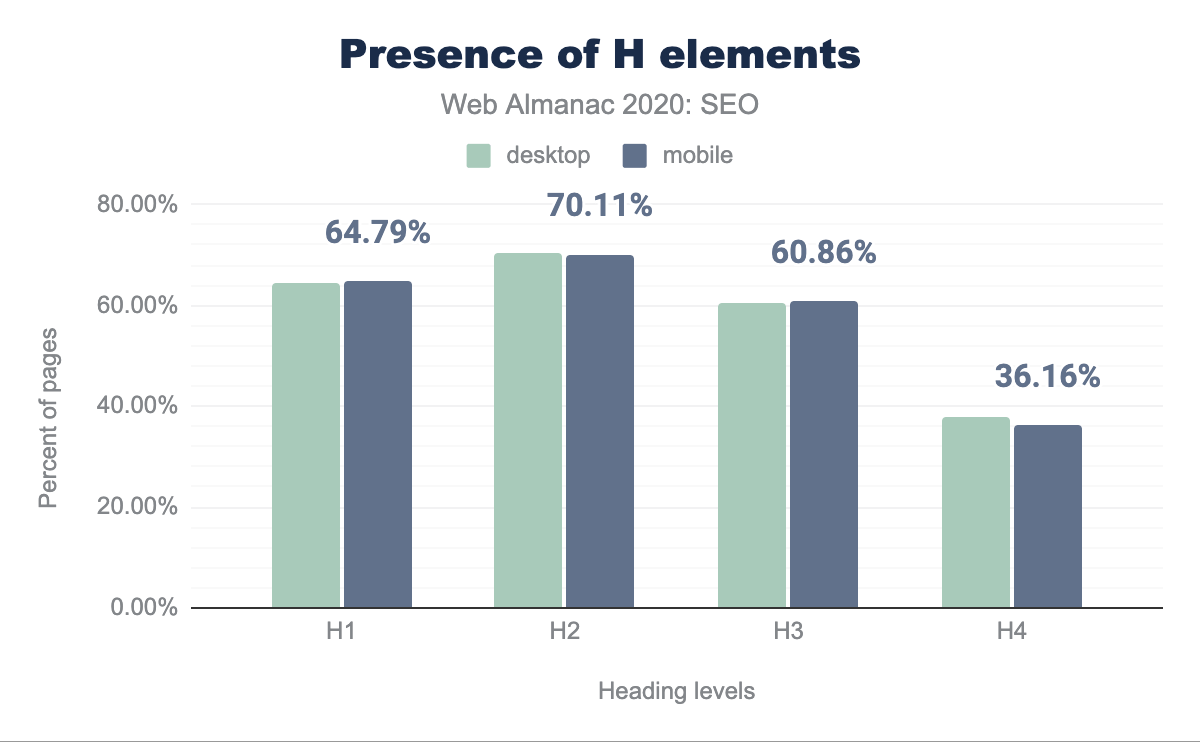
Oltre il 60% delle pagine presenta elementi H1 (compresi quelli vuoti) sia nel contesto mobile che desktop.
Questi numeri oscillano intorno al 60%+ attraverso H2 e H3. Il tasso di incidenza degli elementi H4 è inferiore al 4%, suggerendo che il livello di specificità non è richiesto per la maggior parte delle pagine o che gli sviluppatori definiscono gli altri elementi delle intestazioni in modo diverso per supportare la struttura visiva del contenuto.
La prevalenza di più elementi H2 rispetto a H1 suggerisce che un minor numero di pagine utilizzano più elementi H1.
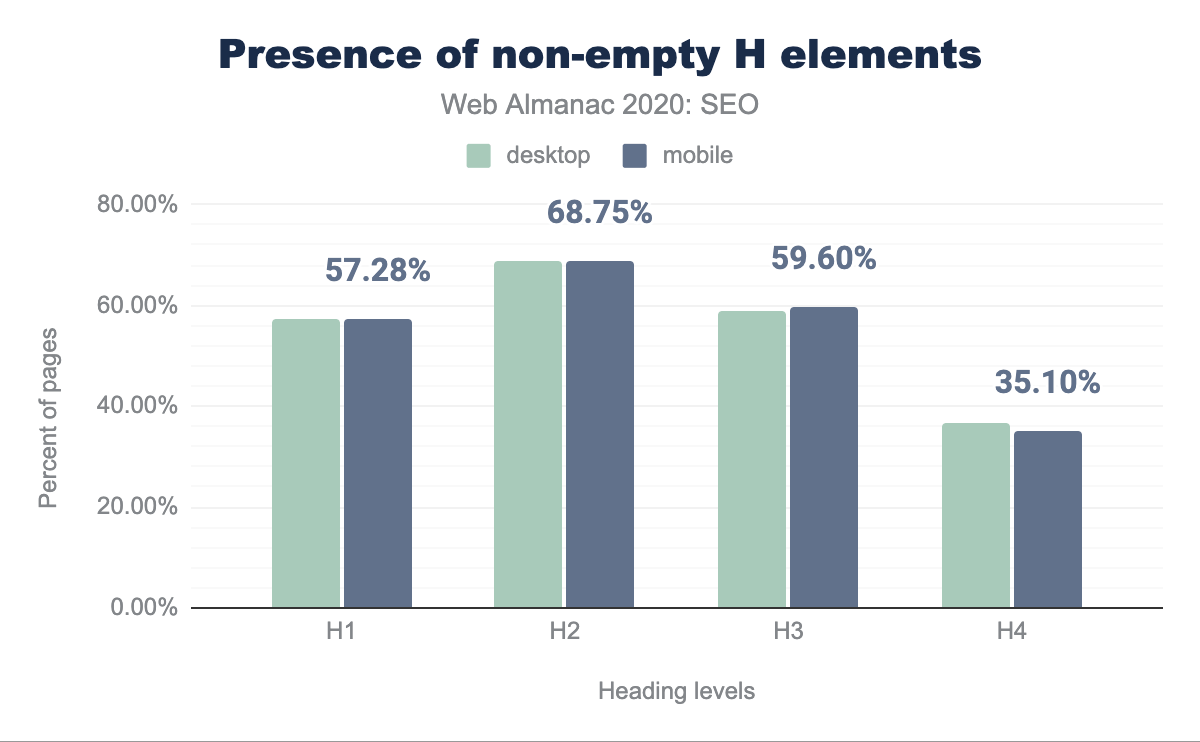
Esaminando l’adozione di elementi di intestazione non vuoti, abbiamo scoperto che il 7.55% di H1, l’1.4% di H2, l’1.5% di H3 e l’1.1% di H4 non contengono testo. Una possibile spiegazione per questi risultati bassi è che quelle parti vengono utilizzate per definire lo stile della pagina o sono il risultato di errori di codifica.
Puoi saperne di più sull’uso delle intestazioni nel capitolo Markup, incluso l’uso improprio di elementi H7 e H8 non standard.
Dati strutturati
Nel corso dell’ultimo decennio, i motori di ricerca, in particolare Google, hanno continuato a spingere per diventare il livello di presentazione del web. Questi progressi sono in parte guidati dalla loro migliore capacità di estrarre informazioni da contenuti non strutturati (ad esempio, indicizzazione dei passaggi) e dall’adozione del markup semantico nel modulo di dati strutturati. I motori di ricerca hanno incoraggiato i creatori di contenuti e gli sviluppatori a implementare dati strutturati per dare maggiore visibilità ai loro contenuti all’interno dei componenti dei risultati di ricerca.
Nel articolo riguardante “strings to things”, i motori di ricerca hanno concordato un ampio vocabolario di oggetti a sostegno della marcatura su una varietà di persone, luoghi e cose all’interno dei contenuti web. Tuttavia, solo un sottoinsieme di quel vocabolario attiva l’inclusione nei componenti dei risultati di ricerca. Google specifica quelli che supportano e come vengono visualizzati nella sua galleria di ricerca e fornisce uno strumento per convalidare il loro supporto e implementazione.
Man mano che i motori di ricerca si evolvono per riflettere più di questi elementi nei risultati di ricerca, i tassi di incidenza dei diversi vocabolari cambiano nel web.
Come parte del nostro esame, abbiamo esaminato i tassi di incidenza di diversi tipi di markup strutturati. I vocabolari disponibili includono RDFa e schema.org, disponibili sia nei microformati che in JSON-LD. Google ha recentemente abbandonato il supporto per il vocabolario dei dati, che è stato utilizzato principalmente per implementare i breadcrumb.
JSON-LD è generalmente considerato l’implementazione più portabile e più facile da gestire e quindi è diventato il formato preferito. Di conseguenza, vediamo che JSON-LD appare sul 29.78% delle pagine mobile e sul 30.60% delle pagine desktop.
| Formato | Mobile | Desktop |
|---|---|---|
| JSON-LD | 29.78% | 30.60% |
| Microdata | 19.55% | 17.94% |
| RDFa | 1.42% | 1.63% |
| Microformats2 | 0.10% | 0.10% |
Troviamo che la disparità tra mobile e desktop continua con questo tipo di dati. I microdati sono apparsi sul 19.55% delle pagine mobile e sul 17.94% delle pagine desktop. RDFa è apparso sull’1.42% delle pagine mobile e sull’1.63% delle pagine desktop.
Dati strutturati renderizzati contro Dati strutturati non renderizzati
Abbiamo riscontrato che il 38.61% delle pagine desktop e il 39.26% delle pagine mobile presentano dati strutturati JSON-LD o microformati nell’HTML grezzo, mentre il 40.09% delle pagine desktop e il 40.97% delle pagine mobile presentano dati strutturati nel DOM renderizzato.
Analizzando questo in modo più dettagliato, abbiamo scoperto che l’1.49% delle pagine desktop e l’1.77% delle pagine mobile presentavano solo questo tipo di dati strutturati nel DOM renderizzato a causa delle trasformazioni JavaScript, basandosi sulle capacità di esecuzione JavaScript nei motori di ricerca.
Infine, abbiamo scoperto che il 4.46% delle pagine desktop e il 4.62% delle pagine mobile presentano dati strutturati che appaiono nell’HTML grezzo e vengono successivamente modificati dalle trasformazioni JavaScript nel DOM renderizzato. A seconda del tipo di modifiche applicate alla configurazione dei dati strutturati, ciò potrebbe generare segnali contrastanti per i motori di ricerca durante il rendering.
Gli Oggetti di dati strutturati più diffusi
Come visto lo scorso anno, gli oggetti di dati strutturati più diffusi rimangono WebSite,SearchAction, WebPage, Organization e ImageObject e il loro utilizzo ha continuato a crescere:
WebSiteè cresciuto del 9.37% su desktop e del 10.5% su dispositivi mobileSearchActionè cresciuto del 7.64% sia su desktop che su dispositivi mobileWebPageè cresciuto del 6.83% sui desktop e del 7.09% sui dispositivi mobileOrganizationè cresciuto del 4.75% sui desktop e del 4.98% sui dispositivi mobileImageObjectè cresciuto del 6.39% sui desktop e del 6.13% sui dispositivi mobile
Va notato che WebSite, SearchAction e Organization sono tutti tipicamente associati alle home page, quindi questo evidenzia il bias del set di dati e non riflette la maggior parte dei dati strutturati implementati sul web.
Al contrario, nonostante il fatto che le recensioni non dovrebbero essere associate alle home page, i dati indicano che AggregateRating viene utilizzato il 23.9% su dispositivi mobile e il 23.7% su desktop.
È interessante vedere la crescita di VideoObject per annotare i video. Sebbene i video di YouTube dominino i risultati di ricerca video in Google, l’utilizzo di VideoObject è cresciuto del 30.11% su desktop e del 27.7 % sul cellulare.
La crescita di questi oggetti è un’indicazione generale di una maggiore adozione di dati strutturati. C’è anche un’indicazione di ciò che Google offre visibilità all’interno delle funzionalità di ricerca aumenta i tassi di incidenza di oggetti meno utilizzati. Google ha annunciato gli oggetti FAQPage, HowTo e QAPage come opportunità di visibilità nel 2019 e hanno sostenuto una crescita significativa di anno in anno:
- Il markup
FAQPageè cresciuto del 3.261% su desktop e del 3.000% su mobile. - Il markup
HowToè cresciuto del 605% su desktop e del 623% su dispositivi mobile. - Il markup
QAPageè cresciuto del 166.7% su desktop e del 192.1% su dispositivi mobili.
L’adozione di dati strutturati è un vantaggio per il Web in quanto l’estrazione dei dati è preziosa per una vasta gamma di casi d’uso. Ci aspettiamo che questo continui a crescere man mano che i motori di ricerca espandono il loro utilizzo e quando inizia a potenziare le applicazioni oltre la ricerca sul web.
I Metadati
I metadati sono un’opportunità per descrivere e spiegare il valore del contenuto dall’altra parte del clic. Mentre si ritiene che i titoli delle pagine siano pesati direttamente nelle classifiche di ricerca, le meta descrizioni non lo sono. Entrambi gli elementi possono incoraggiare o scoraggiare un utente a fare clic o meno in base ai propri contenuti.
Abbiamo esaminato queste funzionalità per vedere come le pagine si allineano quantitativamente alle best practice per indirizzare il traffico dalla ricerca organica.
Titoli
Il titolo della pagina viene mostrato come testo di ancoraggio nei risultati dei motori di ricerca ed è generalmente considerato uno degli elementi più preziosi nella pagina che influisce sulla capacità di una pagina di classificarsi.
Analizzando l’utilizzo del tag title, abbiamo scoperto che il 99% delle pagine desktop e mobile ne ha uno. Ciò rappresenta un leggero miglioramento rispetto l’anno scorso, quando il 97% delle pagine per dispositivi mobile aveva un tag title.
La pagina mediana presenta un titolo di pagina lungo sei parole. Non c’è differenza nel conteggio delle parole tra il contesto mobile e desktop all’interno del nostro set di dati. Ciò suggerisce che l’elemento del titolo della pagina è un elemento che non viene modificato tra diversi tipi di modelli di pagina.
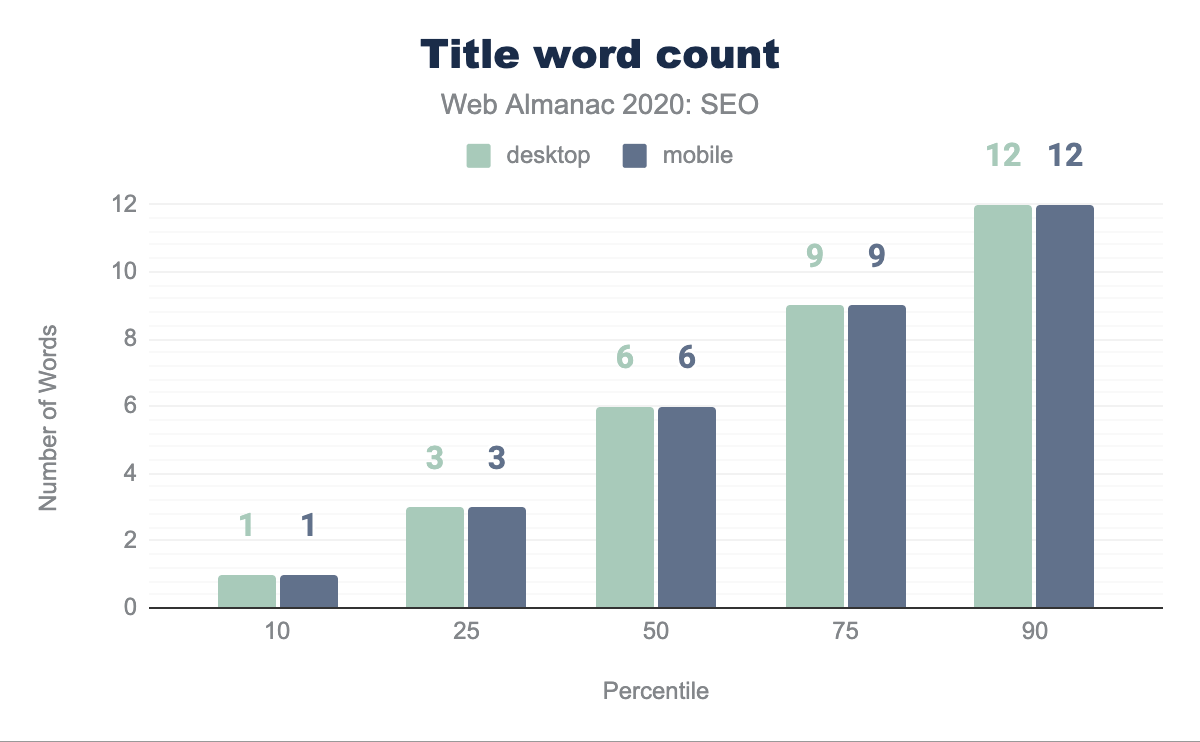
Il conteggio mediano dei caratteri del titolo della pagina è di 38 caratteri su dispositivi mobili e desktop. È interessante notare che questo è aumentato da 20 caratteri su desktop e 21 caratteri su dispositivo mobile dall’analisi dell’anno scorso. La disparità tra i contesti è scomparsa di anno in anno tranne che nel 90° percentile in cui c’è una differenza di un carattere.

Le Meta description
La meta description funge da slogan pubblicitario per una pagina web. Sebbene uno studio recente suggerisca che questo tag venga ignorato e riscritto da Google il 70% delle volte, è un elemento preparato con l’obiettivo di invogliare un utente a fare clic.
Analizzando l’utilizzo delle meta description, abbiamo rilevato che il 68.62% delle pagine desktop e il 68.22% delle pagine mobile ne hanno una. Sebbene possa essere sorprendentemente basso, si tratta di un leggero miglioramento rispetto a l’anno scorso, quando solo il 64.02% delle pagine mobile aveva una meta description.
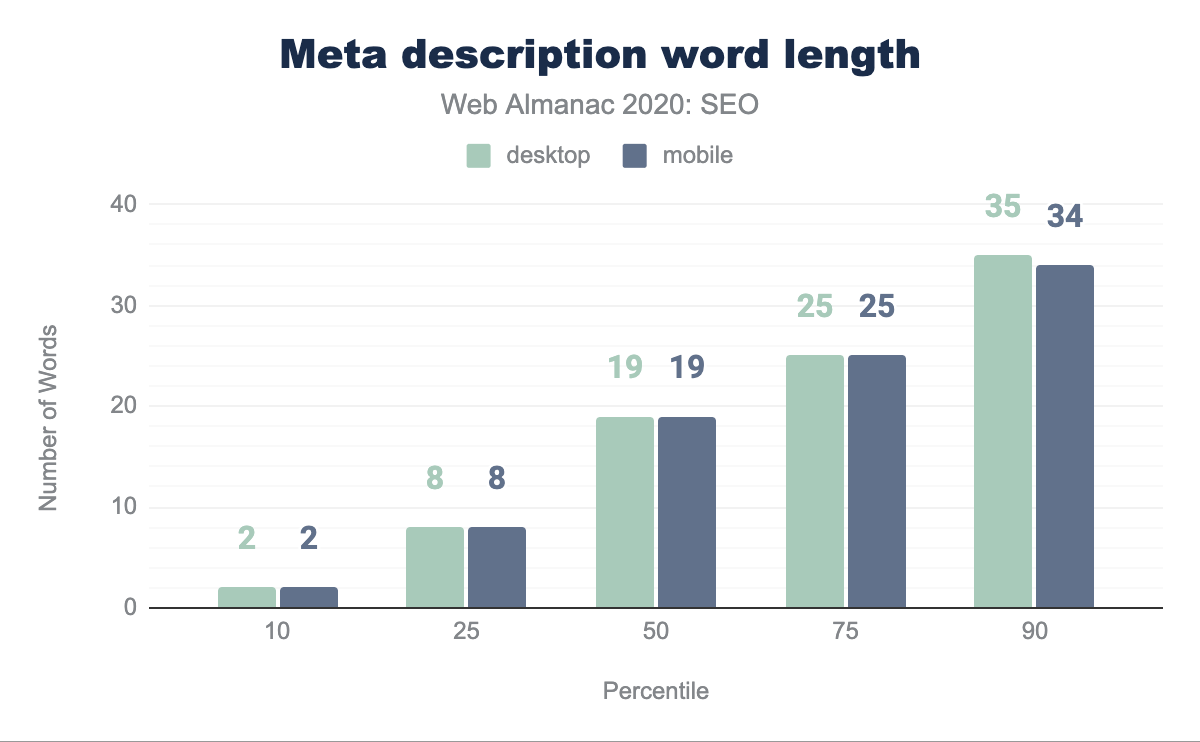
La lunghezza mediana della meta description è di 19 parole. L’unica disparità nel conteggio delle parole si verifica nel 90° percentile in cui il contenuto del desktop ha una parola in più rispetto al mobile.
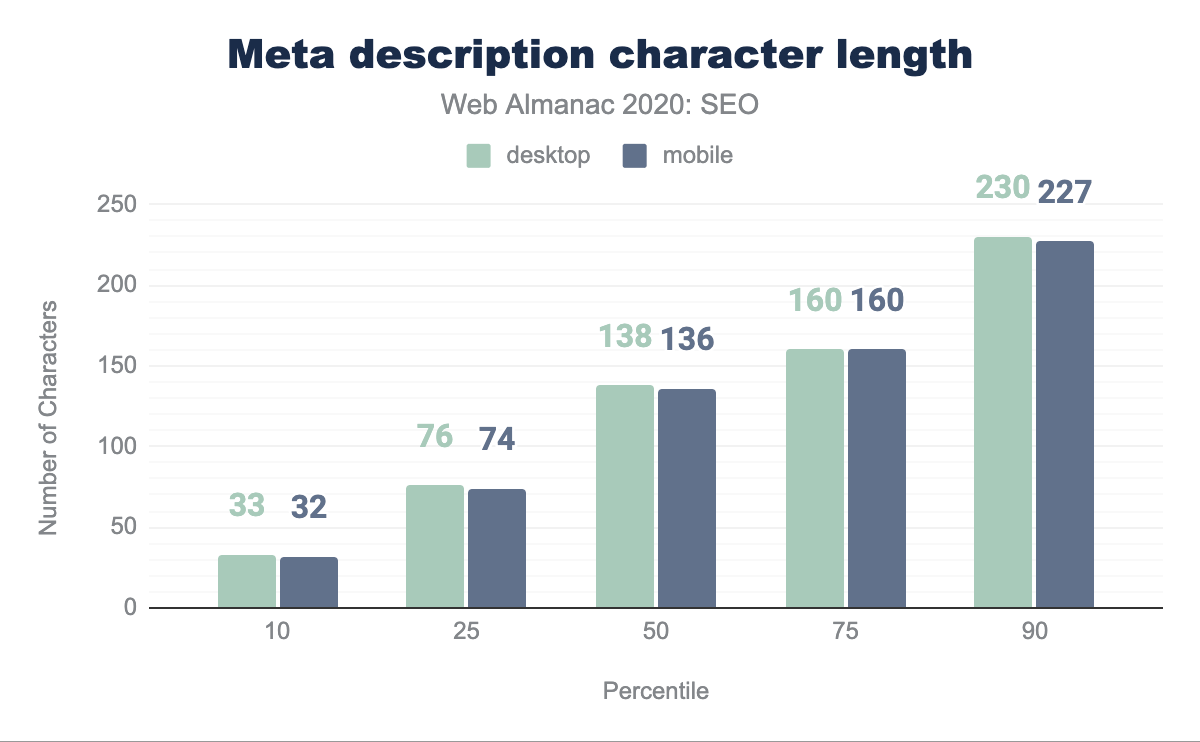
Il conteggio mediano dei caratteri per la meta description è di 138 caratteri sulle pagine desktop e 136 caratteri sulle pagine mobile. A parte il 75° percentile, c’è una piccola disparità tra le lunghezze delle meta description per dispositivi mobile e desktop distribuite nel set di dati. Le migliori pratiche SEO suggeriscono di limitare la meta description a un massimo di 160 caratteri, ma Google, in modo incoerente, può visualizzare fino a 300 caratteri nei suoi frammenti.
Con le meta description che continuano ad alimentare altri snippet come social e news feed, e dato che Google le riscrive continuamente e non le considera un fattore di ranking diretto, è ragionevole aspettarsi che le meta description continueranno a crescere oltre il limite di 160 caratteri.
Le immagini
L’uso di immagini, in particolare usando i tag img, all’interno di una pagina suggerisce spesso una focalizzazione sulla presentazione visiva del contenuto. Sebbene le capacità dei motori di ricerca relative alla visione artificiale abbiano continuato a migliorare, non abbiamo alcuna indicazione che questa tecnologia venga utilizzata nel posizionamento delle pagine. Gli attributi alt rimangono il modo principale per spiegare un’immagine al posto della capacità di un motore di ricerca di “vederla”. Gli attributi alt supportano anche l’accessibilità e chiariscono gli elementi sulla pagina per gli utenti con problemi di vista.
La pagina desktop mediana include 21 tag img e la pagina mobile mediana ha 19 tag img. Il web continua a fare tendenza verso la pesantezza dell’immagine con la crescita della larghezza di banda e l’ubiquità degli smartphone. Tuttavia, questo ha un costo in termini di prestazioni.
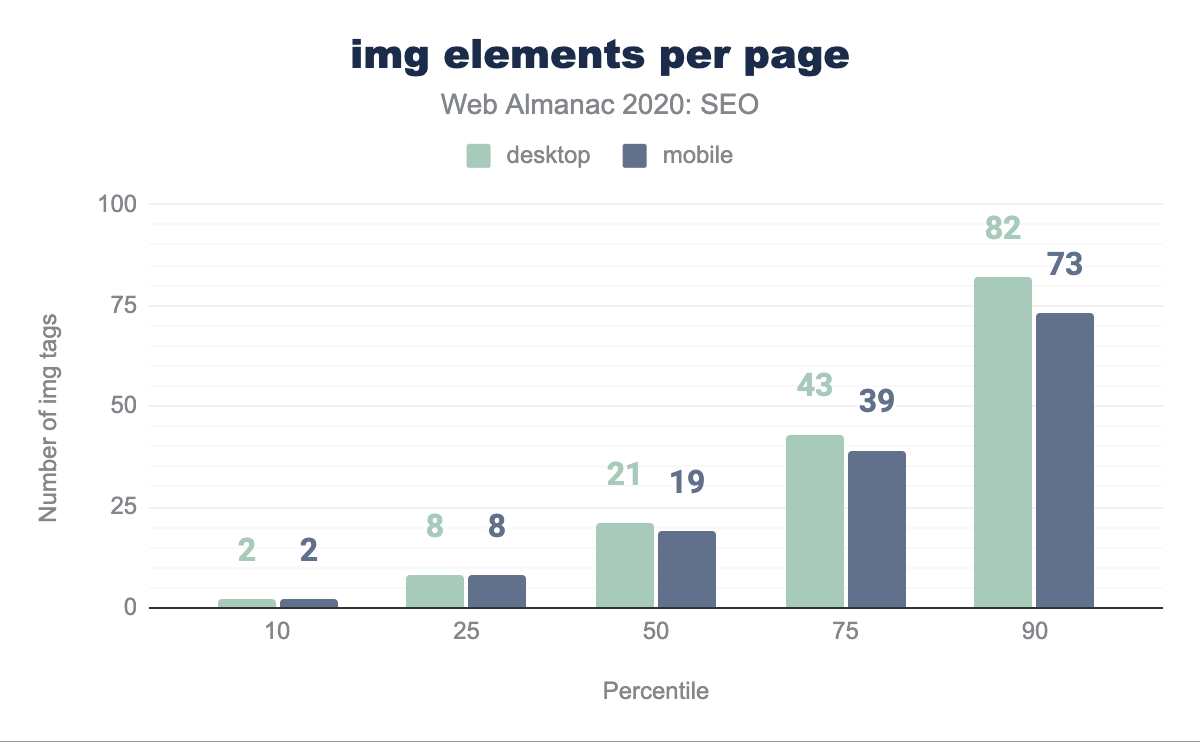
<img> per pagina per percentile (10, 25, 50, 75 e 90). La pagina desktop mediana presenta 21 elementi <img> e la pagina mobile mediana presenta 19 elementi <img><img> per pagina.
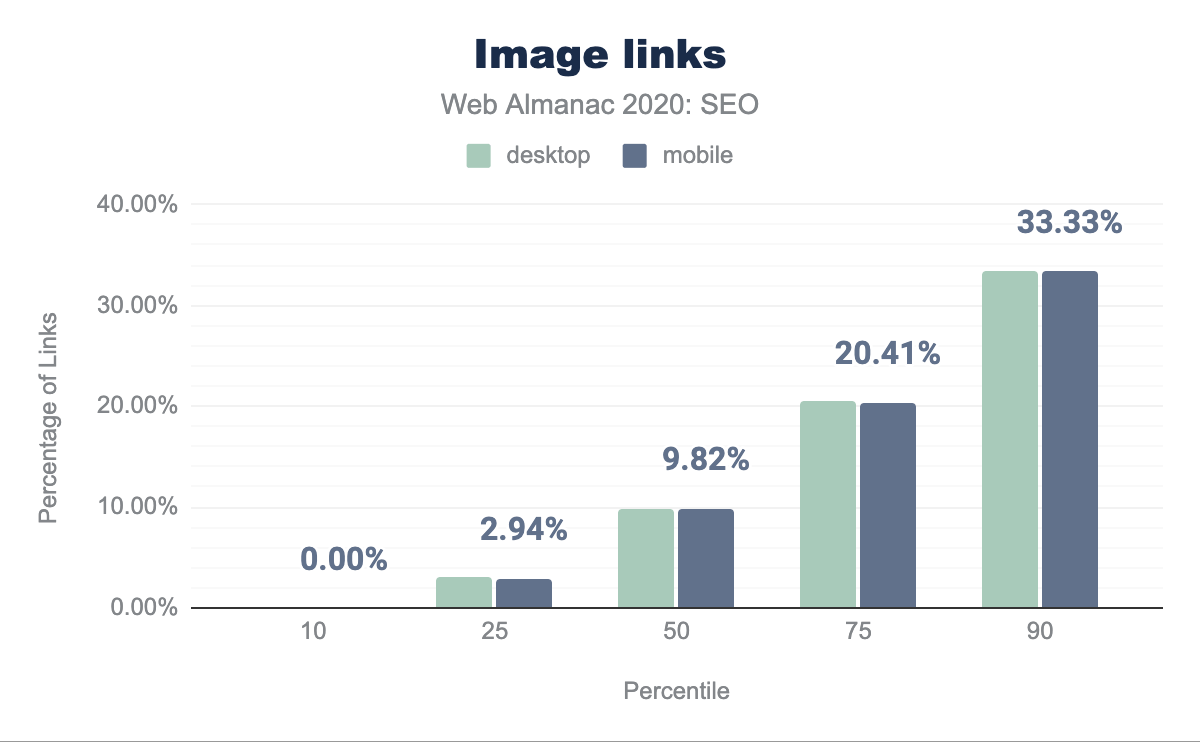
Nella pagina web mediana manca il 2.99% degli attributi alt sul desktop e il 2.44% degli attributi alt sui dispositivi mobile. Per maggiori informazioni sull’importanza degli attributi alt, vedere il capitolo Accessibilità.
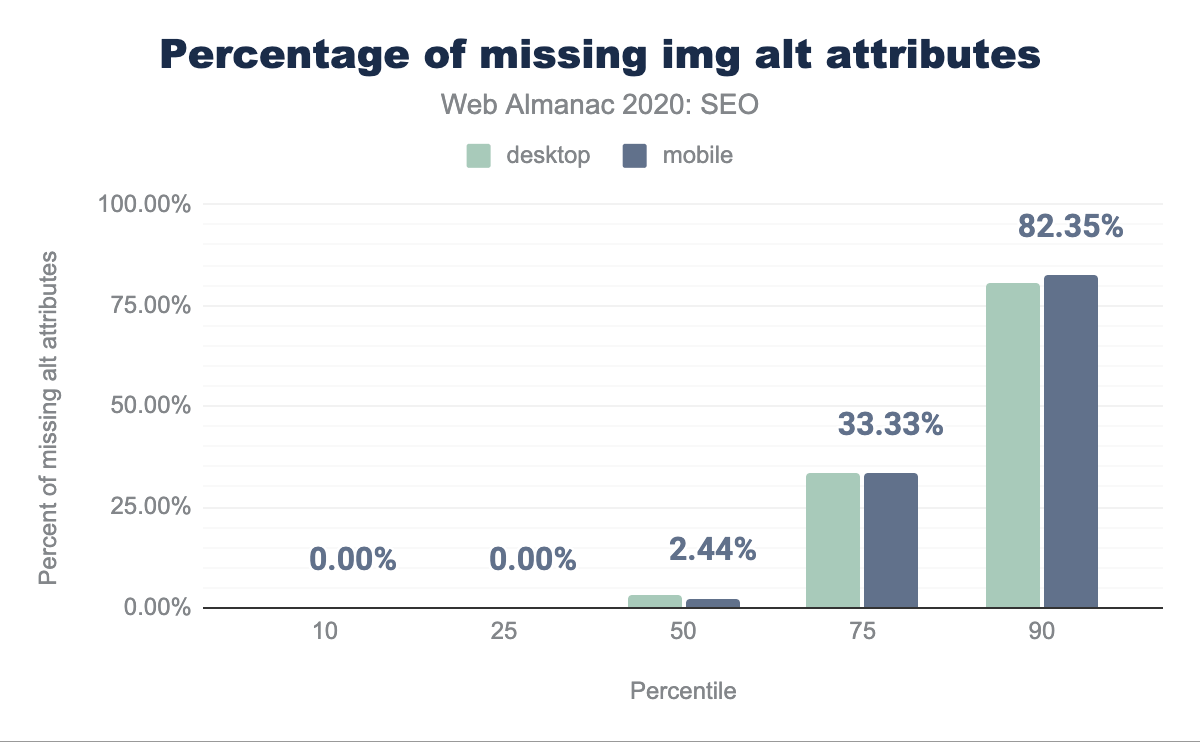
alt mancanti per percentile (10, 25, 50, 75 e 90). Nella pagina web mediana mancano il 2.99% degli attributi alt sul desktop e il 2.44% degli attributi alt sui dispositivi mobile.<img> mancanti degli attributi immagine alt per pagina.
Abbiamo scoperto che la pagina mediana contiene attributi alt solo nel 51.22% delle immagini.
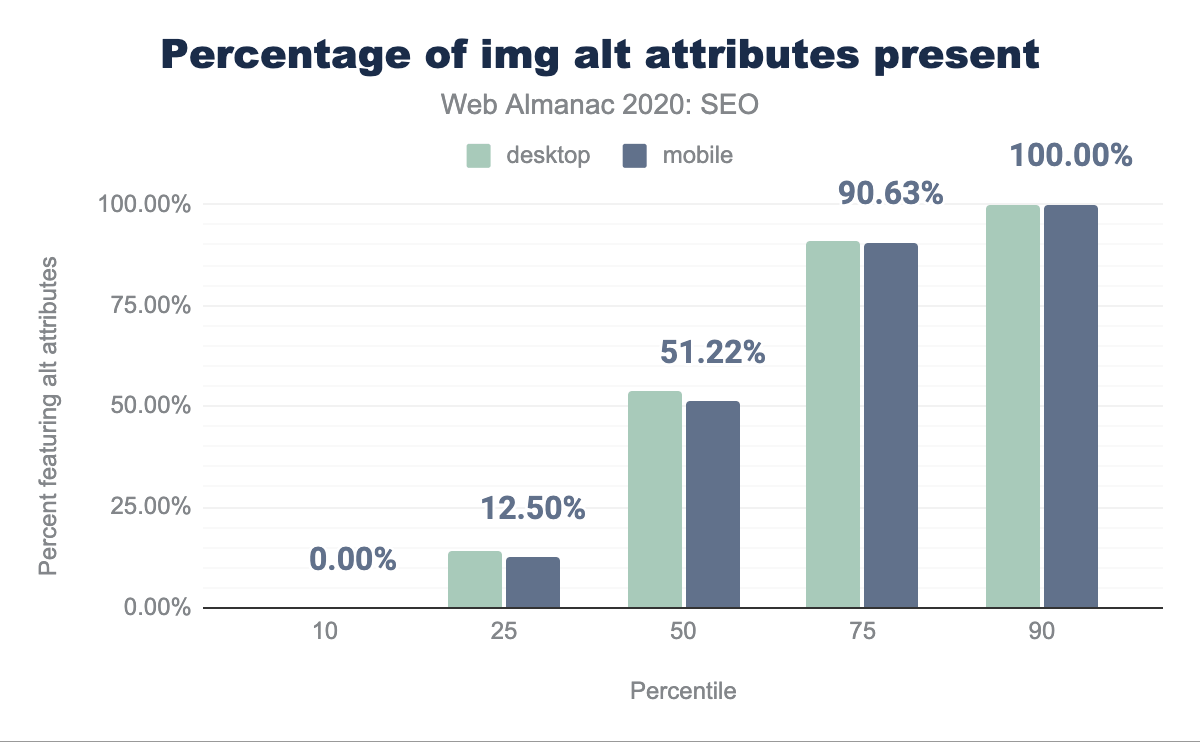
alt presenti per percentile (10, 25, 50, 75 e 90). È stato rilevato che solo il 53.86% delle pagine desktop e il 51.22% delle pagine mobile presentavano attributi di immagine alt.alt per pagina.
La pagina web mediana ha il 10.00% di immagini con attributi alt vuoti su desktop e 11.11% su dispositivi mobile.
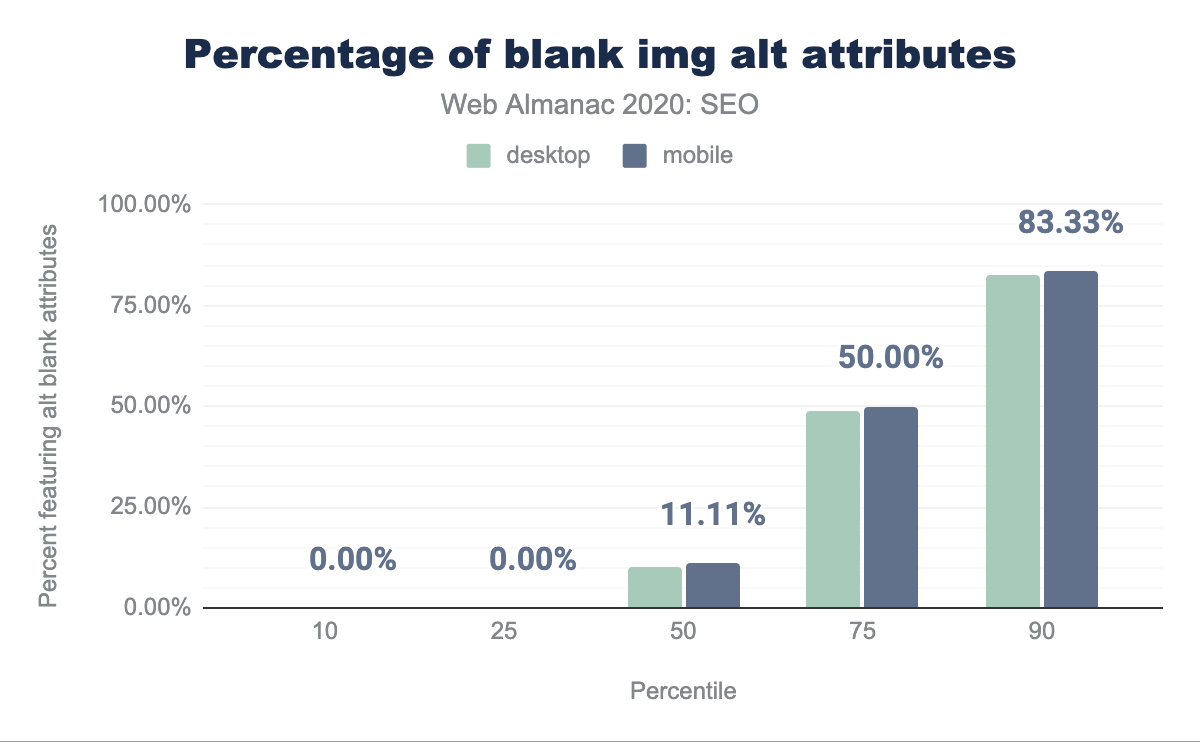
alt in primo piano per percentile (10, 25, 50, 75 e 90). La pagina web mediana presenta attributi alt vuoti del 10% sul desktop e attributi alt vuoti dell’11.11% sui dispositivi mobile.alt vuoti per pagina.
I Link
I motori di ricerca moderni utilizzano collegamenti ipertestuali (hyperlink) tra le pagine per la scoperta di nuovi contenuti per l’indicizzazione e come indicazione dell’autorità per il posizionamento. Il grafico dei collegamenti è qualcosa che i motori di ricerca controllano attivamente sia algoritmicamente che tramite revisione manuale. Le pagine web passano link equity attraverso i loro siti e ad altri siti attraverso questi collegamenti ipertestuali, quindi è importante assicurarsi che ci sia una grande quantità di link in ogni data pagina, ma anche, come Google menziona nella sua Guida introduttiva al SEO per creare saggiamente un link.
I link in uscita
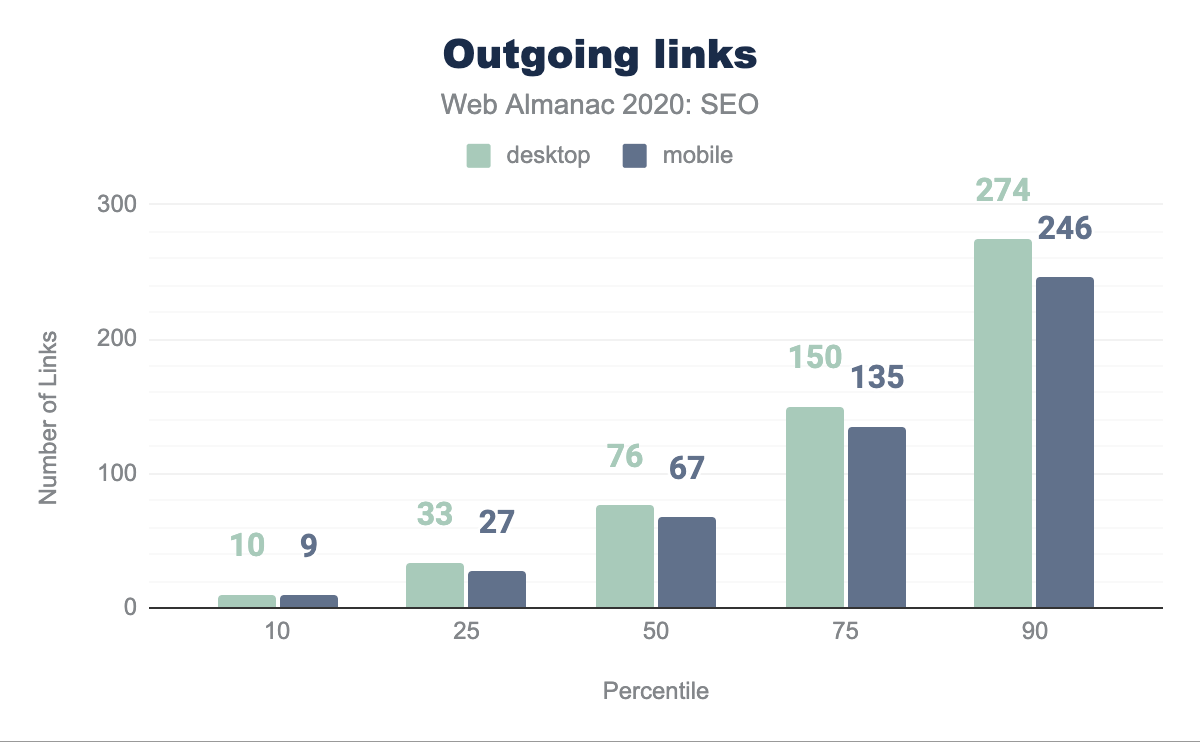
Nell’ambito di questa analisi siamo in grado di valutare i link in uscita da ciascuna pagina, sia a pagine interne dello stesso dominio, sia a quelle esterne, tuttavia non abbiamo analizzato i link in entrata.
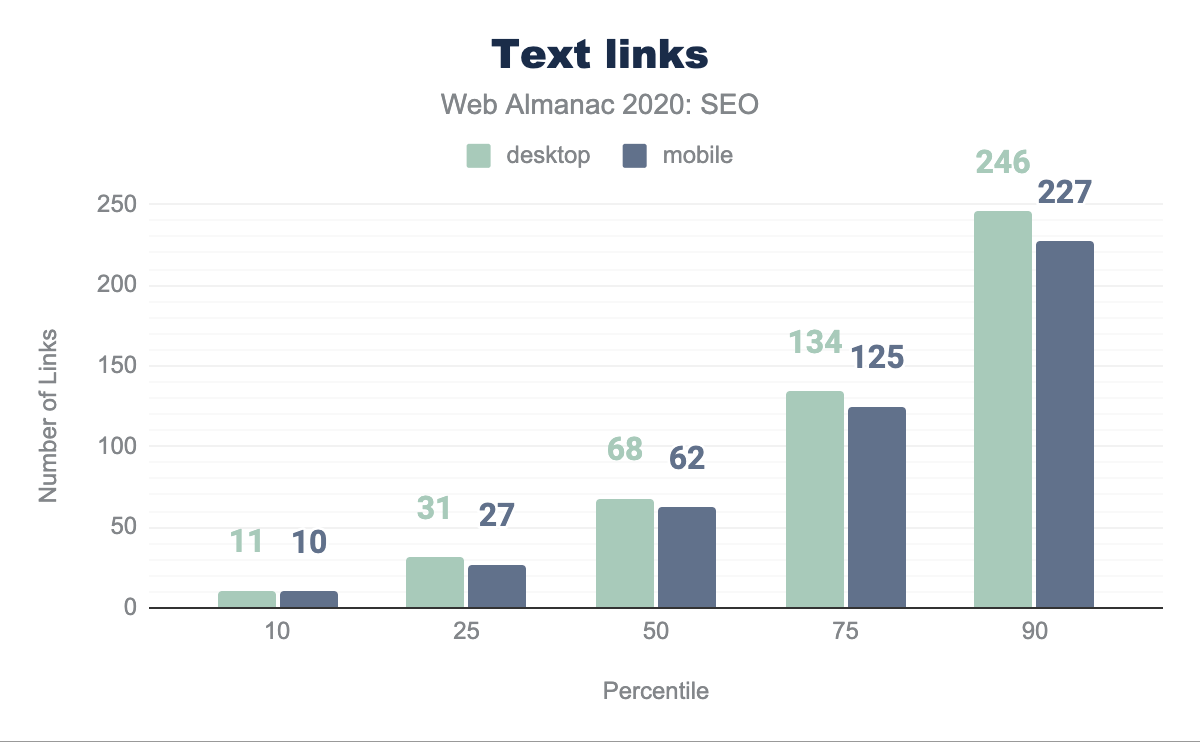
La pagina desktop mediana include 76 link mentre la pagina mobile mediana ne ha 67. Storicamente, la direzione di Google ha suggerito che i link fossero limitati a 100 per pagina. Sebbene tale raccomandazione sia obsoleta sul Web moderno e da allora Google ha affermato che non ci sono limiti, la pagina mediana nel nostro set di dati aderisce ad esso.
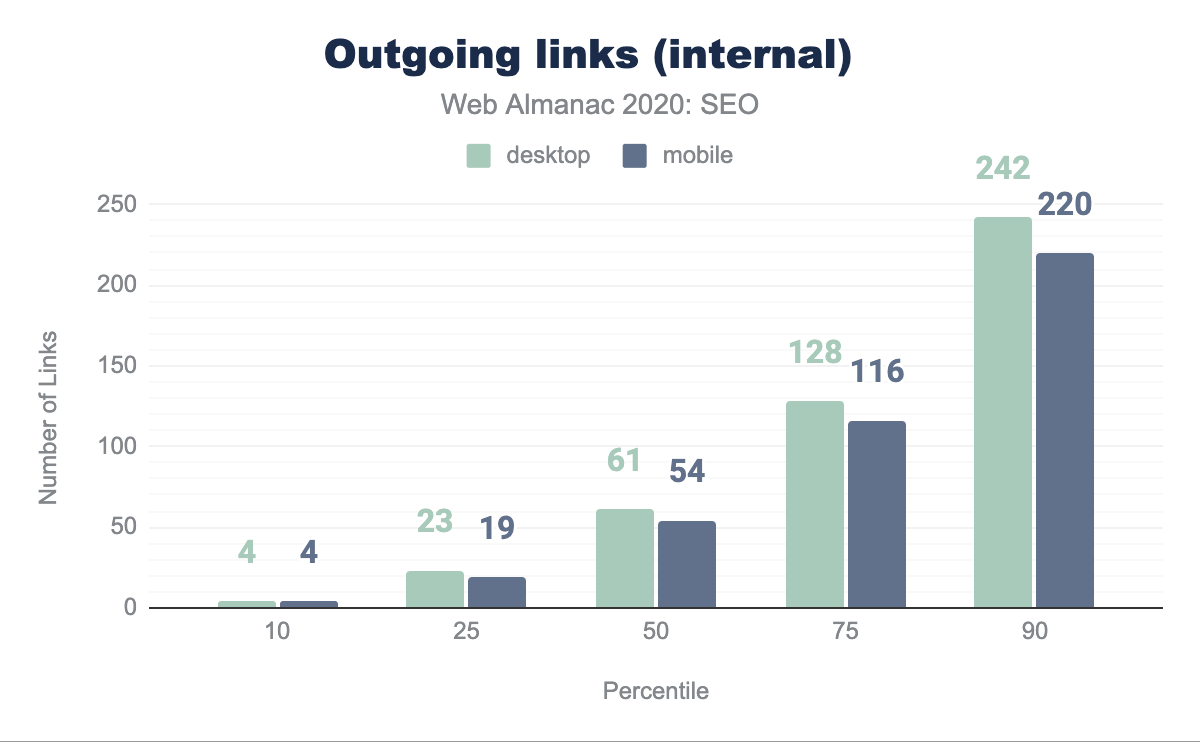
La pagina mediana ha 61 link interni (che vanno a pagine all’interno dello stesso sito) su desktop e 54 su dispositivi mobile. Questo è in calo del 12.8% e del 10% rispettivamente dall’analisi dello scorso anno. Ciò suggerisce che i siti non stanno massimizzando la capacità di migliorare la crawlability e il flusso di link equity attraverso le loro pagine come hanno fatto l’anno prima.
La pagina mediana si collega a siti esterni 7 volte su desktop e 6 volte su dispositivi mobile. Si tratta di una diminuzione rispetto allo scorso anno, quando si è riscontrato che il numero medio di link esterni per pagina erano 10 su desktop e 8 su dispositivi mobile. Questa diminuzione dei link esterni potrebbe suggerire che i siti web stanno ora prestando maggiore attenzione quando si collegano ad altri siti, sia per evitare di passare popolarità di link o di indirizzare gli utenti ad essi.
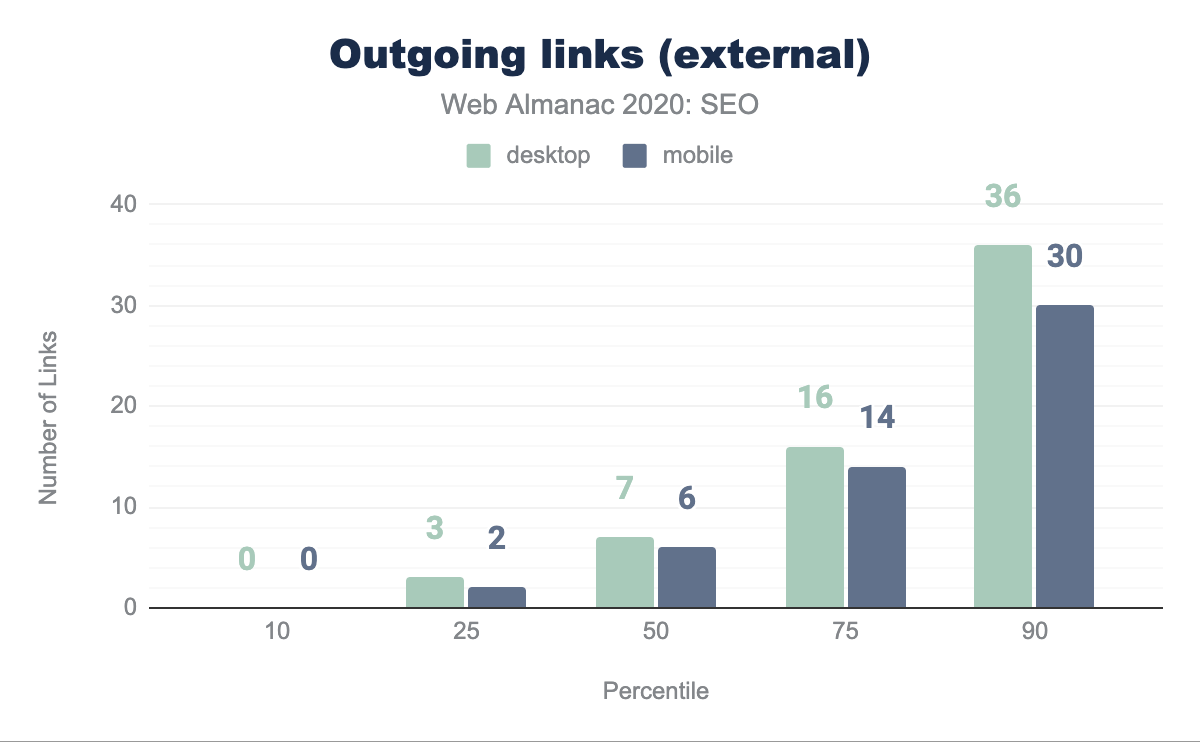
I link testo contro i link immagine
La pagina web mediana utilizza un’immagine come testo di ancoraggio per collegare il 9.80% delle pagine desktop e il 9.82% delle pagine mobile. Questi link rappresentano opportunità perse per implementare un anchor text pertinente per le parole chiave. Questo diventa un problema significativo solo al 90° percentile di pagine.
I link mobile contro i link desktop
Esiste una disparità nei link tra mobile e desktop che avrà un impatto negativo sui siti poiché Google si impegna maggiormente all’indicizzazione mobile-only anziché solo all’indicizzazione mobile-first. Ciò è illustrato nei 62 link sui dispositivi mobile rispetto ai 68 link sul desktop per la pagina web mediana.
Utilizzo degli attributi rel=nofollow, ugc e sponsored
Nel settembre del 2019, Google ha introdotto attributi che consentono agli editori di classificare i link come sponsorizzati o generati dagli utenti. Questi attributi sono in aggiunta a rel=nofollow che è stato precedentemente introdotto nel 2005. I nuovi attributi, rel=ugc e rel=sponsored, hanno lo scopo di chiarire o qualificare il motivo per cui questi link appaiono su una data pagina web.
La nostra revisione delle pagine indica che il 28.58% delle pagine include attributi rel=nofollow su desktop e il 30.74% su dispositivi mobile. Tuttavia, l’adozione di rel=ugc e rel=sponsored è piuttosto bassa con meno dello 0.3% delle pagine (circa 20.000) che ne hanno entrambe. Poiché questi attributi non aggiungono valore a un editore più di rel=nofollow, è ragionevole aspettarsi che il tasso di adozione continuerà a essere lento.
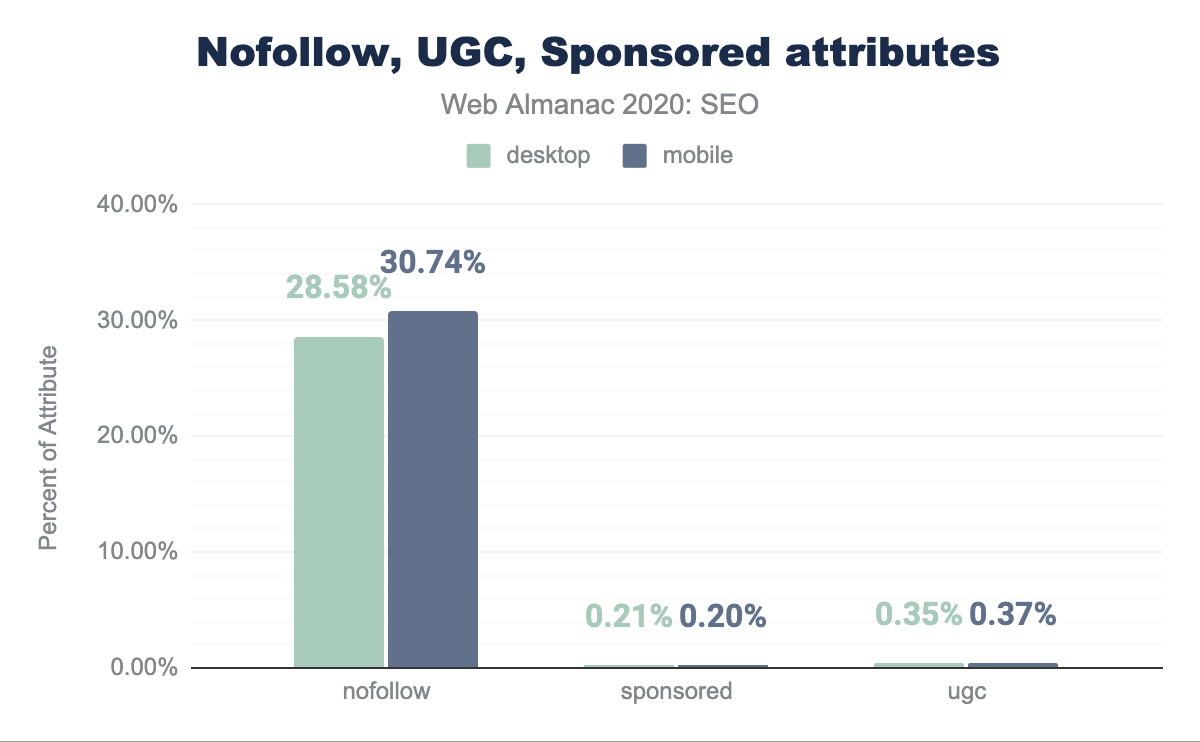
rel su desktop e dispositivi mobili. La nostra recensione indica che il 28.58% delle pagine presenta attributi nofollow nelle versioni desktop e il 30.74% nei dispositivi mobili. Tuttavia, l’adozione di ugc e sponsored è piuttosto bassa con meno dello 0.3% in entrambe le pagine.rel=nofollow, rel=ugc e rel=sponsored.
Avanzate
Questa sezione esplora le opportunità di ottimizzazione relative alle configurazioni web e agli elementi che potrebbero non influenzare direttamente la crawlability o l’indicizzazione di un sito, ma che sono stati confermati dai motori di ricerca per essere utilizzati come segnali di ranking o influenzeranno la capacità dei siti web di sfruttare le funzionalità di ricerca.
Compatibilità mobile
Con la crescente popolarità dei dispositivi mobile per la navigazione e la ricerca sul Web, i motori di ricerca hanno preso in considerazione l’ottimizzazione per i dispositivi mobile come un fattore di ranking per diversi anni.
Inoltre, come accennato in precedenza, dal 2016 Google è passata a un indice mobile first, il che significa che il contenuto che viene scansionato, indicizzato e classificato è quello accessibile agli utenti di dispositivi mobile e al Googlebot per smartphone.
Inoltre, da luglio 2019 Google utilizza l’indice mobile-first per tutti i nuovi siti web e all’inizio di marzo, ha annunciato che il 70% delle pagine mostrate nei risultati di ricerca è già stato spostato. Si prevede ora che Google passi completamente a un indice mobile first nel marzo 2021.
La compatibilità mobile dovrebbe essere fondamentale per qualsiasi sito web che cerca di fornire una buona esperienza di ricerca e, di conseguenza, aumentare i risultati di ricerca.
Un sito web ottimizzato per i dispositivi mobile può essere implementato attraverso diverse configurazioni: utilizzando un responsive web design, con pubblicazione dinamica o tramite una versione web mobile separata. Tuttavia, il mantenimento di una versione Web mobile separata non è più consigliato da Google, che sostiene invece il responsive web design.
Il Meta tag viewport
Il viewport del browser è l’area visibile del contenuto di una pagina, che cambia a seconda del dispositivo utilizzato. Il tag <meta name="viewport"> (o metatag viewport) consente di specificare ai browser la larghezza e il ridimensionamento del viewport, in modo che venga dimensionato correttamente su diversi dispositivi. I siti Web reattivi utilizzano il meta tag viewport e le query multimediali CSS per offrire un’esperienza mobile friendly.
Il 42.98% delle pagine mobile e il 43.2% di quelle desktop hanno un meta tag viewport con l’attributo content=initial-scale=1,width=device-width. Tuttavia, il 10.84% delle pagine mobile e il 16.18% di quelle desktop non includono affatto il tag, il che suggerisce che non sono ancora mobile friendly.
| Viewport | Mobile | Desktop |
|---|---|---|
initial-scale=1,width=device-width |
42.98% | 43.20% |
| not-set | 10.84% | 16.18% |
initial-scale=1,maximum-scale=1,width=device-width |
5.88% | 5.72% |
initial-scale=1,maximum-scale=1,user-scalable=no,width=device-width |
5.56% | 4.81% |
initial-scale=1,maximum-scale=1,user-scalable=0,width=device-width |
3.93% | 3.73% |
content di ciascun metatag viewport.
CSS media queries
Le media query sono una funzionalità CSS3 che gioca un ruolo fondamentale nel responsive web design, in quanto consentono di specificare le condizioni per applicare lo stile solo quando il browser e il dispositivo corrispondono a determinate regole. Ciò consente di creare layout diversi per lo stesso HTML a seconda delle dimensioni del viewport.
Abbiamo scoperto che l’80.29% delle pagine desktop e l’82.92% di quelle per dispositivi mobile utilizza una funzione CSS height, width o aspect-ratio, il che significa che un’alta percentuale di pagine ha caratteristiche reattive. Le funzionalità utilizzate più comunemente possono essere visualizzate nella tabella seguente.
| Funzione | Mobile | Desktop |
|---|---|---|
max-width |
78.98% | 78.33% |
min-width |
75.04% | 73.75% |
-webkit-min-device-pixel-ratio |
44.63% | 38.78% |
orientation |
33.48% | 33.49% |
max-device-width |
26.23% | 28.15% |
Vary: User-Agent
Quando si implementa un sito Web ottimizzato per i dispositivi mobile con una configurazione di pubblicazione dinamica, in cui si visualizzano diversi HTML della stessa pagina in base al dispositivo utilizzato, si consiglia di aggiungere un’intestazione HTTP Vary: User-Agent per aiutare i motori di ricerca a scoprire il contenuto mobile durante la scansione del sito Web, poiché informa che la risposta varia a seconda dell’user agent.
È stato riscontrato che solo il 13.48% delle pagine mobile e il 12.6% delle pagine desktop specificano un’intestazione Vary: User-Agent.
<link rel="alternate" media="only screen and (max-width: 640px)">Si consiglia ai siti web desktop che hanno versioni mobile separate di collegarsi ad essi utilizzando questo tag nella head del loro HTML. È stato rilevato che solo lo 0.64% delle pagine desktop analizzate includeva il tag con il valore dell’attributo media specificato.
Prestazioni web
Avere un sito Web veloce è fondamentale per fornire un’ottima esperienza di ricerca utente. Per la sua importanza è da anni considerato come fattore di ranking dai motori di ricerca. Google ha inizialmente annunciato di utilizzare la velocità del sito come fattore di ranking nel 2010, quindi nel 2018 ha fatto lo stesso per le ricerche su dispositivi mobile.
As announced in November 2020, three performance metrics known as Core Web Vitals are on track to be a ranking factor as part of the “page experience” signals in May 2021. Core Web Vitals consist of:
Largest Contentful Paint (LCP)
- Rappresenta: esperienza di caricamento percepita dall’utente
- Misurazione: il punto nella sequenza temporale di caricamento della pagina in cui l’immagine o il blocco di testo più grande della pagina è visibile all’interno della visualizzazione
- Obiettivo: <2,5 secondi
First Input Delay (FID)
- Rappresenta: reattività all’input dell’utente
- Misurazione: il tempo da quando un utente interagisce per la prima volta con una pagina al momento in cui il browser è effettivamente in grado di iniziare a elaborare i gestori di eventi in risposta a tale interazione
- Obiettivo: <300 millisecondi
Cumulative Layout Shift (CLS)
- Rappresenta: stabilità visiva
- Misurazione: la somma del numero di punti di spostamento del layout che si avvicina alla percentuale del viewport che si è spostato
- Obiettivo: <0.10
Le esperienze di Core Web Vitals per dispositivo
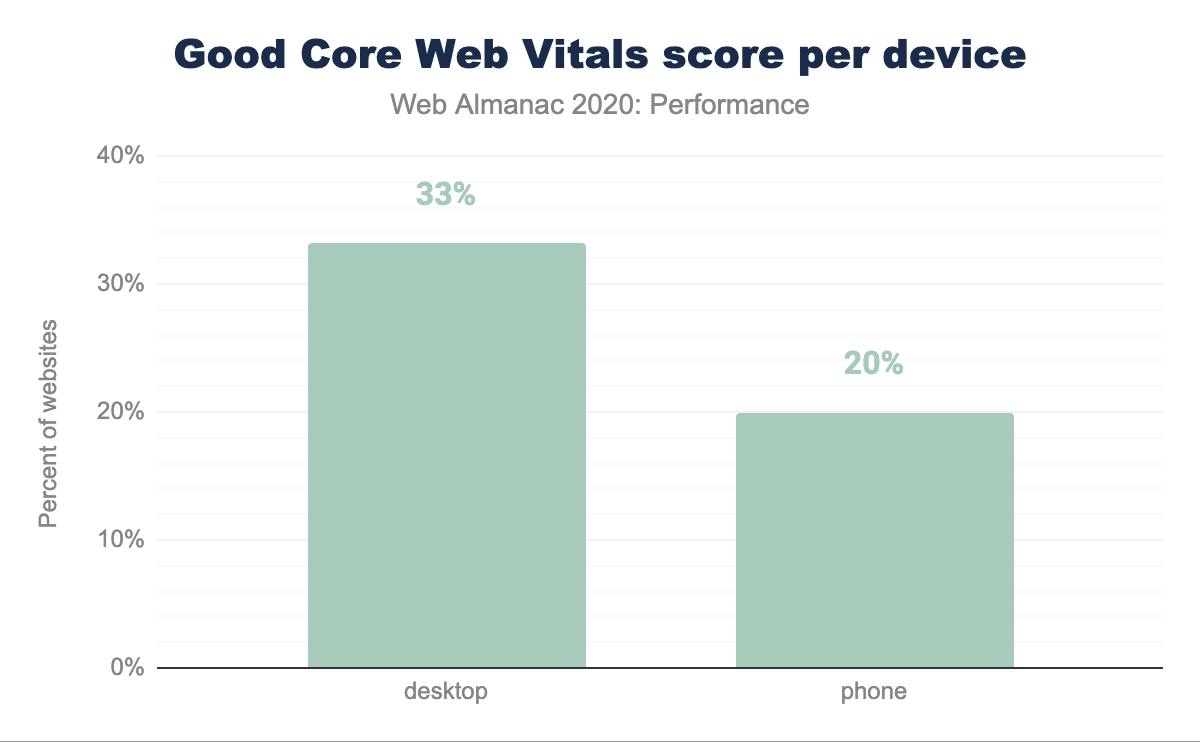
Il desktop continua a essere la piattaforma più performante per gli utenti nonostante il maggior numero di utenti su dispositivi mobile. Il 33.13% dei siti web ha ottenuto Good Core Web Vitals per desktop, mentre solo il 19.96% delle loro controparti mobile ha superato la valutazione Core Web Vitals.
Le esperienze di Core Web Vitals per paese
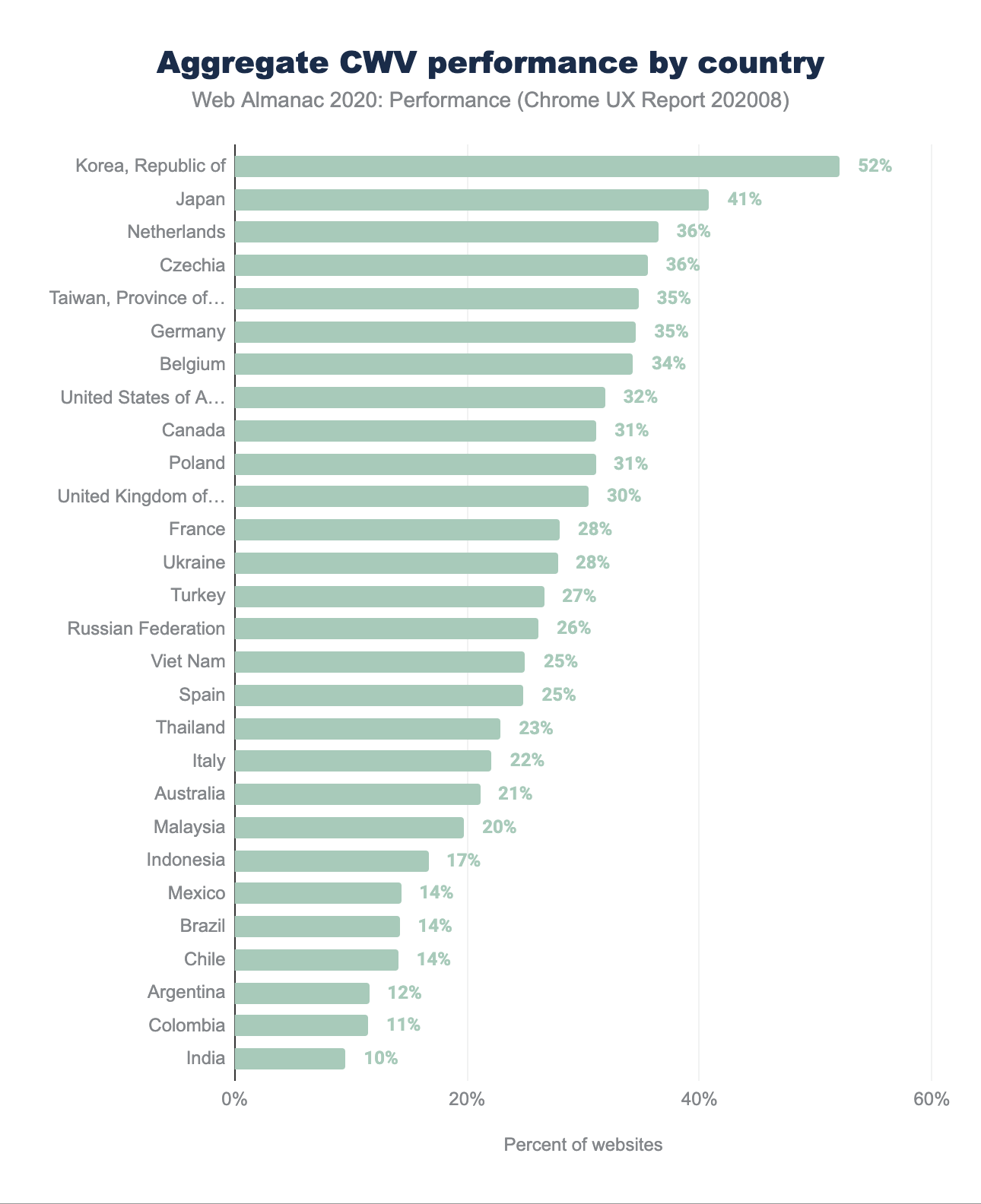
La posizione fisica di un utente influisce sulla percezione delle prestazioni poiché l’infrastruttura di telecomunicazioni disponibile localmente, la capacità di larghezza di banda della rete e il costo dei dati creano condizioni di carico uniche.
Gli utenti negli Stati Uniti hanno registrato il maggior numero assoluto di siti Web con Good Core Web Vitals nonostante solo il 32% dei siti abbia ottenuto il voto di superamento. La Repubblica di Corea ha registrato la percentuale più alta di Good Core Web Vital al 52%. Vale la pena notare la porzione relativa del totale dei siti web richiesti da ciascun paese. Gli utenti negli Stati Uniti hanno generato 8 volte il totale delle richieste di origine generate dagli utenti della Repubblica di Corea.
Ulteriori analisi delle prestazioni di Core Web Vitals per dimensioni in base al tipo di connessione effettivo e metriche specifiche sono disponibili nel capitolo Performance.
Internazionalizzazione
L’internazionalizzazione copre le configurazioni che i siti web multilingue o multipaese possono utilizzare per informare i motori di ricerca sulle loro diverse lingue e/o versioni nazionali, specificare quali sono le pagine rilevanti da mostrare agli utenti in ogni caso ed evitare problemi di targeting.
Le due configurazioni internazionali che abbiamo analizzato sono il meta tag content-language e gli attributi hreflang, che possono essere usati per specificare la lingua e il contenuto di ogni pagina. Inoltre, le annotazioni hreflang consentono di specificare la lingua alternativa o le versioni nazionali di ciascuna pagina.
Motori di ricerca come Google e Yandex usano gli attributi hreflang come segnale per determinare la lingua della pagina e il paese di destinazione, e sebbene Google non utilizzi la lingua HTML o il meta tag content-language, quest’ultimo ultimo tag viene utilizzato da Bing.
hreflang
L’8.1% delle pagine desktop e il 7.48% delle pagine mobile utilizzano l’attributo hreflang, che potrebbe sembrare basso, ma questo è naturale perché vengono utilizzati solo da siti Web multilingue o multinazionali.
Abbiamo scoperto che solo lo 0.09% delle pagine desktop e lo 0.07% delle pagine mobile implementano hreflang tramite le loro intestazioni HTTP e che la maggior parte si basa sull’implementazione HTML head.
Abbiamo anche identificato che ci sono alcune pagine che si basano su JavaScript per rendere le annotazioni hreflang. Lo 0.12% delle pagine desktop e mobile mostra hreflang nella resa ma non nell’HTML grezzo.
Dal punto di vista del valore della lingua e del paese, analizzando l’implementazione tramite la head dell’HTML, abbiamo scoperto che l’inglese (en) è il valore utilizzato più popolare, con il 4.11% delle pagine mobile e il 4.64% delle pagine desktop incluso. Dopo l’inglese, il secondo valore più popolare è x-default (utilizzato quando si definisce una versione default o fallback per utenti di lingue o paesi non target), con il 2.07% delle pagine mobile e il 2.2% delle pagine desktop che lo includono.
Il terzo, il quarto e il quinto più popolari sono il tedesco (de), il francese (fr) e lo spagnolo (es), seguiti dall’italiano (it) e dall’inglese per gli Stati Uniti (en-us) , come si può vedere nella tabella sottostante con il resto dei valori implementati tramite l’HTML head.
| Valore | Mobile | Desktop |
|---|---|---|
en |
4.11% | 4.64% |
x-default |
2.07% | 2.20% |
de |
1.76% | 1.88% |
fr |
1.74% | 1.87% |
es |
1.74% | 1.84% |
it |
1.27% | 1.33% |
en-us |
1.15% | 1.31% |
ru |
1.12% | 1.13% |
en-gb |
0.87% | 0.98% |
pt |
0.87% | 0.87% |
nl |
0.83% | 0.94% |
ja |
0.73% | 0.81% |
pl |
0.72% | 0.75% |
de-de |
0.69% | 0.78% |
tr |
0.69% | 0.66% |
hreflang nella head HTML.
Inoltre è stato trovato nei valori principali di lingua e paese di hreflang implementati tramite le intestazioni HTTP, con l’inglese (en) ancora il più popolare, sebbene in questo caso seguito da francese (fr), tedesco (de), spagnolo (es) e olandese (nl) come valori principali.
| Valore | Mobile | Desktop |
|---|---|---|
en |
0.05% | 0.06% |
fr |
0.02% | 0.02% |
de |
0.01% | 0.02% |
es |
0.01% | 0.01% |
nl |
0.01% | 0.01% |
hreflang nelle intestazioni HTTP.
Content-Language
Analizzando l’utilizzo e i valori di content-language, implementandolo come meta tag nell’HTML head o nelle intestazioni HTTP, abbiamo scoperto che solo l’8.5% delle pagine mobile e il 9.05% delle pagine desktop lo specificavano nelle intestazioni HTTP. Ancora meno siti web stavano specificando la loro lingua o paese con il tag content-language nell’HTML head, con solo il 3.63% delle pagine mobile e il 3.59% delle pagine desktop con il meta tag.
Dal punto di vista del valore della lingua e del paese, abbiamo scoperto che i valori più popolari specificati nel meta-tag content-language e nelle intestazioni HTTP sono l’inglese (en) e l’inglese per gli Stati Uniti (en-us).
Nel caso dell’inglese (en) abbiamo identificato che il 4.34% delle pagine desktop e il 3.69% delle pagine mobile lo specificavano nelle intestazioni HTTP e lo 0.55% del desktop e lo 0.48% delle pagine mobile lo facevano tramite il meta tag content-language nell’HTML head.
Per l’inglese per gli Stati Uniti (en-us), il secondo valore più popolare, è stato rilevato che solo l’1.77% delle pagine mobile e l’1.7% di quelle desktop lo specificavano nelle intestazioni HTTP e lo 0.3% delle pagine mobile e lo 0.36% di quelli desktop lo facevano in HTML.
Il resto della lingua e dei valori nazionali più diffusi può essere visualizzato nelle tabelle seguenti.
| Valore | Mobile | Desktop |
|---|---|---|
en |
3.69% | 4.34% |
en-us |
1.77% | 1.70% |
de |
0.50% | 0.44% |
es |
0.34% | 0.33% |
fr |
0.31% | 0.34% |
ru |
0.18% | 0.16% |
pt-br |
0.15% | 0.16% |
nl |
0.13% | 0.15% |
it |
0.13% | 0.13% |
ja |
0.08% | 0.10% |
content-language nelle intestazioni HTTP.
| Valore | Mobile | Desktop |
|---|---|---|
en |
0.48% | 0.55% |
en-us |
0.30% | 0.36% |
pt-br |
0.24% | 0.24% |
ja |
0.19% | 0.26% |
fr |
0.18% | 0.19% |
tr |
0.17% | 0.13% |
es |
0.16% | 0.15% |
de |
0.15% | 0.11% |
cs |
0.12% | 0.12% |
pl |
0.11% | 0.09% |
content-language nei meta tag HTML.
Sicurezza
Google pone uno specifico interesse sulla sicurezza sotto tutti gli aspetti. Il motore di ricerca conserva elenchi di siti che hanno mostrato attività sospette o sono stati compromessi. Search Console affronta questi problemi e agli utenti di Chrome vengono presentati avvisi prima di visitare i siti con questi problemi. Inoltre, Google fornisce un boost algoritmico alle pagine servite tramite HTTPS (Hypertext Transfer Protocol Secure). Per un’analisi più approfondita su questo argomento, vedere il capitolo Sicurezza.
Utilizzo di HTTPS
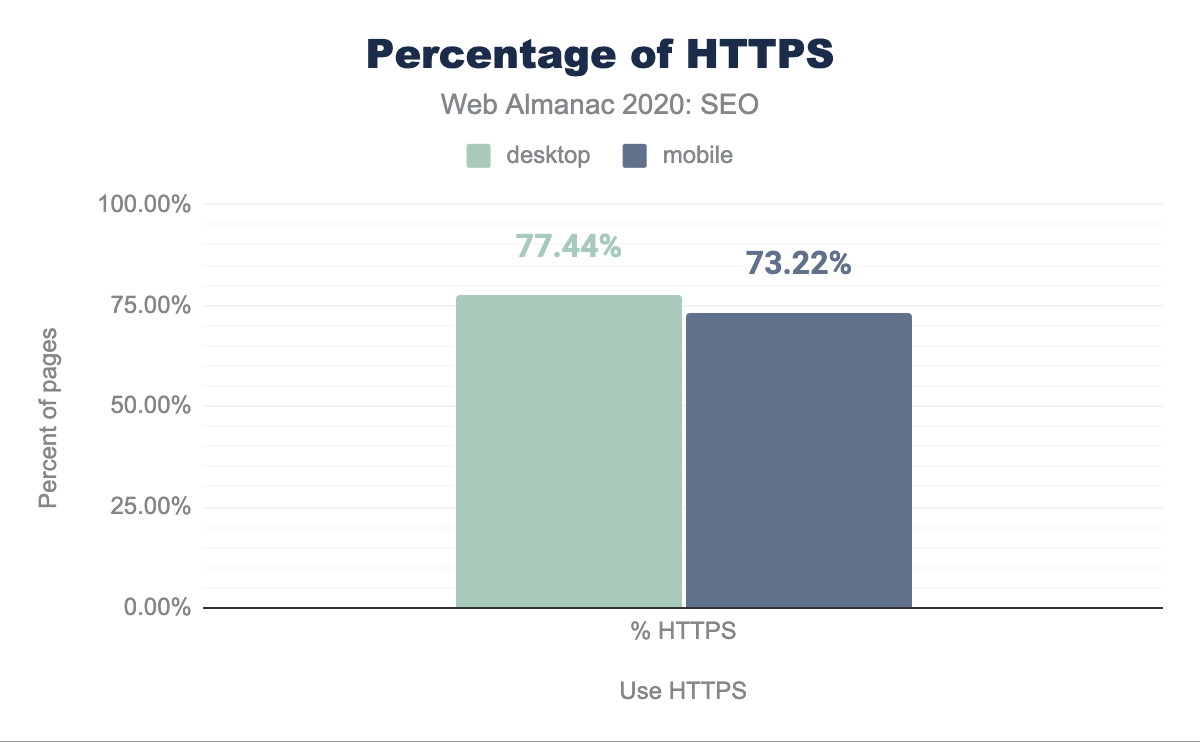
Abbiamo rilevato che il 77.44% delle pagine desktop e il 73.22% delle pagine mobile hanno adottato HTTPS. Questo è il 10.38% rispetto allo scorso anno. È importante notare che i browser sono diventati più aggressivi nello spingere HTTPS segnalando che le pagine non sono sicure quando le visiti senza HTTPS. Inoltre, HTTPS è attualmente un requisito per capitalizzare su protocolli ad alte prestazioni come HTTP/2 e HTTP/3 (noto anche come HTTP su QUIC). Puoi saperne di più sullo stato di questi protocolli nel capitolo HTTP/2.
Tutte queste cose hanno probabilmente contribuito al tasso di adozione più elevato anno dopo anno.
AMP
AMP (precedentemente chiamato Accelerated Mobile Pages) è un framework HTML open source che è stato lanciato da Google nel 2015 per aiutare le pagine a caricarsi più rapidamente, soprattutto sui dispositivi mobile. AMP può essere implementato come una versione alternativa di pagine web esistenti o sviluppati da zero utilizzando il framework AMP.
Quando è disponibile una versione AMP per una pagina, verrà mostrata da Google nei risultati di ricerca per dispositivi mobile, insieme al logo AMP.
È anche importante notare che mentre l’utilizzo di AMP non è un fattore di ranking per Google (o per qualsiasi altro motore di ricerca), la velocità web è un fattore di ranking.
Inoltre, al momento della stesura di questo documento, AMP è un requisito per essere incluso nel carosello di Google Top Stories nei risultati di ricerca per dispositivi mobile, che è una caratteristica importante per le pubblicazioni relative alle notizie. Tuttavia, questo cambierà nel maggio 2021, quando i contenuti non AMP diventeranno idonei a condizione che soddisfino le norme sui contenuti di Google News e fornisce un’ottima page experience come annunciato da Google a novembre di quest’anno.
Durante il controllo dell’utilizzo di AMP come versione alternativa di una pagina non basata su AMP, abbiamo scoperto che lo 0.69% delle pagine web mobile e lo 0.81% di quelle desktop includevano un tag amphtml che puntava a una versione AMP. Sebbene l’adozione sia ancora molto bassa, si tratta di un leggero miglioramento rispetto ai risultati dello scorso anno, in cui solo lo 0.62% delle pagine mobile conteneva un link a una versione AMP.
D’altra parte, nel valutare l’utilizzo di AMP come framework per lo sviluppo di siti Web, abbiamo riscontrato che solo lo 0.18% delle pagine mobile e lo 0.07% di quelle desktop specificava <html amp> o l’attributo emoji <html ⚡>, il quale vengono utilizzati per indicare le pagine basate su AMP.
Applicazioni Single-page
Le applicazioni Single-page (SPA) consentono ai browser di conservare e aggiornare il caricamento di una singola pagina anche se il contenuto della pagina viene aggiornato per soddisfare una richiesta dell’utente. Molteplici tecnologie come framework JavaScript, AJAX e WebSocket vengono utilizzate per eseguire leggeri caricamenti di pagine sequenziali.
Questi framework richiedevano considerazioni SEO speciali, sebbene Google abbia lavorato per mitigare i problemi causati dal rendering lato client con strategie di caching aggressive. In un video dalla conferenza di Google Webmaster del 2019, il Software Engineer Erik Hendriks ha condiviso che Google non fa più affidamento sulle intestazioni Cache-Control e cerca invece le intestazioni ETag o Last-Modified per vedere se il contenuto del file è cambiato.
Le SPA dovrebbero utilizzare le Fetch API per il controllo granulare della memorizzazione nella cache. L’API consente il passaggio di oggetti Request con specifici override della cache impostati e può essere utilizzata per impostare le intestazioni If-Modified e ETag necessarie.
Le risorse non rilevabili sono ancora la preoccupazione principale dei motori di ricerca e dei loro web crawler. I crawler di ricerca cercano gli attributi href nei tag <a> per trovare le pagine collegate. Senza questi, la pagina viene vista come isolata senza link interni. Il 5.59% delle pagine desktop studiate non conteneva link interni e il 6.04% delle pagine mobile renderizzate. Questo è un indicatore del fatto che la pagina fa parte di un framework SPA JavaScript e il tag mancante necessario <a> con attributi href validi richiesti per il loro collegamento interno da scoprire.
La rilevabilità dei link nei framework JavaScript più diffusi utilizzati per le SPA è aumentata notevolmente nel 2020 rispetto all’anno precedente. Nel 2019, il 13.08% dei link di navigazione mobile sui siti React utilizzava hash URL deprecati. Per il 2020, solo il 6.12% dei link React testati è stato sottoposto ad hashing.
Allo stesso modo, Vue.js ha registrato un calo al 3.45% dall’8.15% dell’anno precedente. Angular era il meno propenso a utilizzare link di navigazione mobile con hash non scansionabili nel 2019 con solo il 2.37% delle pagine mobile che li utilizzavano. Per il 2020, quel numero è precipitato allo 0.21%.
Conclusione
Coerentemente con quanto trovato e concluso lo scorso anno, la maggior parte dei siti ha pagine desktop e mobile sottoponibili a scansione e indicizzabili inoltre utilizzano le configurazioni fondamentali relative alla SEO.
È importante evidenziare come la rilevabilità dei link per i principali framework JavaScript utilizzati per le SPA sia aumentata notevolmente rispetto al 2019. Testando i link di navigazione mobile per gli URL con hash, abbiamo visto -53% istanze di link non scansionabili da siti che utilizzano React, -58% in meno da siti basati su Vue.js e una riduzione del -91% da Angular.
Inoltre, abbiamo anche riscontrato un leggero miglioramento rispetto ai risultati dello scorso anno in molte delle aree analizzate:
-
robots.txt: L’anno scorso il 72.16% dei siti per dispositivi mobile aveva unrobots.txtvalido rispetto al 74.91% di quest’anno. - canonical tag: L’anno scorso abbiamo rilevato che il 48.34% delle pagine per dispositivi mobile utilizzava un tag canonico rispetto al 53.61% di quest’anno.
-
titletag: Quest’anno abbiamo rilevato che il 98.75% delle pagine desktop ne presenta uno, mentre lo include anche il 98,7% delle pagine mobile. Il capitolo dello scorso anno ha rilevato che il 97.1% delle pagine mobile presentava un tagtitle. -
metadescription: Quest’anno, abbiamo riscontrato che il 68.62% delle pagine desktop e il 68.22% di quelle mobile avevano una descrizionemeta, un miglioramento rispetto allo scorso anno, quando il 64.02% delle pagine mobile ne aveva una. - dati strutturati: Nonostante il fatto che le recensioni non dovrebbero essere associate alle home page, i dati indicano che
AggregateRatingè aumentato del 23.9% su dispositivi mobile e del 23.7% su desktop. - Utilizzo di HTTPS: Il 77.44% delle pagine desktop e il 73.22% delle pagine mobile hanno adottato HTTPS. Questo è il 10.38% rispetto allo scorso anno.
Tuttavia, non tutto è migliorato nell’ultimo anno. La pagina desktop mediana include 61 link interni mentre la pagina mobile mediana ne ha 54. Questo è in calo rispettivamente del 12.8% e del 10% rispetto l’anno scorso, suggerendo che i siti non stanno massimizzando la capacità di migliorare la crawlability e il flusso di link equity attraverso le loro pagine.
È anche importante notare come vi sia ancora un’importante opportunità di miglioramento in molte aree e configurazioni critiche relative alla SEO. Nonostante il crescente utilizzo di dispositivi mobile e il passaggio di Google a un indice mobile-first:
- Il 10.84% delle pagine mobile e il 16.18% di quelle desktop non includono affatto il tag
viewport, il che suggerisce che non sono ancora mobile friendly. - Sono state riscontrate disparità non banali tra le pagine mobile e desktop, come quella tra i link mobile e desktop, illustrata nei 62 link sui dispositivi mobili rispetto ai 68 link sul desktop per la pagina web mediana.
- Il 33.13% dei siti web ha ottenuto Good Core Web Vitals per desktop, mentre solo il 19.96% delle loro controparti mobile ha superato la valutazione Core Web Vitals, suggerendo che il desktop continua ad essere la piattaforma più performante per gli utenti.
Questi risultati potrebbero avere un impatto negativo sui siti poiché Google completa la migrazione a un indice mobile first nel marzo 2021.
Sono state riscontrate disparità anche tra HTML renderizzato e non renderizzato. Ad esempio, la pagina mobile mediana mostra l’11.5% di parole in più quando è renderizzato rispetto al suo HTML grezzo, indicando che si fa affidamento su JavaScript lato client per mostrare il contenuto.
I crawler di ricerca cercano i tag <a href> per trovare le pagine collegate. Senza questi, la pagina viene vista come isolata senza link interni. Il 5.59% delle pagine desktop non conteneva link interni e il 6.04% delle pagine mobile renderizzate.
Questi risultati suggeriscono che i motori di ricerca sono in continua evoluzione nella loro capacità di eseguire la scansione, l’indicizzazione e il posizionamento dei siti Web in modo efficace e alcune delle più importanti configurazioni SEO vengono ora prese in maggiore considerazione.
Tuttavia, molti siti sul Web stanno ancora perdendo importanti visibilità nella ricerca e opportunità di crescita, il che mostra anche il bisogno persistente di evangelizzare il SEO e l’adozione di best practice tra le organizzazioni.


