Structured Data
Introduction
This is the second year that the Web Almanac has included a chapter on structured data. Last year’s content gave a solid grounding in the concept of structured data, outlining the reason it exists, the most frequently used types, and how it benefits organizations. This year we compared data gathered in 2022 with the previous data from last year, so were able to monitor trends that occurred within that period.
Despite many advances in machine learning and in particular the field of “natural language progressing”, data still needs to be presented in a machine-readable format. Structured data assists in information discoverability in web search, data linkage and archival purposes. By implementing structured data on websites, engineers and web content creators facilitate:
- making website data more widely available for automated discovery and linking
- the open availability of data for public research
- ensuring the quality of the organization’s data is maintained when the data leaves its origin
Organizations of all sizes and types want their content to be discovered on the web. Search engines such as Google and Bing emphasize data discoverability by promoting the use of structured data. From an SEO point of view, it is advantageous to present data in an easy to find and parse manner. Some of these advantages will be discussed in the use cases and key concepts sections within this chapter.
Last year’s introduction pointed out that “when machines can reliably extract structured data, at scale, we enable new and smarter types of software, systems, services and businesses”. This year’s chapter includes sections that explore recently published research on structured data, open source frameworks and tools that assist the generation of high-quality structured data.
This year we provide the first year over year comparison of metrics such as the presence of different structured data types as well as the growth of those structured data types, and examines the evolving benefits of using structured data. Having a baseline of data from 2021 allows us to gain insights into how the use of structured data has changed over the intervening period and observe interesting trends, for example the growth of TikTok in the period.
Data caveats
Structured data can appear in many forms, and may be more visible in certain domains, and their corresponding websites, over others. For example, compare a news website with an ecommerce website. In general, a news site shows the most important breaking news on its home page, therefore the structured data relating to the news articles may be present on the main website landing page attached as data-snippets to the individual article headlines. In comparison, structured data in ecommerce pertains to individual products and, as such, is mostly present within a website’s product catalog itself, and in many ways, “hidden” from a high level search of the main navigation and promotional parts of the website. This is the key caveat that we need to be aware of in relation to the structured data chapter and report.
Due to the fact that the technology used to harvest data from websites only scratches the surface of sites (ie: the home pages), and does not go into depth on a full crawl of the site, we are unable to get a full picture of the extent of structured data usage in sites where such data is by necessity, contained deep within the site. In future years we hope to take a sample of sites across different domains and go deep to rectify this issue and give additional insight into domain-specific use of structured data.
The high level caveats from last year’s chapter still remain, namely:
-
Auto-generated structured data: This is where technologies such as content creation systems auto-generate structured data snippets based on templates. In this case any template-based error will inevitably populate across all data presented.
-
Data format overlaps: Structured data can be presented in a number of different ways, including JSON-LD, RDF etc. This means that we may see overlap, for example, between a Facebook meta tag and the same tag presented in a different manner in the RDFa section. As analysis is tightly based on queries created for the baseline in 2021, we expect the impact of cleaning/normalization and data flattening should carry through for like analysis.
Key concepts
As structured data is a rich and complex area, it is important to explore and explain some key concepts of the topic before diving head-first into further analysis.
Linked data
By adding structured data to web pages, and providing URI links to the entities the pages contain/reference, we create linked data. This structured data is then interlinked, making it more useful through semantic queries.
Adding linked data to describe web page content enables machines to treat web pages as databases. At a large scale, this contributes to the semantic web. The semantic web links data together through The Resource Description Framework (RDF). This is a framework for representing information on the web using URIs to define entities and the relationships between them.
A relationship between entities in the RDF data model is known as a semantic triple. With a semantic triple (or just triple), we can codify a statement about data. These expressions follow the form of subject–predicate–object (e.g., “Allen knows John”).
To be able to retrieve and manipulate RDF data, we can use an RDF Query Language such as SPARQL, the standard RDF query language.
As will be discussed later, this semantic web creates many opportunities for business and technology.
Open data
Linked data may also be open data, described as Linked Open Data. Open data, as the name implies, is data that is openly accessible to anyone for any purpose. This data is licensed under an open license.
Open data is the first of the 5 stars of open data, a deployment scheme suggested by Tim Berners-Lee. According to the open data handbook, to score the maximum five stars, data must (1) Be available on the Web under an open license, (2) Be in the form of structured data, (3) Be in a non-proprietary file format, (4) Use URIs as its identifiers, (5) Include links to other data sources (see data linking).
While structured data is the second star in the 5 star open data plan, linked data should fulfill requirements for all 5 stars of open data.
Semantic search engines, rich results and beyond
A semantic search engine is one which performs semantic search. This is different from lexical search where search engines look for exact or close matches to words or strings of text. Semantic search aims to understand the user’s intent and the context of the search terms in order to improve the accuracy of search. An example would be a structured data entity of “local business: hairdresser” versus “TG Locks n Lashes”; the latter is a business name, and while it tells the creative name of the hair salon as a key-word, it does little to help the search engine to understand what the business does. By using structured data, the website can better help the search engine understand the context of its information, and thus enable the engine to offer better search results in the context of the query asked by the search user. Google and Bing are excellent examples of semantic search engines.
Google uses semantic search technologies to serve relevant information from the Google Knowledge Graph which is a knowledge base used to serve search results in an infobox. This infobox is known as a knowledge panel, and can be seen in many results. This knowledge box can be enabled or enhanced by structured data.
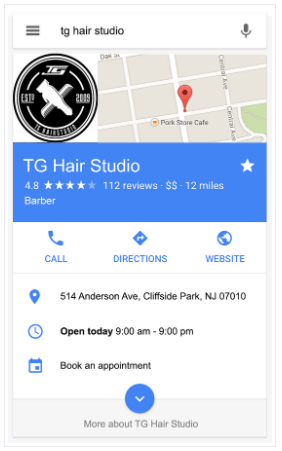
Another search result that is made possible by structured data combined with linked data is the rich result. These results display richer features in search results, and come in the form of Events, FAQs, How-tos, Job listings and many more. Implementing structured data to make web pages eligible for rich results could increase clickthrough rate. The image below illustrates how structured data with business details for a Hair Studio allows the search engine to easily extract and display information about the business, highlighting it and optimizing SEO.
Beyond knowledge panels and web page rich results, structured data can also enable answers to factual queries in search. A factual query search can get multiple signals from different structured data sources and support more precise results. Here, structured data implementation, and the technologies that allow for it, provide faster and more reliable access to information in order to improve user experience.
The combination of SEO importance, higher click-through rates, improved user experience and machine-readable data being accessible for analysis illustrate significant benefits to implementing structured data. Understanding these key concepts will help both content providers and technical personnel who construct sites how to implement better navigation and understand the function of automated data consumption from web pages.
Structured Data research
For this year’s chapter we were interested in investigating what—if any—academic research has been carried out in the area of structured data, or if structured data was documented as being used to assist in development of state-of-the-art technologies and services.
To look for published research, we used academic search tools such as Google Scholar, ConnectedPapers and University-based citation databases. We not only looked for recent publications, but also older research that continues to be cited.
The results of our search showed that there is not a lot of highly cited recent work conducted into generating, managing and building structured web data. However, research on the application of structured web data (“The Semantic Web”) like knowledge graphs, recommendation engines, information retrieval, chatbots and explainable AI has been conducted in the past twelve months and continues to grow.
Web structured data shares a synergetic relationship with the field of machine learning by providing consistent data with appropriate Uniform Reference Indicator (URI) vocabulary which can be used to generate machine readable labels. Our searches and background reading have shown that structured data has considerably reduced the work and time input to generate high quality web data for training machine learning algorithms.
On a practical level, we highlight three areas that structured data has improved:
- Knowledge graphs
- Question Answering over Knowledge Graphs
- Explainable AI
Knowledge graphs
Structured web data provides fixed vocabularies between entities and objects as a domain-specific language, which are generally stored in a RDF format. Knowledge graphs using RDF have proven to be great tools for querying relationships between entities. As an example, Wikidated 1.0 is an evolving knowledge graph which uses web structured data to store Wikipedia’s revision history. Its corresponding paper talks through the process of aggregating revisions to a page as a set of additions and deletions of the RDF tuple. The authors have open sourced their method to convert wikipedia dumps into knowledge graphs. Applied research carried out by doordash engineering demonstrates that using knowledge graphs can dramatically improve search performance.
Question Answering over Knowledge Graphs
Question answering systems enable end users to find answers to their questions. When built upon a knowledge graph, a question answering system makes it possible to access the rich and structured data stored in knowledge graphs. Query languages such as SPARQL are often used to query the information stored as RDF triples in knowledge graphs.
However, writing SPARQL queries can be tedious and challenging for end-users. Therefore, natural language questions (NLQs) are an attractive solution that allows overcoming the numerous complexities of querying knowledge graphs. This work proposes a KG-based question answering system (KGQAS) that consists of two main phases: 1) an offline phase, and 2) a semantic parsing phase.
While the offline phase aims to convert natural language questions into formal query patterns in a semi-automated way, the semantic parsing phase leverages machine learning to build a prediction model. The model is trained on the output of the first phase. It enables predicting the most appropriate query pattern for a given question. For evaluation, SalzburgerLand KG is used as a practical use case. It’s a real-world knowledge graph that is built using the schema markup vocabulary and its primary focus is structured data automation that describes touristic entities of the region of Salzburg, Austria.
Explainable AI
Explainable AI focuses on explaining decisions of an AI model. Most AI models are not openly available to the public, and so do not provide rationale for the decisions they make. Owing to knowledge graphs built on top of semantic web; harder to find relationships between entities can be found. These are then used as ’ground truth’ to trace back the results of the model. The most common approach is to map network inputs or neurons to classes of an ontology or entities of a web structured data.
References:
- Knowledge graphs: Wikidated 1.0: An Evolving Knowledge Graph Dataset of Wikidata’s Revision History
- Question Answering Over Knowledge Graphs: Question Answering Over Knowledge Graphs: A Case Study in Tourism
- Explainable AI using structured data: Semantic Web Technologies for Explainable Machine Learning Models: A Literature Review
Open source use of Structured Data
Three projects of note that rely heavily on the use of structured data are the following:
- Open Source Metadata Framework (OMF) - The OMF aims to collect data about Open Source documentation / metadata which are typically stored in a structured data format that will be used to describe the documentation. The idea is that the OMF will act as a sophisticated card catalog type of system for the numerous Open Source documentation projects that exist.
- DBpedia is a set of datasets, tools and services related to structured web data. It contains more than 228 million freely-available entities to date. The main DBpedia Knowledge Graph encompasses clean data from Wikipedia. DBPedia is available in all supported Wikipedia languages and averages over 600k file downloads per year. Some open source tools that are built on top of DBpedia provide data access, versioning, quality control, ontology visualization and linking infrastructures.
- Wikidata stores structured data from Wikimedia projects like Wikipedia. It is a document-oriented database, which focuses on storing structured web data.
Use cases
The implementation of structured data is widely beneficial in numerous areas, some of which will be focused on in this section. It is important to note that many of these areas are overlapping, such is the nature of linked and structured data.
Data linking
Having structured and linked data, while using identifiers to designate places, events, people, concepts, etc, the data can be cited by other data sources and therefore make their metadata descriptions more accessible. This data is then more shareable and reusable.
With data linking, we collect information from different sources to create richer and more useful data. This is possible thanks to structured data, whose global, unique identifiers allow machines to read and understand the relationship between different types of data. This has the use of creating a more connected web of relationships.
Search Engine Optimization & discoverability
Search engine optimization (SEO) is the area focusing on building the content of a web page so that it has better results from search engines. Naturally, this is highly important for discoverability as a successful implementation of SEO may allow for a page to appear higher on the search engine results page (SERP). The SERP is where the titles, URLs, and meta descriptions are displayed from a search query.
By adding structured data to web pages, we can optimize a web page for search engines, as well as have extra content visible from the SERP. This extra content can come in many forms, some of which has been discussed previously, namely Knowledge Panels, Rich Snippets and Related Questions.
Having this added discoverability, enabled by structured data, is essential for increasing traffic to a web page from search engines. It follows that businesses and ecommerce pages would find great value in these technologies, which will be discussed in the following section.
Ecommerce & business
The implementation of structured data for ecommerce web pages is incredibly beneficial for those involved with the business. There are numerous structured data types which are widely used for these businesses for SEO.
LocalBusiness is a structured data type which may return a Google knowledge panel with details entered in the structured data type during relevant search queries (e.g. “popular restaurants in Dublin”). This type also may have business hours, different departments within a business, reviews for the business, which could all be returned from a maps app search query as well.
Product, the structured data type, works similarly to LocalBusiness in that it allows for a search query to return rich results. These results can include price, availability, reviews, ratings, and even images in the search results. These added elements can make the product far more likely to receive attention from the search. Product attributes can help link products together and better respond to search queries, increasing discoverability.
These are just a couple of examples of use cases for structured data in ecommerce, but there are many more structured data types that an ecommerce page can benefit from implementing.
A year in review
Structured data is underpinned by formats and standards that describe a meta-level schema into which publishers can fit and present data in a pre-defined manner. RDFa, OpenGraph, JSON-LD and other established formats have been used in the analysis for this chapter.
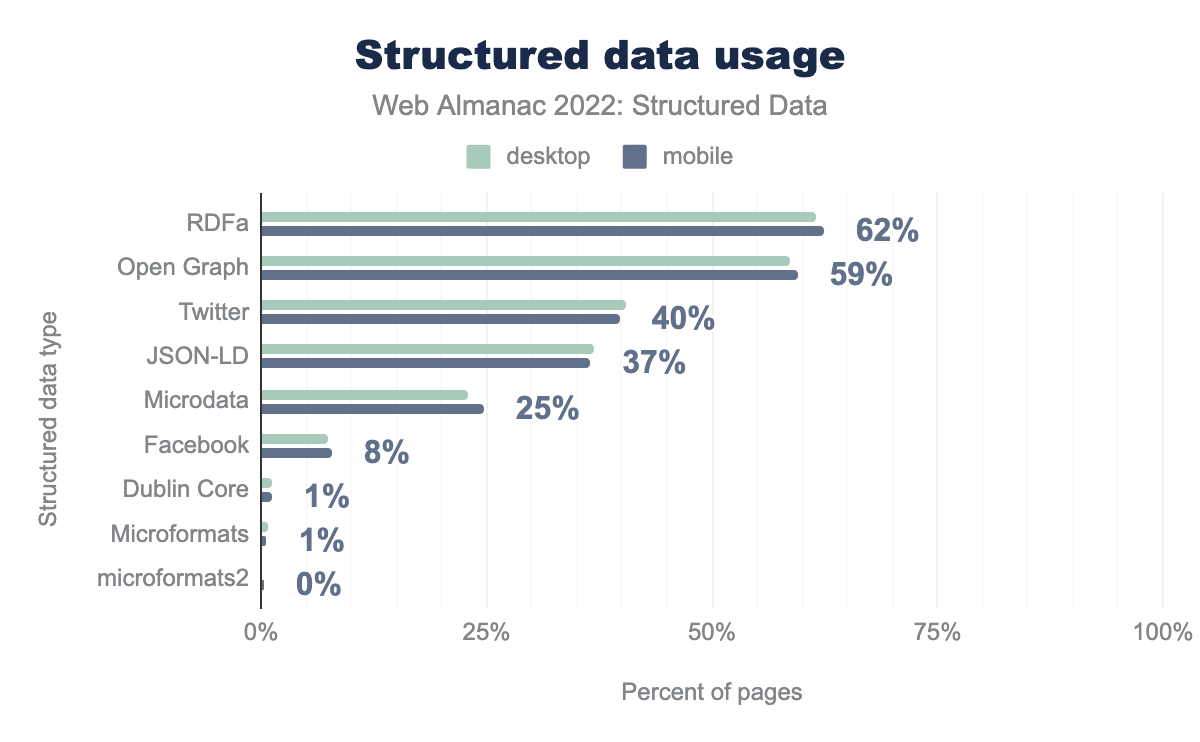
RDFa and Open Graph remain in the majority with 62% and 57% of mobile pages, respectively. Structured data types are seen consistently across mobile and desktop pages, with Microformats and microformats2 differing the most from other structured data types we examined in this chapter. Microformats are 86% as prominent on mobile pages, whereas microformats2 are 171% as prominent on mobile pages. These two structured data types make up a small percentage of those found in our set.
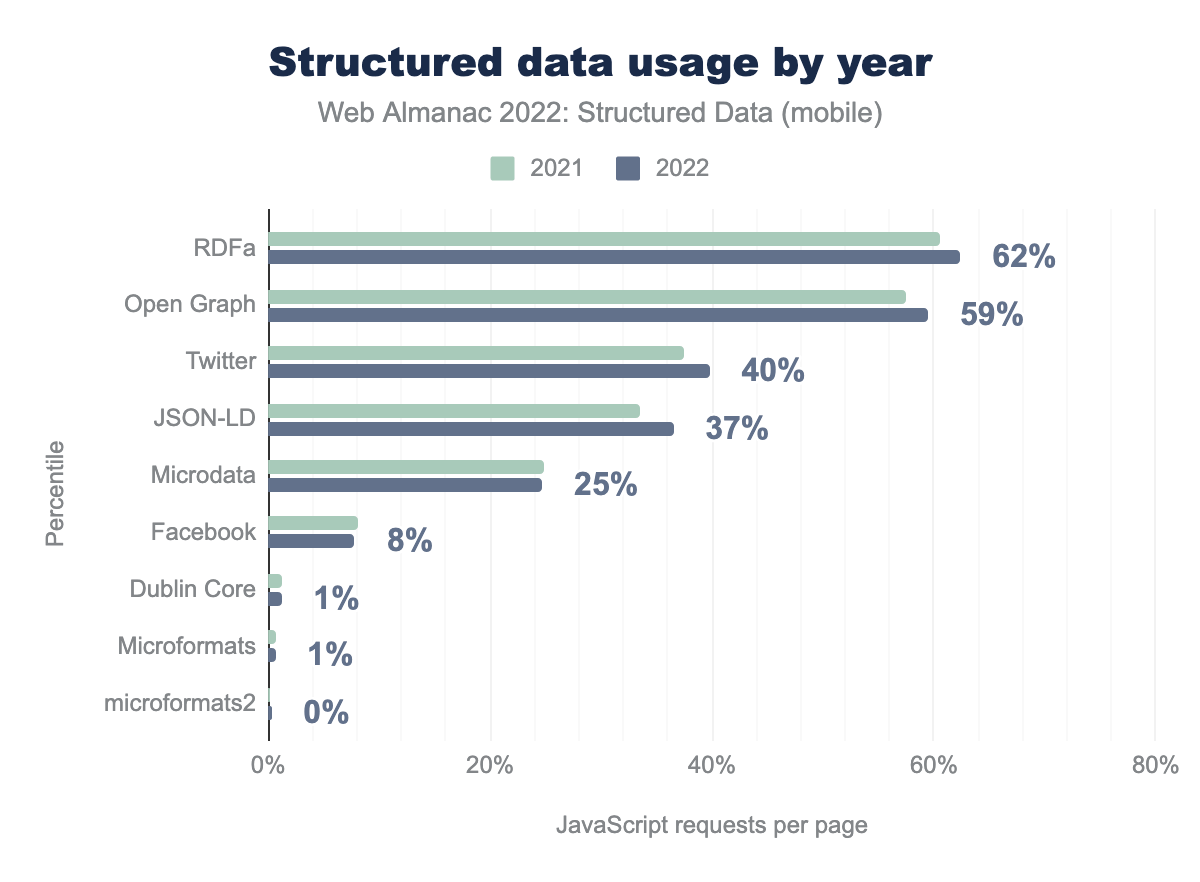
A general increase in these widely-used structured data types can be seen, including Twitter meta tags (which has increased from 37% to 40%) and JSON-LD (which has increased coverage from 34% overall in 2021 to 37% overall in 2022). There is a slight decrease in usage for some of the less prevalent structured data types such as Microdata, Facebook meta tags, Dublin Core and Microformats. Desktop movements were very similar.
The below table lists the major changes to structured data formats in the last year. Only types with changes have been listed.
| Data type | Change |
|---|---|
| RDFa |
Although there are no changes in the base format of RDFa, version 3 of the Data Catalog Vocabulary (DCAT) contained a significant update. DCAT is an “RDF vocabulary designed to facilitate interoperability between data catalogs published on the Web”. This is significant due to the increased availability of open datasets on the web. Being able to describe the entire contents of a dataset greatly increases the discoverability, and thus usefulness, of a public dataset and makes federated search and distribution more likely.
References:
|
| JSON-LD |
Updates and additions in the past year were minor. Of these, most were related to maintenance and minor expansion of context, for example “adding OnlineBusiness as a subtype of Organization and OnlineStore as a subtype of OnlineBusiness”.
References: |
Overall there has been little change in the definitions of the major data types as the table outlines, however some formats have been advanced in specific domains.
Let’s delve a little deeper into each type.
RDFa
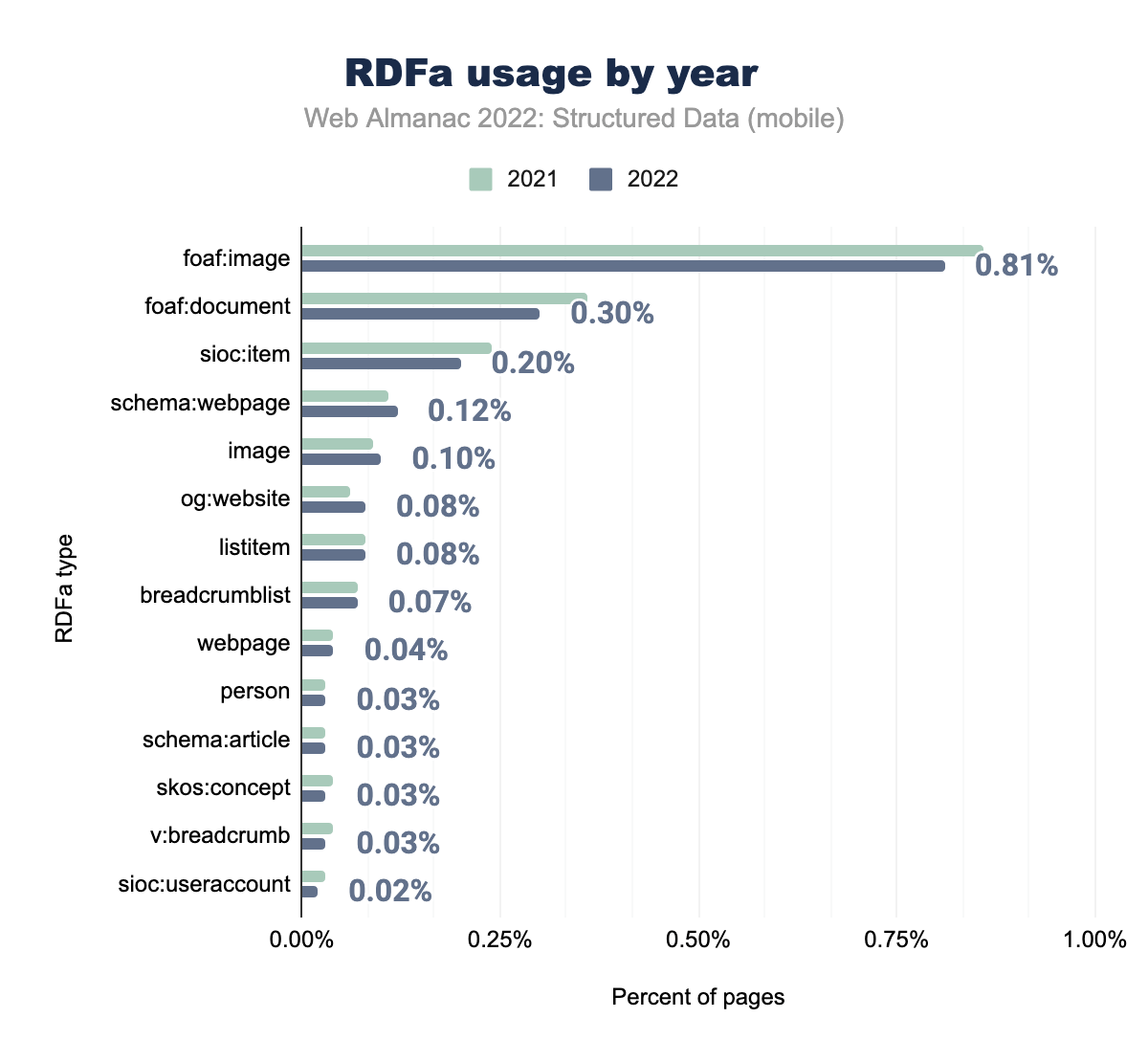
foaf:image on was used on 0.86% of pages in 2021 and 0.81% in 2022, foaf:document on 0.36% and 0.30% respectively, sioc:item on 0.24% and 0.20%, schema:webpage on 0.11% and 0.12%, image on 0.09% and 0.10%, og:website on 0.06% and 0.08%, listitem on 0.08% and 0.08%, breadcrumblist on 0.07% and 0.07%, webpage on 0.04% and 0.04%, person on 0.03% and 0.03%, schema:article on 0.03% and 0.03%, skos:concept on 0.04% and 0.03%, v:breadcrumb on 0.04% and 0.03%, and finally sioc:useraccount was used on 0.03% of pages in 2021 and 0.02% in 2022.When evaluating the types of RDFa, foaf:image remains present on more pages than any other type, though it has shown a decrease in the percent of pages in our set since 2021. This applies to the next two types, foaf:document and sioc:item, with small decreases in usage. Many of the other types show a slight increase in usage, as RDFa has seen as a whole.
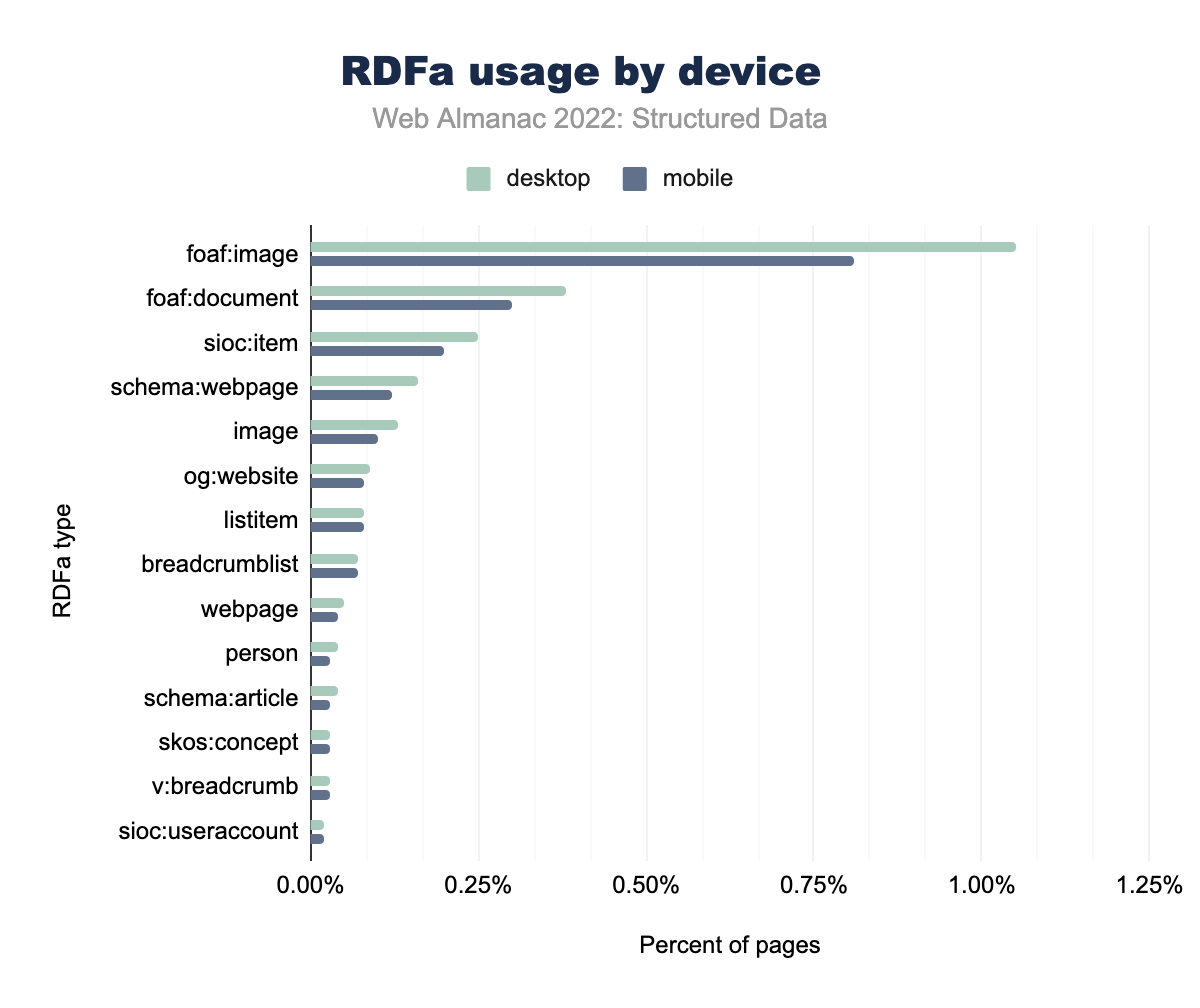
foaf:image was used on 1.05% of desktop and 0.81% of mobile pages, foaf:document on 0.38% and 0.30% respectively, sioc:item on 0.25% and 0.20%, schema:webpage on 0.16% and 0.12%, image on 0.13% and 0.10%, og:website on 0.07% and 0.08%, listitem on 0.09% and 0.08%, breadcrumblist on 0.08% and 0.07%, webpage on 0.05% and 0.04%, person on 0.03% and 0.03%, schema:article on 0.04% and 0.03%, skos:concept on 0.04% and 0.03%, v:breadcrumb on 0.03% and 0.03%, and finally sioc:useraccount on 0.02% of both desktop and mobile pages.RDFa remains more prominent on desktop with foaf:image appearing on 1% of desktop pages, compared to 0.81% on mobile pages. Other RDFa types saw a slight increase in appearance on desktop pages over mobile, with the exception of og:website reaching ahead with 0.08% on mobile pages and 0.07% on desktop pages.
Dublin Core
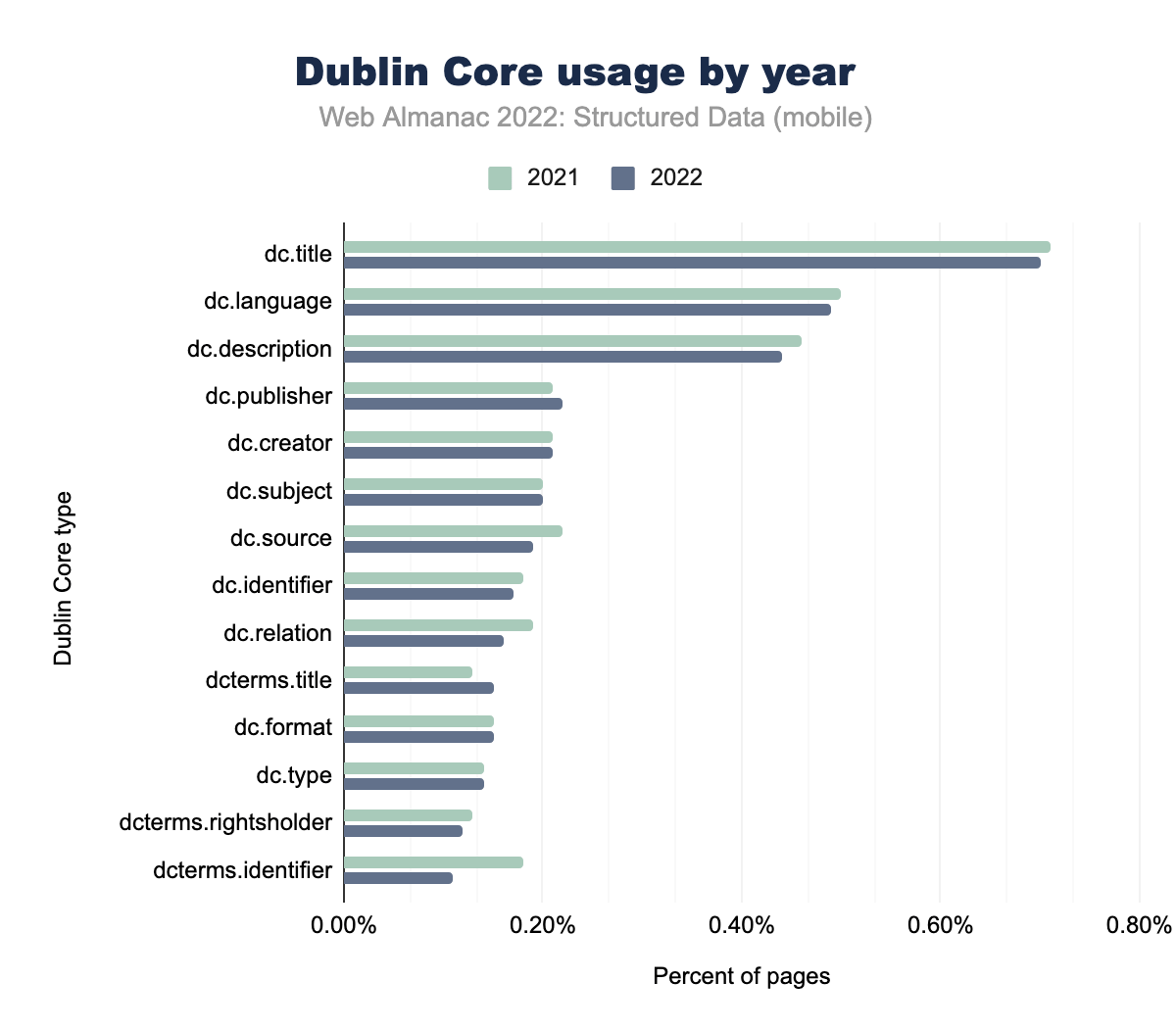
dc.title was used on 0.71% of mobile pages in 2021 and 0.70% in 2022, dc.language on 0.50% and 0.49% respectively, dc.description on 0.46% and 0.44%, dc.publisher on 0.21% and 0.22%, dc.creator on 0.21% and 0.21%, dc.subject on 0.20% and 0.20%, dc.source on 0.22% and 0.19%, dc.identifier on 0.18% and 0.17%, dc.relation on 0.19% and 0.16%, dcterms.title on 0.13% and 0.15%, dc.format on 0.15% and 0.15%, dc.type on 0.14% and 0.14%, dcterms.rightsholder on 0.13% and 0.12%, and finally dcterms.identifier on 0.18% of mobile pages in 2021 and 0.11% in 2022.Dublin Core attribute type usage remains very similar across the most prominent attribute types. A notable exception is dcterms.identifier, going from 0.11% in 2021 to 0.18% in 2022 for mobile pages. Though small in percentage, this totals to a usage count of nearly 15,000 in our set. This increase was also seen for desktop pages, though not as substantial, going from 0.14% in 2021 to 0.18% in 2022.
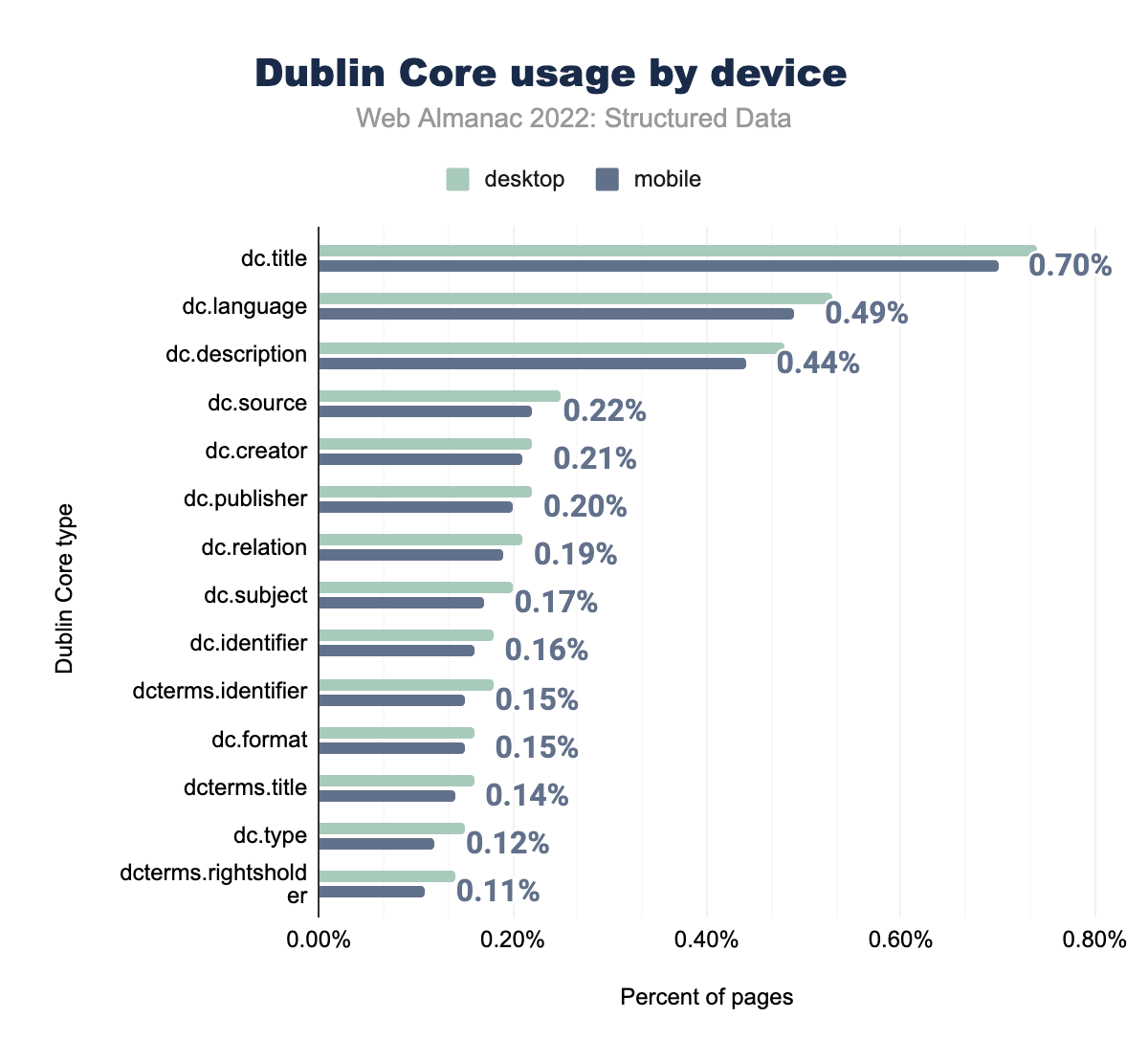
dc.title was used on 0.74% of desktop and 0.70% of mobile pages, dc.language on 0.53% and 0.49% respectively, dc.description on 0.48% and 0.44%, dc.publisher on 0.22% and 0.22%, dc.creator on 0.22% and 0.21%, dc.subject on 0.20% and 0.20%, dc.source on 0.25% and 0.19%, dc.identifier on 0.18% and 0.17%, dc.relation on 0.21% and 0.16%, dcterms.title on 0.16% and 0.15%, dc.format on 0.16% and 0.15%, dc.type on 0.15% and 0.14%, dcterms.rightsholder on 0.14% and 0.12%, and finally dcterms.identifier on 0.18% of desktop and 0.11% of mobile pages.Other than that, Dublin Core types are similar between mobile and desktop pages, sharing the same slight increase in appearances compared to the previous year.
Open Graph
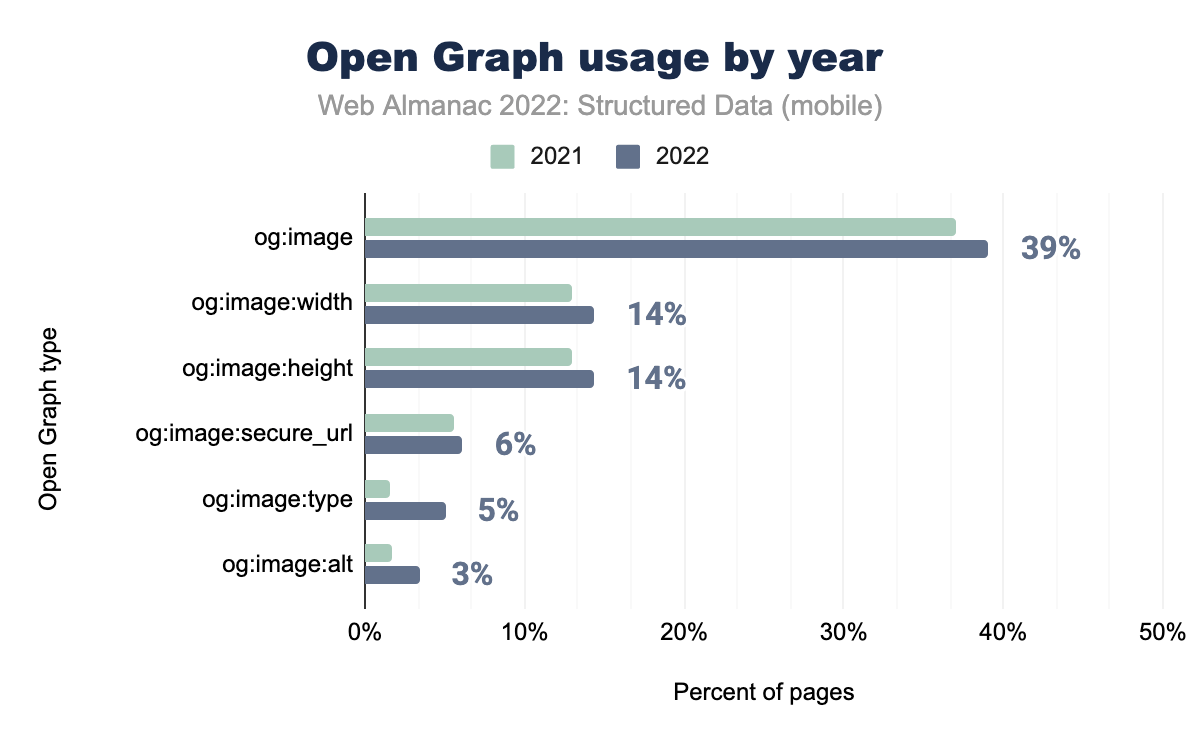
og:image was used on 37% of mobile pages in 2021 and 39% in 2022, og:image:width on 13% and 14% respectively, og:image:height on 13% and 14%, og:image:secure_url on 6% and 6%, og:image:type on 2% and 5%, and finally og:image:alt on 2% of mobile pages in 2021 and 3% in 2022.Open Graph tags have seen a widespread increase in use. The most common of these tags is og:title appearing in over half of all pages in our set, joined by og:url and og:type. Most of these increases are small, with og:image:type as an exception which more than tripled on mobile pages since 2021. This is matched by desktop, going from 1.6% to 5.4% over the course of the year.
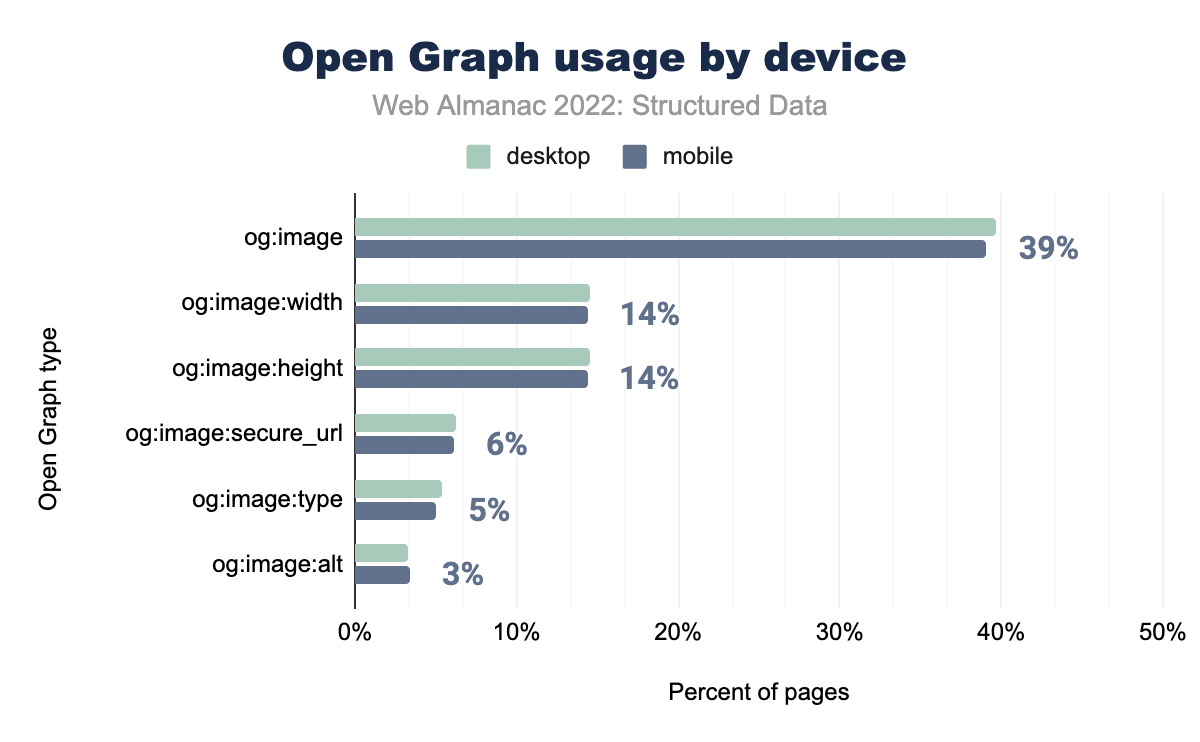
og:image was used on 40% of desktop and 39% of mobile pages, og:image:width on 15% and 14% respectively, og:image:height on 15% and 14%, og:image:secure_url on 6% and 6%, og:image:type on 5% of both, and finally og:image:alt was used on 3% of both desktop and mobile pages.We have seen an increase in use for each Open Graph type in the top 10 for both mobile and desktop, resulting in Open Graph’s relative growth of 1.5% since 2021.
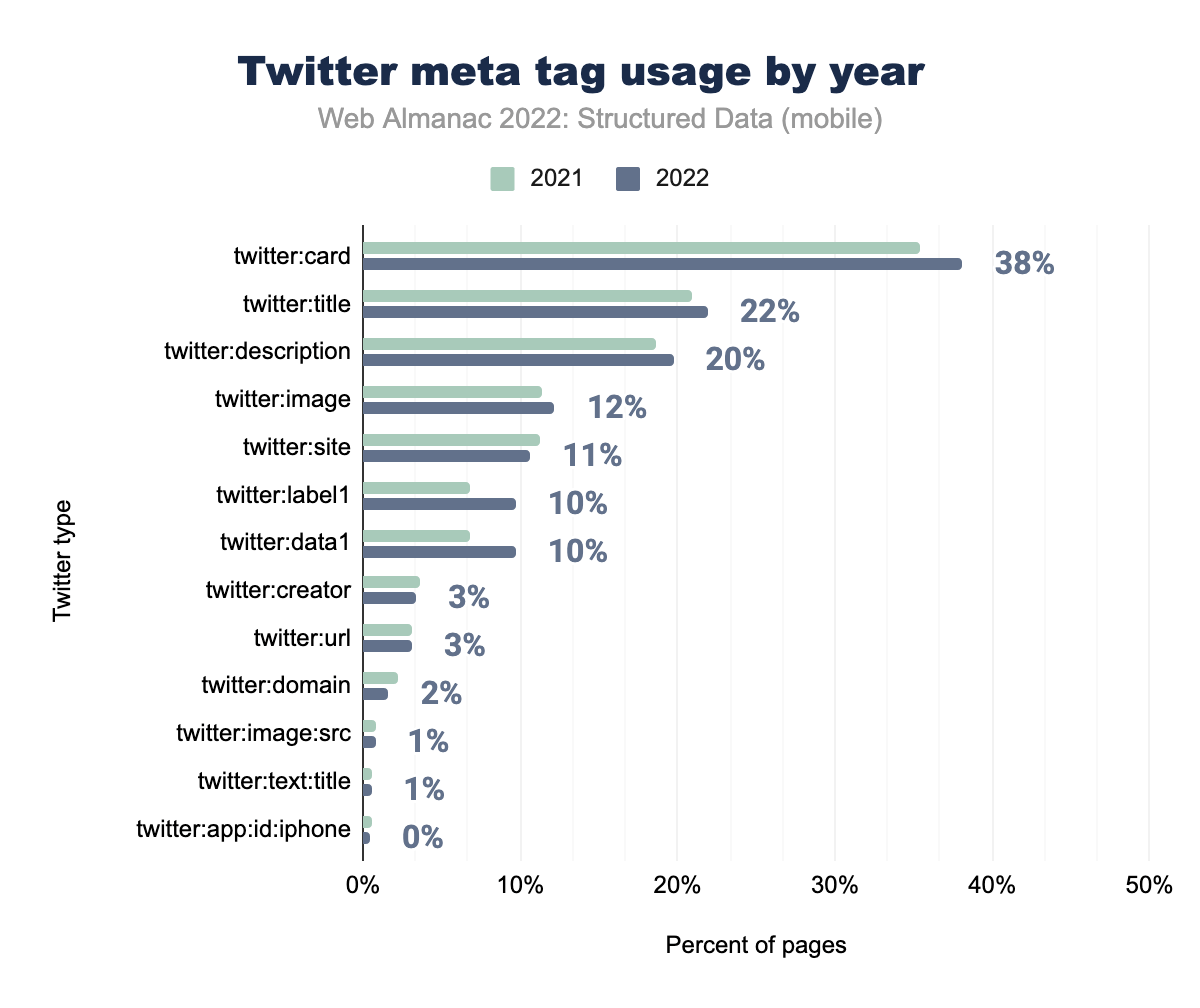
twitter:card was used on 35% of mobile pages in 2021 and 38% in 2022, twitter:title on 21% and 22% respectively, twitter:description on 19% and 20%, twitter:image on 11% and 12%, twitter:site on 11% and 11%, twitter:label1 on 7% and 10%, twitter:data1 on 7% and 10%, twitter:creator on 4% and 3%, twitter:url on 3% and 3%, twitter:domain on 2% and 2%, twitter:image:src on 1% and 1%, twitter:text:title on 1% and 1%, and finally twitter:app:id:iphone was used on 1% of mobile pages in 2021 and 0% in 2022.Twitter meta tags once again follow the pattern of a general increase in usage, more specifically in the common tags of twitter:card, twitter:title, twitter:description and twitter:image. A notable increase can be seen for twitter:label1 and twitter:data1, both at 7% in 2021 to 10% in 2022 for mobile pages.
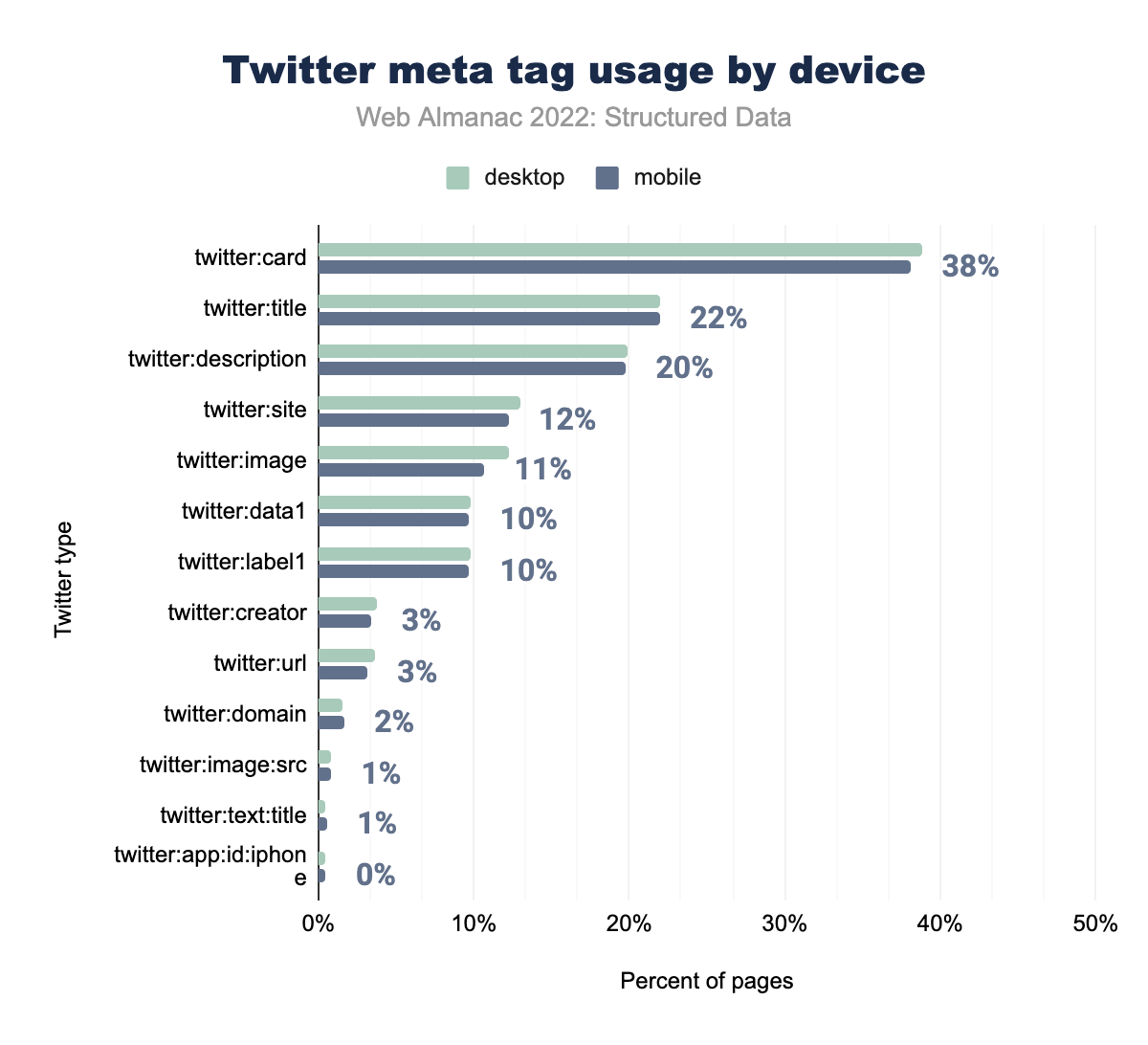
twitter:card was used on 39% of desktop and 38% of mobile pages, twitter:title on 22% and 22% respectively, twitter:description on 20% and 20%, twitter:image on 12% and 12%, twitter:site on 13% and 11%, twitter:label1 on 10% and 10%, twitter:data1 on 10% and 10%, twitter:creator on 4% and 3%, twitter:url on 4% and 3%, twitter:domain on 2% and 2%, twitter:image:src on 1% and 1%, twitter:text:title on 0% and 1%, and finally twitter:app:id:iphone was used on 0% of both desktop and mobile pages.Twitter meta tags such as twitter:site and twitter:image have a larger presence on desktop sites, though the majority of these meta tags share the same prevalence between mobile and desktop, as well as year-to-year. Some of the less common tags saw a slight decrease in use this year, though Twitter meta tag usage maintains an overall increase from last year.
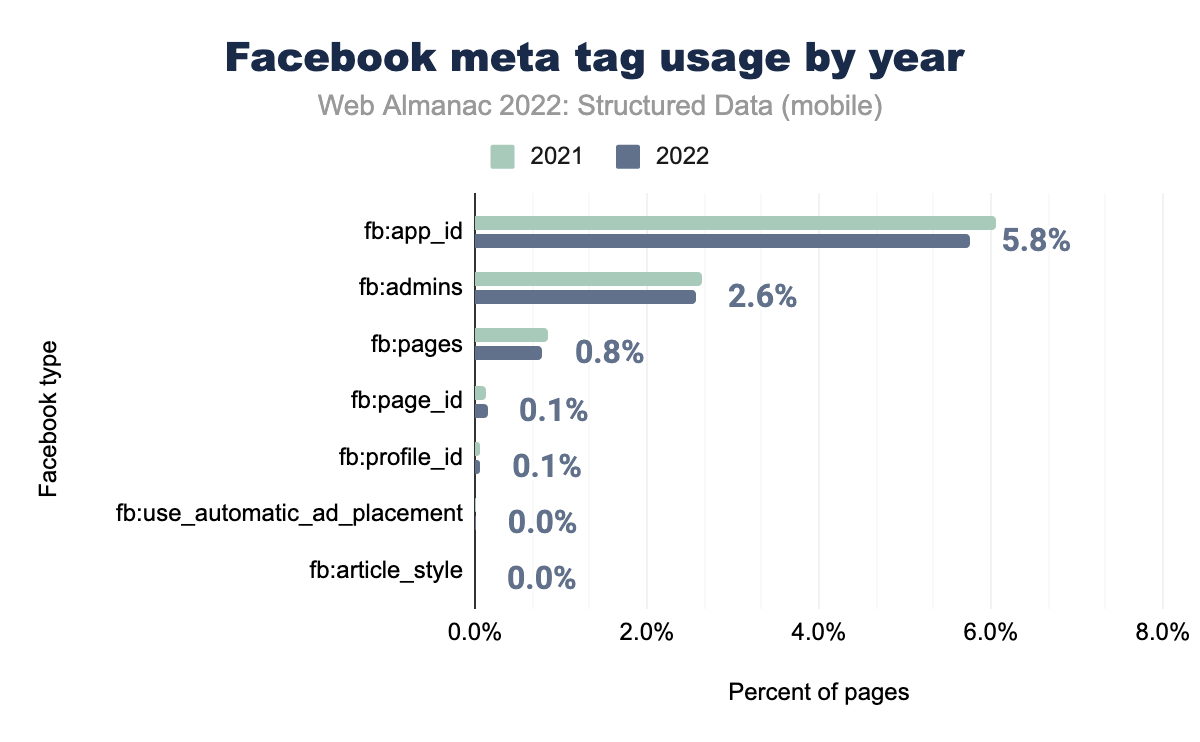
fb:app_id was used on 6.1% of mobile pages in 2021 and 5.8% in 2022, fb:admins on 2.6% and 2.6% respectively, fb:pages on 0.9% and 0.8%, fb:page_id and fb:profile_id on 0.1% in both years, and fb:use_automatic_ad_placement and fb:article_style on 0.0% in both years.Out of all of the Facebook tags here, there are only three with significant numbers of appearances. These are the same as the top three in 2021, namely fb:app_id, fb:admins and fb:pages at 5.8%, 2.6% and 0.8% on mobile, all a slight decrease from last year.
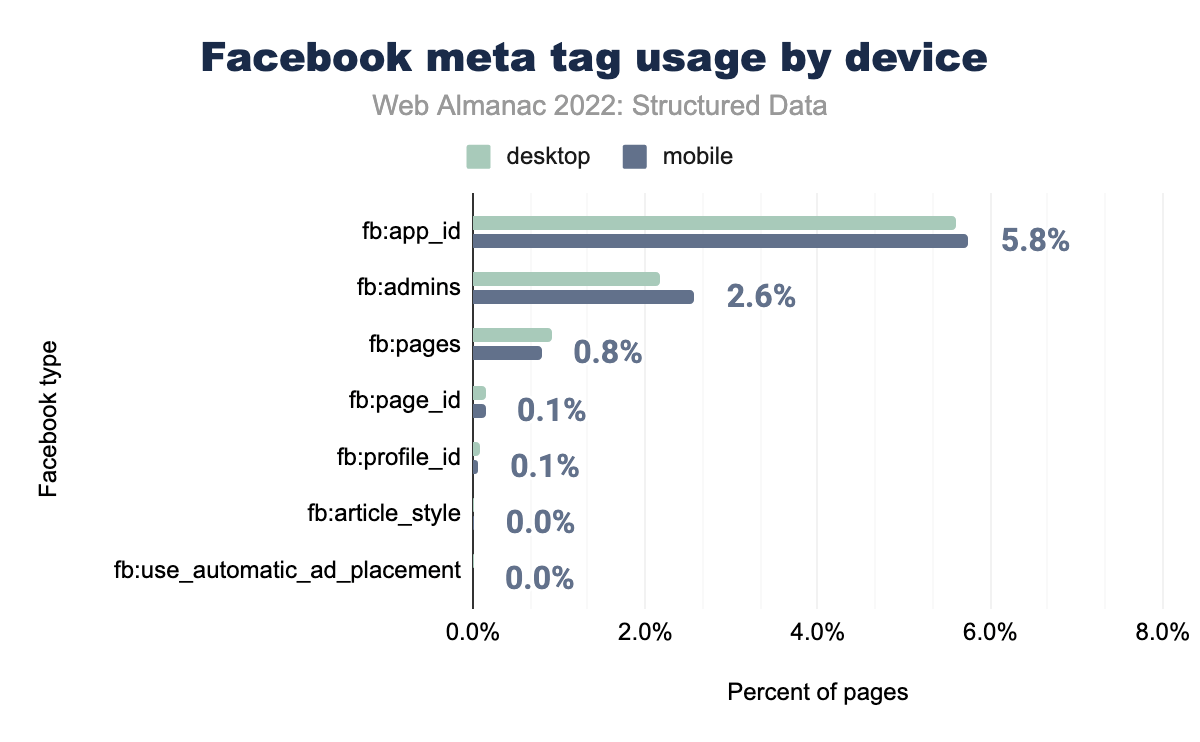
fb:app_id was used on 5.6% of desktop and 5.8% of mobile pages, fb:admins on 2.2% and 2.6% respectively, fb:pages on 0.9% and 0.8%, fb:page_id on 0.2% and 0.1%, fb:profile_id on 0.1% on both, and fb:use_automatic_ad_placement and fb:article_style on 0.0% of both desktop and mobile pages.This is true for desktop pages too, with the exception of fb:pages at a slight increase from 0.90% in 2021 to 0.92% in 2022. The meta tag fb:pages_id sees a slight increase on mobile and desktop pages alike, but overall facebook meta tag usage has seen a decline for both mobile and desktop pages since last year.
Microformats and microformats2
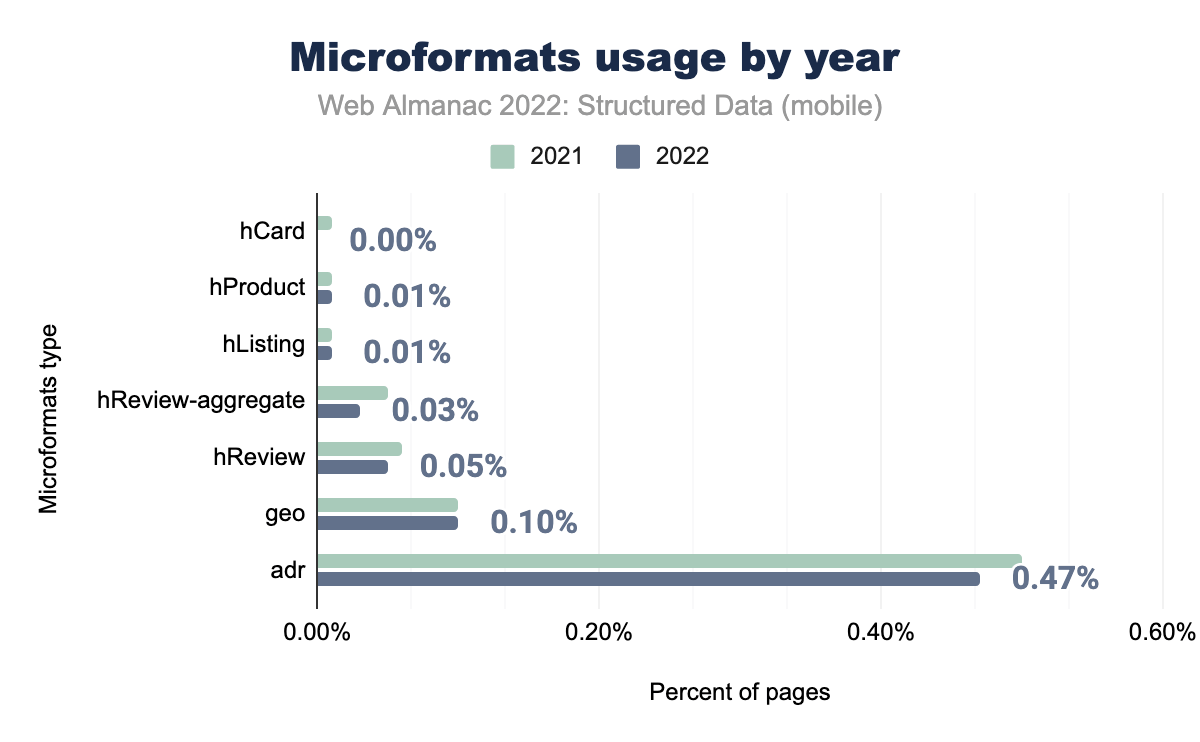
adr was used on 0.50% of mobile pages in 2021 and 0.47% in 2022, geo on 0.10% and 0.10% respectively, hReview on 0.06% and 0.05%, hReview-aggregate on 0.05% and 0.03%, hListing and hProduct on 0.01% in both years, and finally hCard on 0.01% of mobile pages in 2021 and 0.00% in 2022.Microformats have remained very similar in usage numbers since 2021, with adr (appearing on 0.47% of pages in our set) still being the most common on the list.
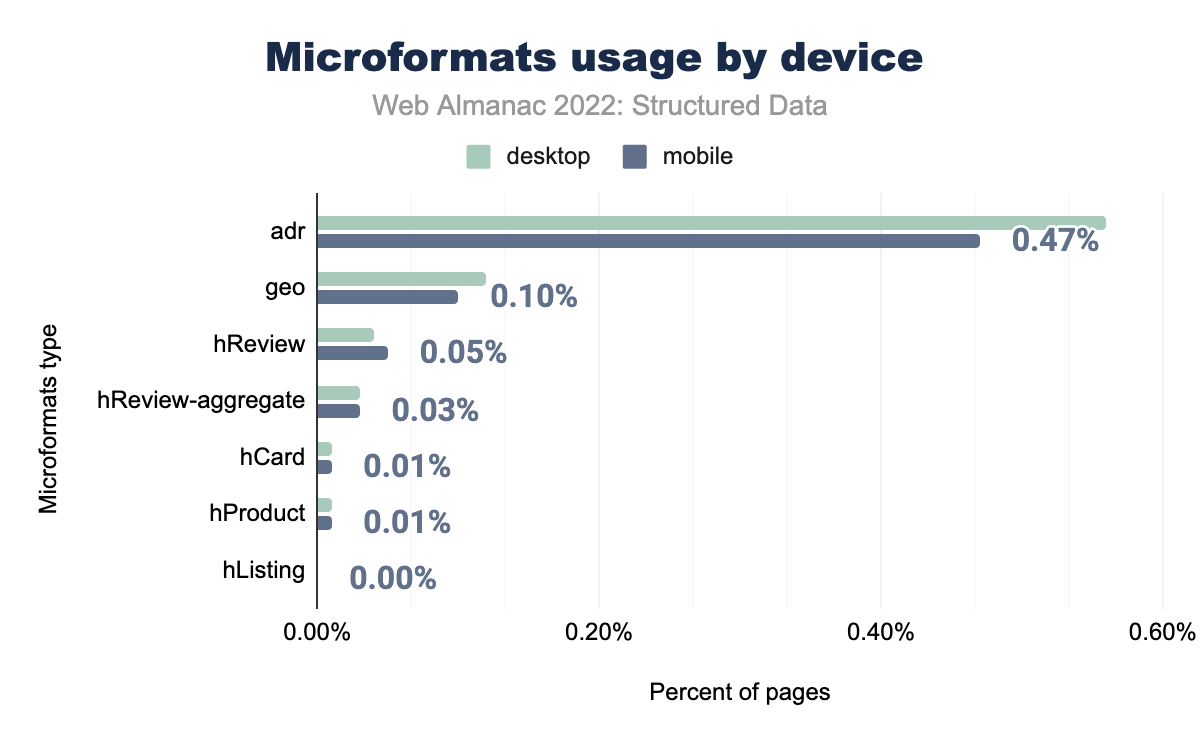
adr was used on 0.56% of desktop and 0.47% of mobile pages, geo on 0.12% and 0.10% respectively, hReview on 0.04% and 0.05%, hReview-aggregate on 0.03% and 0.03%, hListing on 0.00% and 0.01%, hProduct on 0.01% and 0.01%, and finally hCard was used on 0.01% of desktop and 0.00% of mobile pages.Both mobile and desktop share a mix of increased and decreased usage between microformat types, though both averaging out to less than last year’s numbers. Some types which factor into this decrease are hReview (going from 0.06% to 0.05% on mobile pages and 0.06% to 0.04% on desktop pages) and hReview-aggregate (going from 0.06% to 0.04% on both mobile and desktop pages).
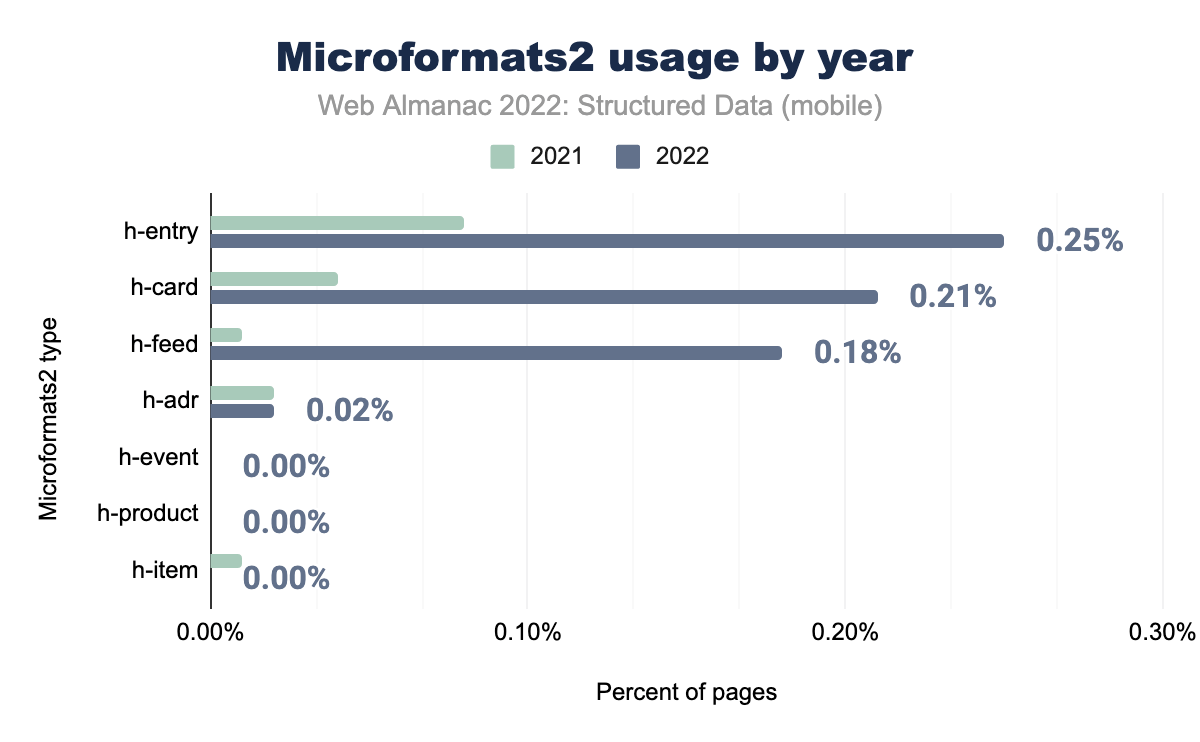
h-entry was used on 0.08% of mobile pages in 2021 and 0.25% in 2022 h-card on 0.04% and 0.21% respectively, h-feed on 0.01% and 0.18%, h-adr on 0.02% and 0.02%, h-event on 0.00% and 0.00%, h-product on 0.00% and 0.00%, and finally h-item was used on 0.01% of mobile pages in 2021 and 0.00% in 2022.Meanwhile, microformats2 attributes have skyrocketed since 2021. The properties of h-entry, h-card and h-feed have shown huge increases in our set of pages, which account for the fact that microformats2 attributes have almost tripled in our set since the previous year.
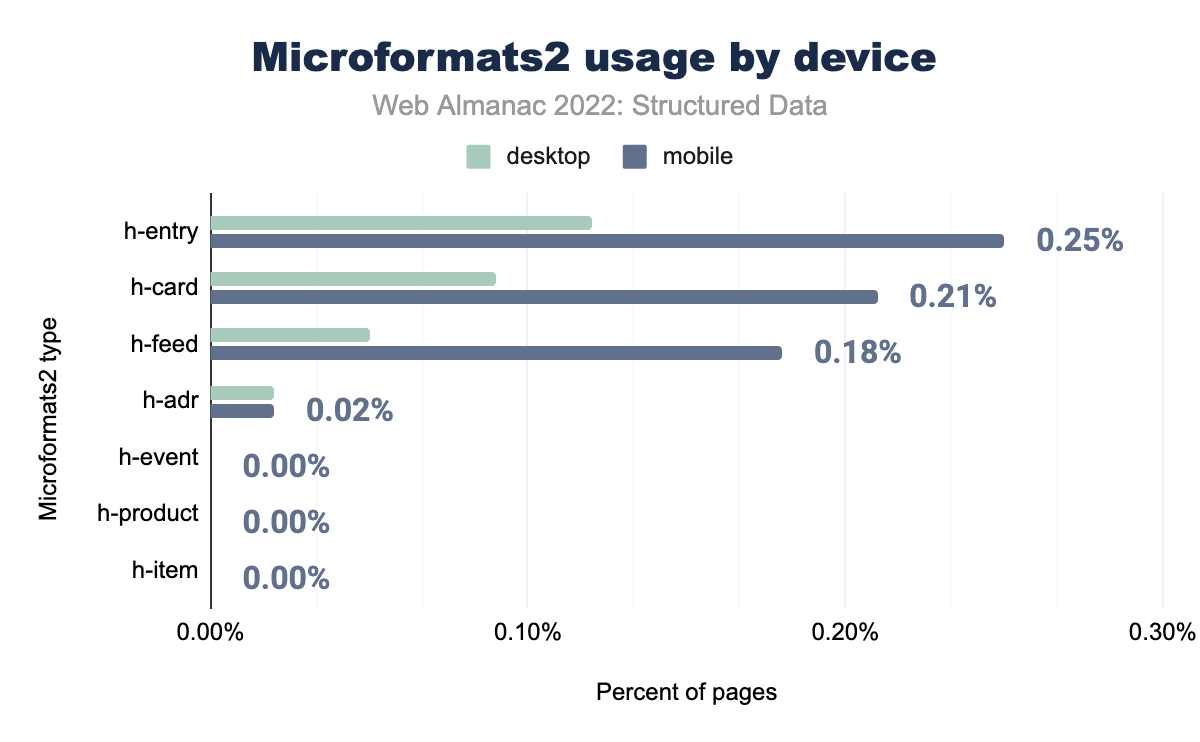
h-entry was used on 0.12% of desktop and 0.25% of mobile pages, h-card on 0.09% and 0.21% respectively, h-feed on 0.05% and 0.18%, h-adr on 0.02% and 0.02%, and h-event, h-product and h-item on 0.00% of both desktop and mobile pages.This growth is seen more drastically on mobile pages, though desktop pages do follow the same pattern. Other than that, h-adr remains the exact same across both years and both platforms at 0.02% of pages.
Microdata
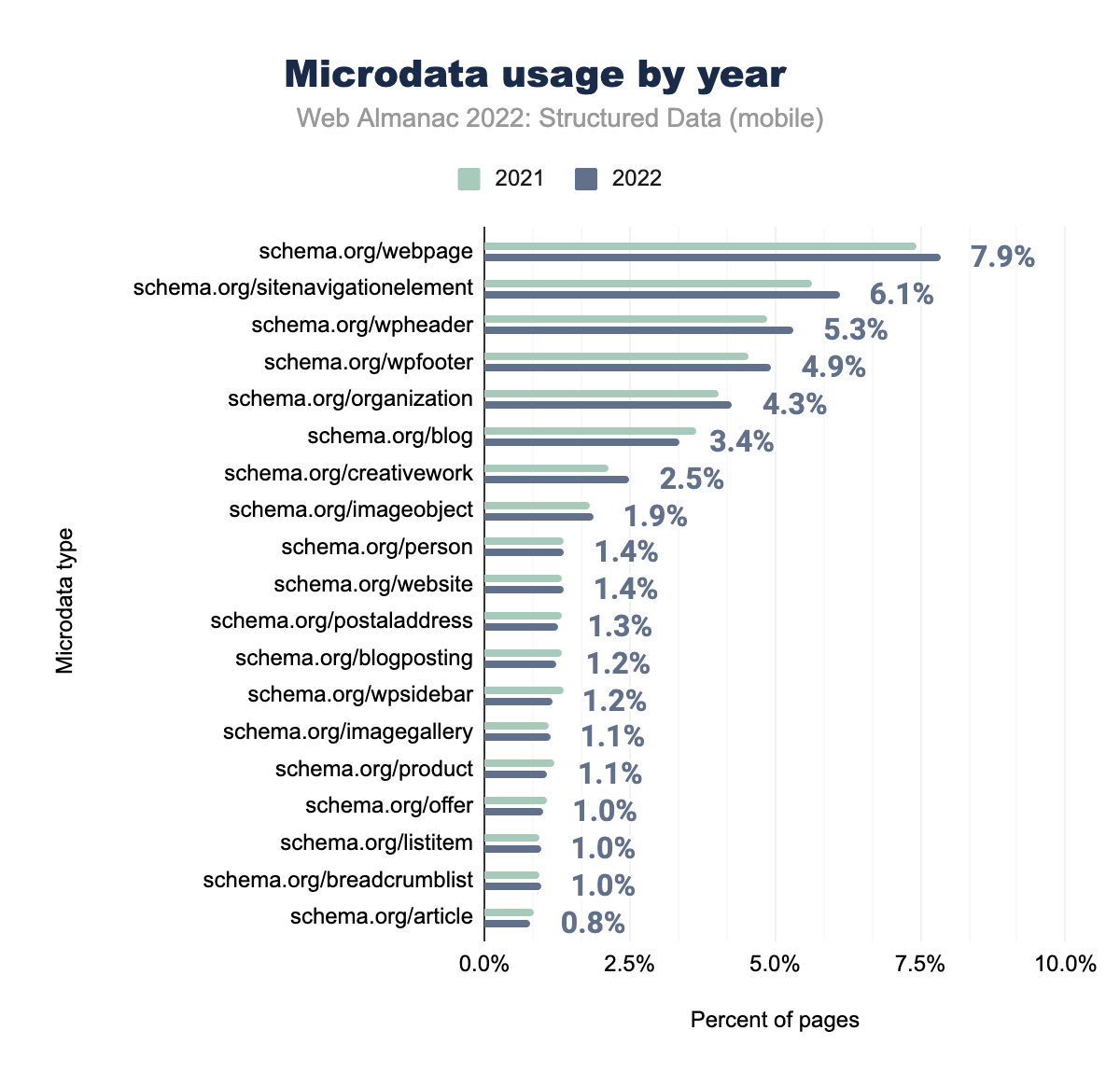
schema.org/webpage was used on 7.4% of mobile pages in 2021 and 7.9% in 2022, schema.org/sitenavigationelement on 5.6% and 6.1% respectively, schema.org/wpheader on 4.9% and 5.3%, schema.org/wpfooter on 4.6% and 4.9%, schema.org/organization on 4.0% and 4.3%, schema.org/blog on 3.7% and 3.4%, schema.org/creativework on 2.1% and 2.5%, schema.org/imageobject on 1.8% and 1.9%, schema.org/person on 1.4% and 1.4%, schema.org/website on 1.3% and 1.4%, schema.org/postaladdress on 1.3% and 1.3%, schema.org/blogposting on 1.3% and 1.2%, schema.org/wpsidebar on 1.4% and 1.2%, schema.org/imagegallery on 1.1% and 1.1%, schema.org/product on 1.2% and 1.1%, schema.org/offer on 1.1% and 1.0%, schema.org/listitem on 1.0% and 1.0%, schema.org/breadcrumblist on 1.0% and 1.0%, and finally schema.org/article on 0.9% of mobile pages in 2021 and 0.8% of mobile pages in 2022.Most of the properties for Microdata have not seen much change, with a slight increase in some of the more common properties such as webpage, sitenavigationelement and wpheader appearing in 7.9%, 6.1% and 5.3% of mobile pages respectively.
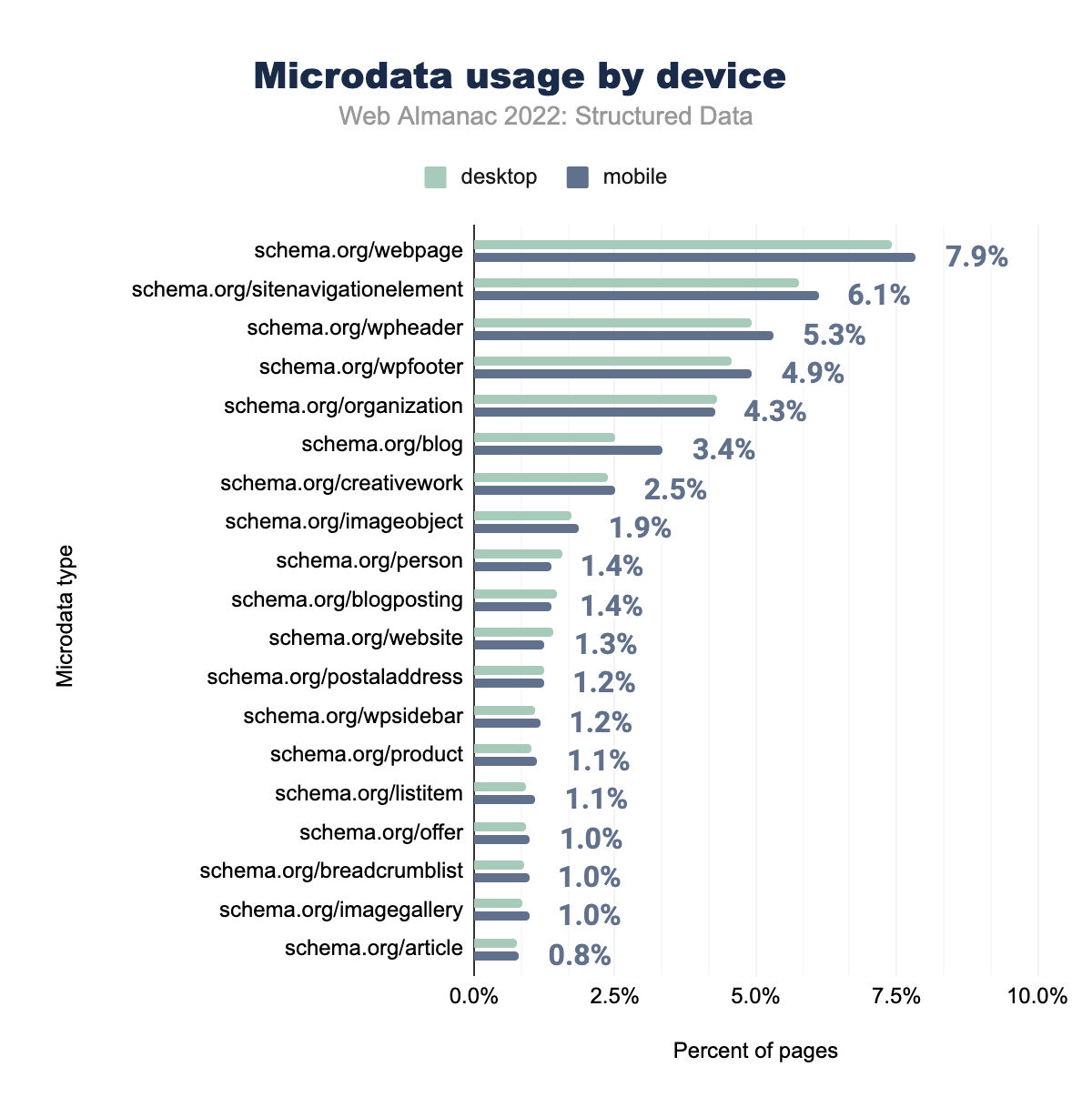
schema.org/webpage was used on 7.4% of desktop and 7.9% of mobile pages, schema.org/sitenavigationelement on 5.8% and 6.1% respectively, schema.org/wpheader on 4.9% and 5.3%, schema.org/wpfooter on 4.6% and 4.9%, schema.org/organization on 4.3% and 4.3%, schema.org/blog on 2.5% and 3.4%, schema.org/creativework on 2.4% and 2.5%, schema.org/imageobject on 1.7% and 1.9%, schema.org/person on 1.6% and 1.4%, schema.org/website on 1.4% and 1.4%, schema.org/postaladdress on 1.3% and 1.3%, schema.org/blogposting on 1.5% and 1.2%, schema.org/wpsidebar on 1.1% and 1.2%, schema.org/imagegallery on 0.9% and 1.1%, schema.org/product on 1.0% and 1.1%, schema.org/offer on 0.9% and 1.0%, schema.org/listitem on 0.9% and 1.0%, schema.org/breadcrumblist on 0.9% and 1.0%, and finally schema.org/article was used on 0.8% of both desktop and mobile pages.These increases are common for desktop as well, with slight decreases elsewhere such as wpsidebar (going from 1.4% to 1.2% on mobile pages and going from 1.3% to 1.1% on desktop pages), resulting in minimum change over the last year for both mobile and desktop pages as a whole.
JSON-LD
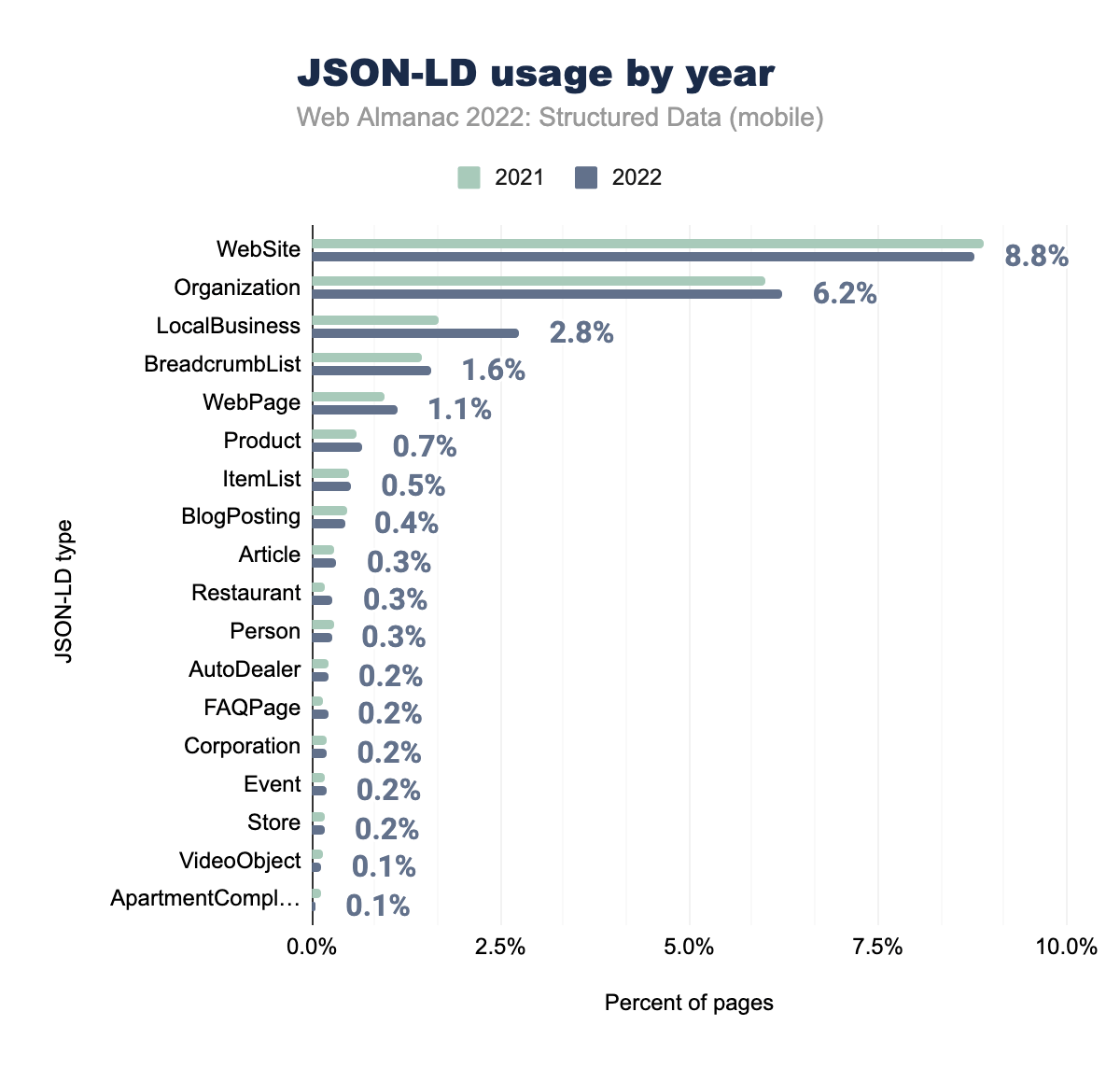
WebSite was used on 8.9% of mobile pages in 2021 and 8.8% in 2022, Organization on 6.0% and 6.2% respectively, LocalBusiness on 1.7% and 2.8%, BreadcrumbList on 1.5% and 1.6%, WebPage on 1.0% and 1.1%, Product on 0.6% and 0.7%, ItemList on 0.5% and 0.5%, BlogPosting on 0.5% and 0.4%, Article on 0.3% and 0.3%, Restaurant on 0.2% and 0.3%, Person on 0.3% and 0.3%, AutoDealer on 0.2% and 0.2%, FAQPage on 0.1% and 0.2%, Corporation on 0.2% and 0.2%, Event on 0.2% and 0.2%, Store on 0.2% and 0.2%, VideoObject on 0.2% and 0.1%, and finally ApartmentComplex on 0.1% on mobile pages in both 2021 and 2022.JSON-LD types continue to be mostly similar with a few notable increases over the previous year. Namely, these are LocalBusiness (which has increased to 2.8% of pages in our set) and Restaurant (which has increased to 0.3% of pages in our set).
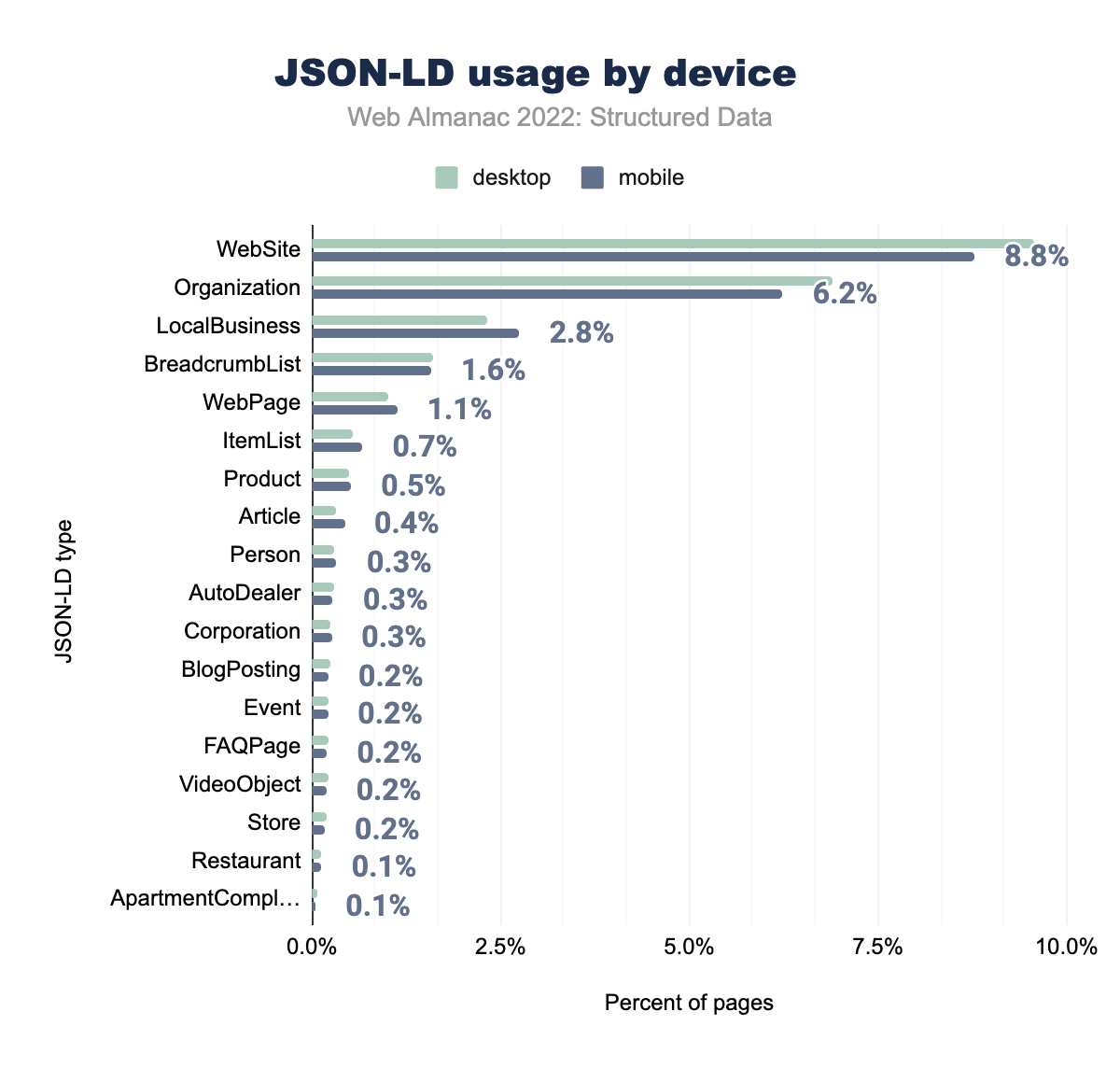
WebSite was used on 9.6% of desktop and 8.8% of mobile pages, Organization on 6.9% and 6.2% respectively, LocalBusiness on 2.3% and 2.8%, BreadcrumbList on 1.6% and 1.6%, WebPage on 1.0% and 1.1%, Product on 0.5% and 0.7%, ItemList on 0.6% and 0.5%, BlogPosting on 0.2% and 0.4%, Article on 0.3% and 0.3%, Restaurant on 0.1% and 0.3%, Person on 0.3% and 0.3%, AutoDealer on 0.3% and 0.2%, FAQPage on 0.2% and 0.2%, Corporation on 0.2% and 0.2%, Event on 0.2% and 0.2%, Store on 0.2% and 0.2%, VideoObject on 0.2% and 0.1%, and finally ApartmentComplex was used on 0.1% of both desktop and mobile pages.These increases are enough to make JSON-LD types have the 2nd biggest positive change since 2021, going from appearing on 33.5% to 36.5% of mobile pages in our set and going from 34.1% to 36.9% on desktop pages.
JSON-LD Relationships
When evaluating JSON-LD, we can focus on the most recurring patterns of relationships among the different classes. More than with other syntaxes, JSON-LD expresses the value of graphs in structured data. An Article, for example, is frequently characterized by a linked image and the entity type Person to represent its author. Quite similarly, we would see that BlogPosting is also connected with image but as a frequent relationship with the Organization that serves as Publisher.
Some types are purely syntactic like BreadcrumbList that is used exclusively to connect different items (itemListElement) of a site navigation’s system or a Question that is typically linked with its answer (acceptedAnswer). Other elements deal with meanings: a LocalBusiness typically is linked to an address and to the opening hours (openingHoursSpecification).
With this analysis we want to share a birds-eye overview of the most common types of relationships between entities and the subtle differences between let’s say Article and BlogPosting.
Here below we can see the common links between the different types, based on how frequently they occur within all structure/relationship values. Some of these structures are typically part of larger relationship chains.

WebPage is the largest “From” item branching off to multiple “Relationship” types and “To” results (for example WebPage -> PotentialAction -> SearchAction). This is followed by WebSite, then Organization, Product, BreadCrumblist, BlogPosting and then a decreasingly used list of other items. Of the middle “Relationships” column PotentialAction is used most, followed by ItemListElement, IsPartOf, Publisher, image and then a similar long tail of ever-decreasing usage. The “To” column has ImageObject as the most used at the top, following by Organization, SearchAction, ListItem, WebSite, WebPage and then again a longer tail of every decreasing usage. The general sense created by the graph is a lot of different relationships with much cross-usage between the three columns.The analysis also provides an overview of the verticals behind these constructs: from news and media to e-commerce, from local businesses to events, and so on.
Here below we can see the same data interactively with the source attribute on the left and the target class on the right.

itemListElement to ListItem, isPartOf to Website, potentialAction to both SearchAction and ReadAction, and image, logo, and primaryImageOfPage to ImageObject, followed with a long list of lesser used relationships.The main limitation of this analysis is represented by the fact that we can evaluate relationship chains at the home page level.
SameAs
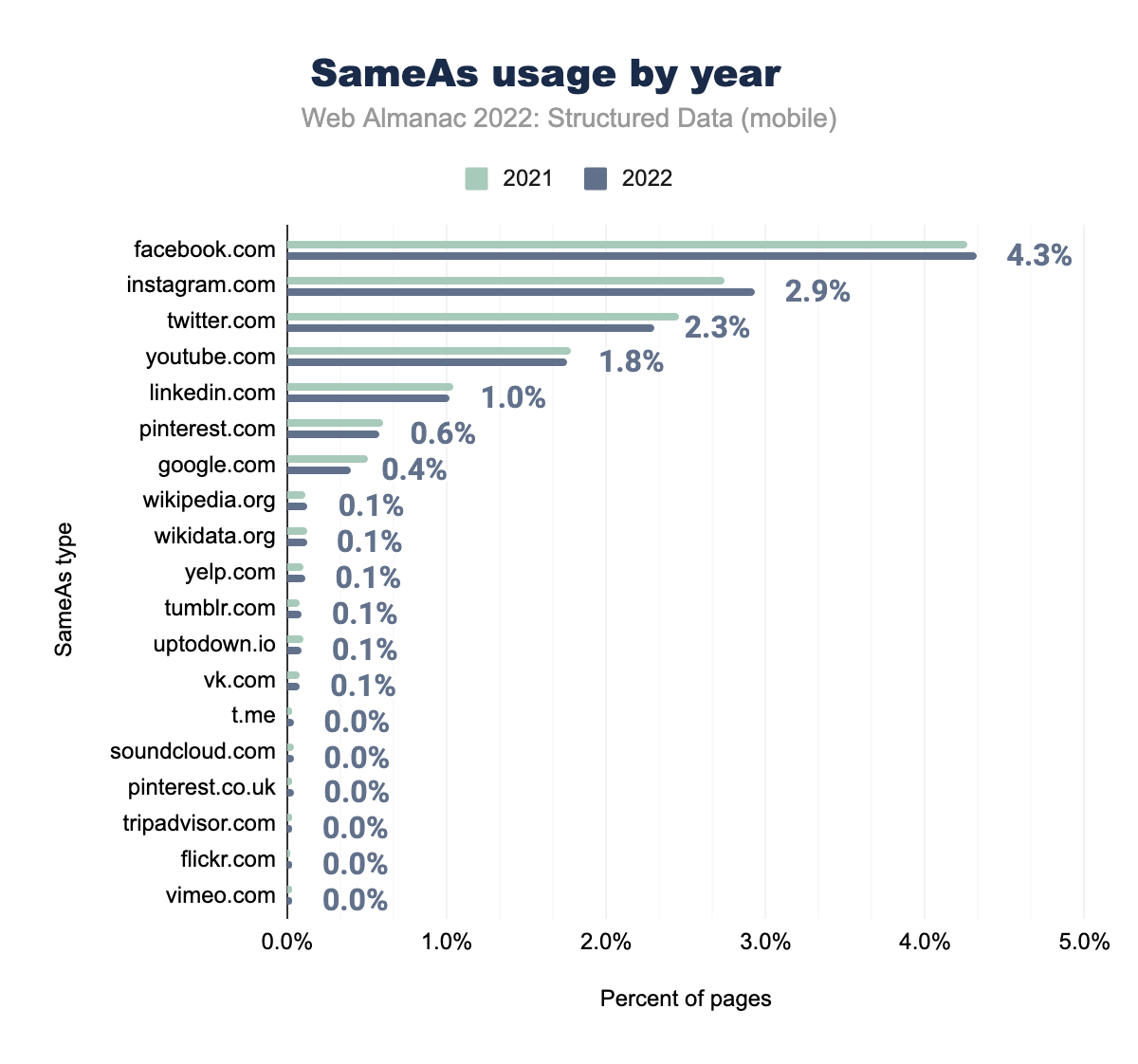
WebSite was used on 4.3% of mobile pages in both 2021 and 2022, instagram.com on 2.7% and 2.9% respectively, twitter.com on 2.5% and 2.3%, youtube.com on 1.8% and 1.8%, linkedin.com on 1.0% and 1.0%, pinterest.com on 0.6% and 0.6%, google.com on 0.5% and 0.4%, wikipedia.org on 0.1% and 0.1%, wikidata.org on 0.1% and 0.1%, yelp.com on 0.1% and 0.1%, tumblr.com on 0.1% and 0.1%, uptodown.io on 0.1% and 0.1%, vk.com on 0.1% and 0.1%, and t.me, soundcloud.com, pinterest.co.uk, tripadvisor.com, flickr.com, and vimeo.com all were used on 0.0% of mobile pages in both 2021 and 2022.SameAs usage by year (mobile).
As was the case in 2021, the most common values of the sameAs property are social media platforms. These include facebook.com (at 4.32% on mobile and 4.94% on desktop), instagram.com (at 2.93% on mobile and 3.34% on desktop) and twitter.com (at 2.30% on mobile and 2.86% on desktop). The former two of which have seen a slight increase on mobile from 2021, with all 3 increasing on desktop.
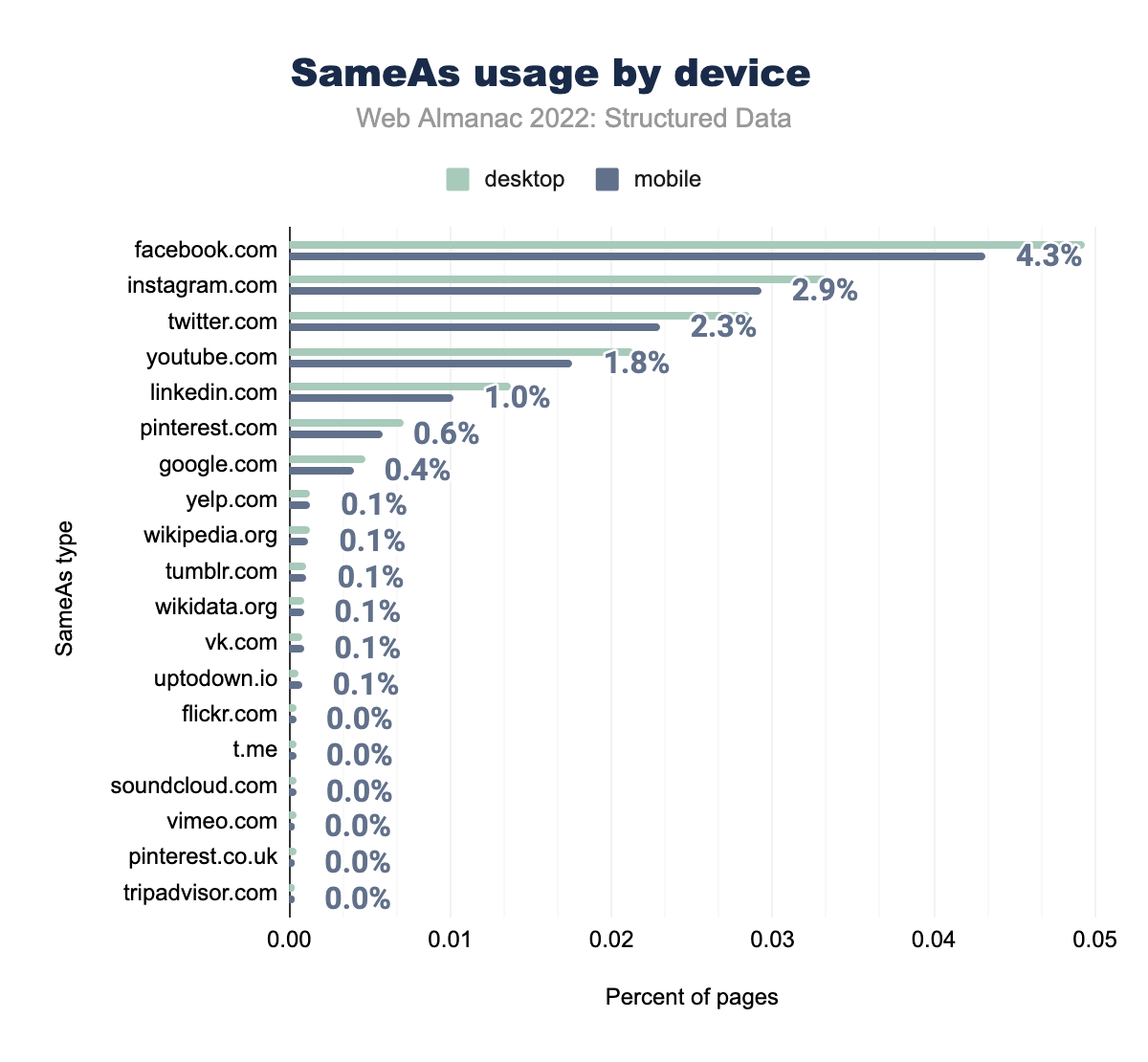
facebook.com was used on 4.9% of desktop and 4.3% of mobile pages, instagram.com on 3.3% and 2.9% respectively, twitter.com on 2.9% and 2.3%, youtube.com on 2.1% and 1.8%, linkedin.com on 1.4% and 1.0%, pinterest.com on 0.7% and 0.6%, google.com on 0.5% and 0.4%, wikipedia.org on 0.1% and 0.1%, wikidata.org on 0.1% and 0.1%, yelp.com on 0.1% and 0.1%, tumblr.com on 0.1% and 0.1%, uptodown.io on 0.1% and 0.1%, vk.com on 0.1% and 0.1%, and t.me, soundcloud.com, pinterest.co.uk, tripadvisor.com, flickr.com, and vimeo.com were all used on 0.0% of both desktop and mobile pages.SameAs usage by device.
The rest of the list includes information sources such as wikipedia.org (at 0.13% on both mobile and desktop) and yelp.com (at 0.11% on mobile and 0.13% on desktop), both at an increase from the previous year.
Further JSON-LD insights - relative changes
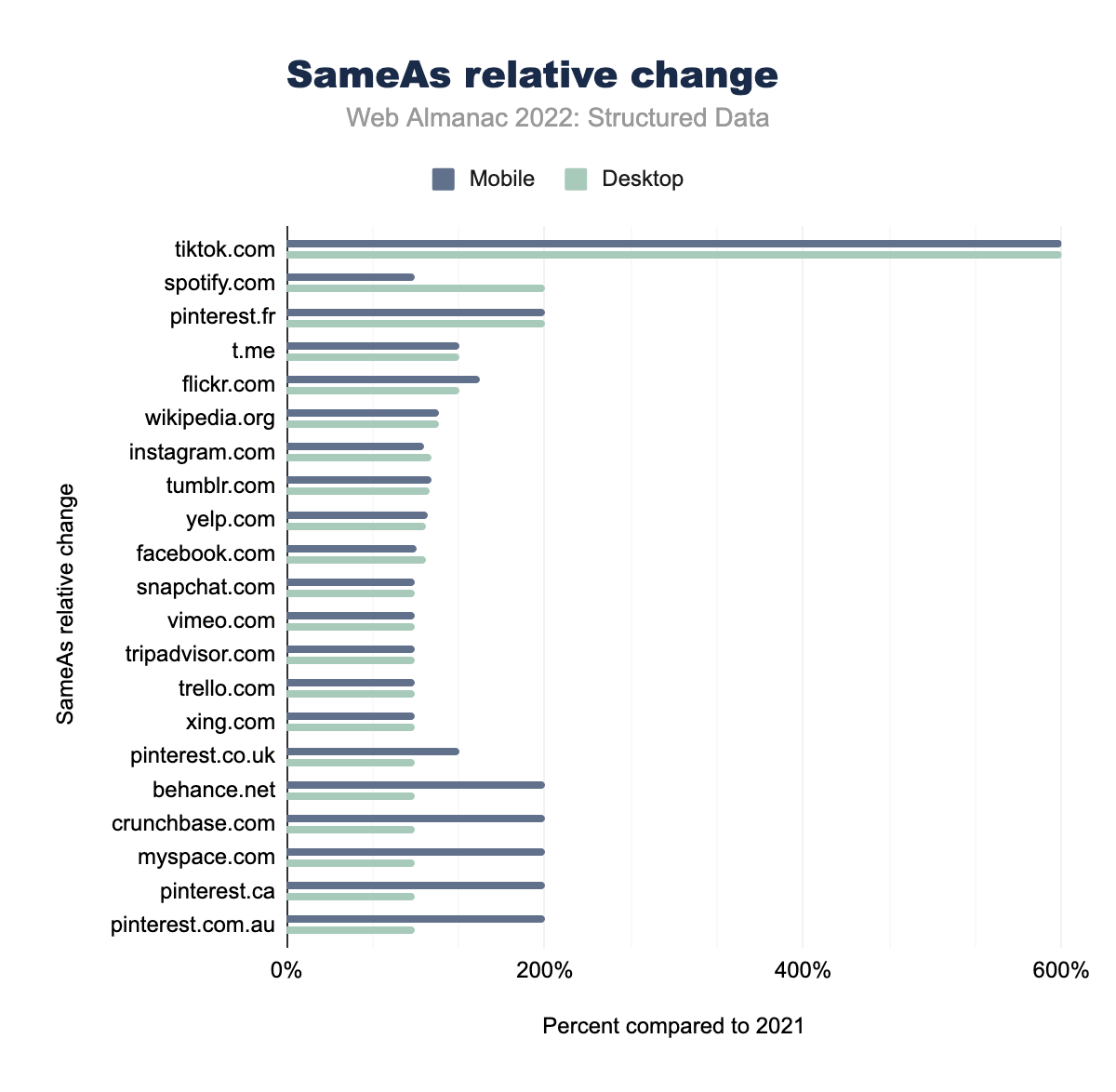
tiktok.com changed by 600% by both desktop and mobile pages, spotify.com by 100.00% on desktop and 200.00% on mobile, pinterest.fr by 200.00% and 200.00% respectively, t.me by 133.33% and 133.33%, flickr.com by 150.00% and 133.33%, wikipedia.org by 118.18% and 118.18%, instagram.com by 106.93% and 112.46%, tumblr.com by 112.50% and 111.11%, yelp.com by 110.00% and 108.33%, facebook.com by 101.41% and 107.39%, snapchat.com by 100.00% and 100.00%, vimeo.com by 100.00% and 100.00%, tripadvisor.com by 100.00% and 100.00%, trello.com by 100.00% and 100.00%, xing.com by 100.00% and 100.00%, pinterest.co.uk by 133.33% and 100.00%, behance.net, crunchbase.com, myspace.com, pinterest.ca, and pinterest.com.au all changed by 200.00% on desktop and 100.00% on mobile.SameAs relative change.
It is insightful to look at the SameAs entries and how they change over time. TikTok has seen a huge increase with 2022 showing its appearance on six times as many pages relative to our set compared to 2021. This change is equal for both desktop and mobile pages. Pinterest, and the various domain names it has, make up for 3 of the top 5 largest growth for mobile pages in 2022. Mobile overall has seen a larger increase for SameAs entries than desktop, with Spotify being an exception with its desktop page appearances being doubled compared to 2021.
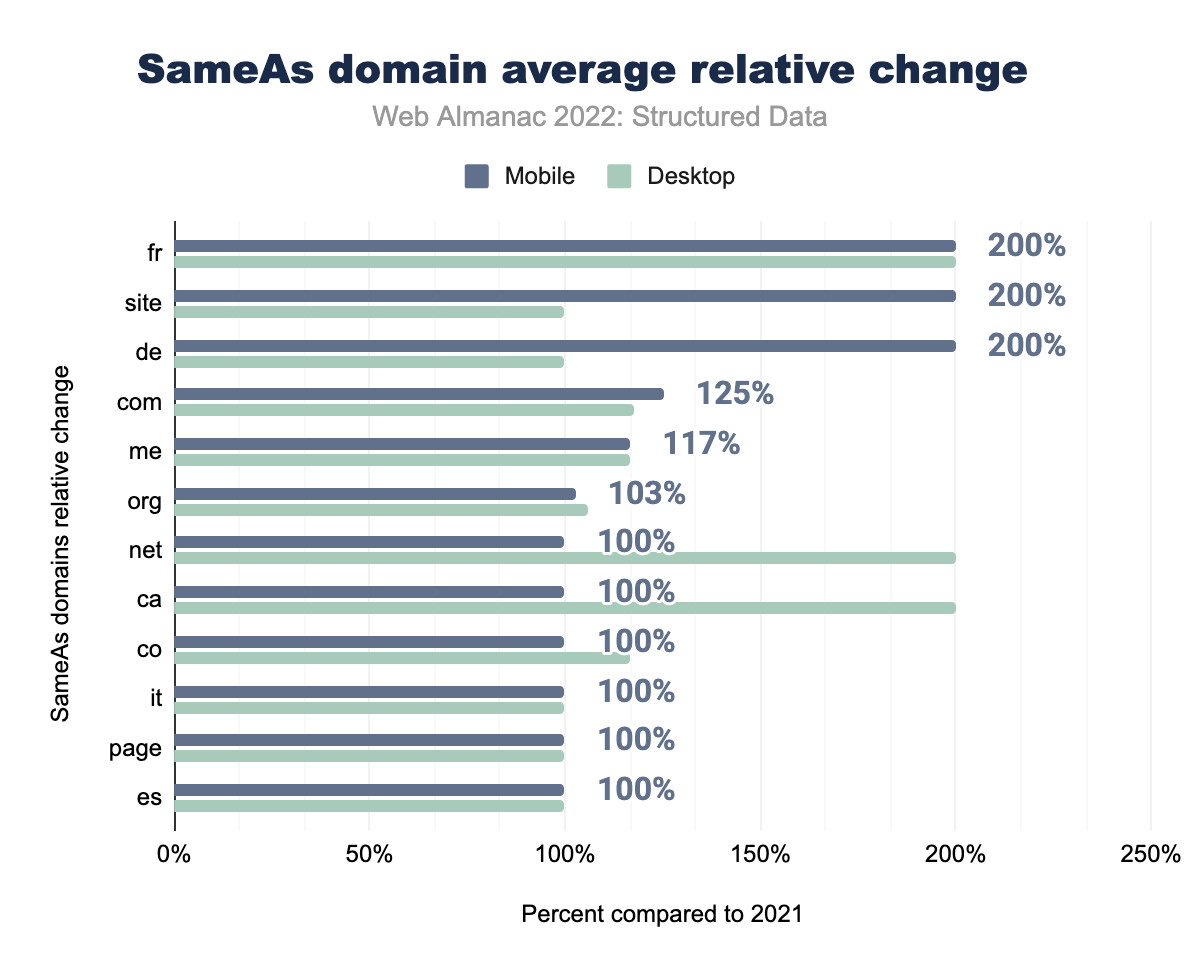
fr changed by 200% by both desktop and mobile pages, site by 200.00% on desktop and 100.00% on mobile, de by 200% and 100% respectively, com by 125% and 118%, me by 117% and 117%, org by 103% and 106%, net by 100% and 200%, ca by 100% and 200%, co by 100% and 117%, and finally it, page, and es by 100% on both desktop and mobile.SameAs domain average relative change.
Looking at the domain names of the SameAs entries, and how they change over time, also may give valuable insight. In the largest desktop page growth we see .ca, .net and .fr, with the latter also being up there in the top for mobile page increases. As this is an average, the amount of entries is not accounted for. In both years .com is far larger in numbers than all other entries, but the average change is 125% for mobile pages and 117% for desktop pages. The Canadian and French domain averages are heavily boosted by Pinterest, which—as mentioned above—has seen widespread increases from last year. In fact, 7 out of the top 10 SameAs domain growers have Pinterest in their entries, sometimes being their only entry.
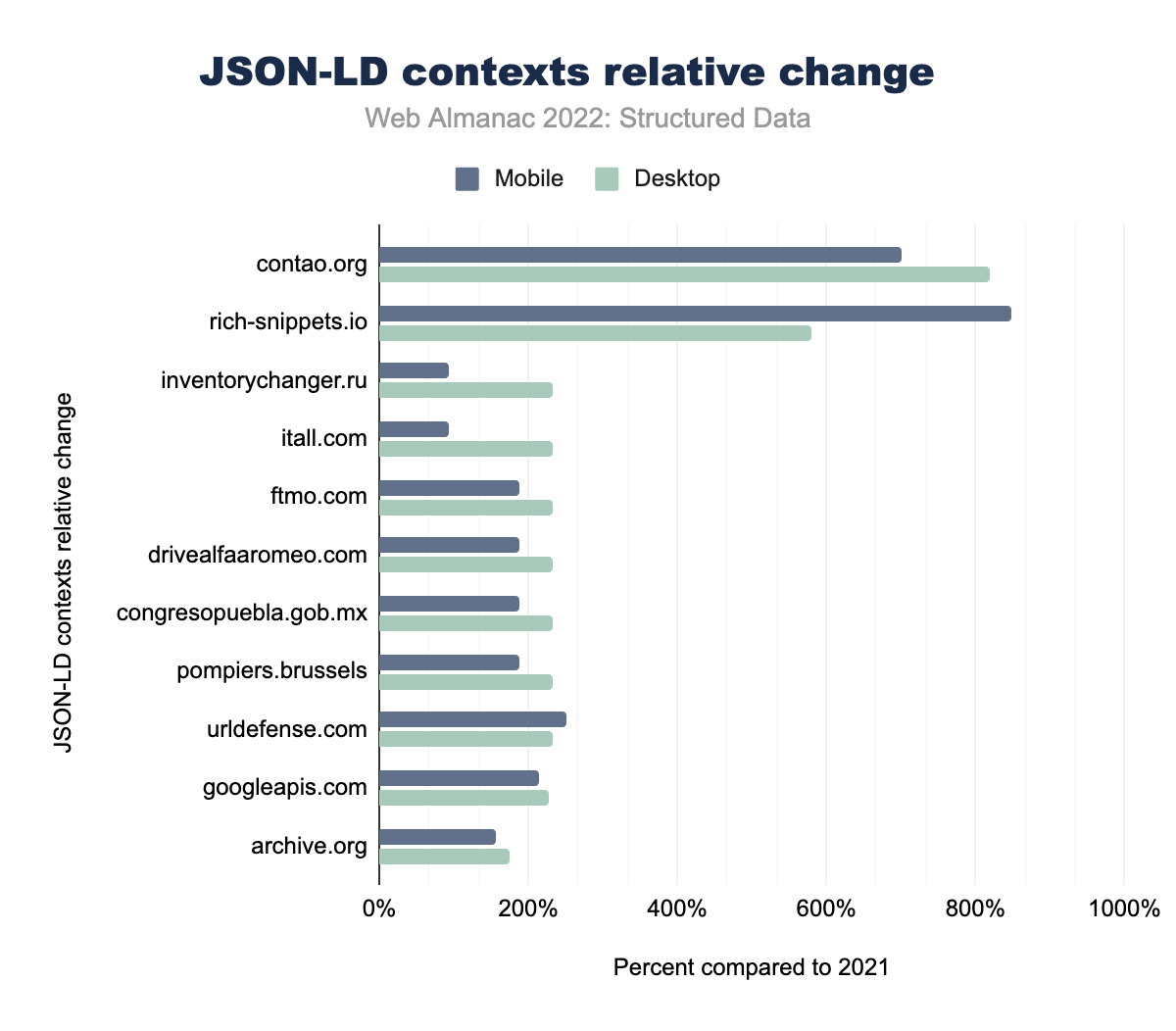
contao.org had a 819% increase on desktop and 701% on mobile, for contao.org it was 819% and 701% respectively, for rich-snippets.io 579% and 849%, for inventorychanger.ru 232% and 94%, for itall.com 232% and 94%, for ftmo.com 232% and 189%, for drivealfaaromeo.com 232% and 189%, for congresopuebla.gob.mx 232% and 189%, for pompiers.brussels 232% and 189%, for urldefense.com 232% and 252%, for googleapis.com 227% and 214%, and finally for archive.org there was a 174% increase on desktop and 157% on mobile.For JSON-LD contexts, schema.org is by far the largest contributor, with over 6,000 times as many appearances for desktop pages and over 3,500 times as many appearances for mobile pages than the second largest contributor, googleapis.com. With that said, googleapis.com’s appearances more than doubled for both desktop and mobile pages, compared to schema.org’s more modest increase to 108% of last year’s numbers. In terms of top growers, contao.org and rich-snippets.io take the top spots with contao.org’s desktop page increase of 819% and rich-snippets.io’s mobile increase of 849%. Contao.org ranks 4th in total entries, while rich-snippets.io ranks at 8th.
Conclusion
A lot has been outlined about how structured data affects the web and, by extension, our experience. This year we also focused on comparing how the adoption of structured data has changed over a year. We could see, for example, the general increase in some classes like LocalBusiness (particularly for Restaurants) or FAQ and the slight decrease in usage for some of the less relevant structured data types that come from foaf or the microdata syntax.
Although far from being a comprehensive list, we can see structured (linked) data bringing several advantages to:
- Ecommerce pages
- Business pages
- Researchers
- Social media sites
- Users
Through SEO, increased discoverability, general data linking, and rich results drive the adoption. Implementing semantic markup within web pages results in a more connected and accessible web.
With more information and insight available than ever, it is essential to understand the capabilities and limitations of specific techniques or choices when trying to increase web page traffic. Adding fake reviews or misleading data in the hopes of improving SEO will be detected, resulting in fewer benefits from those mentioned above and poorer discoverability and performance from search engines.
As already seen in the previous year, while SEO remains a crucial driver for adopting structured data, a growing landscape of use cases is emerging beyond search engines. Website owners are adding data in diverse scenarios to make their systems interoperable, train their content recommendation systems, and gain new insights from web pages.
Although this is only the second year for this chapter in the Web Almanac, we are excited to see how these trends continue and change, along with the state of structured data on the web. With all of the benefits structured data brings, we expect an increasing implementation of these technologies.

