SEO
Введение
SEO (Search Engine Optimization, поисковая оптимизация) — это практика оптимизации веб-сайта или веб-страницы для увеличения количества и качества их трафика на основе органических результатов поисковой системы.
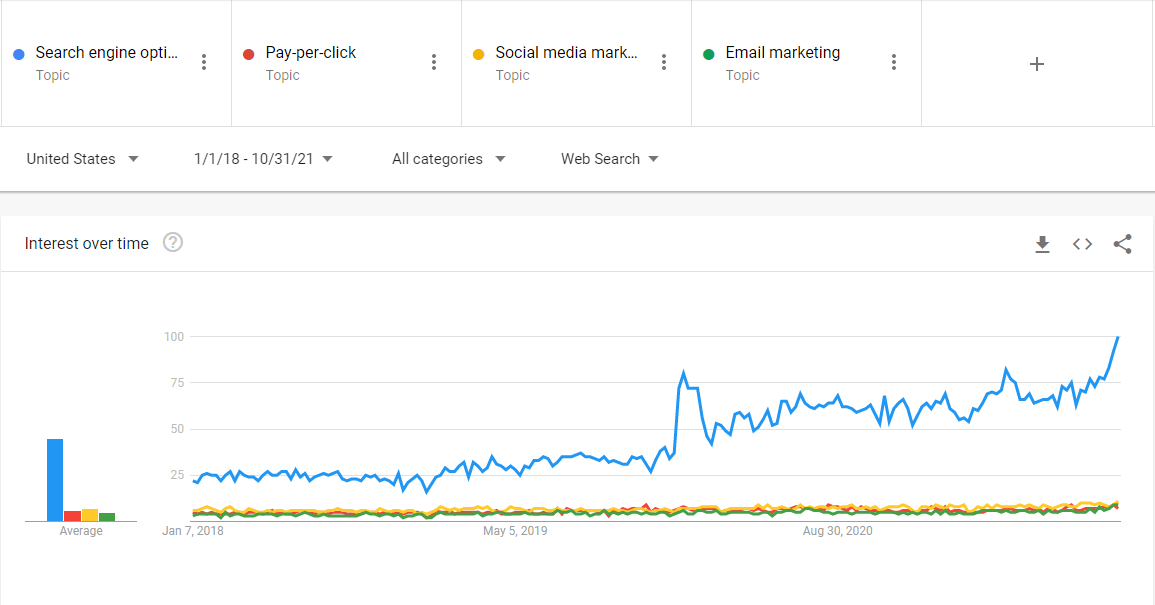
SEO сейчас популярнее, чем когда-либо, и оно значительно выросло за последние пару лет, так как компании искали новые способы привлечь клиентов. Популярность SEO сильно превзошла другие цифровые каналы.
Цель главы «SEO» издания Web Almanac — проанализировать различные элементы, связанные с оптимизацией веб-сайта. В этой главе мы проверим, удобны ли веб-сайты для пользователей и поисковых систем.
Для нашего анализа использовались многие источники данных, включая Lighthouse, отчет о пользовательском опыте Chrome (CrUX), а также необработанные и обработанные HTML-элементы из HTTP Archive на мобильных устройствах и компьютерах. В случае с HTTP Archive и Lighthouse данные ограничиваются анализом только главных страниц веб-сайтов, а не сканированием всего сайта. Помните об этом, делая выводы на основе наших результатов. Вы можете узнать больше об анализе на нашей странице Methodology.
Читайте дальше, чтобы узнать больше о текущем состоянии Интернета и его удобстве для поисковых систем.
Сканируемость и Индексируемость
Чтобы возвращать релевантные результаты по запросам пользователей, поисковые системы должны создать индекс в Интернете. Этот процесс включает в себя:
- Сканирование — поисковые системы используют поисковых роботов, или пауков, для посещения страниц в Интернете. Они находят новые страницы через такие источники, как карты сайта или ссылки между страницами.
- Обработка — на этом этапе поисковые системы могут отрисовывать контент на страницах. Они будут извлекать необходимую информацию, такую как контент и ссылки, которые они будут использовать для создания и обновления своего индекса, ранжирования страниц и поиска нового контента.
- Индексация — cтраницы, отвечающие определенным требованиям к индексации в отношении качества и уникальности контента попадают в индекс. Эти проиндексированные страницы могут быть возвращены по запросам пользователей.
Давайте рассмотрим некоторые проблемы, оказывающие влияние на сканируемость и индексируемость.
robots.txt
robots.txt — файл, расположенный в корневой директории каждого поддомена на веб-сайте, который говорит роботам, например поисковым, куда они могут и не могут заходить.
81.9% веб-сайтов используют файл robots.txt (для мобильных сайтов). По сравнению с предыдущими годами (72.2% в 2019 году и 80.5% в 2020 году) это небольшое улучшение.
Наличие robots.txt не обязательно. Если возвращается 404 ответ сервера, Google воспримет это как разрешение сканировать все страницы веб-сайта. Другие поисковые системы могут реагировать иначе.
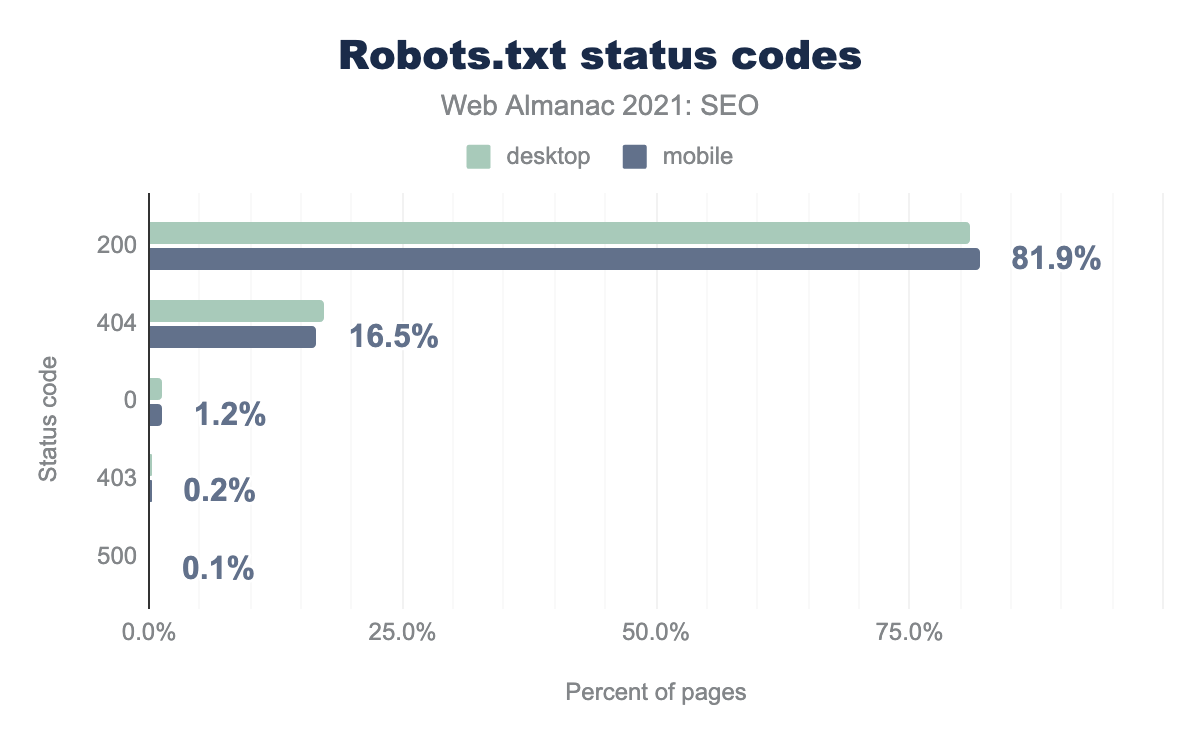
robots.txt. Код ответа сервера 200 получен от 81.9% мобильных веб-сайтов, 404 — от 16.5%. Другие коды ответа сервера практически не использовались, и показатели на компьютерах почти такие же, как и на мобильных устройствах.Использование robots.txt позволяет владельцам веб-сайтов контролировать поисковых роботов. Однако данные анализа показали, что у 16.5% веб-сайтов нет файла robots.txt.
У веб-сайтов может быть неправильно настроен robots.txt. Например, некоторые популярные веб-сайты (вероятно по ошибке) блокировали поисковых роботов. Google может хранить эти веб-сайты в индексе некоторое время, но в конце концов их видимость в результатах поиска будет снижена.
Другая категория ошибок, связанных с robots.txt — ошибки доступа или сети. Ситуация, когда robots.txt существует, но к нему нельзя получить доступ. Если Google запрашивает файл robots.txt и получает ошибку, он может временно приостановить сканирование. Логика в том, что поисковая система не уверена, может ли выбранная страница быть просканирована, поэтому ждет доступа к robots.txt.
По нашим данным ~0.3% веб-сайтов вернули ошибку 403 Доступ запрещен или 5xx. Разные роботы могут реагировать по-разному, поэтому мы не знаем, как именно Googlebot обработал ошибку.
По последней информации, полученной от Google за 2019 год, до 5% веб-сайтов временно возвращали 5xx ответ сервера при запросе robots.txt, в то время как 26% были недоступны.
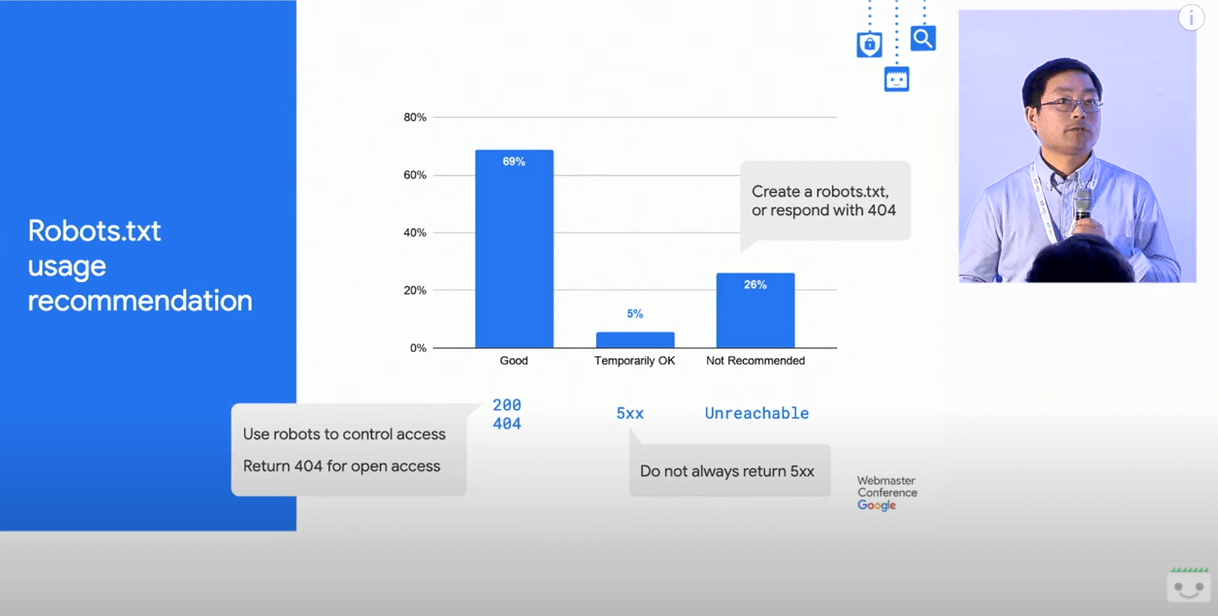
robots.txt от Googlebot. По данным за 2019 год 69% сайтов были в порядке и использовали ответ сервера 200 или 404 для открытого доступа. Целых 5% веб-сайтов были временно в порядке, возвращая 5хх при запросе robots.txt. 26% веб-сайтов оказались недоступны.Две вещи могут вызвать расхождение между данными HTTP Archive и Google:
Google представляет данные двухлетней давности, в то время как HTTP Archive основан на последней информации, или
HTTP Archive основан на данных веб-сайтов, которые достаточно популярны для попадания в CrUX, в то время как Google пытается посетить все известные веб-сайты.
Размер robots.txt
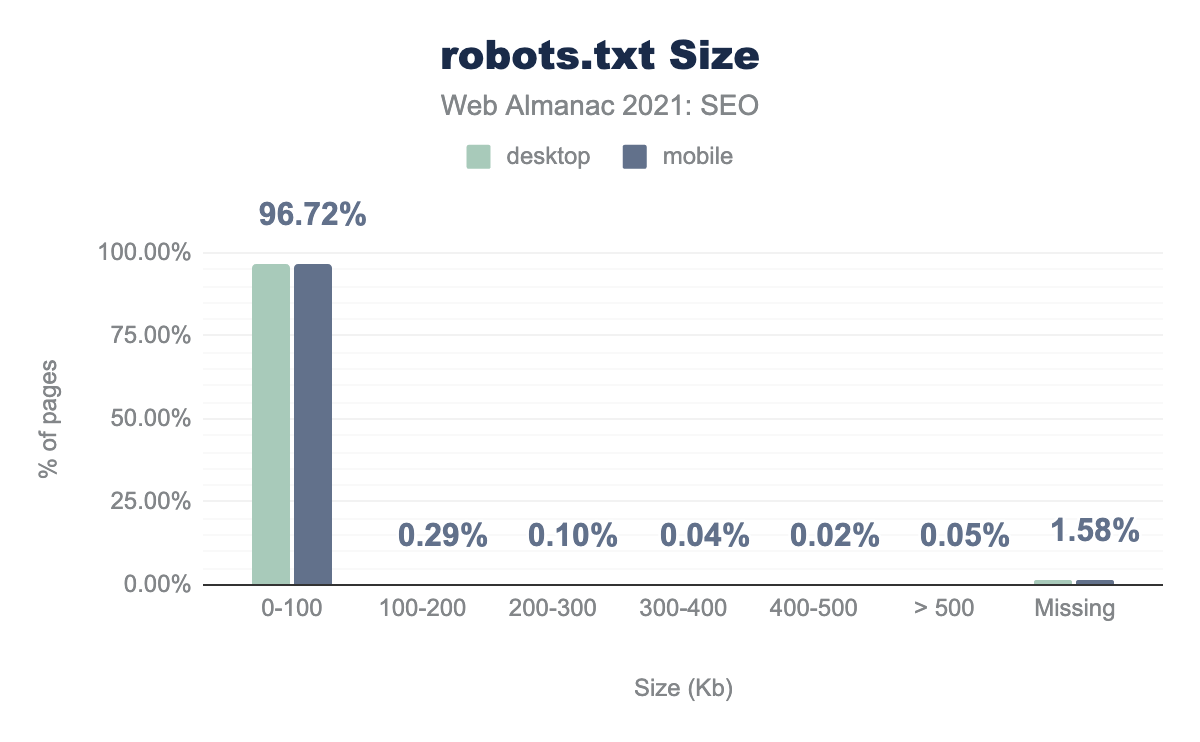
robots.txt. Почти все файлы robots.txt имеют небольшой размер и весят от 0 до 100 Кб. Мы обнаружили, что 96.72% файлов robots.txt на мобильных страницах имеют размер 0-100 Кб (аналогичные результаты и для компьютеров). Практически ни на одной из веб-страниц (на компьютерах или телефонах) не было файлов robots.txt размером более 100 Кб, а на 1.58% веб-сайтов он отсутствовал.robots.txt.
Большинство файлов robots.txt малы, их размер составляет от 0 до 100 Кб. Однако мы нашли более 3000 доменов с размером файла robots.txt больше 500 Кб, что превышает максимальный предел Google. Правила после этого ограничения будут проигнорированы.
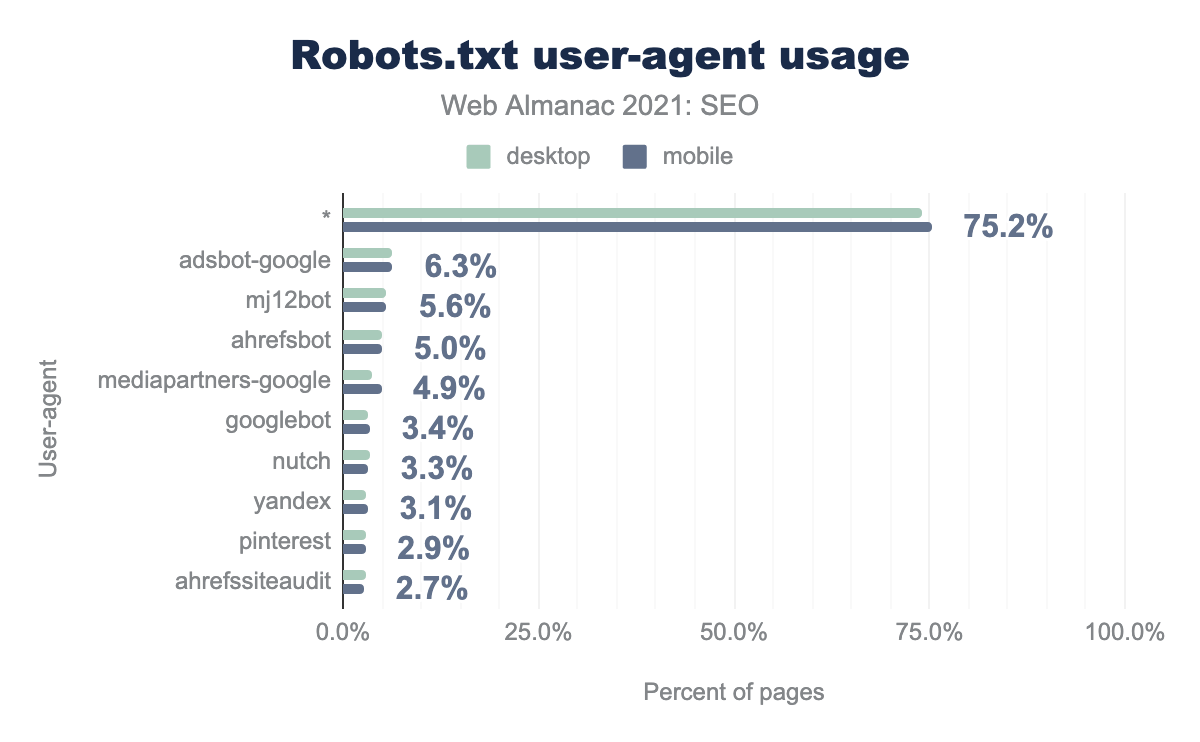
robots.txt. Результаты были схожи для компьютеров и мобильных устройств, 75.2% доменов не указывают конкретный пользовательский агент. Мы обнаружили adsbot-google в 6.3% случаев, mj12bot — 5.6%, ahrefsbot — 5.0%, mediapartners-google — 4.9%, googlebot — 3.4%, nutch — 3.3%, yandex — 3.1%, pinterest — 2.9%, ahrefssiteaudit — 2.7%.robots.txt.
Вы можете объявить правило для всех роботов или указать правило для конкретных роботов. Роботы обычно пробуют следовать по наиболее конкретному правилу для их пользовательского агента. User-agent: Googlebot будет относиться только к Googlebot, а User-agent: * будет относиться ко всем роботам, для которых нет более конкретного правила.
Мы увидели двух популярных SEO-роботов mj12bot (Majestic) и ahrefsbot (Ahrefs) в топ 5 наиболее часто используемых пользовательских агентов.
Распределение поисковых систем в robots.txt
| Робот | Компьютеры | Телефоны |
|---|---|---|
| Googlebot | 3.3% | 3.4% |
| Bingbot | 2.5% | 3.4% |
| Baiduspider | 1.9% | 1.9% |
| Yandexbot | 0.5% | 0.5% |
robots.txt.
При рассмотрении правил, применяемых к конкретным поисковым системам, чаще всего указывался робот Googlebot, который появлялся на 3,3% просканированных веб-сайтов.
Правила роботов, относящиеся к другим поисковым системам, таким как Bing, Baidu и Яндекс, менее популярны (2.5%, 1.9% и 0.5% соответственно). Мы не анализировали, какие правила применялись к этим роботам.
Канонические теги
Интернет — это огромный набор документов, некоторые из которых повторяются. Чтобы избежать дублирования контента, веб-разработчики могут использовать канонические теги, чтобы сообщать поисковым системам, какую версию следует индексировать. Канонические теги также помогают объединять сигналы, такие как ссылки на ранжируемую страницу.
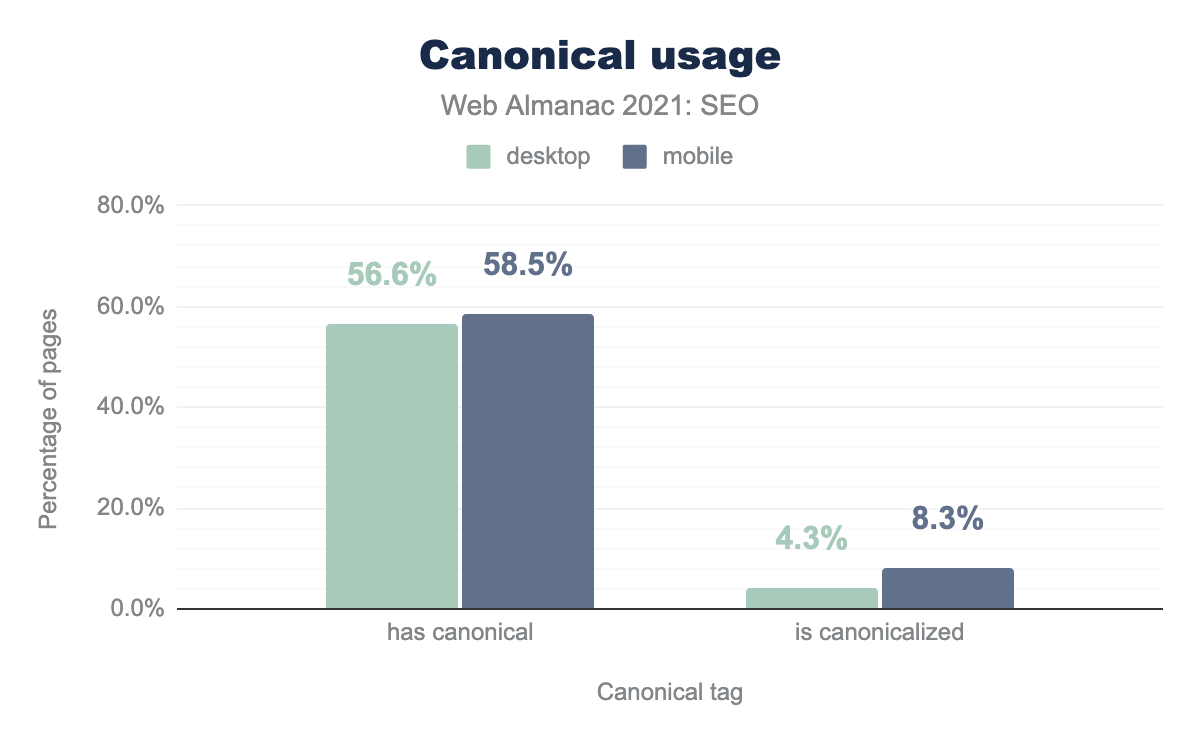
Данные показывают рост использования канонических тегов за последние годы. Например, издание 2019 года показывает, что 48.3% страниц мобильных страниц использовали канонический тег. В издании 2020 года процент вырос до 53.6%, а в 2021 — до 58.5%.
Канонические теги используются на большем количестве страниц для мобильных устройств, чем для компьютеров. Кроме того, 8.3% мобильных и 4.3% компьютерных страниц канонизированы в другую страницу, чтобы дать Google и другим поисковым системам, что страница, указанная в каноническом теге, является той, которую следует проиндексировать.
Большее число канонизированных страниц на мобильных устройствах, по-видимому, связано с веб-сайтами, использующими отдельные URL-адреса для мобильных устройств. В этих случаях Google рекомендует размещать тег rel="canonical", указывающий на соответствующие URL-адреса для компьютеров.
Наш набор данных и анализ ограничены главными страницами веб-сайтов; скорее всего, результат будет отличаться при рассмотрении всех URL-адресов на тестируемых веб-сайтах.
Два способа использования канонических тегов
Существует два способа использования канонических тегов:
- В секции
<head>HTML-документа - В HTTP-заголовке (через заголовок
Link)
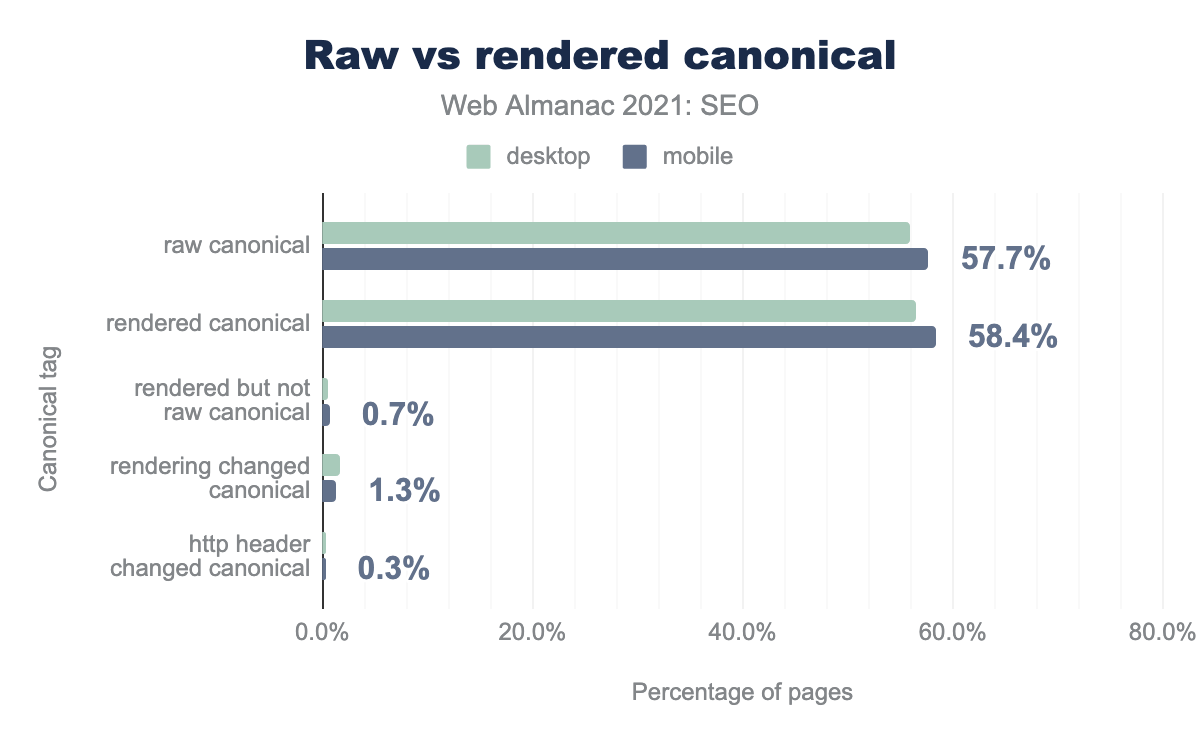
Внедрение канонических тегов в секции <head> HTML-документа популярнее, чем использование HTTP-заголовка Link. Реализация тега в секции <head> считается проще, поэтому используется значительно чаще.
Мы также увидели небольшое изменение (< 1%) в каноническом теге между доставленным необработанным и отрисованным HTML после применения JavaScript.
Конфликтующие канонические теги
Иногда страницы содержат более одного канонического тега. При возникновении таких противоречивых сигналов поисковым системам приходится в этом разбираться. Один из адвокатов поиска Google, Мартин Сплитт, однажды сказал, что это вызывает неопределенное поведение со стороны Google.
На предыдущем рисунке показано, что 1.3% мобильных страниц имеют разные канонические теги в исходном HTML и в отрисованной версии.
В прошлогодней главе отмечалось: «Подобный конфликт можно обнаружить с разными методами реализации: 0.15% мобильных и 0.17% компьютерных страниц показывают конфликты между каноническими тегами, реализованными через HTTP-заголовки и секцию head.»
Данные 2021 года по этому конфликту вызывают еще большую тревогу. Страницы отправляют противоречивые сигналы в 0.4% случаев на компьютерах и в 0.3% случаев на мобильных устройствах.
Поскольку данные Web Almanac охватывают только домашние страницы, могут возникнуть дополнительные проблемы со страницами, расположенными глубже в архитектуре сайта, так как они с большей вероятностью нуждаются в канонических сигналах.
Удобство страницы
В 2021 году стали уделять больше внимания пользовательскому опыту. Google выпустил обновление, связанное с удобством страниц, которое включает существующие сигналы, такие как HTTPS и удобство для мобильных устройств, а также новые показатели скорости под названием Core Web Vitals.
HTTPS
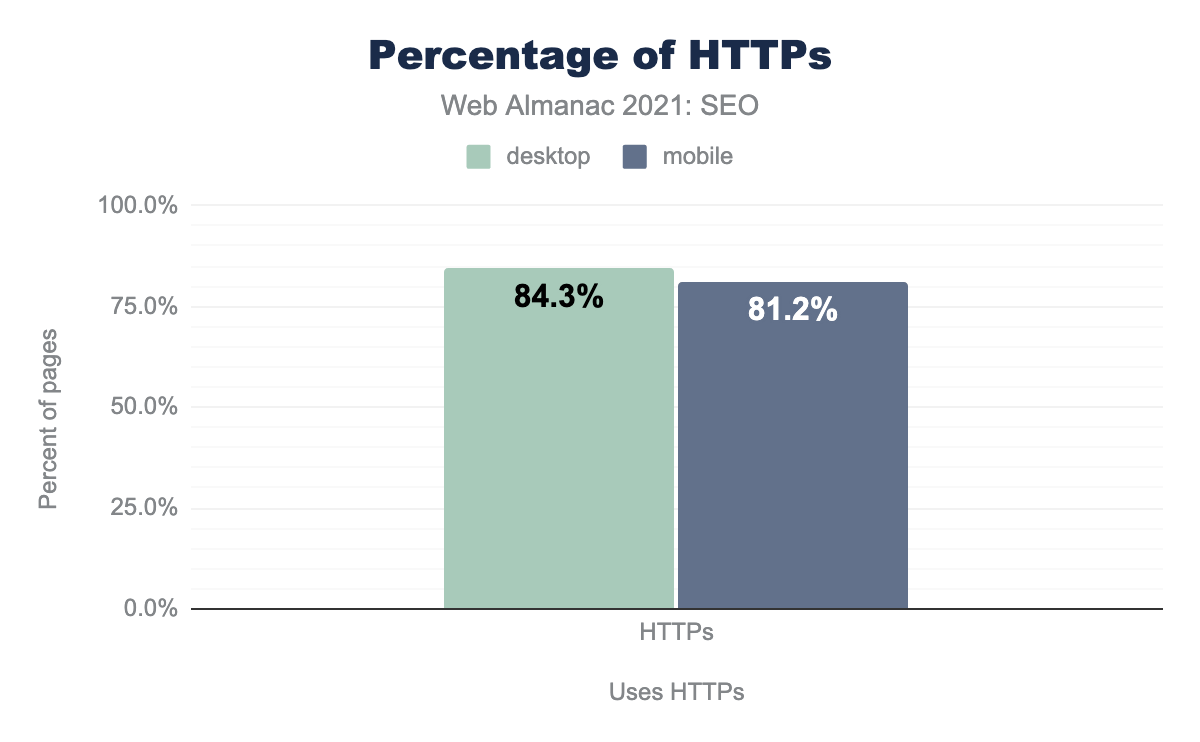
Распространение HTTPS все еще растет. HTTPS используется по умолчанию на 81.2% мобильных и 84.3% компьютерных страниц. Это больше почти на 8% на мобильных и на 7% на компьютерных сайтах по сравнению с прошлым годом.
Удобство для мобильных устройств
В этом году наблюдается небольшой всплеск удобства для мобильных устройств. Реализация адаптивного дизайна увеличились, в то время как динамический показ остался относительно неизменным.
Адаптивный дизайн отправляет один и тот же код и настраивает отображение веб-сайта в зависимости от размера экрана, в то время как динамический показ отправляет другой код в зависимости от устройства. Метатег viewport использовался для распознавания адаптивных веб-сайтов, а заголовок Vary: User-Agent — для распознавания веб-сайтов, использующих динамический показ.
viewport — сигнал удобства для мобильных устройств.
91.1% мобильных страниц содержат метатег viewport, по сравнению с 89.2% в 2020 году. 86.4% компьютерных страниц также содержат метатег viewport, по сравнению с 83.8% в 2020 году.
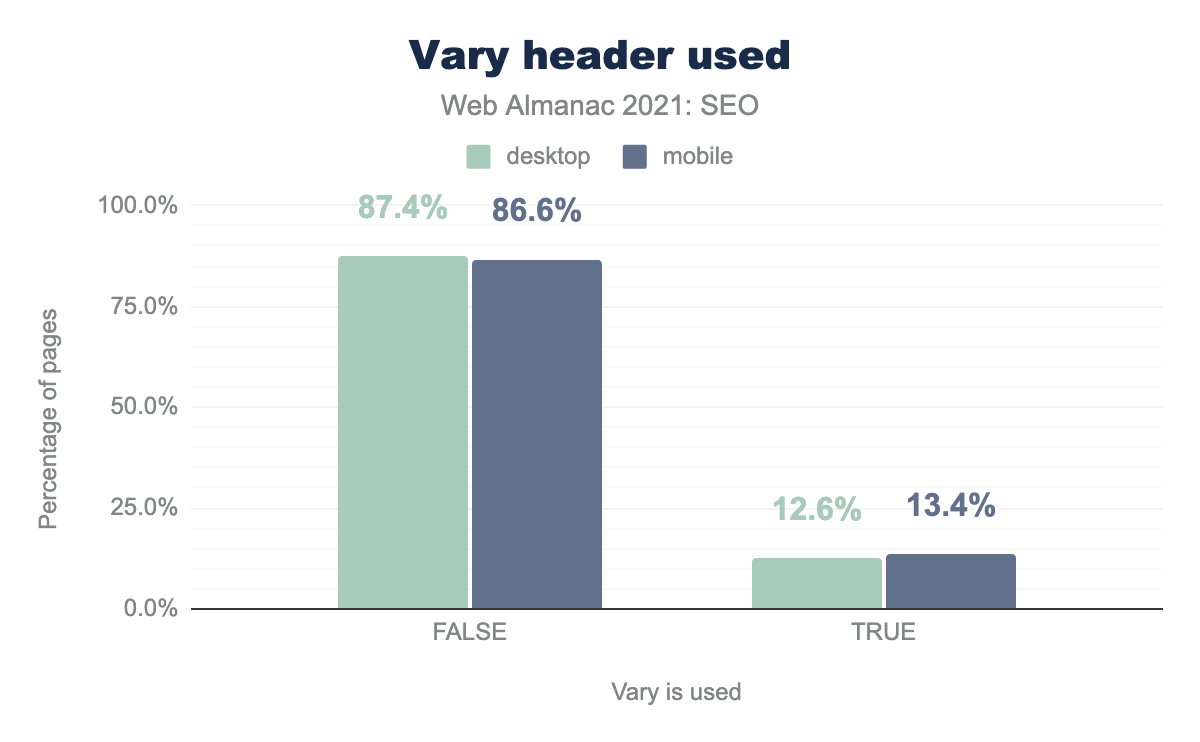
vary, необходимого для распознавания удобства для мобильных устройств. Мы обнаружили, что адаптивный дизайн на страницах используется чаще (87.4% для компьютеров и 86.6% для мобильных устройств), чем динамический показ (12.6% для компьютеров и 13.4% для мобильных устройств).Vary: User-Agent.
Для заголовка Vary: User-Agent цифры почти не изменились: 12.6% страниц для компьютеров и 13.4% мобильных страниц.
Одна из главных причин неудобства страниц для мобильных устройств — 13.5% страниц не используют разборчивые размеры шрифта. Это значит, что 60% или больше текста на странице имеют размер шрифта меньше 12px, что может сложно читаться на мобильных устройствах.
Core Web Vitals
Core Web Vitals — это новые показатели скорости, которые являются частью сигналов удобства страниц для Google. Метрики измеряют производительность загрузки с помощью Largest Contentful Paint (LCP), визуальную стабильность с Cumulative Layout Shift (CLS) и интерактивность с First Input Delay (FID).
Данные поступают из отчета о пользовательском опыте Chrome (CrUX), в котором записываются реальные данные от зарегистрированных пользователей Chrome.
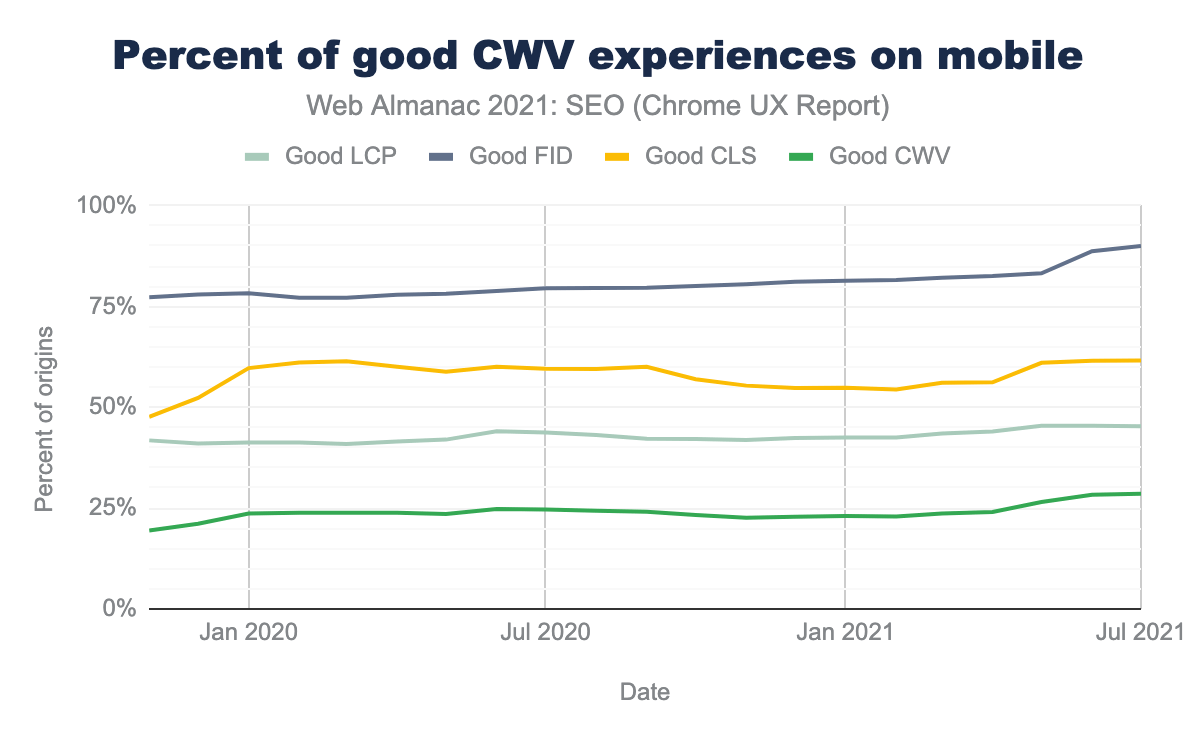
29% мобильных веб-сайтов удовлетворяют пороговым значениям Core Web Vitals по сравнению с 20% в прошлом году. У большинства веб-сайтов удовлетворительный показатель FID, но владельцы веб-сайтов, похоже, пытаются улучшить CLS и LCP. Дополнительную информацию по этой теме смотрите в главе Производительность.
On-Page
Поисковые системы просматривают контент вашей страницы, чтобы определить, соответствует ли содержимое поисковому запросу. Другие элементы на странице могут также влиять на ранжирование или внешний вид в поисковых системах.
Метаданные
Метаданные включают в себя элементы <title> и теги <meta name="description">. Метаданные могут напрямую или косвенно влиять на эффективность SEO.
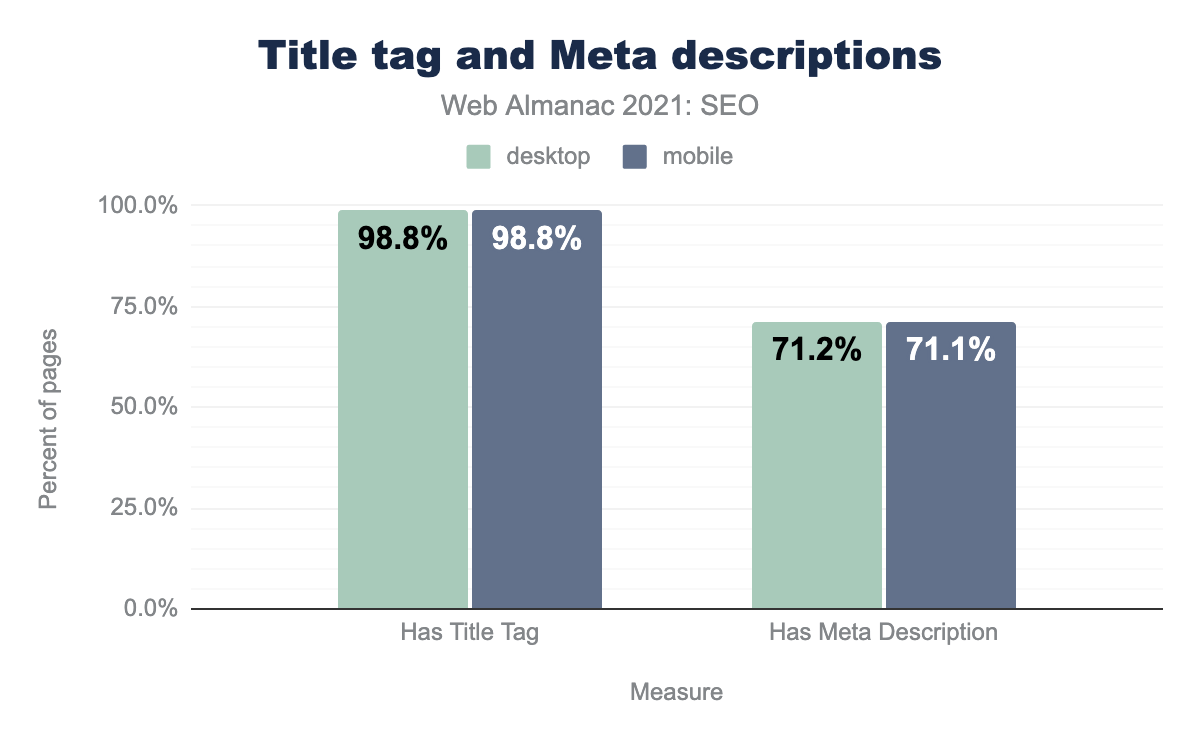
title, и на 71.1% — meta description.title и meta description.
В 2021 году 98.8% компьютерных и мобильных страниц содержали элемент <title>. 71.1% главных страниц для компьютеров и мобильных устройств содержали теги <meta name="description">.
Элемент <title>
Элемент <title> — это фактор ранжирования на странице, который дает подсказку о релевантности страницы и может отображаться на странице результатов поисковой системы (SERP). В августе 2021 года Google начал чаще переписывать заголовки в результатах поиска.
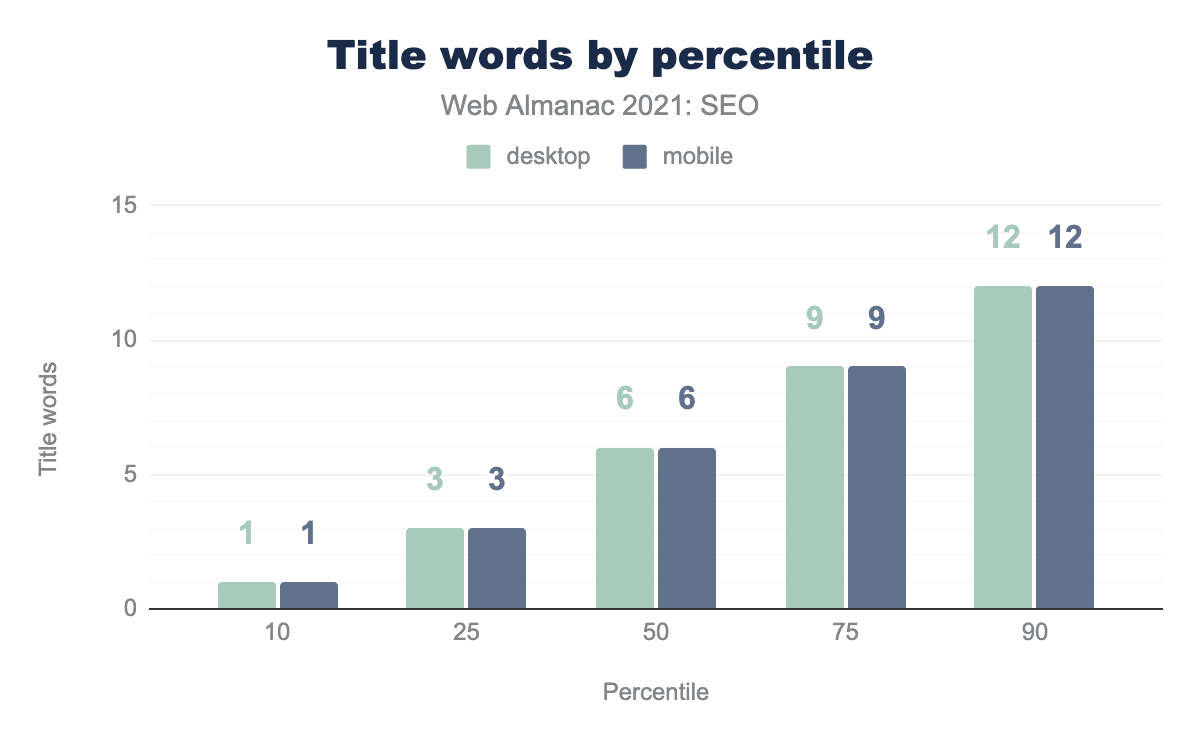
<title> на процентиль (10, 25, 50, 75 и 90). Средняя страница содержала заголовок, который имел 6 слов, и 50% всех заголовков содержали 3-9 слов. По нашим данным не было обнаружено разницы в количестве слов между компьютерными и мобильными страницами.<title>.
<title>.
В 2021 году:
- Средняя страница содержала 6 слов в
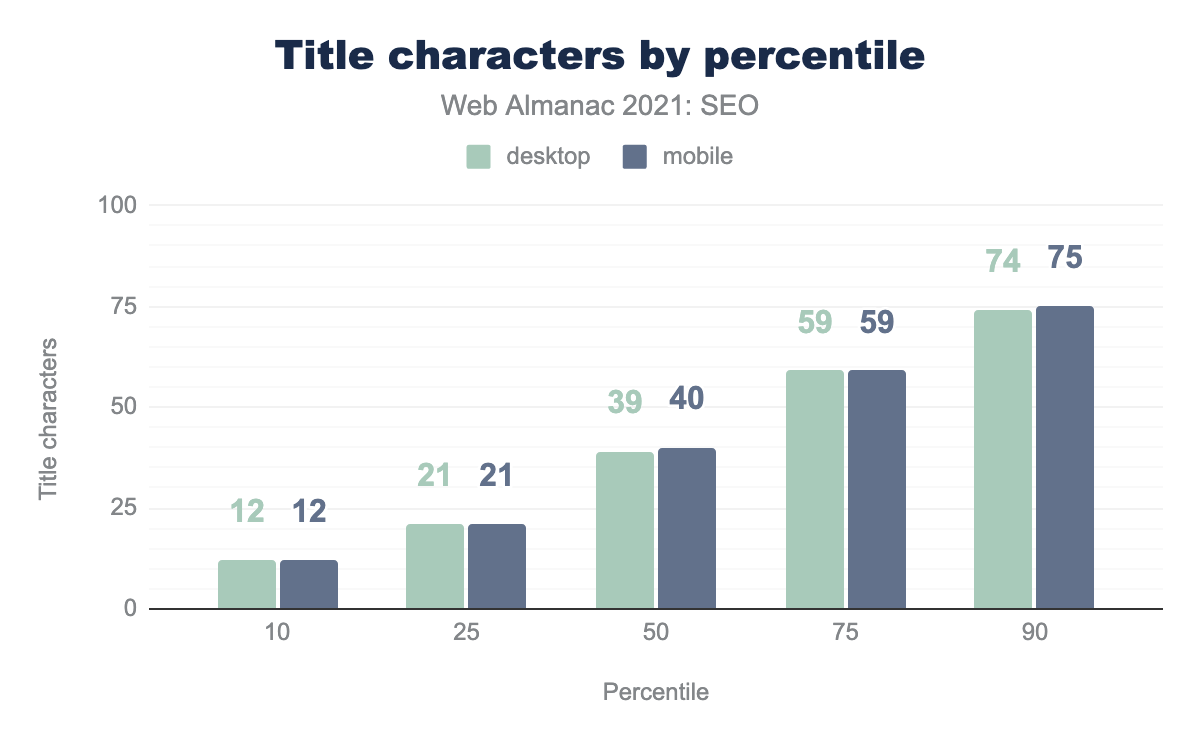
<title>. - Средняя страница содержала 39 и 40 символов в
<title>на компьютерах и мобильных устройствах соответственно. - На 10% страниц элемент
<title>содержал 12 слов. - На 10% компьютерных и мобильных страниц элемент
<title>содержал 74 и 75 символов соответственно.
Большинство из этих статистических данных относительно не изменились с прошлого года. Напоминаем, что это заголовки главных страниц, которые, как правило, короче, чем заголовки на более глубоких страницах.
Метатег description
Тег <meta name="description> не влияет напрямую на ранжирование, но может появляться в поисковой выдаче как описание страницы.
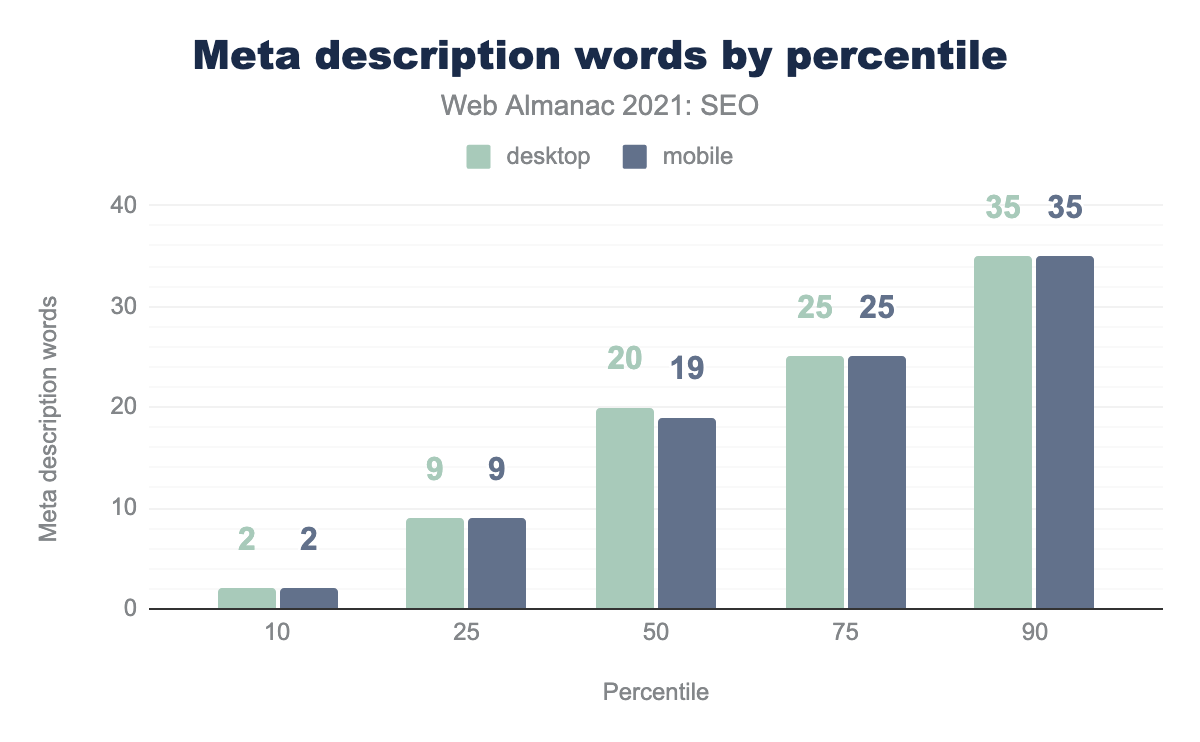
description на процентиль (10, 25, 50, 75 и 90). Средняя страница содержала мета описание из 20 слов для компьютеров и 19 слов для мобильных устройств. По нашим данным количество слов между компьютерами и мобильными устройствами отличалось незначительно.description.
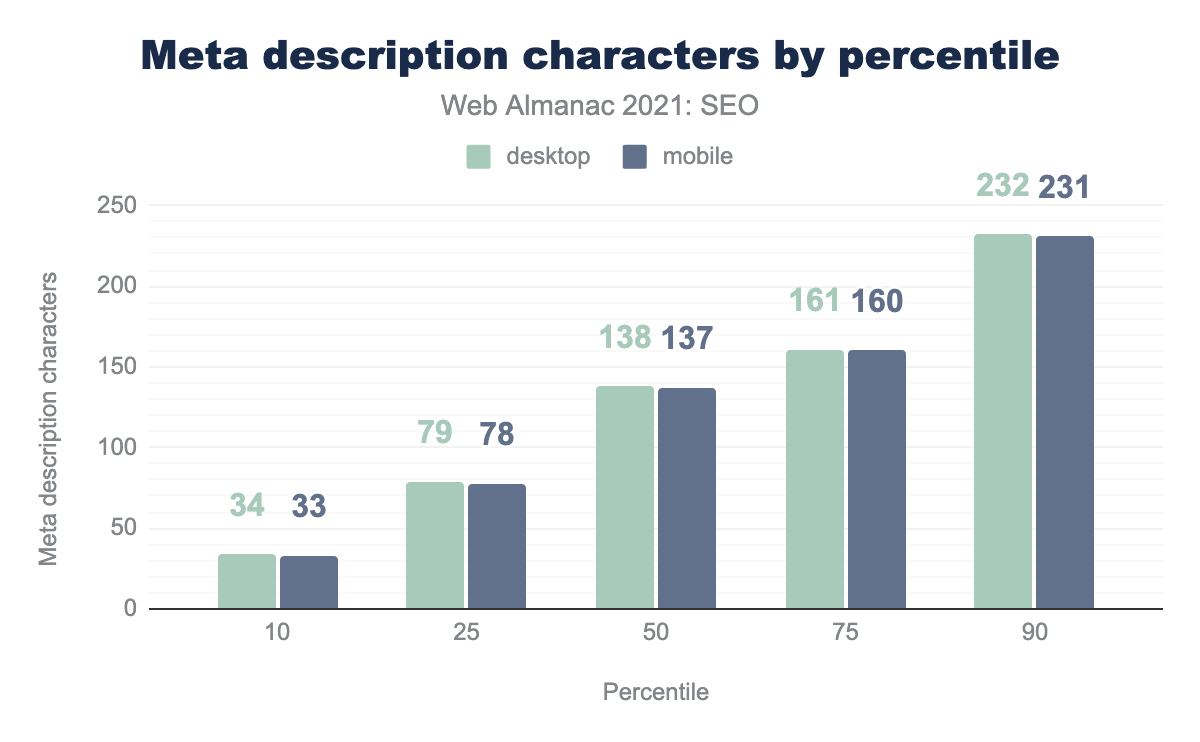
description на процентиль (10, 25, 50, 75 и 90). Средняя страница содержала мета описание длиной 138 символов на компьютерных и 137 символов на мобильных страницах. По нашим данным количество символов между компьютерами и мобильными устройствами отличалось незначительно.description.
В 2021 году:
- Средняя компьютерная и мобильная страницы содержали тег
<meta name="description>длиной 20 и 19 слов соответственно. - Средняя компьютерная и мобильная страницы содержали тег
<meta name="description>длиной 138 и 127 символов соответственно. - На 10% компьютерных и мобильных страниц тег
<meta name="description>был длиной 35 слов. - На 10% компьютерных и мобильных страниц тег
<meta name="description>был длиной 232 и 231 символов соответственно.
Эти показатели практически не изменились с прошлого года.
Изображения
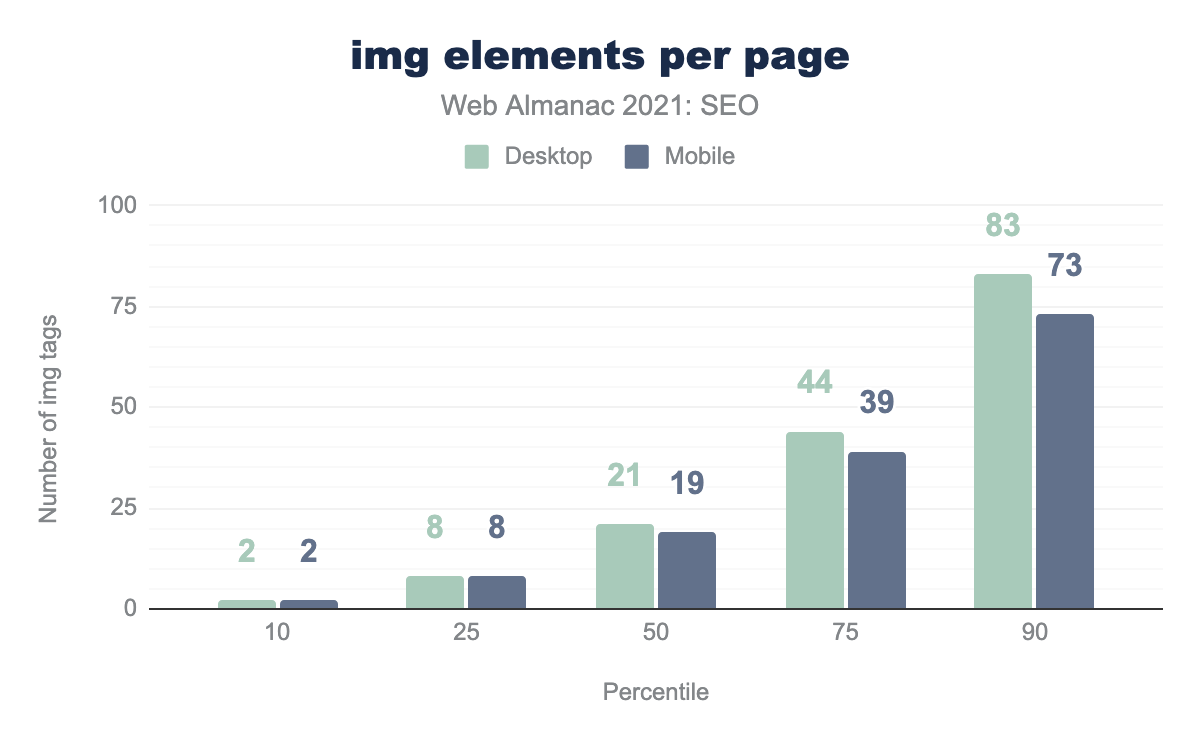
<img> на странице на процентиль (10, 25, 50, 75 и 90). Средняя компьютерная и мобильная страницы содержали 21 и 19 элементов <img> соответственно.Изображения могу напрямую или косвенно влиять на SEO, поскольку они влияют на рейтинг изображений в поиске и производительность страницы.
- 10% страниц содержат 2 или меньше тегов
<img>. Это верно и для компьютеров, и для мобильных устройств. - Средняя компьютерная и мобильная страницы содержат 21 и 19 тегов
<img>соответственно. - На 10% компьютерных страниц содержится 83 или больше тегов
<img>. На 10% мобильных страниц содержится 73 или больше тегов<img>.
Эти цифры незначительно изменились с 2020 года.
Атрибуты изображения alt
Атрибут alt для элемента <img> помогает пояснить содержимое изображения и влияет на общедоступность.
Обратите внимание, что отсутствие атрибута alt не означает проблему. Страницы могут содержать очень маленькие или пустые изображения, которым не требуется атрибут alt для SEO или общедоступности.
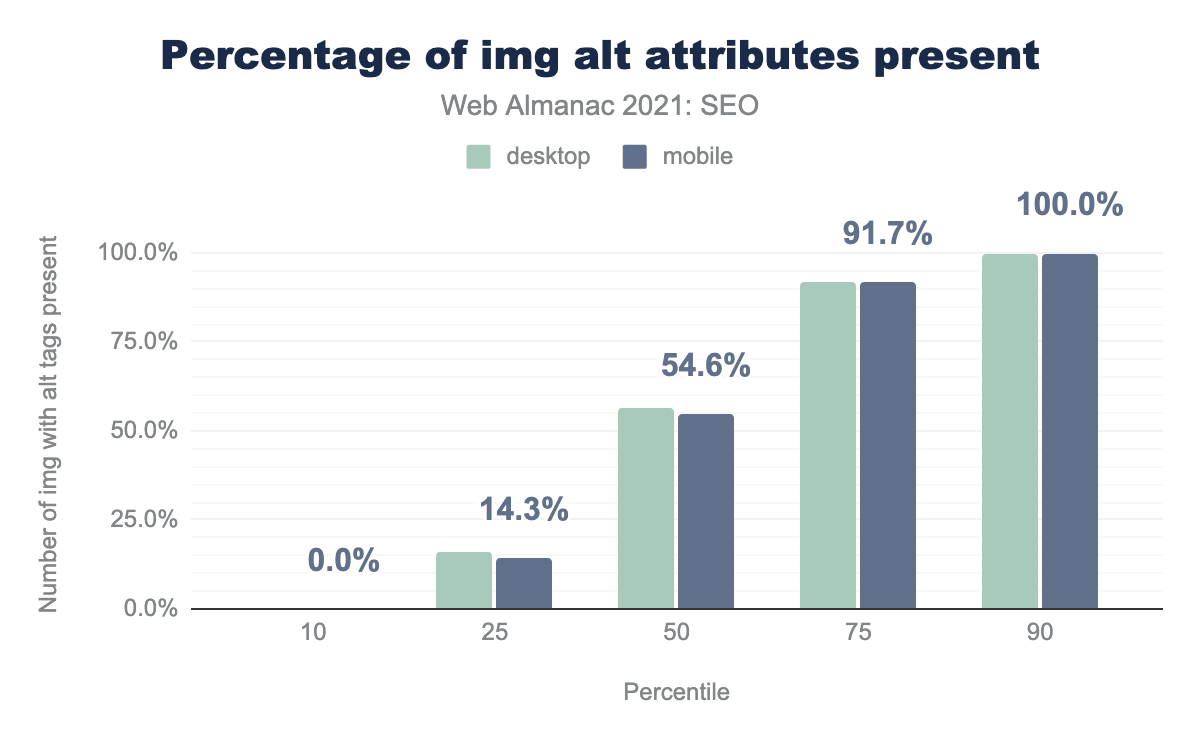
alt на процентиль (10, 25, 50, 75 и 90). По нашим данным средняя страница содержит 54.6% и 56.5% изображений с атрибутом alt на мобильных и компьютерных страницах соответственно.alt.
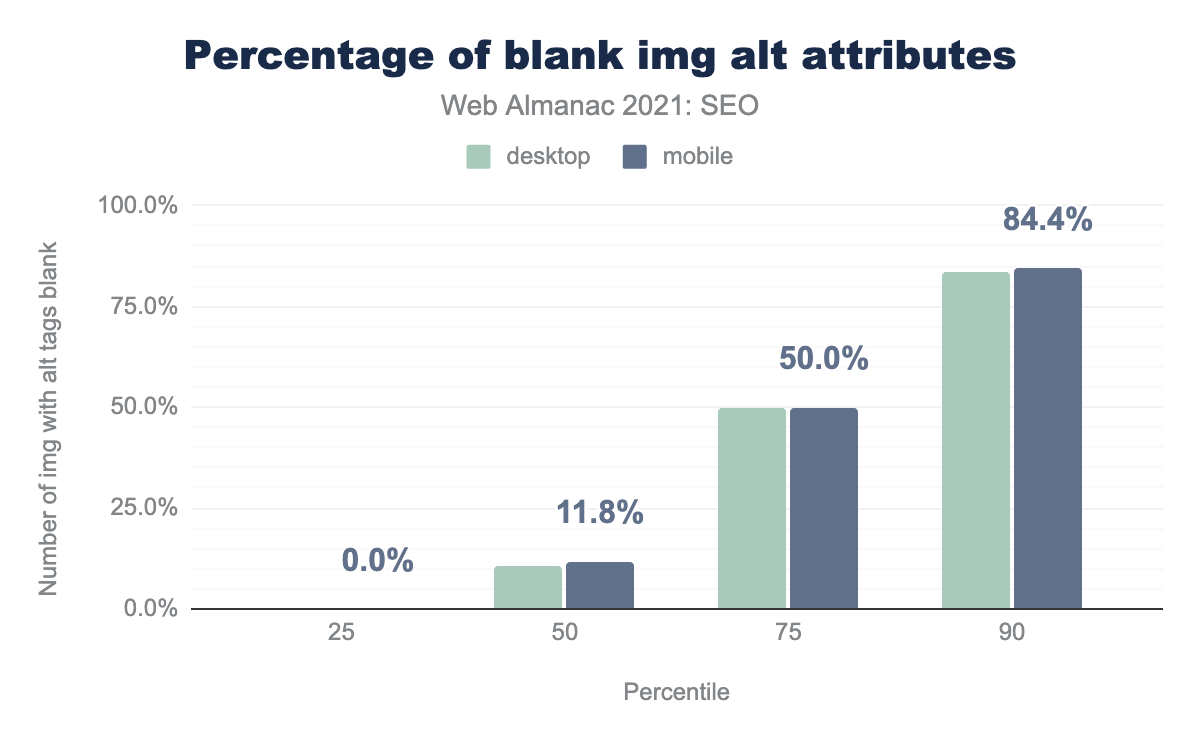
alt на процентиль (25, 50, 75 и 90). Средняя веб-страница содержала 10.5% и 11.8% пустых атрибутов alt на компьютерных и мобильных страницах соответственно.alt.
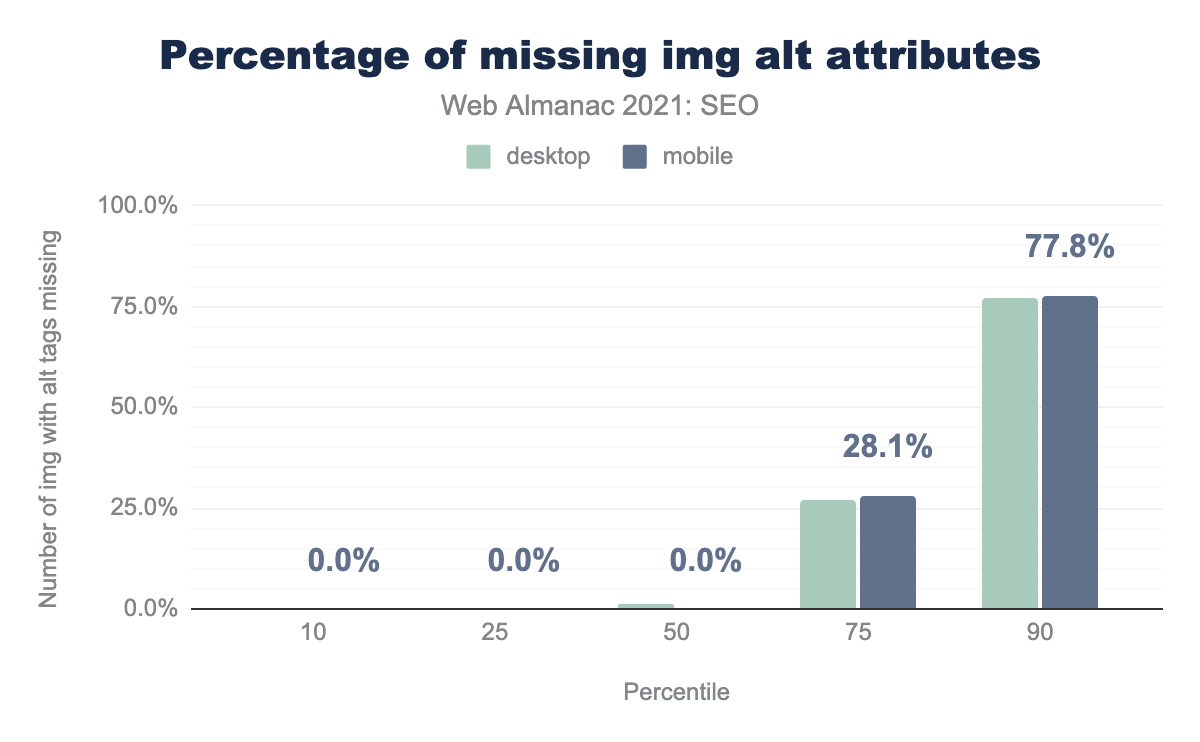
alt на процентиль (10, 25, 50, 75 и 90). Средняя веб-страница содержала 1.4% изображений без атрибутов alt на компьютерах и 0 изображений — на мобильных устройствах.alt.
Мы обнаружили, что:
- На средней компьютерной странице 56.5% тегов
<img>содержали атрибутalt. Это небольшой рост по сравнению с 2020 годом. - На средней мобильной странице 54.6% тегов
<img>содержали атрибутalt. Это небольшой рост по сравнению с 2020 годом. - Однако в среднем страницы для компьютеров и мобильных устройств в 10.5% и 11.8% случаев имеют пустые атрибуты
altдля тегов<img>соответственно. Это фактически то же самое, что и в 2020 году. - На средних страницах для компьютеров и мобильных устройств нет или почти нет тегов
<img>без атрибутовalt. Это улучшение по сравнению с 2020 годом, когда на 2-3% страниц теги<img>не содержали атрибутыalt.
Атрибуты изображений loading
Атрибут loading в элементах <img> влияет на приоритет рендеринга и отображения изображений на странице. Это может влиять на пользовательский опыт и производительность загрузки страницы, оба фактора влияют на SEO.
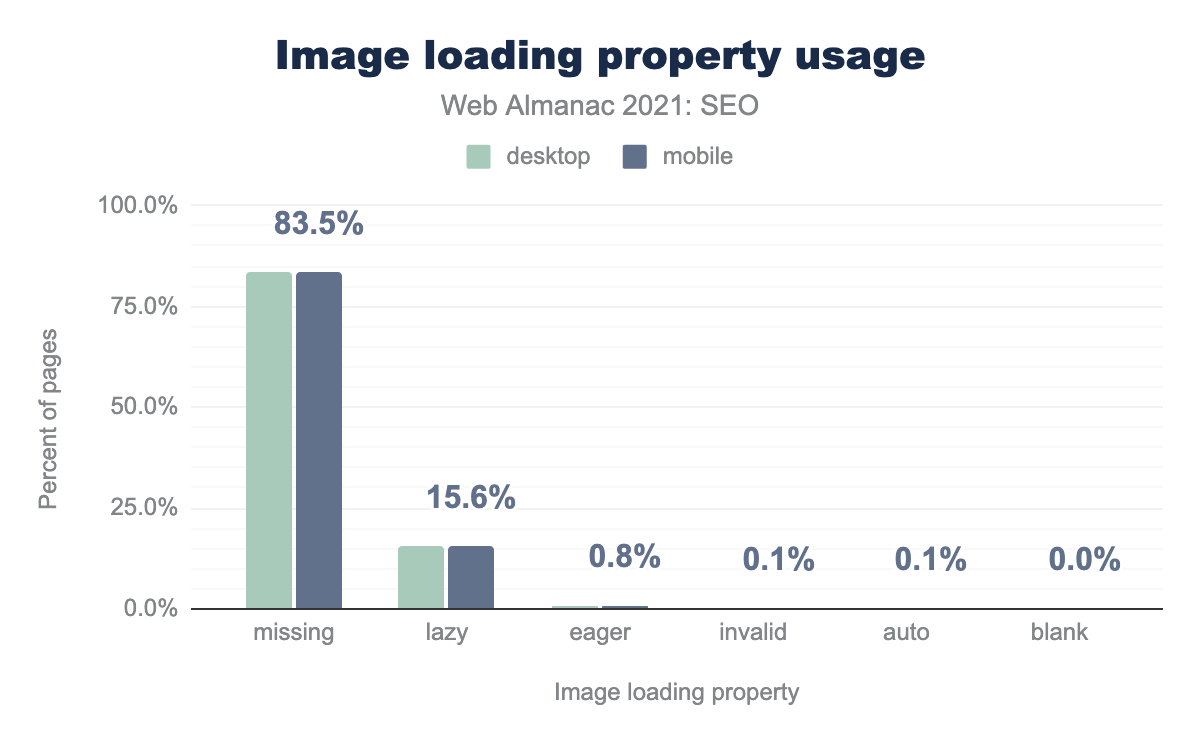
loading (missing — отсутствует, lazy, eager, invalid — недопустимое значение, auto, blank - пустое). По нашим данным на 83.3% компьютерных и 83.5% мобильных страниц отсутствовал атрибут loading для изображений. Мы обнаружили, что loading="lazy" используется на 15.6% страниц для компьютеров и мобильных устройств, в то время как только 0.8% страниц для компьютеров и мобильных устройств используют loading="eager". Количество других случаев составлет менее 1% на компьютерных и мобильных страницах, сюда входят случаи с недопустимым или пустым значением атрибута или со значением auto.loading.
Мы обнаружили, что:
- 85.5% страниц не используют атрибут
loadingдля изображений. - 15.6% страниц используют значение
loading="lazy", которое откладывает загрузку изображения до тех пор, пока оно не приблизится к области просмотра. - 0.8% страниц используют значение
loading="eager", которое загружает изображение сразу же, как только браузер загружает код. - 0.1% страниц используют недопустимое значение атрибута.
- 0.1% страниц используют значение
loading="auto", которое использует поведение браузера по умолчанию.
Количество слов
Количество слов на странице не является фактором ранжирования, но то, как страницы отображают слова, может сильно повлиять на ранжирование. Слова могут быть в необработанном коде страницы или отрисованном контенте.
Количество слов после отрисовки
В первую очередь мы смотрим на отрисованный контент страницы. Отрисованный контент — это содержимое страницы после выполнения браузером всего JavaScript и любого другого кода, который изменяет DOM или CSSOM.
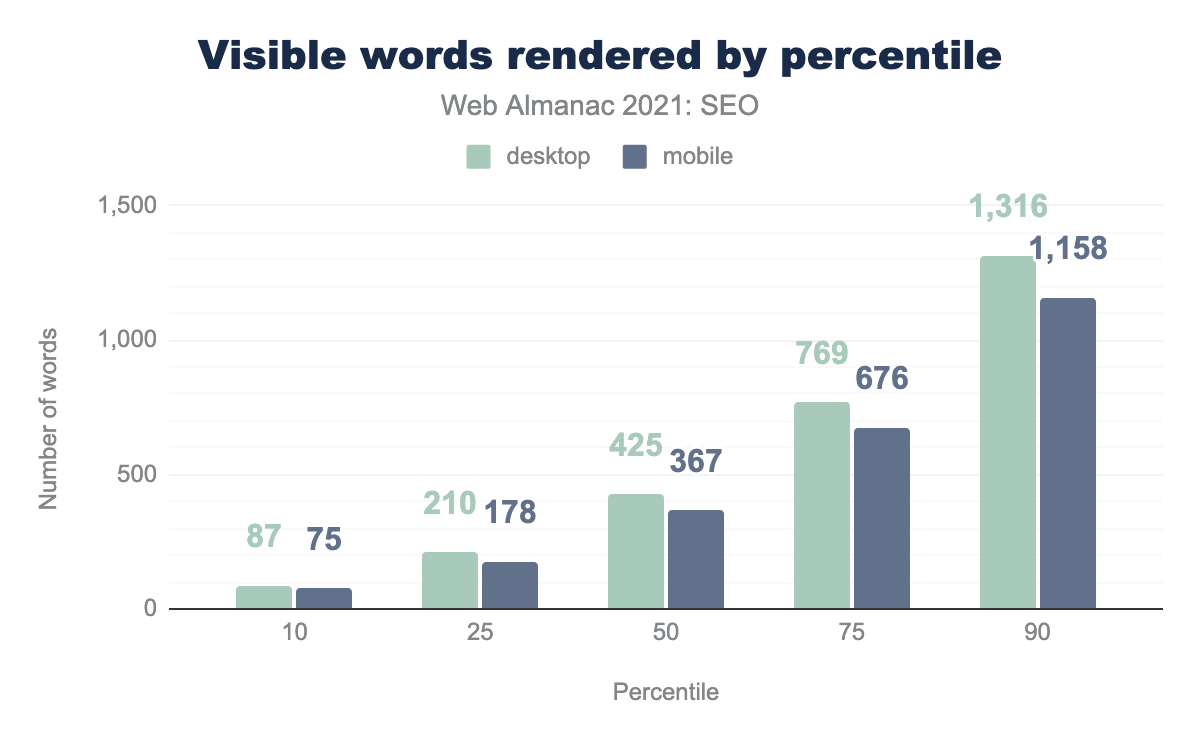
- Средняя отрисованная компьютерная страница содержит 425 слов, по сравнению с 402 словами в 2020 году.
- Средняя отрисованная мобильная страница содержит 367 слов, по сравнению с 348 словами в 2020 году.
- Отрисованные мобильные страницы содержат на 13.6% слов меньше, чем отрисованные компьютерные страницы. Обратите внимание, что Google — это индекс в первую очередь для мобильных устройств. Контент, которого нет в мобильной версии, может не индексироваться.
Количество слов в необработанном варианте
Далее мы смотрим на необработанное содержимое страницы. Необработанный контент — это содержимое страницы до того, как браузер выполнил JavaScript или любой другой код, меняющий DOM или CSSOM. Это «сырой» контент, доставляемый и видимый в исходном коде.
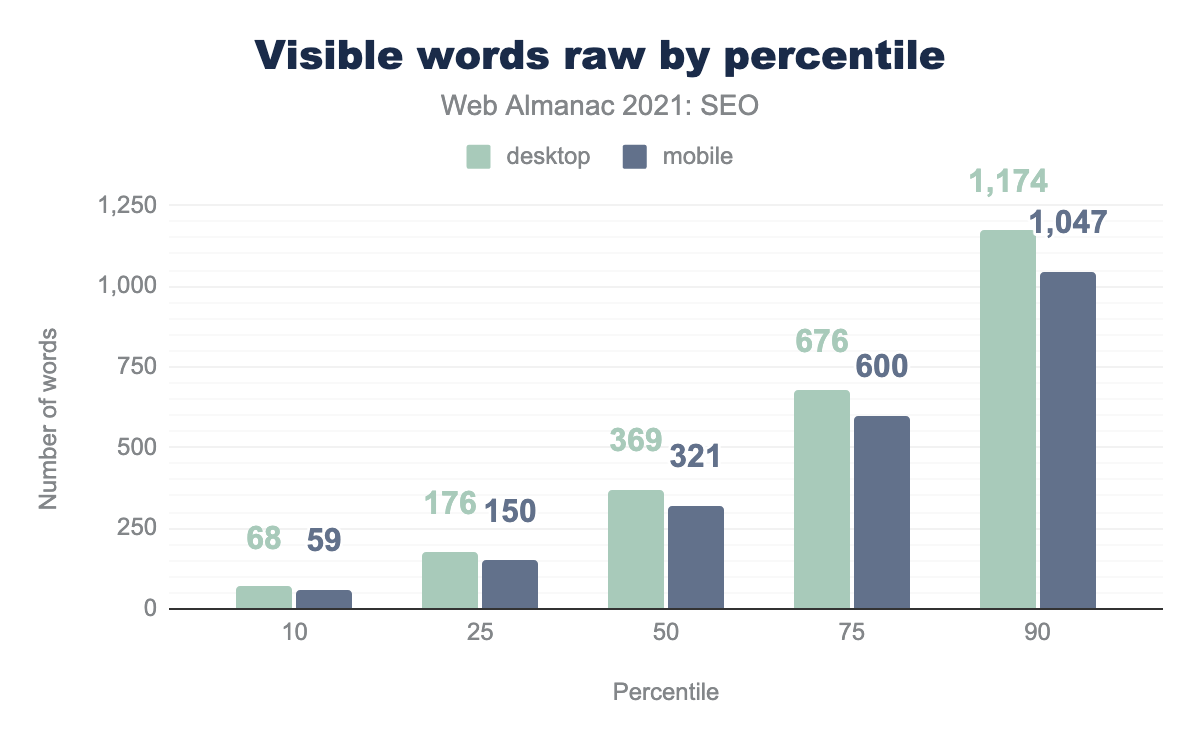
- Средняя необработанная компьютерная страница содержит 369 слов, по сравнению с 360 словами в 2020 году.
- Средняя необработанная мобильная страница содержит 321 слово, по сравнению с 312 словами в 2020 году.
- Необработанная мобильная страница содержит на 13.1% меньше слов, чем необработанная компьютерная страница. Обратите внимание, что Google — это индекс в первую очередь для мобильных устройств. Контент, которого нет в мобильной HTML-версии, может не индексироваться.
В целом, с помощью JavaScript генерируется 15% письменного контента на компьютерах, и 14.3% — на мобильных устройствах.
Структурированные данные
Исторически поисковые системы работали с неструктурированными данными: наборами слов, абзацев и другого контента, составляющего текст страницы.
Разметка schema.org и другие типы структурированных данных предоставляют поисковым системам еще один способ анализа и организации контента. Структурированные данные поддерживают работу многих функций поиска Google.
Как и слова на странице, структурированные данные можно изменить с помощью JavaScript.
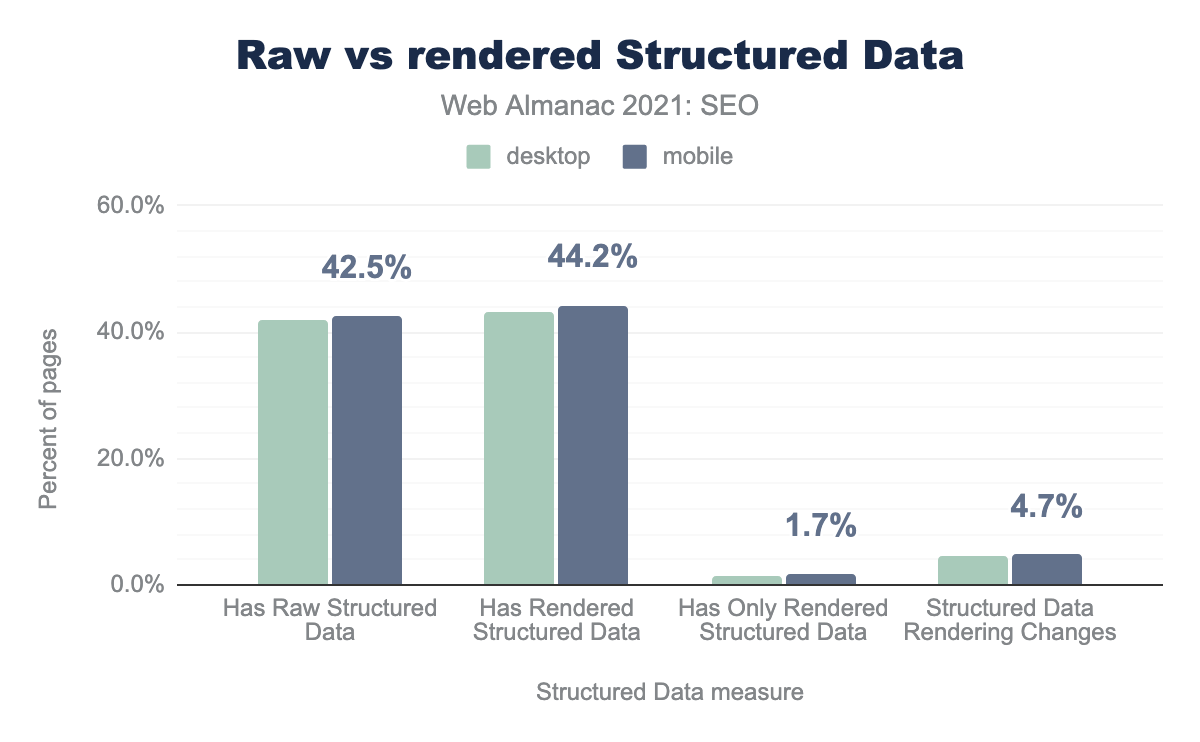
42.5% мобильных и 41.8% компьютерных страниц содержали структурированные данные в исходном HTML. JavaScript изменяет структурированные данные на 4.7% мобильных и 4.5% компьютерных страниц.
На 1.7% мобильных и 1.4% компьютерных страниц структурированные данные были добавлены с помощью JavaScript, их не было в исходном HTML.
Наиболее популярные форматы структурированных данных
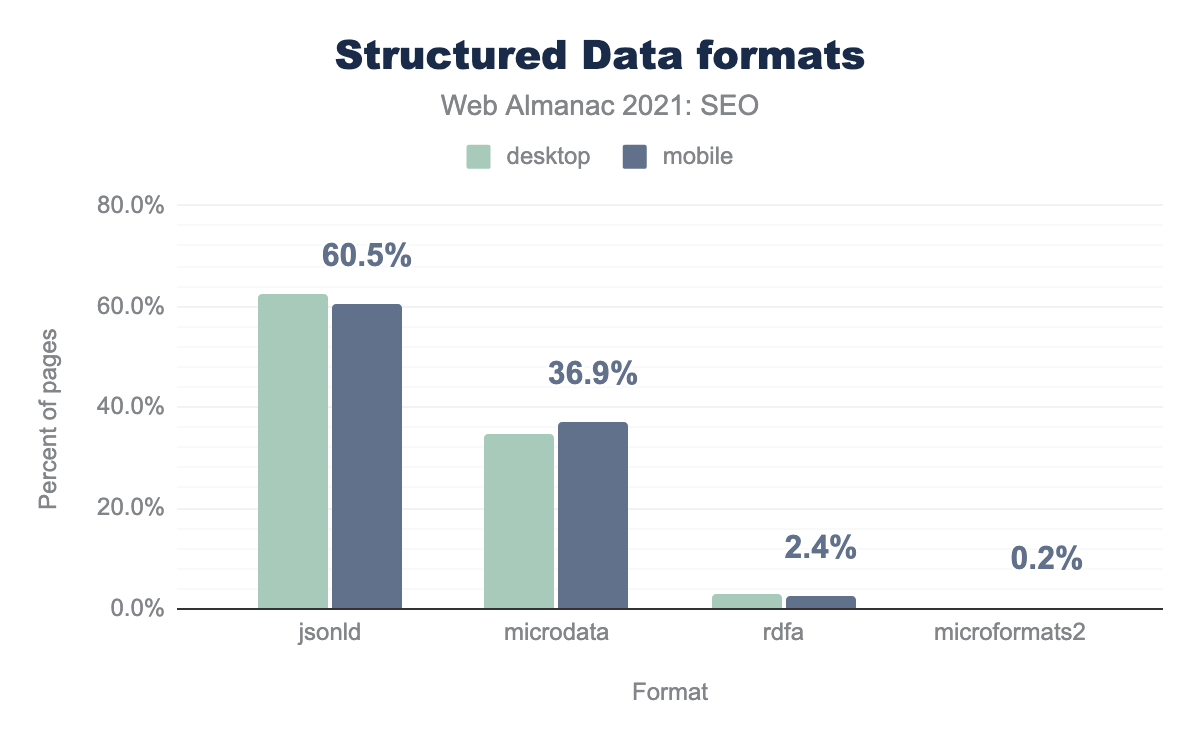
Существует несколько способов использования структурированных данных на странице: JSON-LD, microdata, RDFa, и microformats2. JSON-LD — наиболее популярный метод реализации. Более 60% страниц для компьютеров и мобильных устройств со структурированными данными используют JSON-LD.
Среди веб-сайтов, использующих структурированные данные, более 36% страниц для компьютеров и мобильных устройств используют microdata и менее 3% страниц используют RDFa или microformats2.
Внедрение структурированных данных немного выросло по сравению с прошлым годом. Структурированные данные используются на 33.2% страниц в 2021 году, по сравению с 30.6% в 2020 году.
Наиболее популярные типы разметки schema.org
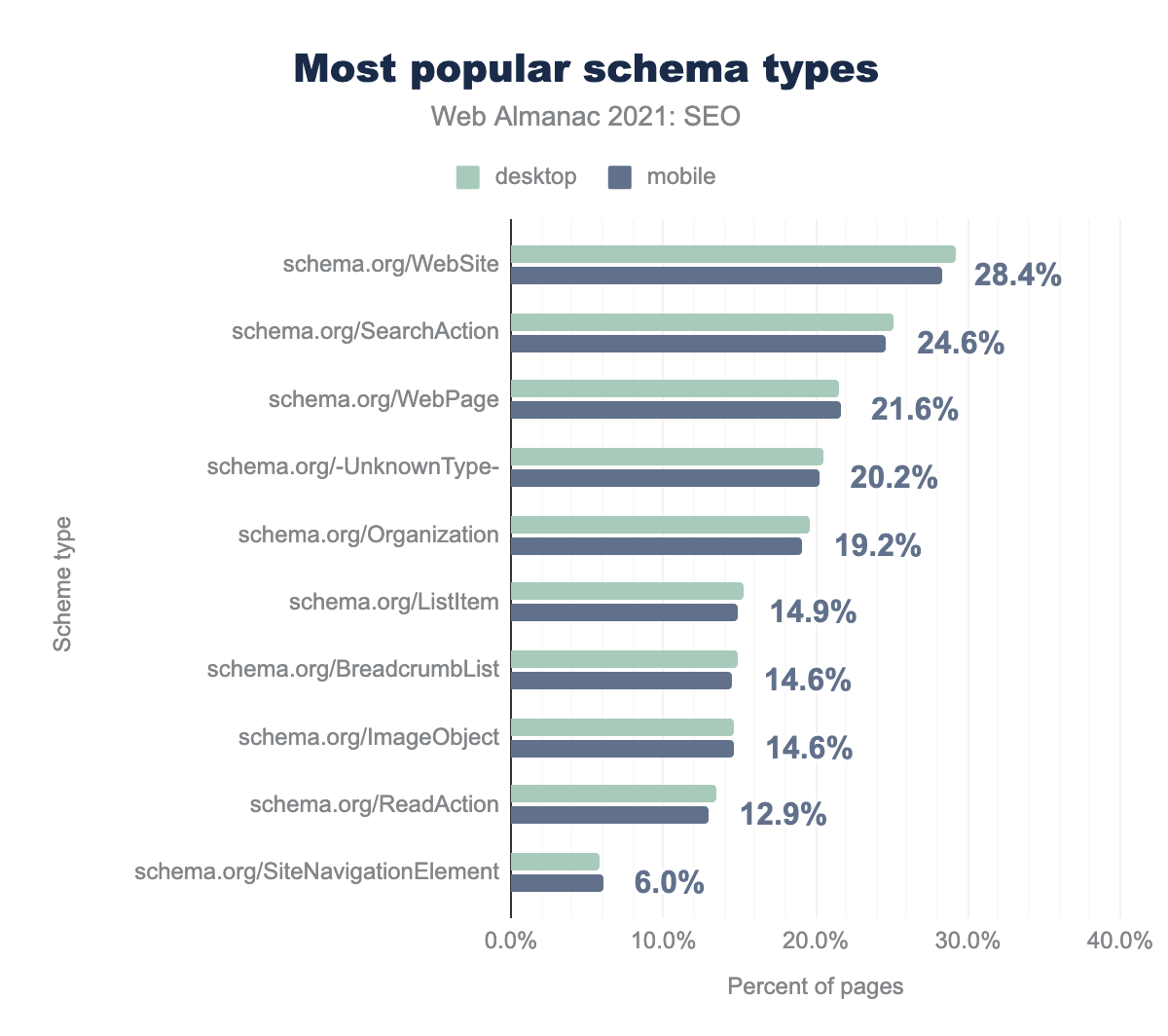
WebSite, SearchAction, WebPage, UnknownType и Organization.Наиболее популярными типами разметки schema.org являются WebSite, SearchAction, WebPage. SearchAction — это то, что приводит в действие окно поиска по сайту, которое Google может выбрать для отображения на странице результатов поиска.
Элементы <h> (заголовки)
Элементы заголовков (<h1>, <h2> и так далее) являются важными структурными элементами. Хотя они не влияют напрямую на ранжирование, они помогают Google лучше понять содержание страницы.
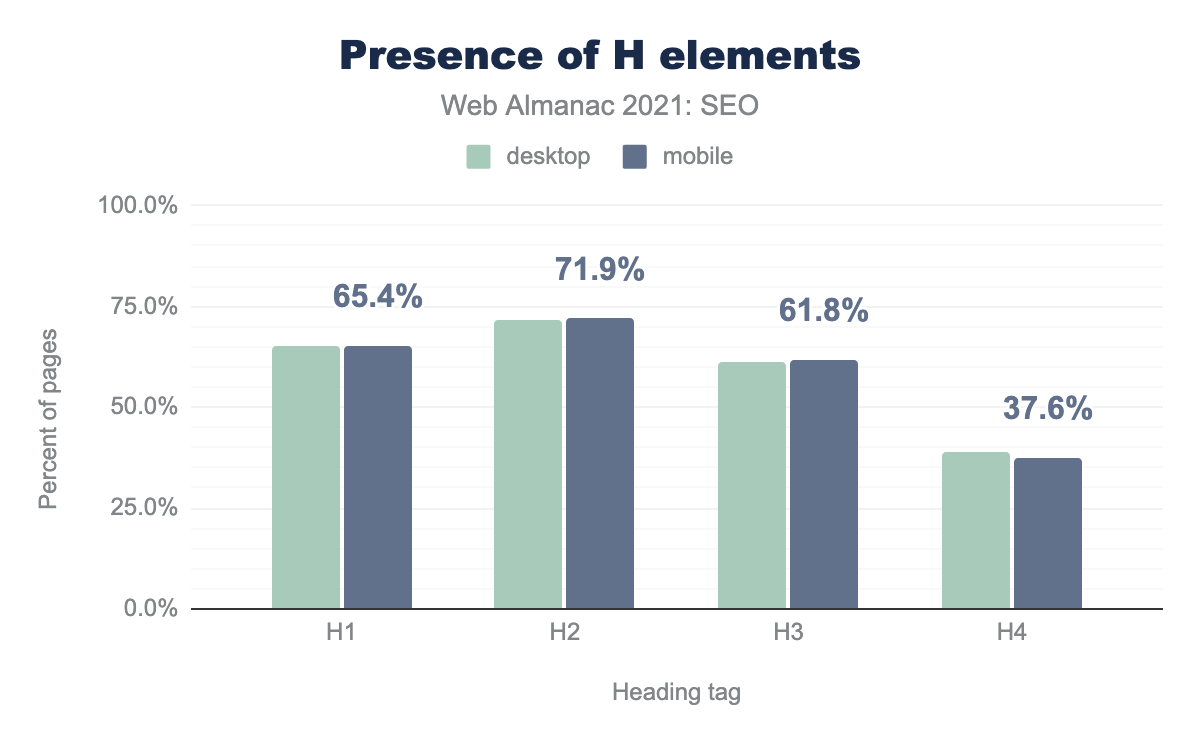
h1 встречались на 65.4% страниц, h2 чаще всего — на 71.9%, h3 — на 61.8%, и h4 — на 37.6% страниц.Касаемо заголовков, на большем количестве страниц (71.9%) есть h2, чем h1 (65.4%). Очевидного объяснения этому расхождению нет. На 61.4% компьютерных и мобильных страниц есть h3 и менее чем на 39% — h4.
Разница в использовании заголовков между компьютерами и мобильными устройствами минимальная, также не было серьезных изменений по сравнению с 2020 годом.

<h> разного уровня (уровень 1, 2, 3, 4). Между результатами для компьютеров и мобильных устройств почти нет разницы. Заголовки h1 встречались на 58.1% страниц, h2 чаще всего — на 70.5%, h3 — на 60.3%, и h4 — на 36.5% страниц.Однако меньший процент страниц содержит непустые элементы <h>, особенно h1. Веб-сайты часто помещают изображения логотипов в элементы <h1> на главных страницах, и это может объяснить расхождение.
Ссылки
Поисковые системы используют ссылки для обнаружения новых страниц и передачи PageRank, что помогает определить важность страниц.
Помимо PageRank, текст, используемый в качестве анкора ссылки, помогает поисковым системам понять, о чем связанная страница. В Lighthouse есть тест, чтобы проверить, является ли используемый анкор полезным текстом, или это общий анкор, такой как “узнать больше” или “нажмите здесь”, который не очень информативен. 16% протестированных ссылок не имели информативного анкорного текста, что является упущенной возможностью с точки зрения SEO, а также плохо влияет на общедоступность.
Внутренние и внешние ссылки
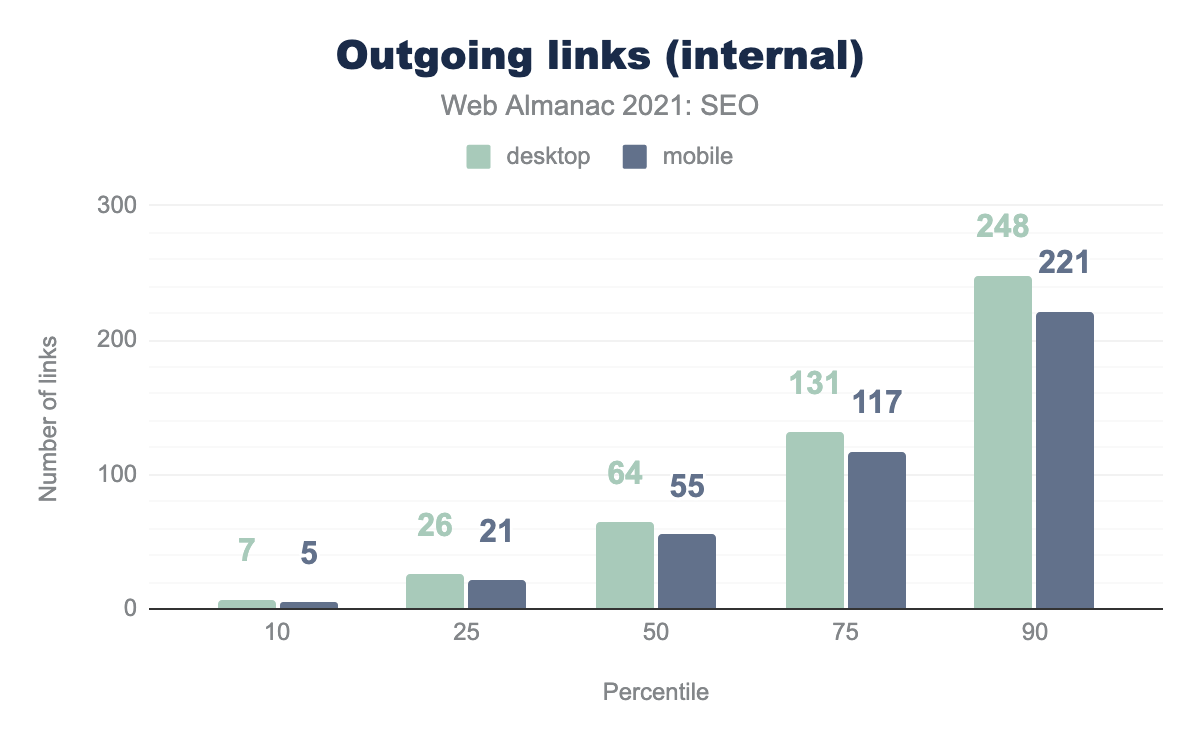
Внутренние ссылки — это ссылки на другие страницы того же сайта. Страницы имели меньше ссылок в мобильных версиях по сравнению с компьютерными версиями.
Данные показывают, что среднее количество внутренних ссылок на компьютерах на 16% выше, чем на мобильных устройствах: 64 против 55 соответственно. Скорее всего, это связано с тем, что разработчики склонны минимизировать навигационные меню и нижние колонтитулы на мобильных устройствах, чтобы упростить их использование на небольших экранах.
Самые популярные сайты (1000 лучших по данным CrUX) имеют больше исходящих внутренних ссылок, чем менее популярные сайты. 144 на компьютерах против 110 на мобильных устройствах, что более чем в два раза выше среднего! Это может быть связано с использованием мега-меню на больших сайтах, которые обычно имеют больше страниц.
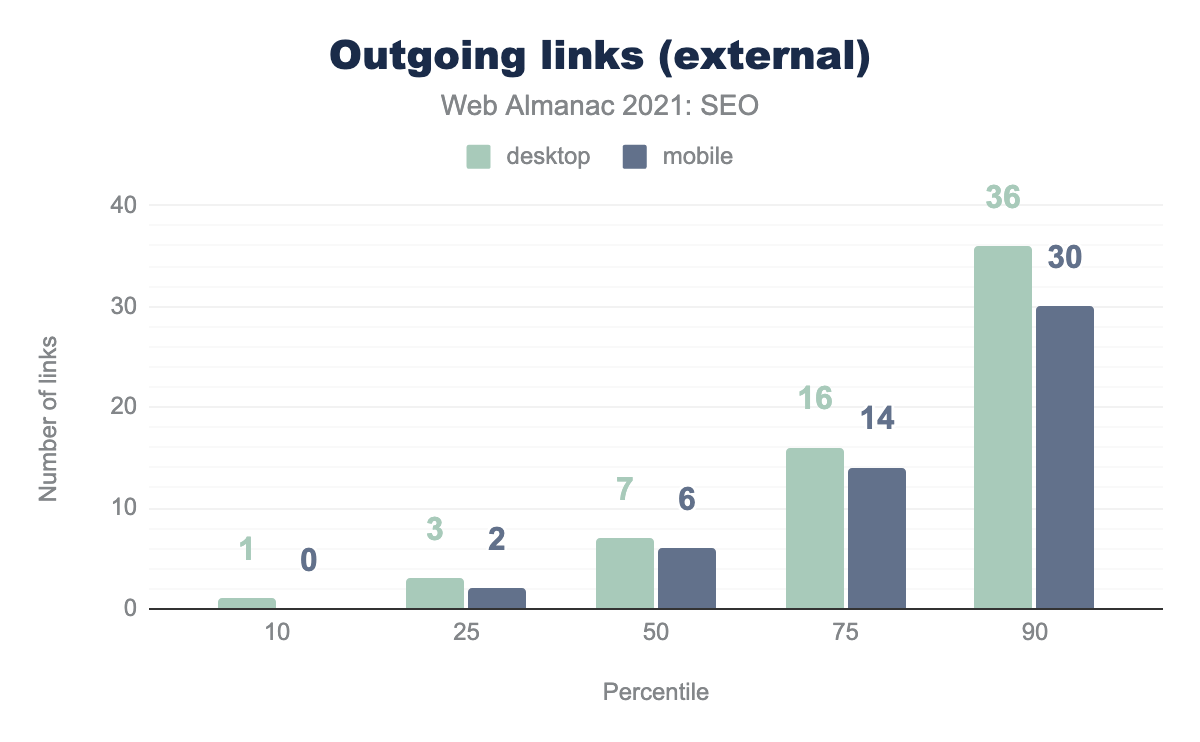
Внешние ссылки — это ссылки с одного сайта на другой сайт. Данные снова показывают меньше внешних ссылок на мобильных версиях страниц.
Значения почти такие же, как и в 2020 году. Несмотря на то, что в этом году Google развернул приоритетную индексацию для мобильных устройств, веб-сайты не довели свои мобильные версии до полного сходства с версиями для компьютеров.
Текстовые ссылки и ссылки-изображения

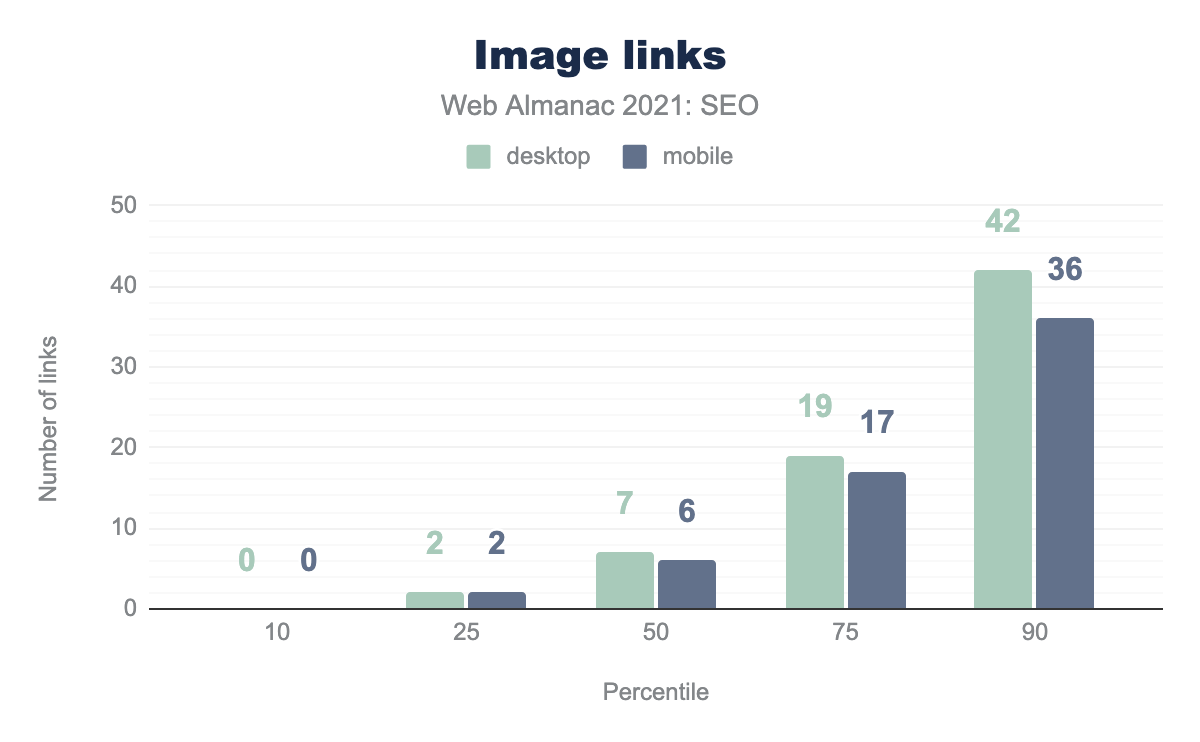
Хотя значительная доля ссылок в Интернете основана на тексте, часть также содержит изображения в ссылках на другие страницы. 9.2% ссылок на компьютерных и 8.7% ссылок на мобильных страницах содержат изображения в элементе <a>. В случае со ссылками-изображениями атрибуты alt для изображения выступают в роли анкорного текста, чтобы обеспечить дополнительный контекст о том, о чем связанная страница.
Атрибуты ссылок
В сентябре 2019 года Google представил атрибуты, которые позволяют издателям классифицировать ссылки как спонсируемые или созданные пользователем. Эти атрибуты являются дополнением к атрибуту rel="nofollow", введенному ранее в 2005 году. Новые атрибуты rel="ugc" и rel="sponsored" дают дополнительную информацию о ссылках.
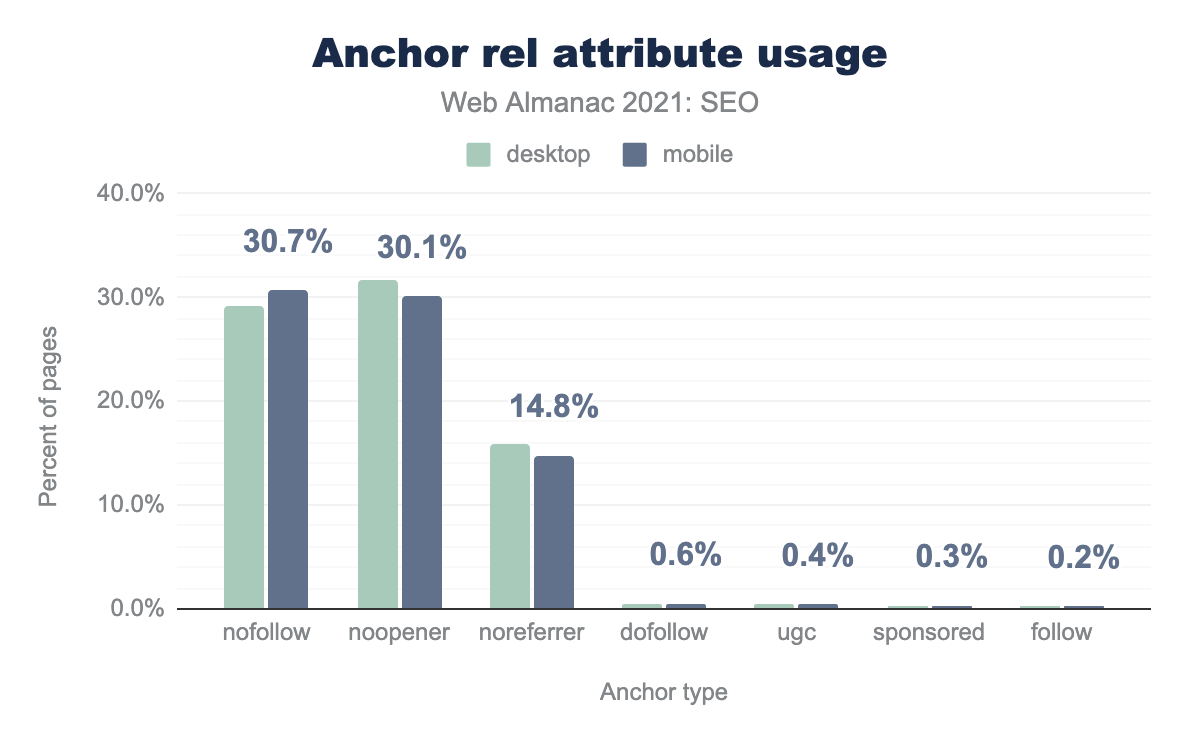
rel на компьютерах и мобильных устройствах. Наши данные показали, что 29.2% главных страниц используют атрибуты nofollow на компьютерных версиях, и 30.7% — на мобильных. Атрибут rel="noopener" использовался на 31.6% компьютерных и на 30.1% мобильных страниц. Атрибут rel="noreferrer" использовался на 15.8% компьютерных и на 14.8% мобильных страниц. Атрибуты rel="dofollow", rel="ugc", rel="sponsored" и rel="follow" использовались менее чем на 1% страниц для компьютеров и мобильных устройств.rel.
Новые атрибуты по-прежнему используются редко, по крайней мере, на главных страницах: rel="ugc" обнаружен на 0.4% мобильных страниц, а rel="sponsored" — на 0.3% мобильных страниц. Скорее всего, эти атрибуты чаще используются на страницах, не являющихся главными.
Атрибуты rel="follow" и rel="dofollow" используются на большем количестве страниц, чем атрибуты rel="ugc" и rel="sponsored". Это не является проблемой, но Google игнорирует rel="follow" и rel="dofollow", поскольку они не являются официальными атрибутами.
Атрибут rel="nofollow" был обнаружен на 30.7% мобильных страниц, как и в прошлом году. Поскольку этот атрибут используется так часто, неудивительно, что Google начал воспринимать nofollow как подсказку, что означает, что Google сам решает, принимать во внимание этот атрибут или нет.
Ускоренные мобильные страницы (AMP)
В 2021 году произошли серьезные изменения в экосистеме ускоренных мобильных страниц (AMP). AMP больше не требуется для карусели “Главные новости”, не требуется для приложения “Google Новости”, и также Google больше не будет отображать логотип AMP рядом с соответствующими результатами в поисковой выдаче.
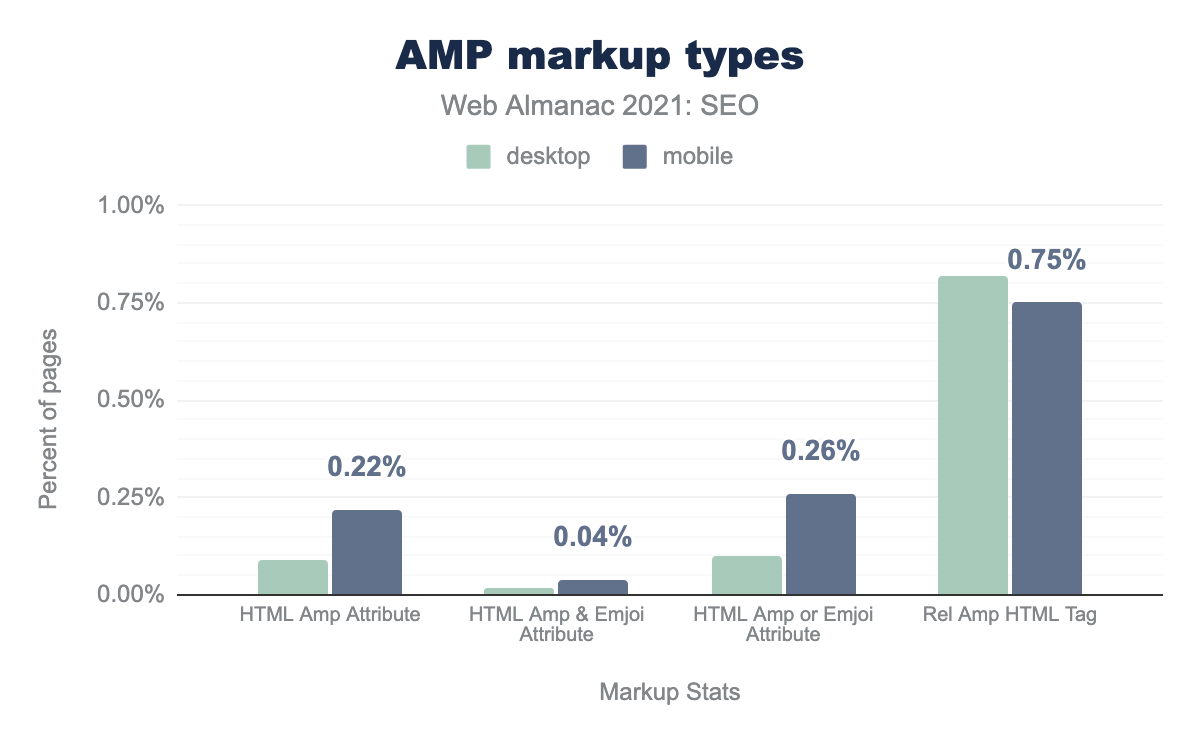
rel="amphtml" был обнаружен на 0.82% компьютерных и 0.75% мобильных страниц.Однако в 2021 году темпы распространения AMP продолжали расти. Атрибут AMP был обнаружен на 0.09% страниц для компьютеров и на 0.22% страниц для мобильных страниц. Это больше, чем 0.06% на компьютерных и 0.15% на мобильных страницах в 2020 году.
Интернационализация
Если у вас несколько версий страницы на разных языках или для разных регионов, помогите Google идентифицировать их. Тогда в результатах поиска будут показываться те языковые версии ваших страниц, которые лучше всего подходят для пользователя.
Чтобы поисковые системы знали о локализованных версиях ваших страниц, используйте теги hreflang. Атрибуты hreflang также используются Яндексом и Bing (в некоторой степени).
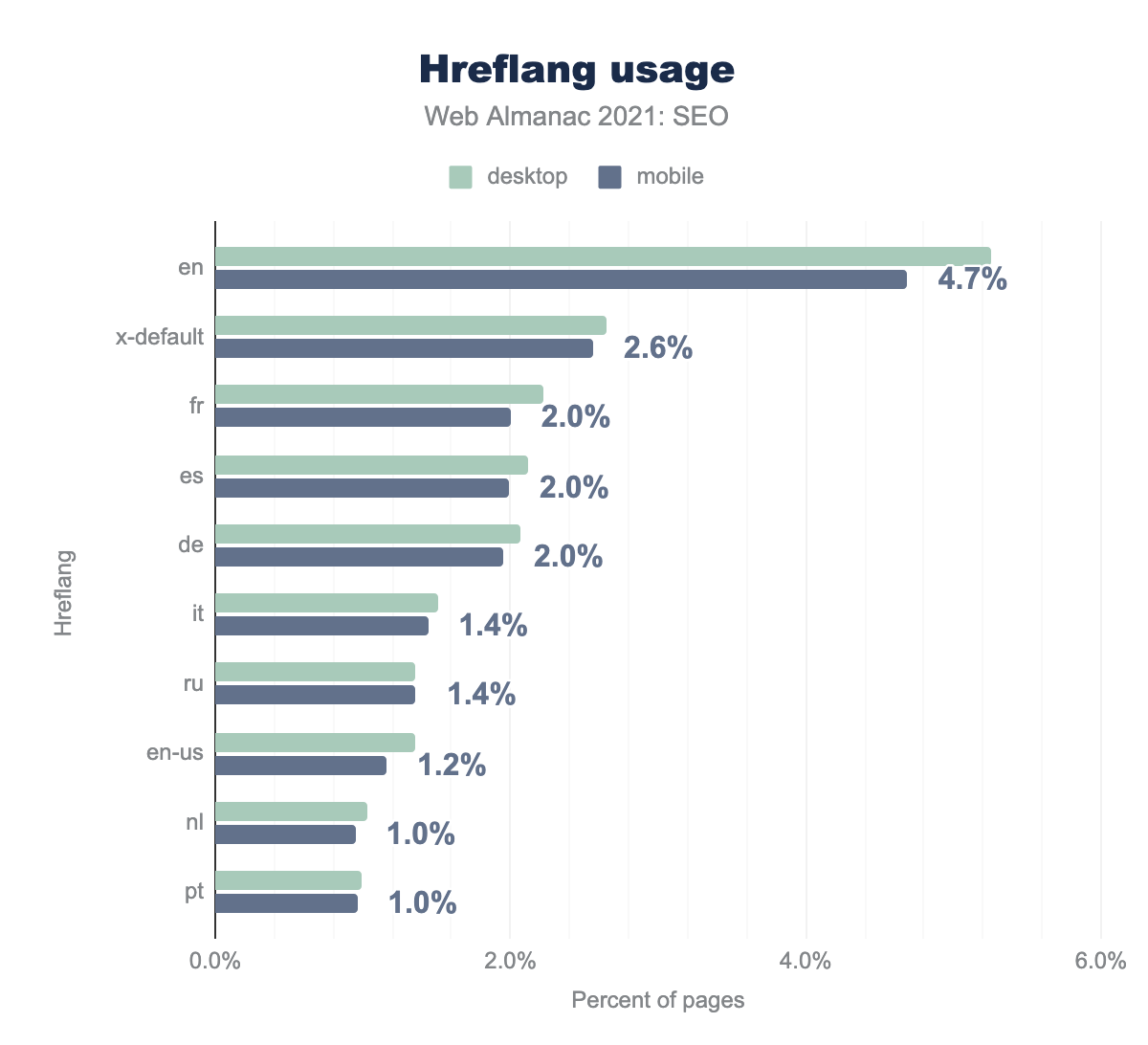
en (английская версия), и атрибуты hreflang (на всех языках) использовались менее чем на 5% страниц для компьютеров и мобильных устройств.Атрибут hreflang использовался на 9.0% страниц для компьютеров, и на 8.4% мобильных страниц.
Существует три способа реализации hreflang: в HTML-элементах <head>, в HTTP-заголовках Link и с помощью карт сайта XML. Наши данные не включают в себя данные из карт сайтов XML.
Самый популярный атрибут hreflang — "en" (английская версия). Его используют 4.75% главных страниц для мобильных устройств, и 5.32% — для компьютеров.
Значение x-default (также называемое резервной версией) используется в 2.56% случаев на мобильных устройствах. Другими популярными языками, используемыми в атрибутах hreflang, являются французский и испанский.
Для Bing hreflang является “гораздо более слабым сигналом”, чем HTTP-заголовок content-language.
Как и многие другие параметры SEO, у content-language есть несколько методов реализации, включая:
- HTTP-заголовок
- HTML-тег
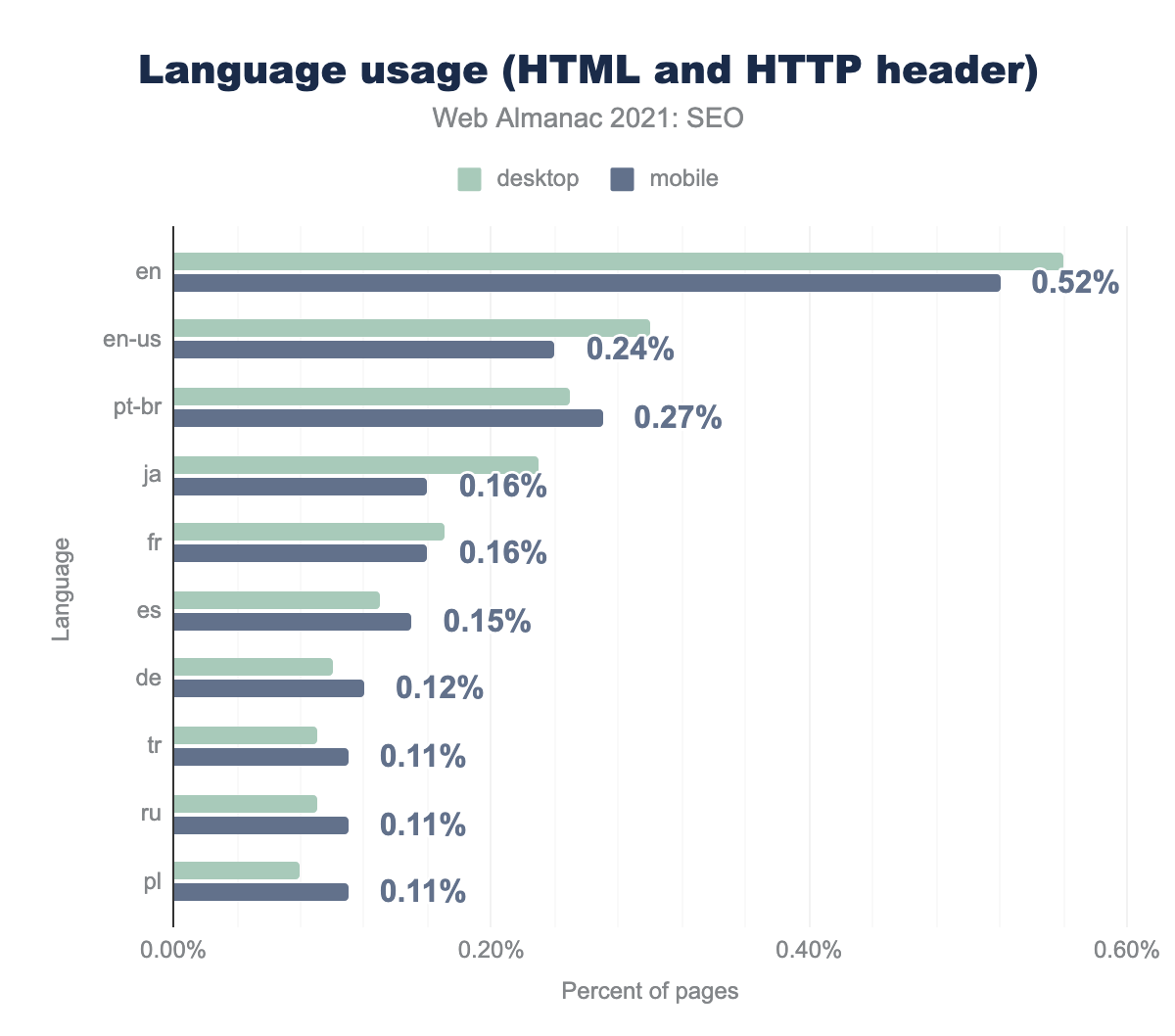
Использование HTTP-заголовков является наиболее популярным способом реализации content-language. 8.7% веб-сайтов используют его на компьютерах, а 9.3% — на мобильных устройствах.
Использование HTML-тега менее популярно: content-language используется только на 3.3% мобильных веб-сайтов.
Заключение
Веб-сайты постепенно улучшаются с точки зрения SEO. Вероятно, это результат комбинированной работы сайтов над улучшением своего SEO и работы над популярными платформами, на которых размещаются веб-сайты. Интернет — это большое и запутанное место, поэтому многое еще предстоит сделать, но приятно видеть постоянный прогресс.


